 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Illumination Distillation Framework for Nighttime Person Re-Identification and A New Benchmark
Aug 31, 2023
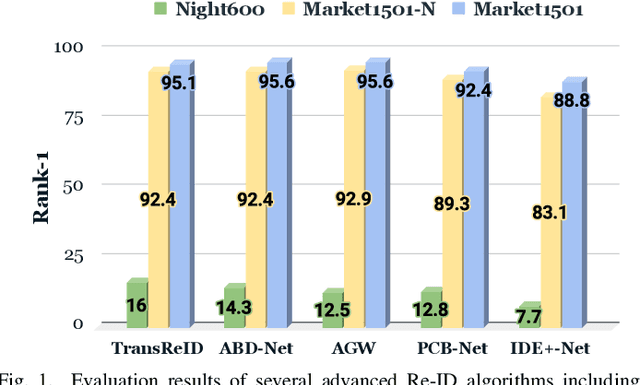

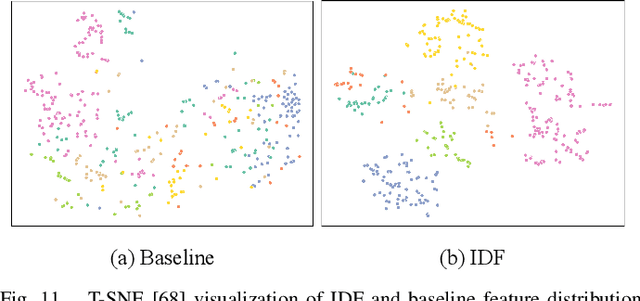
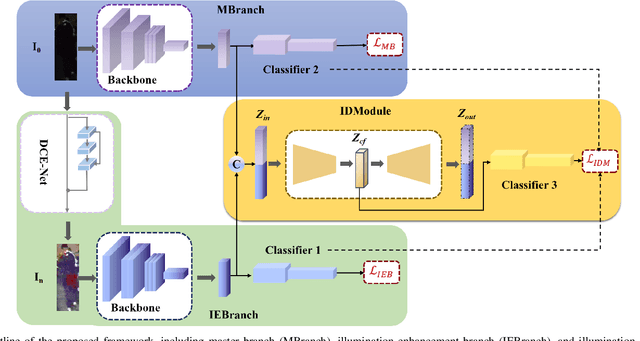
Nighttime person Re-ID (person re-identification in the nighttime) is a very important and challenging task for visual surveillance but it has not been thoroughly investigated. Under the low illumination condition, the performance of person Re-ID methods usually sharply deteriorates. To address the low illumination challenge in nighttime person Re-ID, this paper proposes an Illumination Distillation Framework (IDF), which utilizes illumination enhancement and illumination distillation schemes to promote the learning of Re-ID models. Specifically, IDF consists of a master branch, an illumination enhancement branch, and an illumination distillation module. The master branch is used to extract the features from a nighttime image. The illumination enhancement branch first estimates an enhanced image from the nighttime image using a nonlinear curve mapping method and then extracts the enhanced features. However, nighttime and enhanced features usually contain data noise due to unstable lighting conditions and enhancement failures. To fully exploit the complementary benefits of nighttime and enhanced features while suppressing data noise, we propose an illumination distillation module. In particular, the illumination distillation module fuses the features from two branches through a bottleneck fusion model and then uses the fused features to guide the learning of both branches in a distillation manner. In addition, we build a real-world nighttime person Re-ID dataset, named Night600, which contains 600 identities captured from different viewpoints and nighttime illumination conditions under complex outdoor environments. Experimental results demonstrate that our IDF can achieve state-of-the-art performance on two nighttime person Re-ID datasets (i.e., Night600 and Knight ). We will release our code and dataset at https://github.com/Alexadlu/IDF.
FACET: Fairness in Computer Vision Evaluation Benchmark
Aug 31, 2023

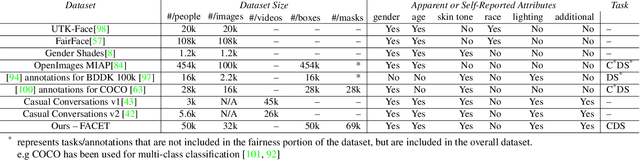
Computer vision models have known performance disparities across attributes such as gender and skin tone. This means during tasks such as classification and detection, model performance differs for certain classes based on the demographics of the people in the image. These disparities have been shown to exist, but until now there has not been a unified approach to measure these differences for common use-cases of computer vision models. We present a new benchmark named FACET (FAirness in Computer Vision EvaluaTion), a large, publicly available evaluation set of 32k images for some of the most common vision tasks - image classification, object detection and segmentation. For every image in FACET, we hired expert reviewers to manually annotate person-related attributes such as perceived skin tone and hair type, manually draw bounding boxes and label fine-grained person-related classes such as disk jockey or guitarist. In addition, we use FACET to benchmark state-of-the-art vision models and present a deeper understanding of potential performance disparities and challenges across sensitive demographic attributes. With the exhaustive annotations collected, we probe models using single demographics attributes as well as multiple attributes using an intersectional approach (e.g. hair color and perceived skin tone). Our results show that classification, detection, segmentation, and visual grounding models exhibit performance disparities across demographic attributes and intersections of attributes. These harms suggest that not all people represented in datasets receive fair and equitable treatment in these vision tasks. We hope current and future results using our benchmark will contribute to fairer, more robust vision models. FACET is available publicly at https://facet.metademolab.com/
Joint one-sided synthetic unpaired image translation and segmentation for colorectal cancer prevention
Jul 20, 2023Deep learning has shown excellent performance in analysing medical images. However, datasets are difficult to obtain due privacy issues, standardization problems, and lack of annotations. We address these problems by producing realistic synthetic images using a combination of 3D technologies and generative adversarial networks. We propose CUT-seg, a joint training where a segmentation model and a generative model are jointly trained to produce realistic images while learning to segment polyps. We take advantage of recent one-sided translation models because they use significantly less memory, allowing us to add a segmentation model in the training loop. CUT-seg performs better, is computationally less expensive, and requires less real images than other memory-intensive image translation approaches that require two stage training. Promising results are achieved on five real polyp segmentation datasets using only one real image and zero real annotations. As a part of this study we release Synth-Colon, an entirely synthetic dataset that includes 20000 realistic colon images and additional details about depth and 3D geometry: https://enric1994.github.io/synth-colon
MoMA: Momentum Contrastive Learning with Multi-head Attention-based Knowledge Distillation for Histopathology Image Analysis
Aug 31, 2023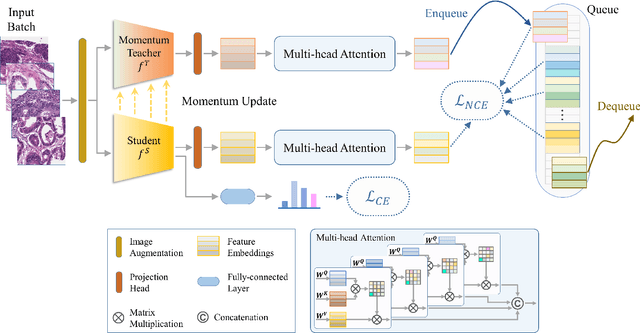
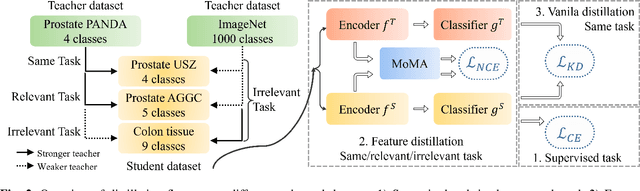
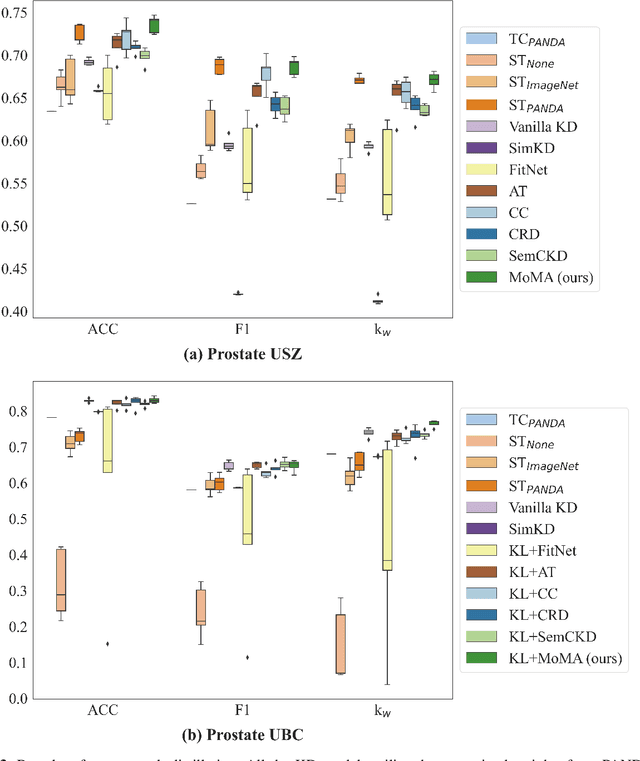
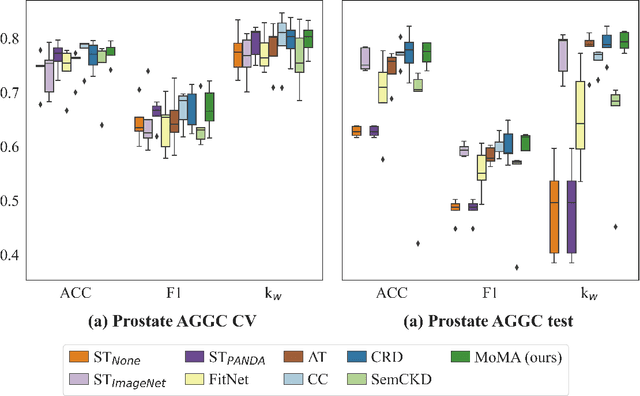
There is no doubt that advanced artificial intelligence models and high quality data are the keys to success in developing computational pathology tools. Although the overall volume of pathology data keeps increasing, a lack of quality data is a common issue when it comes to a specific task due to several reasons including privacy and ethical issues with patient data. In this work, we propose to exploit knowledge distillation, i.e., utilize the existing model to learn a new, target model, to overcome such issues in computational pathology. Specifically, we employ a student-teacher framework to learn a target model from a pre-trained, teacher model without direct access to source data and distill relevant knowledge via momentum contrastive learning with multi-head attention mechanism, which provides consistent and context-aware feature representations. This enables the target model to assimilate informative representations of the teacher model while seamlessly adapting to the unique nuances of the target data. The proposed method is rigorously evaluated across different scenarios where the teacher model was trained on the same, relevant, and irrelevant classification tasks with the target model. Experimental results demonstrate the accuracy and robustness of our approach in transferring knowledge to different domains and tasks, outperforming other related methods. Moreover, the results provide a guideline on the learning strategy for different types of tasks and scenarios in computational pathology. Code is available at: \url{https://github.com/trinhvg/MoMA}.
Division Gets Better: Learning Brightness-Aware and Detail-Sensitive Representations for Low-Light Image Enhancement
Jul 18, 2023



Low-light image enhancement strives to improve the contrast, adjust the visibility, and restore the distortion in color and texture. Existing methods usually pay more attention to improving the visibility and contrast via increasing the lightness of low-light images, while disregarding the significance of color and texture restoration for high-quality images. Against above issue, we propose a novel luminance and chrominance dual branch network, termed LCDBNet, for low-light image enhancement, which divides low-light image enhancement into two sub-tasks, e.g., luminance adjustment and chrominance restoration. Specifically, LCDBNet is composed of two branches, namely luminance adjustment network (LAN) and chrominance restoration network (CRN). LAN takes responsibility for learning brightness-aware features leveraging long-range dependency and local attention correlation. While CRN concentrates on learning detail-sensitive features via multi-level wavelet decomposition. Finally, a fusion network is designed to blend their learned features to produce visually impressive images. Extensive experiments conducted on seven benchmark datasets validate the effectiveness of our proposed LCDBNet, and the results manifest that LCDBNet achieves superior performance in terms of multiple reference/non-reference quality evaluators compared to other state-of-the-art competitors. Our code and pretrained model will be available.
Multi-Scale Estimation for Omni-Directional Saliency Maps Using Learnable Equator Bias
Sep 15, 2023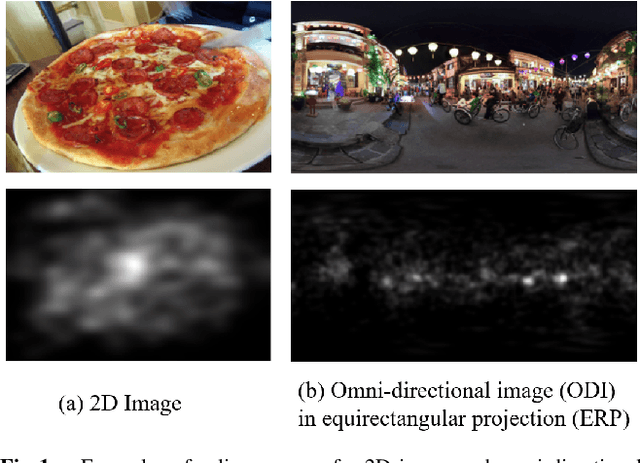
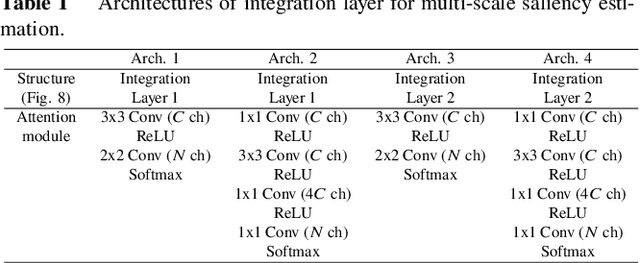
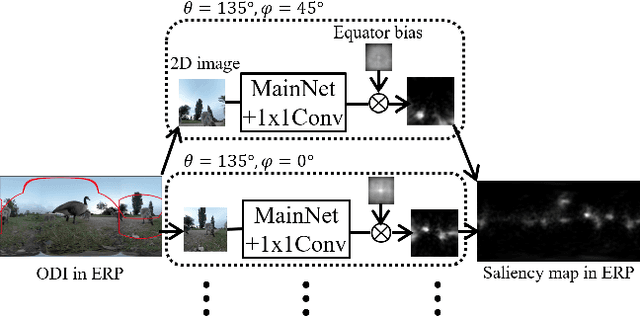
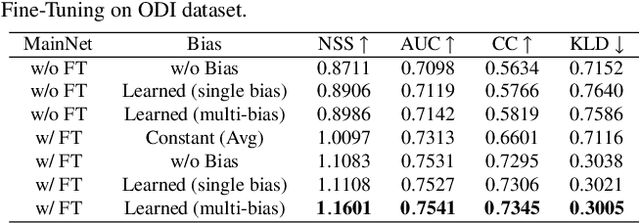
Omni-directional images have been used in wide range of applications. For the applications, it would be useful to estimate saliency maps representing probability distributions of gazing points with a head-mounted display, to detect important regions in the omni-directional images. This paper proposes a novel saliency-map estimation model for the omni-directional images by extracting overlapping 2-dimensional (2D) plane images from omni-directional images at various directions and angles of view. While 2D saliency maps tend to have high probability at the center of images (center bias), the high-probability region appears at horizontal directions in omni-directional saliency maps when a head-mounted display is used (equator bias). Therefore, the 2D saliency model with a center-bias layer was fine-tuned with an omni-directional dataset by replacing the center-bias layer to an equator-bias layer conditioned on the elevation angle for the extraction of the 2D plane image. The limited availability of omni-directional images in saliency datasets can be compensated by using the well-established 2D saliency model pretrained by a large number of training images with the ground truth of 2D saliency maps. In addition, this paper proposes a multi-scale estimation method by extracting 2D images in multiple angles of view to detect objects of various sizes with variable receptive fields. The saliency maps estimated from the multiple angles of view were integrated by using pixel-wise attention weights calculated in an integration layer for weighting the optimal scale to each object. The proposed method was evaluated using a publicly available dataset with evaluation metrics for omni-directional saliency maps. It was confirmed that the accuracy of the saliency maps was improved by the proposed method.
Find What You Want: Learning Demand-conditioned Object Attribute Space for Demand-driven Navigation
Sep 15, 2023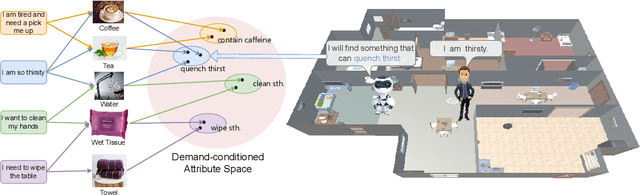
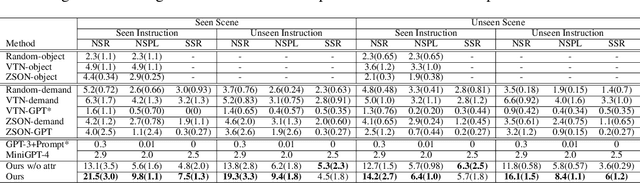
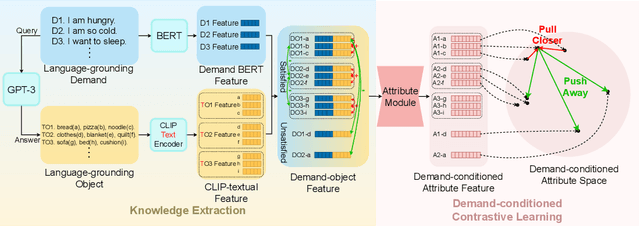
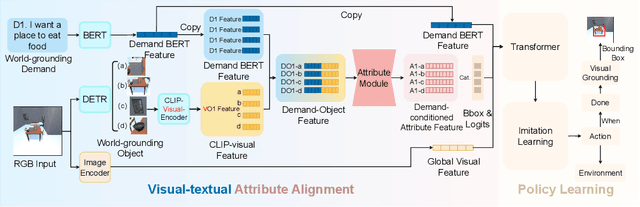
The task of Visual Object Navigation (VON) involves an agent's ability to locate a particular object within a given scene. In order to successfully accomplish the VON task, two essential conditions must be fulfilled:1) the user must know the name of the desired object; and 2) the user-specified object must actually be present within the scene. To meet these conditions, a simulator can incorporate pre-defined object names and positions into the metadata of the scene. However, in real-world scenarios, it is often challenging to ensure that these conditions are always met. Human in an unfamiliar environment may not know which objects are present in the scene, or they may mistakenly specify an object that is not actually present. Nevertheless, despite these challenges, human may still have a demand for an object, which could potentially be fulfilled by other objects present within the scene in an equivalent manner. Hence, we propose Demand-driven Navigation (DDN), which leverages the user's demand as the task instruction and prompts the agent to find the object matches the specified demand. DDN aims to relax the stringent conditions of VON by focusing on fulfilling the user's demand rather than relying solely on predefined object categories or names. We propose a method first acquire textual attribute features of objects by extracting common knowledge from a large language model. These textual attribute features are subsequently aligned with visual attribute features using Contrastive Language-Image Pre-training (CLIP). By incorporating the visual attribute features as prior knowledge, we enhance the navigation process. Experiments on AI2Thor with the ProcThor dataset demonstrate the visual attribute features improve the agent's navigation performance and outperform the baseline methods commonly used in VON.
Universal Preprocessing Operators for Embedding Knowledge Graphs with Literals
Sep 06, 2023
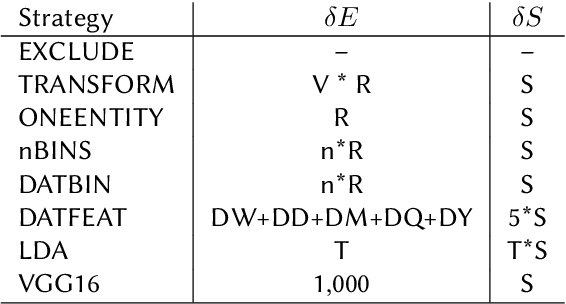
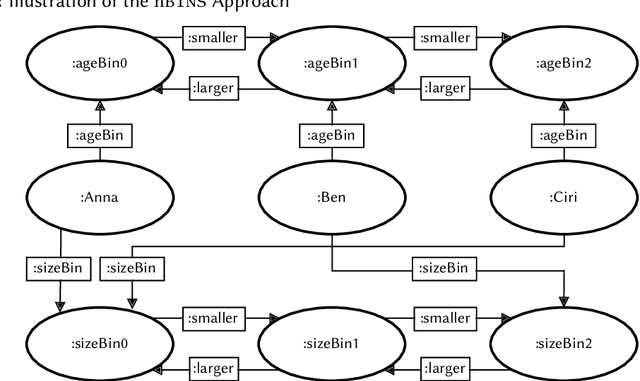
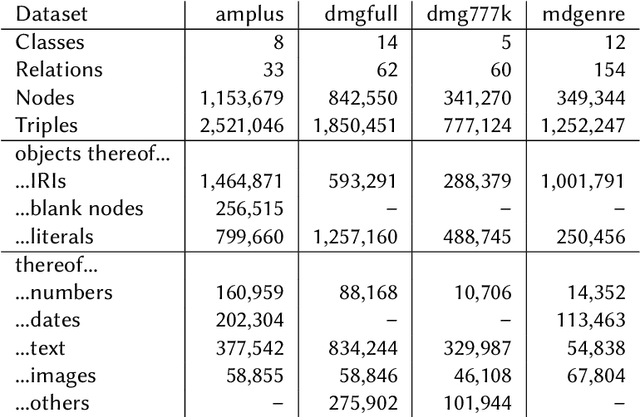
Knowledge graph embeddings are dense numerical representations of entities in a knowledge graph (KG). While the majority of approaches concentrate only on relational information, i.e., relations between entities, fewer approaches exist which also take information about literal values (e.g., textual descriptions or numerical information) into account. Those which exist are typically tailored towards a particular modality of literal and a particular embedding method. In this paper, we propose a set of universal preprocessing operators which can be used to transform KGs with literals for numerical, temporal, textual, and image information, so that the transformed KGs can be embedded with any method. The results on the kgbench dataset with three different embedding methods show promising results.
Reverse Knowledge Distillation: Training a Large Model using a Small One for Retinal Image Matching on Limited Data
Jul 21, 2023
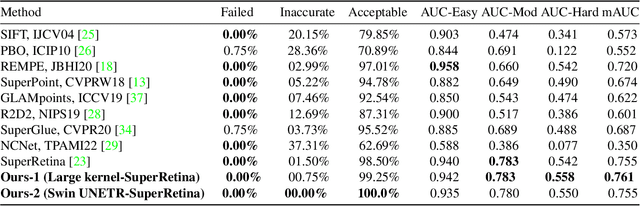
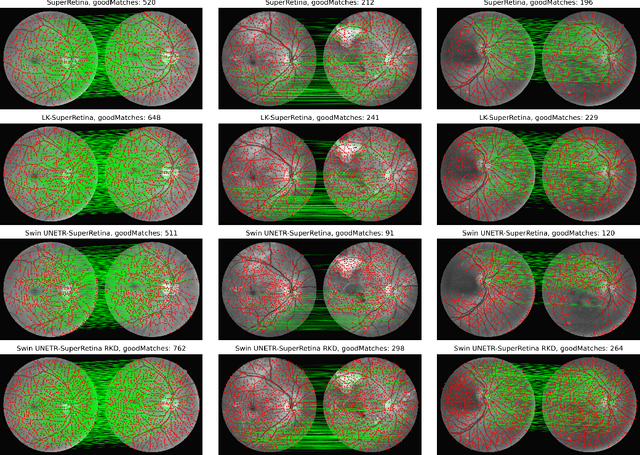
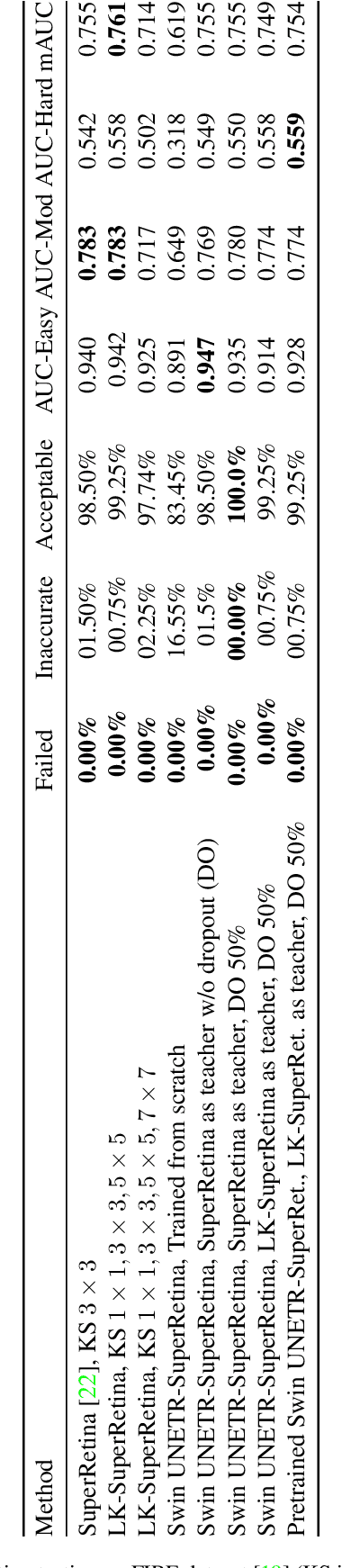
Retinal image matching plays a crucial role in monitoring disease progression and treatment response. However, datasets with matched keypoints between temporally separated pairs of images are not available in abundance to train transformer-based model. We propose a novel approach based on reverse knowledge distillation to train large models with limited data while preventing overfitting. Firstly, we propose architectural modifications to a CNN-based semi-supervised method called SuperRetina that help us improve its results on a publicly available dataset. Then, we train a computationally heavier model based on a vision transformer encoder using the lighter CNN-based model, which is counter-intuitive in the field knowledge-distillation research where training lighter models based on heavier ones is the norm. Surprisingly, such reverse knowledge distillation improves generalization even further. Our experiments suggest that high-dimensional fitting in representation space may prevent overfitting unlike training directly to match the final output. We also provide a public dataset with annotations for retinal image keypoint detection and matching to help the research community develop algorithms for retinal image applications.
Approximately Equivariant Graph Networks
Sep 03, 2023

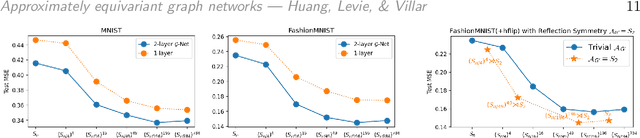

Graph neural networks (GNNs) are commonly described as being permutation equivariant with respect to node relabeling in the graph. This symmetry of GNNs is often compared to the translation equivariance symmetry of Euclidean convolution neural networks (CNNs). However, these two symmetries are fundamentally different: The translation equivariance of CNNs corresponds to symmetries of the fixed domain acting on the image signal (sometimes known as active symmetries), whereas in GNNs any permutation acts on both the graph signals and the graph domain (sometimes described as passive symmetries). In this work, we focus on the active symmetries of GNNs, by considering a learning setting where signals are supported on a fixed graph. In this case, the natural symmetries of GNNs are the automorphisms of the graph. Since real-world graphs tend to be asymmetric, we relax the notion of symmetries by formalizing approximate symmetries via graph coarsening. We present a bias-variance formula that quantifies the tradeoff between the loss in expressivity and the gain in the regularity of the learned estimator, depending on the chosen symmetry group. To illustrate our approach, we conduct extensive experiments on image inpainting, traffic flow prediction, and human pose estimation with different choices of symmetries. We show theoretically and empirically that the best generalization performance can be achieved by choosing a suitably larger group than the graph automorphism group, but smaller than the full permutation group.