 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RMT: Retentive Networks Meet Vision Transformers
Sep 20, 2023
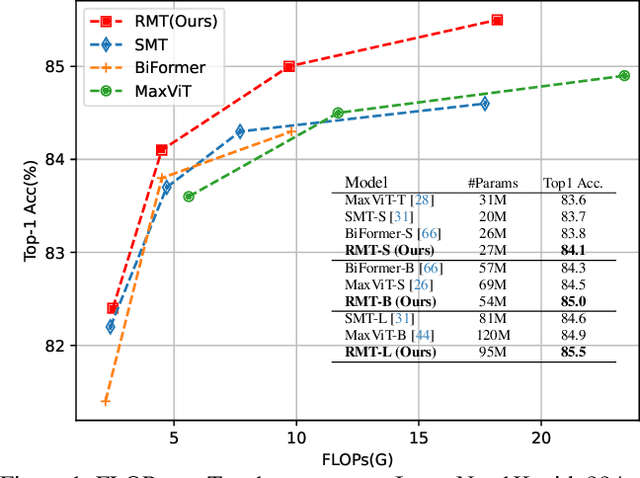

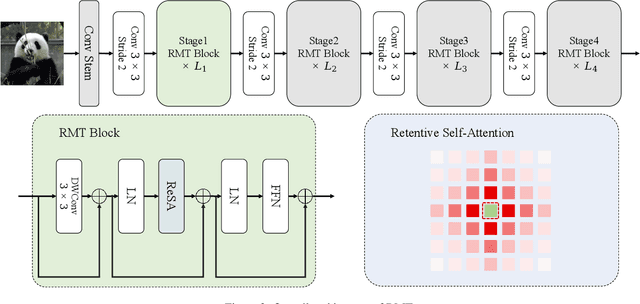
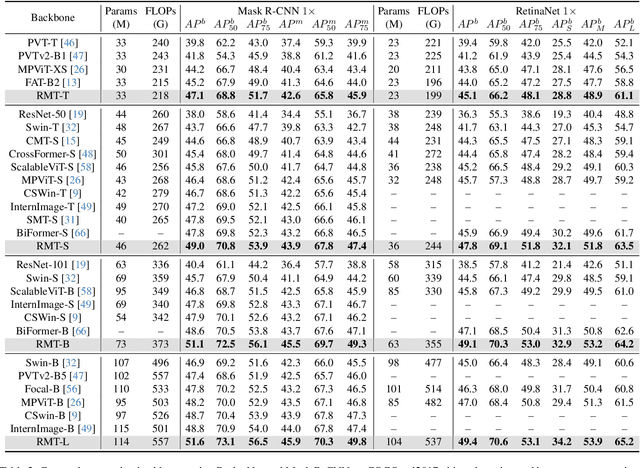
Transformer first appears in the field of natural language processing and is later migrated to the computer vision domain, where it demonstrates excellent performance in vision tasks. However, recently, Retentive Network (RetNet) has emerged as an architecture with the potential to replace Transformer, attracting widespread attention in the NLP community. Therefore, we raise the question of whether transferring RetNet's idea to vision can also bring outstanding performance to vision tasks. To address this, we combine RetNet and Transformer to propose RMT. Inspired by RetNet, RMT introduces explicit decay into the vision backbone, bringing prior knowledge related to spatial distances to the vision model. This distance-related spatial prior allows for explicit control of the range of tokens that each token can attend to. Additionally, to reduce the computational cost of global modeling, we decompose this modeling process along the two coordinate axes of the image. Abundant experiments have demonstrated that our RMT exhibits exceptional performance across various computer vision tasks. For example, RMT achieves 84.1% Top1-acc on ImageNet-1k using merely 4.5G FLOPs. To the best of our knowledge, among all models, RMT achieves the highest Top1-acc when models are of similar size and trained with the same strategy. Moreover, RMT significantly outperforms existing vision backbones in downstream tasks such as object detection, instance segmentation, and semantic segmentation. Our work is still in progress.
Language-driven Object Fusion into Neural Radiance Fields with Pose-Conditioned Dataset Updates
Sep 20, 2023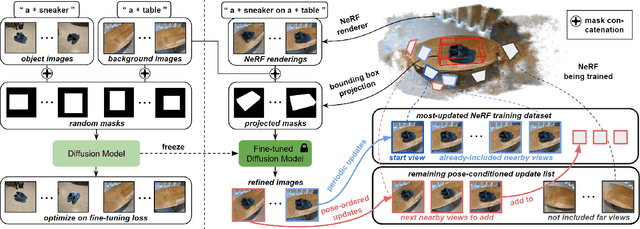


Neural radiance field is an emerging rendering method that generates high-quality multi-view consistent images from a neural scene representation and volume rendering. Although neural radiance field-based techniques are robust for scene reconstruction, their ability to add or remove objects remains limited. This paper proposes a new language-driven approach for object manipulation with neural radiance fields through dataset updates. Specifically, to insert a new foreground object represented by a set of multi-view images into a background radiance field, we use a text-to-image diffusion model to learn and generate combined images that fuse the object of interest into the given background across views. These combined images are then used for refining the background radiance field so that we can render view-consistent images containing both the object and the background. To ensure view consistency, we propose a dataset updates strategy that prioritizes radiance field training with camera views close to the already-trained views prior to propagating the training to remaining views. We show that under the same dataset updates strategy, we can easily adapt our method for object insertion using data from text-to-3D models as well as object removal. Experimental results show that our method generates photorealistic images of the edited scenes, and outperforms state-of-the-art methods in 3D reconstruction and neural radiance field blending.
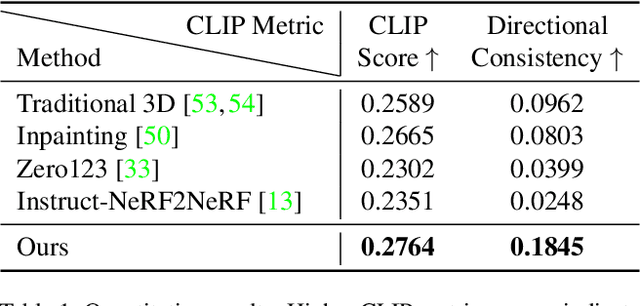
CalibFPA: A Focal Plane Array Imaging System based on Online Deep-Learning Calibration
Sep 20, 2023
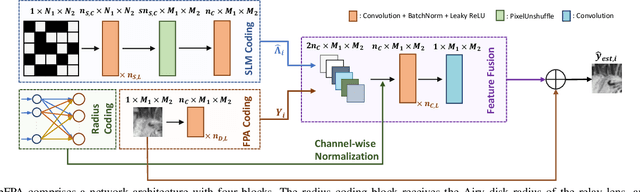
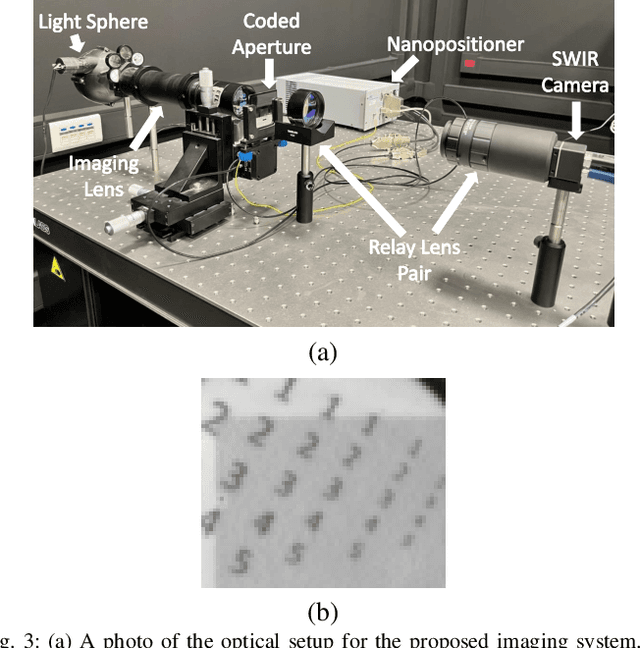
Compressive focal plane arrays (FPA) enable cost-effective high-resolution (HR) imaging by acquisition of several multiplexed measurements on a low-resolution (LR) sensor. Multiplexed encoding of the visual scene is typically performed via electronically controllable spatial light modulators (SLM). An HR image is then reconstructed from the encoded measurements by solving an inverse problem that involves the forward model of the imaging system. To capture system non-idealities such as optical aberrations, a mainstream approach is to conduct an offline calibration scan to measure the system response for a point source at each spatial location on the imaging grid. However, it is challenging to run calibration scans when using structured SLMs as they cannot encode individual grid locations. In this study, we propose a novel compressive FPA system based on online deep-learning calibration of multiplexed LR measurements (CalibFPA). We introduce a piezo-stage that locomotes a pre-printed fixed coded aperture. A deep neural network is then leveraged to correct for the influences of system non-idealities in multiplexed measurements without the need for offline calibration scans. Finally, a deep plug-and-play algorithm is used to reconstruct images from corrected measurements. On simulated and experimental datasets, we demonstrate that CalibFPA outperforms state-of-the-art compressive FPA methods. We also report analyses to validate the design elements in CalibFPA and assess computational complexity.
Scalable Semantic 3D Mapping of Coral Reefs with Deep Learning
Sep 22, 2023
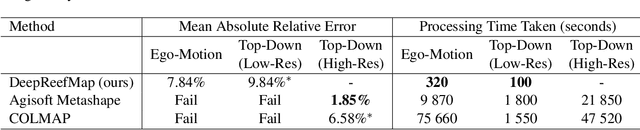


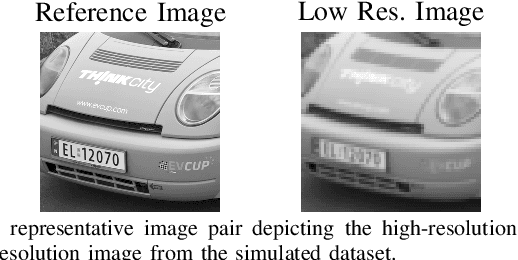
Coral reefs are among the most diverse ecosystems on our planet, and are depended on by hundreds of millions of people. Unfortunately, most coral reefs are existentially threatened by global climate change and local anthropogenic pressures. To better understand the dynamics underlying deterioration of reefs, monitoring at high spatial and temporal resolution is key. However, conventional monitoring methods for quantifying coral cover and species abundance are limited in scale due to the extensive manual labor required. Although computer vision tools have been employed to aid in this process, in particular SfM photogrammetry for 3D mapping and deep neural networks for image segmentation, analysis of the data products creates a bottleneck, effectively limiting their scalability. This paper presents a new paradigm for mapping underwater environments from ego-motion video, unifying 3D mapping systems that use machine learning to adapt to challenging conditions under water, combined with a modern approach for semantic segmentation of images. The method is exemplified on coral reefs in the northern Gulf of Aqaba, Red Sea, demonstrating high-precision 3D semantic mapping at unprecedented scale with significantly reduced required labor costs: a 100 m video transect acquired within 5 minutes of diving with a cheap consumer-grade camera can be fully automatically analyzed within 5 minutes. Our approach significantly scales up coral reef monitoring by taking a leap towards fully automatic analysis of video transects. The method democratizes coral reef transects by reducing the labor, equipment, logistics, and computing cost. This can help to inform conservation policies more efficiently. The underlying computational method of learning-based Structure-from-Motion has broad implications for fast low-cost mapping of underwater environments other than coral reefs.
Color Image Recovery Using Generalized Matrix Completion over Higher-Order Finite Dimensional Algebra
Aug 04, 2023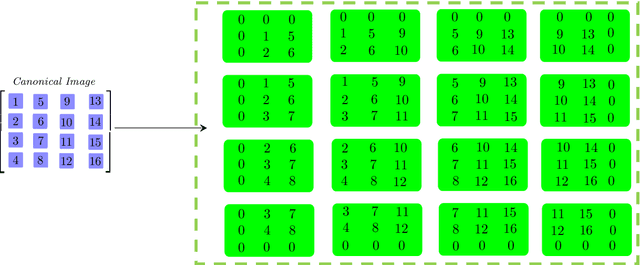
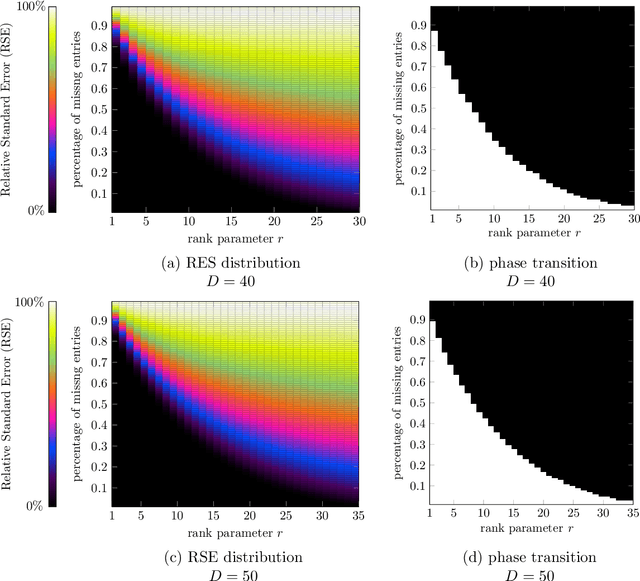

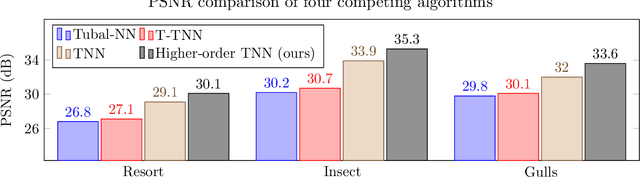
To improve the accuracy of color image completion with missing entries, we present a recovery method based on generalized higher-order scalars. We extend the traditional second-order matrix model to a more comprehensive higher-order matrix equivalent, called the "t-matrix" model, which incorporates a pixel neighborhood expansion strategy to characterize the local pixel constraints. This "t-matrix" model is then used to extend some commonly used matrix and tensor completion algorithms to their higher-order versions. We perform extensive experiments on various algorithms using simulated data and algorithms on simulated data and publicly available images and compare their performance. The results show that our generalized matrix completion model and the corresponding algorithm compare favorably with their lower-order tensor and conventional matrix counterparts.
Towards Top-Down Stereoscopic Image Quality Assessment via Stereo Attention
Aug 08, 2023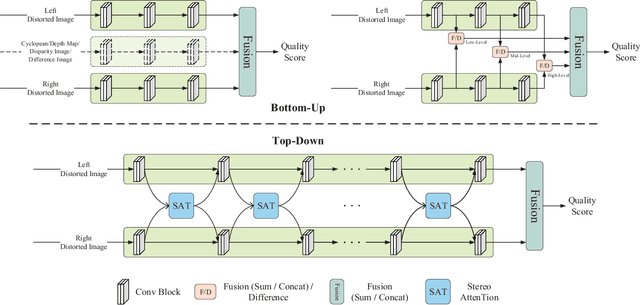
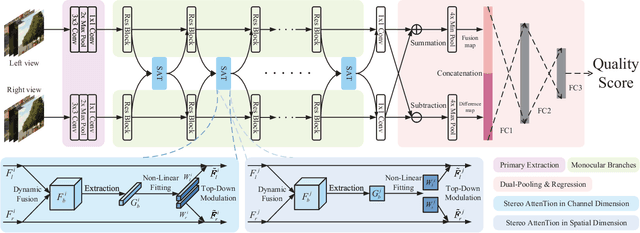
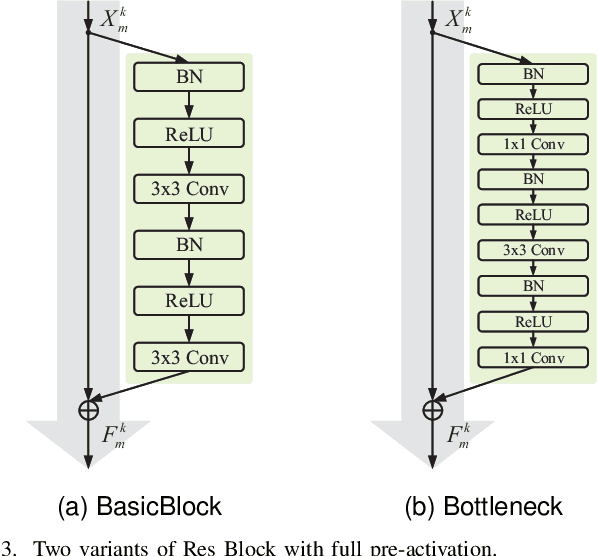
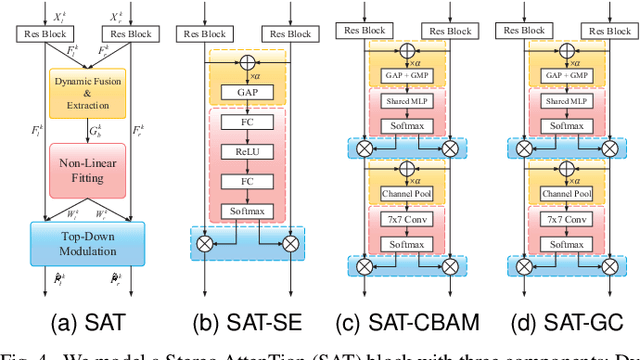
Stereoscopic image quality assessment (SIQA) plays a crucial role in evaluating and improving the visual experience of 3D content. Existing binocular properties and attention-based methods for SIQA have achieved promising performance. However, these bottom-up approaches are inadequate in exploiting the inherent characteristics of the human visual system (HVS). This paper presents a novel network for SIQA via stereo attention, employing a top-down perspective to guide the quality assessment process. Our proposed method realizes the guidance from high-level binocular signals down to low-level monocular signals, while the binocular and monocular information can be calibrated progressively throughout the processing pipeline. We design a generalized Stereo AttenTion (SAT) block to implement the top-down philosophy in stereo perception. This block utilizes the fusion-generated attention map as a high-level binocular modulator, influencing the representation of two low-level monocular features. Additionally, we introduce an Energy Coefficient (EC) to account for recent findings indicating that binocular responses in the primate primary visual cortex are less than the sum of monocular responses. The adaptive EC can tune the magnitude of binocular response flexibly, thus enhancing the formation of robust binocular features within our framework. To extract the most discriminative quality information from the summation and subtraction of the two branches of monocular features, we utilize a dual-pooling strategy that applies min-pooling and max-pooling operations to the respective branches. Experimental results highlight the superiority of our top-down method in simulating the property of visual perception and advancing the state-of-the-art in the SIQA field. The code of this work is available at https://github.com/Fanning-Zhang/SATNet.
3D Object Positioning Using Differentiable Multimodal Learning
Sep 06, 2023This article describes a multi-modal method using simulated Lidar data via ray tracing and image pixel loss with differentiable rendering to optimize an object's position with respect to an observer or some referential objects in a computer graphics scene. Object position optimization is completed using gradient descent with the loss function being influenced by both modalities. Typical object placement optimization is done using image pixel loss with differentiable rendering only, this work shows the use of a second modality (Lidar) leads to faster convergence. This method of fusing sensor input presents a potential usefulness for autonomous vehicles, as these methods can be used to establish the locations of multiple actors in a scene. This article also presents a method for the simulation of multiple types of data to be used in the training of autonomous vehicles.
$L_{2,1}$-Norm Regularized Quaternion Matrix Completion Using Sparse Representation and Quaternion QR Decomposition
Sep 07, 2023
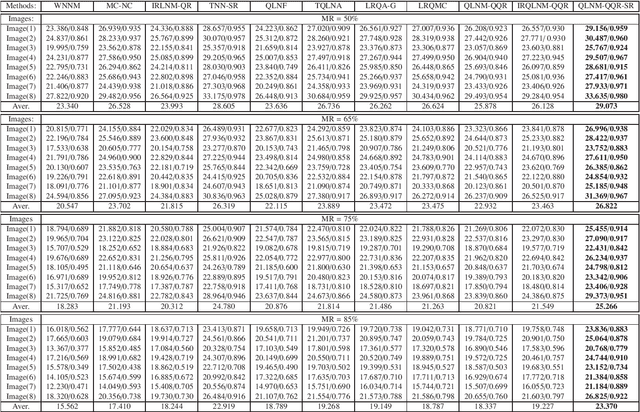


Color image completion is a challenging problem in computer vision, but recent research has shown that quaternion representations of color images perform well in many areas. These representations consider the entire color image and effectively utilize coupling information between the three color channels. Consequently, low-rank quaternion matrix completion (LRQMC) algorithms have gained significant attention. We propose a method based on quaternion Qatar Riyal decomposition (QQR) and quaternion $L_{2,1}$-norm called QLNM-QQR. This new approach reduces computational complexity by avoiding the need to calculate the QSVD of large quaternion matrices. We also present two improvements to the QLNM-QQR method: an enhanced version called IRQLNM-QQR that uses iteratively reweighted quaternion $L_{2,1}$-norm minimization and a method called QLNM-QQR-SR that integrates sparse regularization. Our experiments on natural color images and color medical images show that IRQLNM-QQR outperforms QLNM-QQR and that the proposed QLNM-QQR-SR method is superior to several state-of-the-art methods.
Feature Enhancer Segmentation Network (FES-Net) for Vessel Segmentation
Sep 07, 2023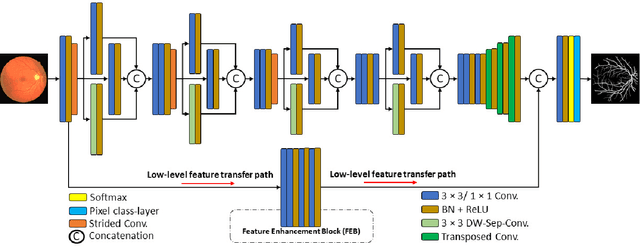
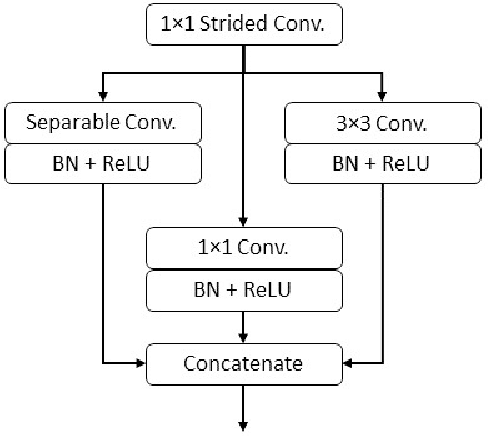
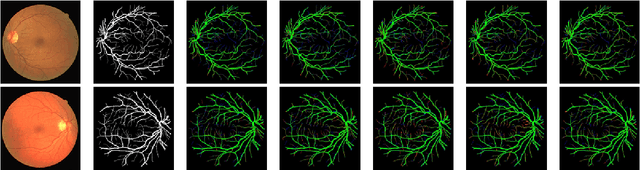
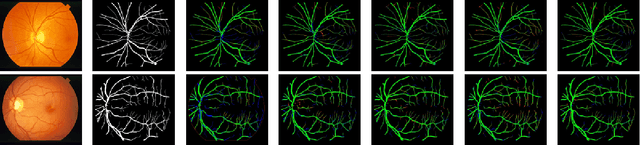
Diseases such as diabetic retinopathy and age-related macular degeneration pose a significant risk to vision, highlighting the importance of precise segmentation of retinal vessels for the tracking and diagnosis of progression. However, existing vessel segmentation methods that heavily rely on encoder-decoder structures struggle to capture contextual information about retinal vessel configurations, leading to challenges in reconciling semantic disparities between encoder and decoder features. To address this, we propose a novel feature enhancement segmentation network (FES-Net) that achieves accurate pixel-wise segmentation without requiring additional image enhancement steps. FES-Net directly processes the input image and utilizes four prompt convolutional blocks (PCBs) during downsampling, complemented by a shallow upsampling approach to generate a binary mask for each class. We evaluate the performance of FES-Net on four publicly available state-of-the-art datasets: DRIVE, STARE, CHASE, and HRF. The evaluation results clearly demonstrate the superior performance of FES-Net compared to other competitive approaches documented in the existing literature.
Few-Shot Panoptic Segmentation With Foundation Models
Sep 19, 2023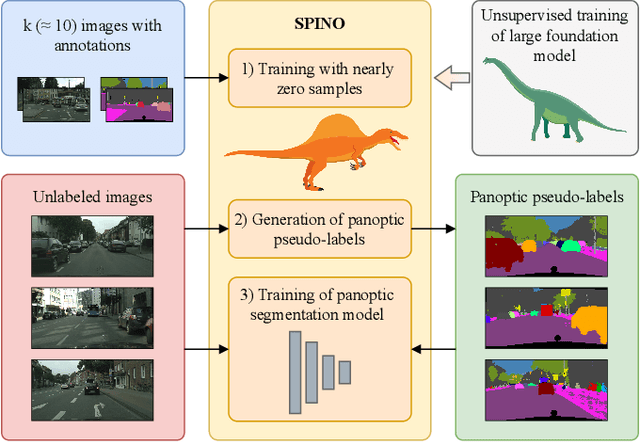
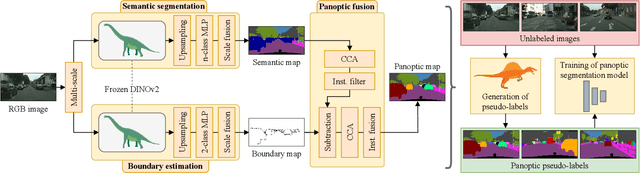
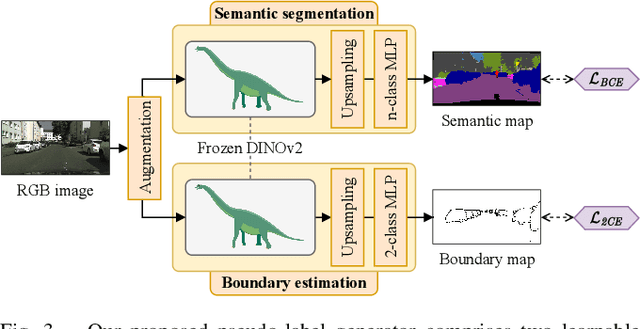
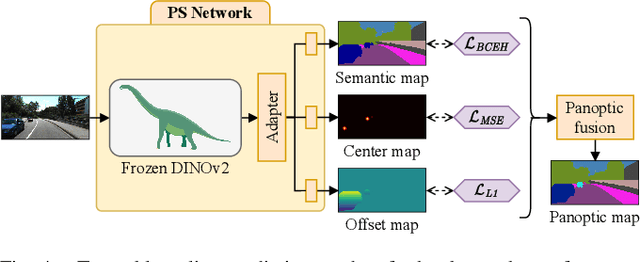
Current state-of-the-art methods for panoptic segmentation require an immense amount of annotated training data that is both arduous and expensive to obtain posing a significant challenge for their widespread adoption. Concurrently, recent breakthroughs in visual representation learning have sparked a paradigm shift leading to the advent of large foundation models that can be trained with completely unlabeled images. In this work, we propose to leverage such task-agnostic image features to enable few-shot panoptic segmentation by presenting Segmenting Panoptic Information with Nearly 0 labels (SPINO). In detail, our method combines a DINOv2 backbone with lightweight network heads for semantic segmentation and boundary estimation. We show that our approach, albeit being trained with only ten annotated images, predicts high-quality pseudo-labels that can be used with any existing panoptic segmentation method. Notably, we demonstrate that SPINO achieves competitive results compared to fully supervised baselines while using less than 0.3% of the ground truth labels, paving the way for learning complex visual recognition tasks leveraging foundation models. To illustrate its general applicability, we further deploy SPINO on real-world robotic vision systems for both outdoor and indoor environments. To foster future research, we make the code and trained models publicly available at http://spino.cs.uni-freiburg.de.