 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Revealing the Underlying Patterns: Investigating Dataset Similarity, Performance, and Generalization
Aug 26, 2023
Supervised deep learning models require significant amount of labelled data to achieve an acceptable performance on a specific task. However, when tested on unseen data, the models may not perform well. Therefore, the models need to be trained with additional and varying labelled data to improve the generalization. In this work, our goal is to understand the models, their performance and generalization. We establish image-image, dataset-dataset, and image-dataset distances to gain insights into the model's behavior. Our proposed distance metric when combined with model performance can help in selecting an appropriate model/architecture from a pool of candidate architectures. We have shown that the generalization of these models can be improved by only adding a small number of unseen images (say 1, 3 or 7) into the training set. Our proposed approach reduces training and annotation costs while providing an estimate of model performance on unseen data in dynamic environments.
Jersey Number Recognition using Keyframe Identification from Low-Resolution Broadcast Videos
Sep 12, 2023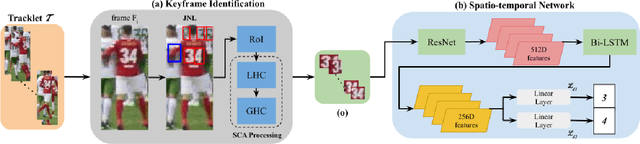
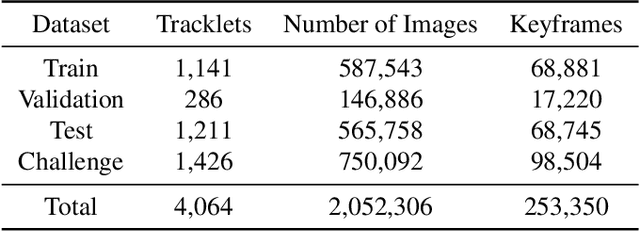
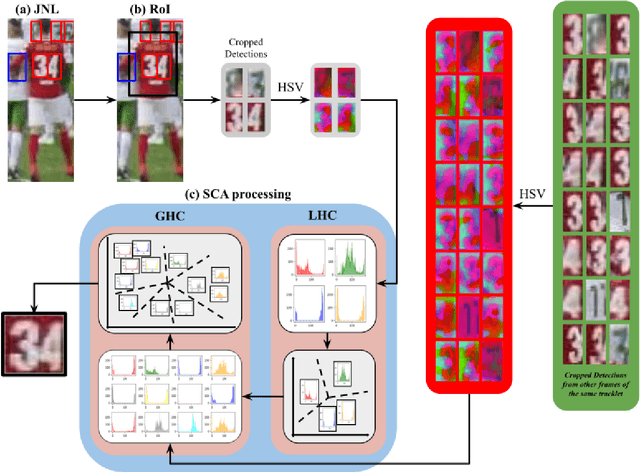
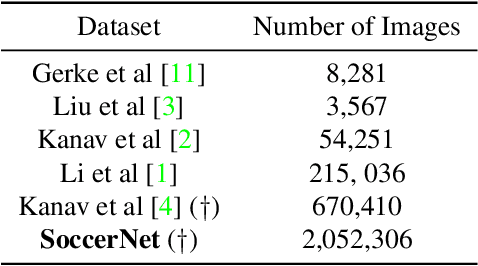
Player identification is a crucial component in vision-driven soccer analytics, enabling various downstream tasks such as player assessment, in-game analysis, and broadcast production. However, automatically detecting jersey numbers from player tracklets in videos presents challenges due to motion blur, low resolution, distortions, and occlusions. Existing methods, utilizing Spatial Transformer Networks, CNNs, and Vision Transformers, have shown success in image data but struggle with real-world video data, where jersey numbers are not visible in most of the frames. Hence, identifying frames that contain the jersey number is a key sub-problem to tackle. To address these issues, we propose a robust keyframe identification module that extracts frames containing essential high-level information about the jersey number. A spatio-temporal network is then employed to model spatial and temporal context and predict the probabilities of jersey numbers in the video. Additionally, we adopt a multi-task loss function to predict the probability distribution of each digit separately. Extensive evaluations on the SoccerNet dataset demonstrate that incorporating our proposed keyframe identification module results in a significant 37.81% and 37.70% increase in the accuracies of 2 different test sets with domain gaps. These results highlight the effectiveness and importance of our approach in tackling the challenges of automatic jersey number detection in sports videos.
Quality-Agnostic Deepfake Detection with Intra-model Collaborative Learning
Sep 12, 2023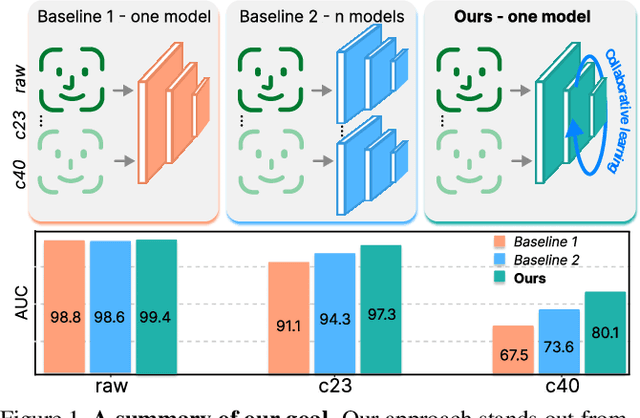
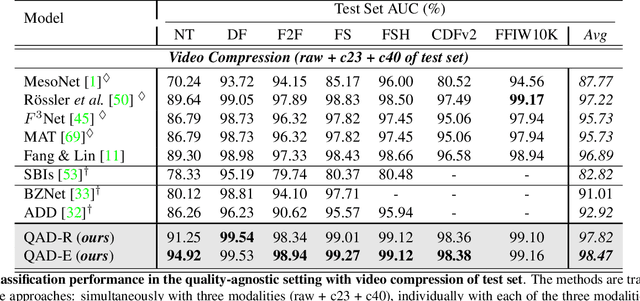
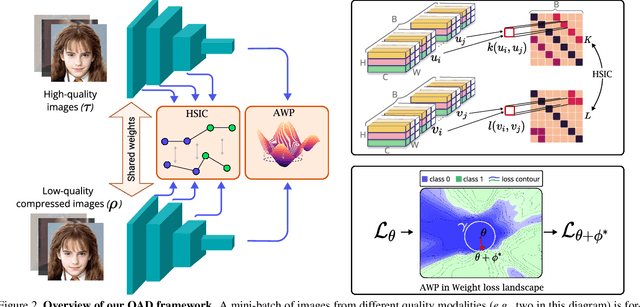
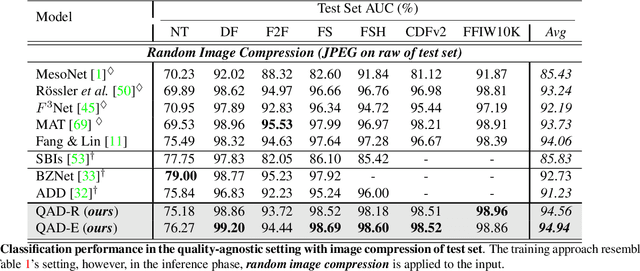
Deepfake has recently raised a plethora of societal concerns over its possible security threats and dissemination of fake information. Much research on deepfake detection has been undertaken. However, detecting low quality as well as simultaneously detecting different qualities of deepfakes still remains a grave challenge. Most SOTA approaches are limited by using a single specific model for detecting certain deepfake video quality type. When constructing multiple models with prior information about video quality, this kind of strategy incurs significant computational cost, as well as model and training data overhead. Further, it cannot be scalable and practical to deploy in real-world settings. In this work, we propose a universal intra-model collaborative learning framework to enable the effective and simultaneous detection of different quality of deepfakes. That is, our approach is the quality-agnostic deepfake detection method, dubbed QAD . In particular, by observing the upper bound of general error expectation, we maximize the dependency between intermediate representations of images from different quality levels via Hilbert-Schmidt Independence Criterion. In addition, an Adversarial Weight Perturbation module is carefully devised to enable the model to be more robust against image corruption while boosting the overall model's performance. Extensive experiments over seven popular deepfake datasets demonstrate the superiority of our QAD model over prior SOTA benchmarks.
TMComposites: Plug-and-Play Collaboration Between Specialized Tsetlin Machines
Sep 12, 2023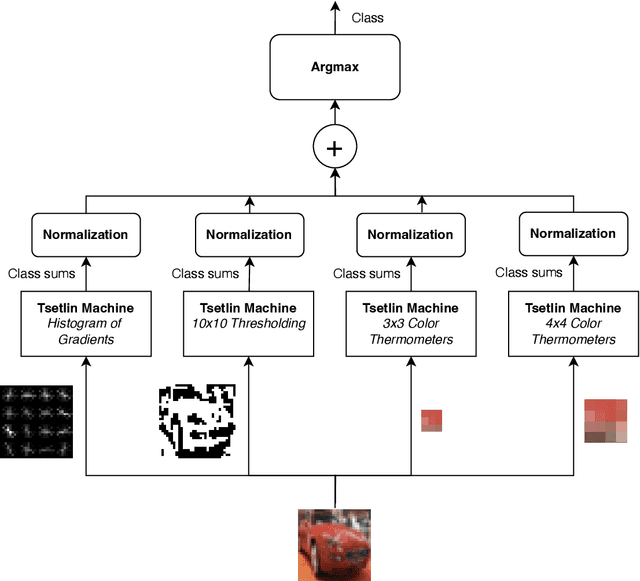

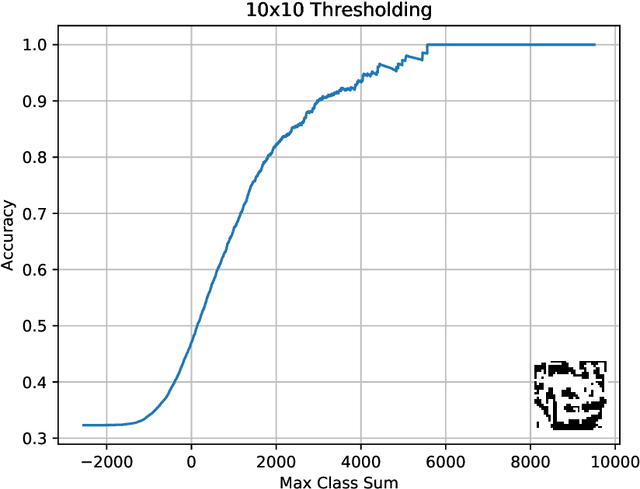
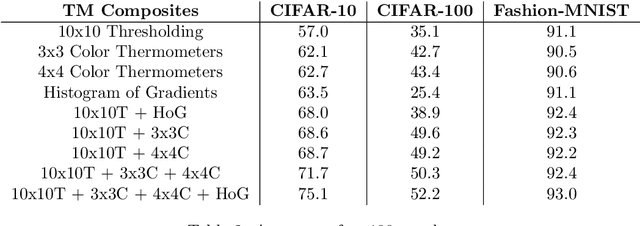
Tsetlin Machines (TMs) provide a fundamental shift from arithmetic-based to logic-based machine learning. Supporting convolution, they deal successfully with image classification datasets like MNIST, Fashion-MNIST, and CIFAR-2. However, the TM struggles with getting state-of-the-art performance on CIFAR-10 and CIFAR-100, representing more complex tasks. This paper introduces plug-and-play collaboration between specialized TMs, referred to as TM Composites. The collaboration relies on a TM's ability to specialize during learning and to assess its competence during inference. When teaming up, the most confident TMs make the decisions, relieving the uncertain ones. In this manner, a TM Composite becomes more competent than its members, benefiting from their specializations. The collaboration is plug-and-play in that members can be combined in any way, at any time, without fine-tuning. We implement three TM specializations in our empirical evaluation: Histogram of Gradients, Adaptive Gaussian Thresholding, and Color Thermometers. The resulting TM Composite increases accuracy on Fashion-MNIST by two percentage points, CIFAR-10 by twelve points, and CIFAR-100 by nine points, yielding new state-of-the-art results for TMs. Overall, we envision that TM Composites will enable an ultra-low energy and transparent alternative to state-of-the-art deep learning on more tasks and datasets.
Joint one-sided synthetic unpaired image translation and segmentation for colorectal cancer prevention
Jul 20, 2023Deep learning has shown excellent performance in analysing medical images. However, datasets are difficult to obtain due privacy issues, standardization problems, and lack of annotations. We address these problems by producing realistic synthetic images using a combination of 3D technologies and generative adversarial networks. We propose CUT-seg, a joint training where a segmentation model and a generative model are jointly trained to produce realistic images while learning to segment polyps. We take advantage of recent one-sided translation models because they use significantly less memory, allowing us to add a segmentation model in the training loop. CUT-seg performs better, is computationally less expensive, and requires less real images than other memory-intensive image translation approaches that require two stage training. Promising results are achieved on five real polyp segmentation datasets using only one real image and zero real annotations. As a part of this study we release Synth-Colon, an entirely synthetic dataset that includes 20000 realistic colon images and additional details about depth and 3D geometry: https://enric1994.github.io/synth-colon
Division Gets Better: Learning Brightness-Aware and Detail-Sensitive Representations for Low-Light Image Enhancement
Jul 18, 2023



Low-light image enhancement strives to improve the contrast, adjust the visibility, and restore the distortion in color and texture. Existing methods usually pay more attention to improving the visibility and contrast via increasing the lightness of low-light images, while disregarding the significance of color and texture restoration for high-quality images. Against above issue, we propose a novel luminance and chrominance dual branch network, termed LCDBNet, for low-light image enhancement, which divides low-light image enhancement into two sub-tasks, e.g., luminance adjustment and chrominance restoration. Specifically, LCDBNet is composed of two branches, namely luminance adjustment network (LAN) and chrominance restoration network (CRN). LAN takes responsibility for learning brightness-aware features leveraging long-range dependency and local attention correlation. While CRN concentrates on learning detail-sensitive features via multi-level wavelet decomposition. Finally, a fusion network is designed to blend their learned features to produce visually impressive images. Extensive experiments conducted on seven benchmark datasets validate the effectiveness of our proposed LCDBNet, and the results manifest that LCDBNet achieves superior performance in terms of multiple reference/non-reference quality evaluators compared to other state-of-the-art competitors. Our code and pretrained model will be available.
Enhancing Breast Cancer Classification Using Transfer ResNet with Lightweight Attention Mechanism
Aug 25, 2023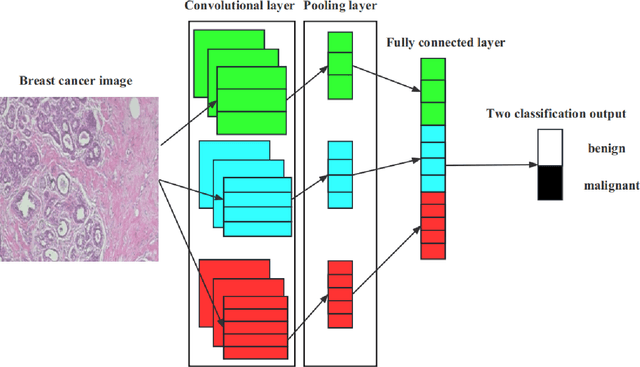
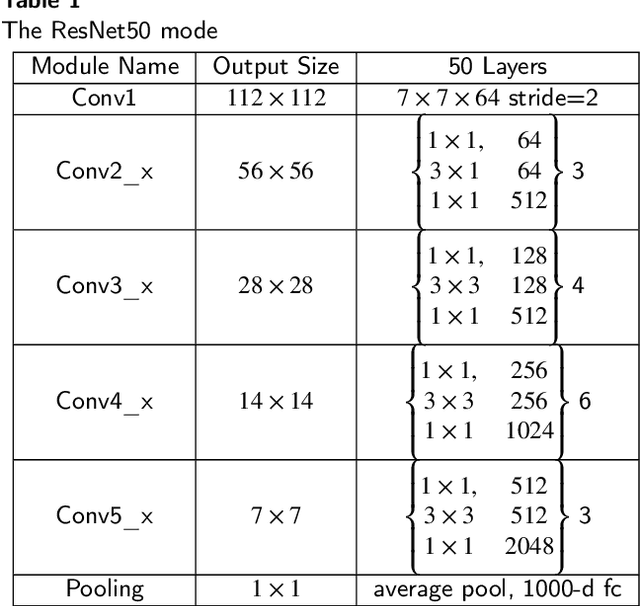
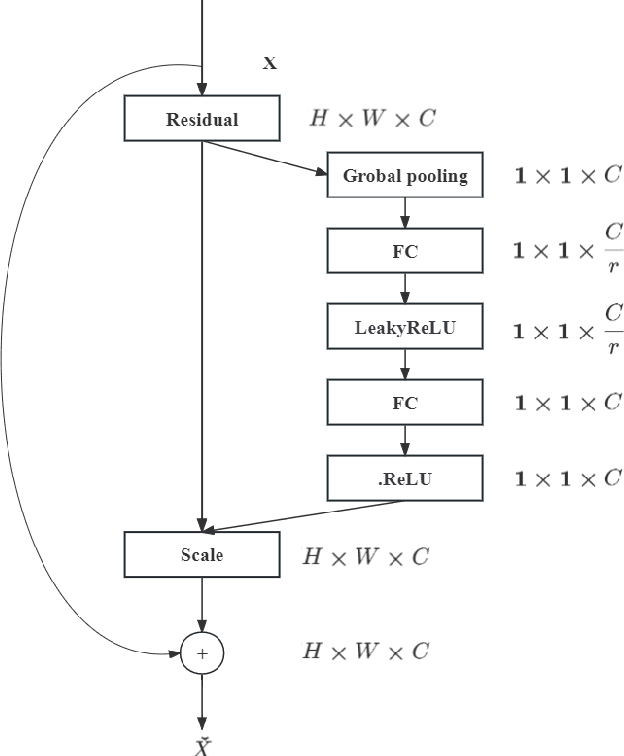
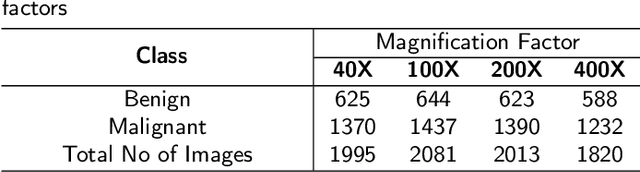
Deep learning models have revolutionized image classification by learning complex feature hierarchies in raw pixel data. This paper introduces an image classification method based on the ResNet model, and introduces a lightweight attention mechanism framework to improve performance. The framework optimizes feature representation, enhances classification capabilities, and improves feature discriminativeness. We verified the effectiveness of the algorithm on the Breakhis dataset, showing its superior performance in many aspects. Not only in terms of conventional models, our method also shows advantages on state-of-the-art methods such as contemporary visual transformers. Significant improvements have been achieved in metrics such as precision, accuracy, recall, F1-score, and G-means, while also performing well in terms of convergence time. These results strengthen the performance of the algorithm and solidify its application prospects in practical image classification tasks. Keywords: ResNet model, Lightweight attention mechanism
A General-Purpose Self-Supervised Model for Computational Pathology
Aug 29, 2023
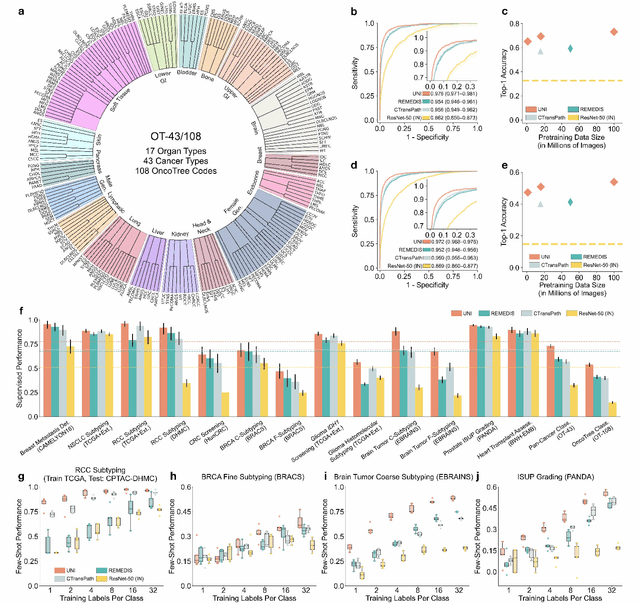
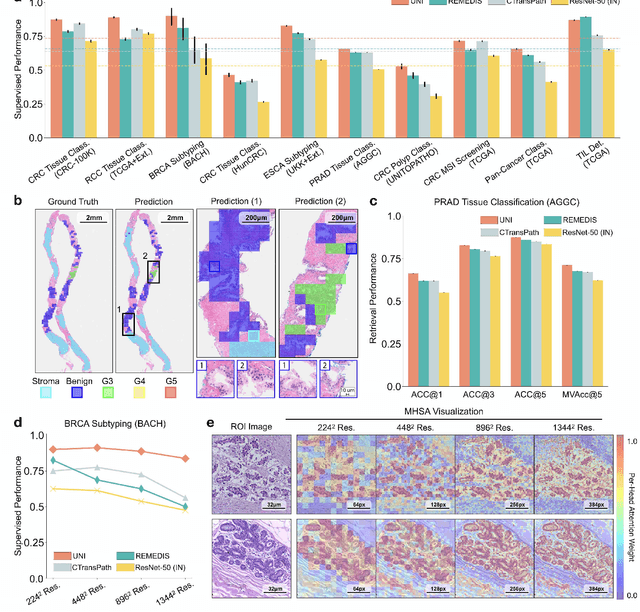
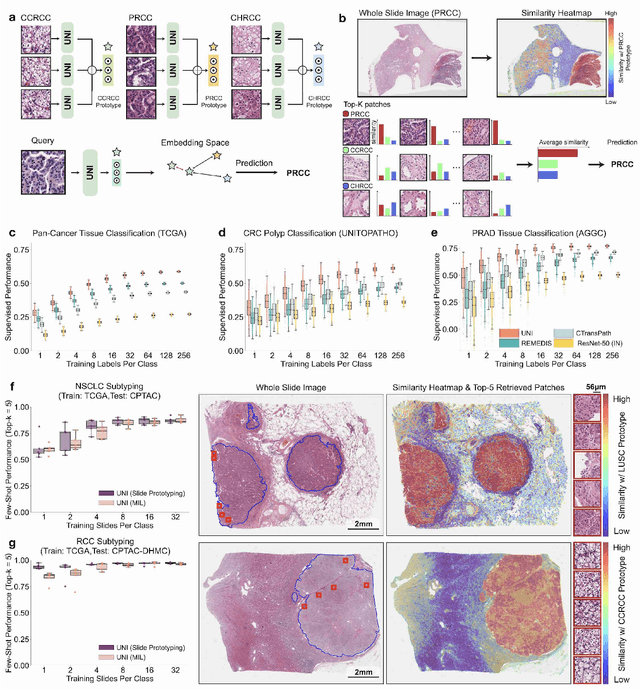
Tissue phenotyping is a fundamental computational pathology (CPath) task in learning objective characterizations of histopathologic biomarkers in anatomic pathology. However, whole-slide imaging (WSI) poses a complex computer vision problem in which the large-scale image resolutions of WSIs and the enormous diversity of morphological phenotypes preclude large-scale data annotation. Current efforts have proposed using pretrained image encoders with either transfer learning from natural image datasets or self-supervised pretraining on publicly-available histopathology datasets, but have not been extensively developed and evaluated across diverse tissue types at scale. We introduce UNI, a general-purpose self-supervised model for pathology, pretrained using over 100 million tissue patches from over 100,000 diagnostic haematoxylin and eosin-stained WSIs across 20 major tissue types, and evaluated on 33 representative CPath clinical tasks in CPath of varying diagnostic difficulties. In addition to outperforming previous state-of-the-art models, we demonstrate new modeling capabilities in CPath such as resolution-agnostic tissue classification, slide classification using few-shot class prototypes, and disease subtyping generalization in classifying up to 108 cancer types in the OncoTree code classification system. UNI advances unsupervised representation learning at scale in CPath in terms of both pretraining data and downstream evaluation, enabling data-efficient AI models that can generalize and transfer to a gamut of diagnostically-challenging tasks and clinical workflows in anatomic pathology.
Reverse Knowledge Distillation: Training a Large Model using a Small One for Retinal Image Matching on Limited Data
Jul 21, 2023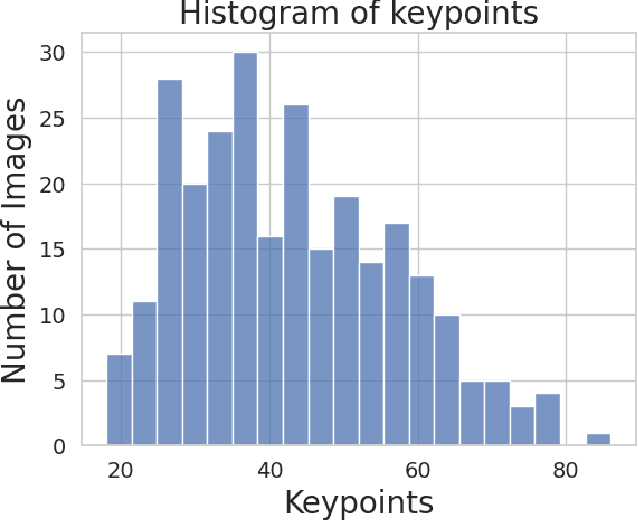
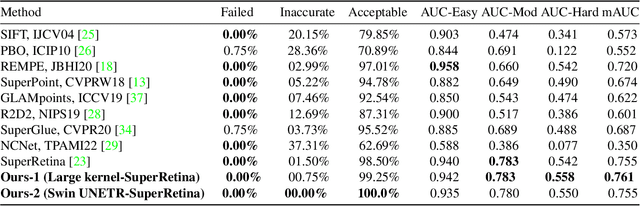
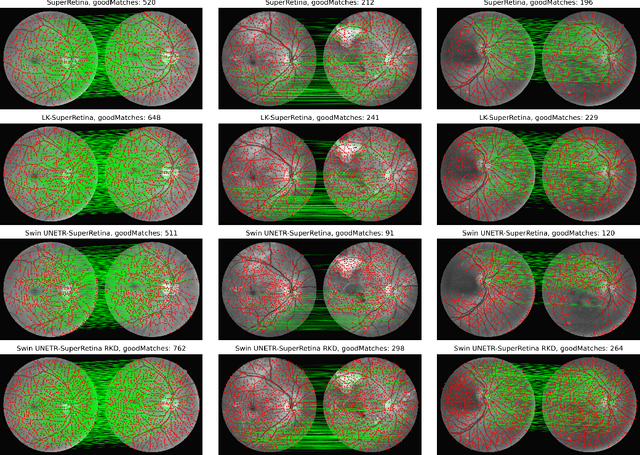
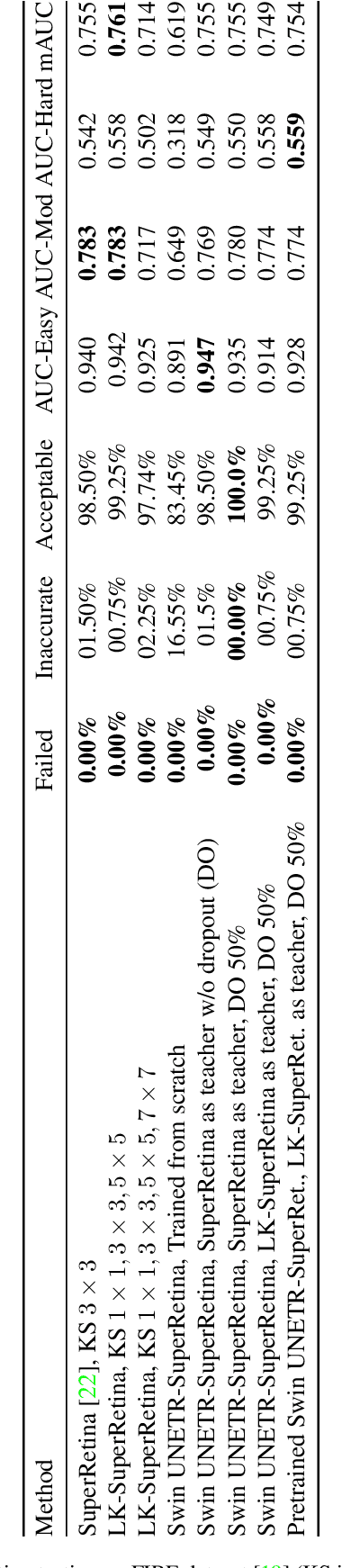
Retinal image matching plays a crucial role in monitoring disease progression and treatment response. However, datasets with matched keypoints between temporally separated pairs of images are not available in abundance to train transformer-based model. We propose a novel approach based on reverse knowledge distillation to train large models with limited data while preventing overfitting. Firstly, we propose architectural modifications to a CNN-based semi-supervised method called SuperRetina that help us improve its results on a publicly available dataset. Then, we train a computationally heavier model based on a vision transformer encoder using the lighter CNN-based model, which is counter-intuitive in the field knowledge-distillation research where training lighter models based on heavier ones is the norm. Surprisingly, such reverse knowledge distillation improves generalization even further. Our experiments suggest that high-dimensional fitting in representation space may prevent overfitting unlike training directly to match the final output. We also provide a public dataset with annotations for retinal image keypoint detection and matching to help the research community develop algorithms for retinal image applications.
Stream-based Active Learning by Exploiting Temporal Properties in Perception with Temporal Predicted Loss
Sep 11, 2023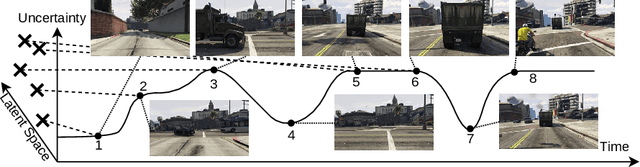
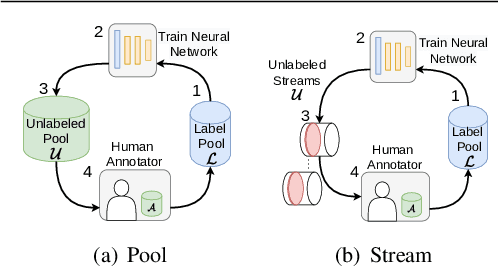
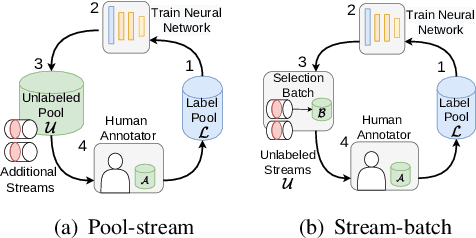

Active learning (AL) reduces the amount of labeled data needed to train a machine learning model by intelligently choosing which instances to label. Classic pool-based AL requires all data to be present in a datacenter, which can be challenging with the increasing amounts of data needed in deep learning. However, AL on mobile devices and robots, like autonomous cars, can filter the data from perception sensor streams before reaching the datacenter. We exploited the temporal properties for such image streams in our work and proposed the novel temporal predicted loss (TPL) method. To evaluate the stream-based setting properly, we introduced the GTA V streets and the A2D2 streets dataset and made both publicly available. Our experiments showed that our approach significantly improves the diversity of the selection while being an uncertainty-based method. As pool-based approaches are more common in perception applications, we derived a concept for comparing pool-based and stream-based AL, where TPL out-performed state-of-the-art pool- or stream-based approaches for different models. TPL demonstrated a gain of 2.5 precept points (pp) less required data while being significantly faster than pool-based methods.