 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DenseMP: Unsupervised Dense Pre-training for Few-shot Medical Image Segmentation
Jul 13, 2023
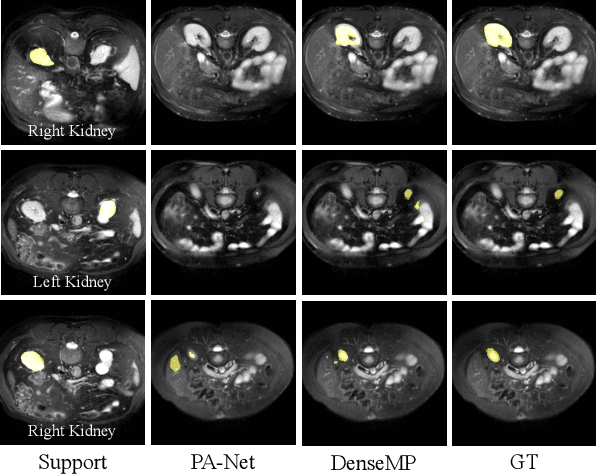


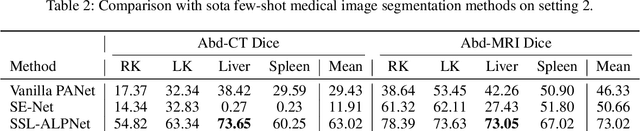
Few-shot medical image semantic segmentation is of paramount importance in the domain of medical image analysis. However, existing methodologies grapple with the challenge of data scarcity during the training phase, leading to over-fitting. To mitigate this issue, we introduce a novel Unsupervised Dense Few-shot Medical Image Segmentation Model Training Pipeline (DenseMP) that capitalizes on unsupervised dense pre-training. DenseMP is composed of two distinct stages: (1) segmentation-aware dense contrastive pre-training, and (2) few-shot-aware superpixel guided dense pre-training. These stages collaboratively yield a pre-trained initial model specifically designed for few-shot medical image segmentation, which can subsequently be fine-tuned on the target dataset. Our proposed pipeline significantly enhances the performance of the widely recognized few-shot segmentation model, PA-Net, achieving state-of-the-art results on the Abd-CT and Abd-MRI datasets. Code will be released after acceptance.
Stimulating the Diffusion Model for Image Denoising via Adaptive Embedding and Ensembling
Jul 08, 2023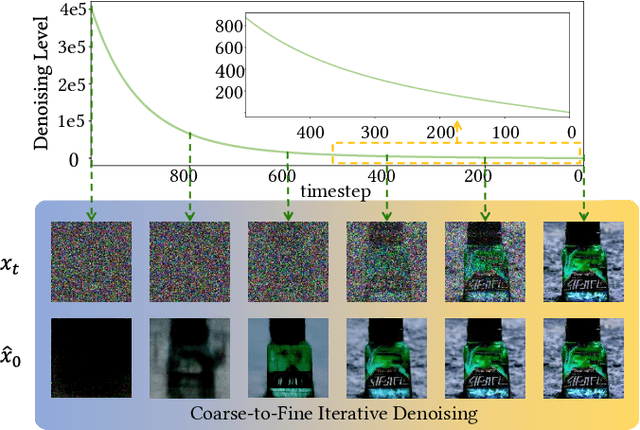
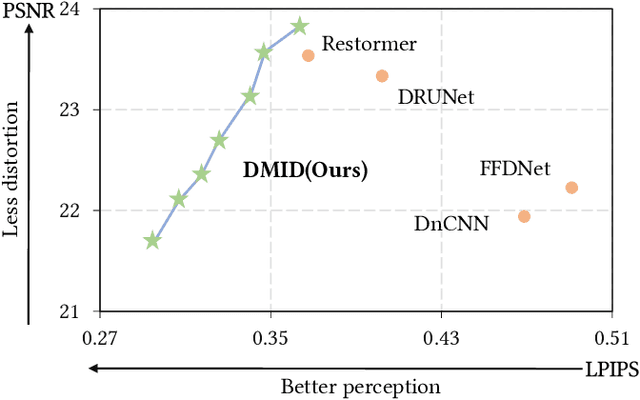
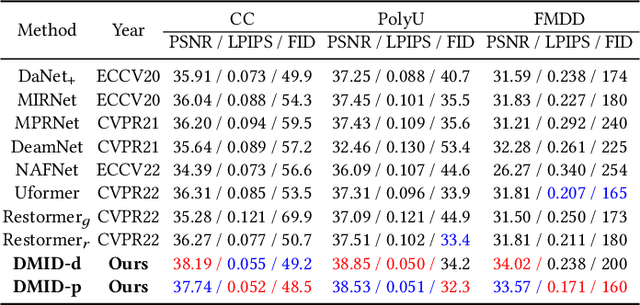
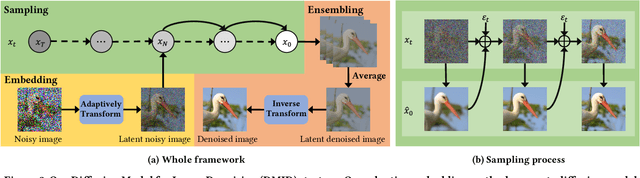
Image denoising is a fundamental problem in computational photography, where achieving high-quality perceptual performance with low distortion is highly demanding. Current methods either struggle with perceptual performance or suffer from significant distortion. Recently, the emerging diffusion model achieves state-of-the-art performance in various tasks, and its denoising mechanism demonstrates great potential for image denoising. However, stimulating diffusion models for image denoising is not straightforward and requires solving several critical problems. On the one hand, the input inconsistency hinders the connection of diffusion models and image denoising. On the other hand, the content inconsistency between the generated image and the desired denoised image introduces additional distortion. To tackle these problems, we present a novel strategy called Diffusion Model for Image Denoising (DMID) by understanding and rethinking the diffusion model from a denoising perspective. Our DMID strategy includes an adaptive embedding method that embeds the noisy image into a pre-trained diffusion model, and an adaptive ensembling method that reduces distortion in the denoised image. Our DMID strategy achieves state-of-the-art performance on all distortion-based and perceptual metrics, for both Gaussian and real-world image denoising.
A Study of Forward-Forward Algorithm for Self-Supervised Learning
Sep 21, 2023
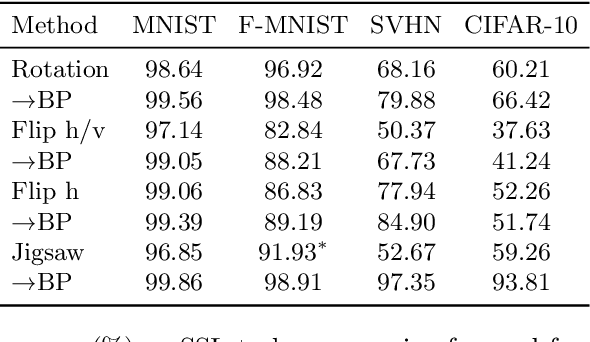
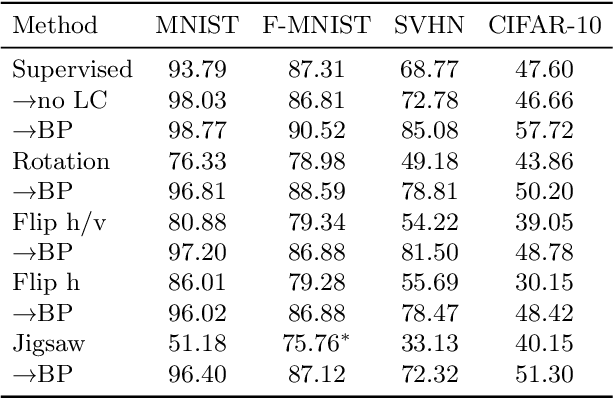

Self-supervised representation learning has seen remarkable progress in the last few years, with some of the recent methods being able to learn useful image representations without labels. These methods are trained using backpropagation, the de facto standard. Recently, Geoffrey Hinton proposed the forward-forward algorithm as an alternative training method. It utilizes two forward passes and a separate loss function for each layer to train the network without backpropagation. In this study, for the first time, we study the performance of forward-forward vs. backpropagation for self-supervised representation learning and provide insights into the learned representation spaces. Our benchmark employs four standard datasets, namely MNIST, F-MNIST, SVHN and CIFAR-10, and three commonly used self-supervised representation learning techniques, namely rotation, flip and jigsaw. Our main finding is that while the forward-forward algorithm performs comparably to backpropagation during (self-)supervised training, the transfer performance is significantly lagging behind in all the studied settings. This may be caused by a combination of factors, including having a loss function for each layer and the way the supervised training is realized in the forward-forward paradigm. In comparison to backpropagation, the forward-forward algorithm focuses more on the boundaries and drops part of the information unnecessary for making decisions which harms the representation learning goal. Further investigation and research are necessary to stabilize the forward-forward strategy for self-supervised learning, to work beyond the datasets and configurations demonstrated by Geoffrey Hinton.
ZS6D: Zero-shot 6D Object Pose Estimation using Vision Transformers
Sep 21, 2023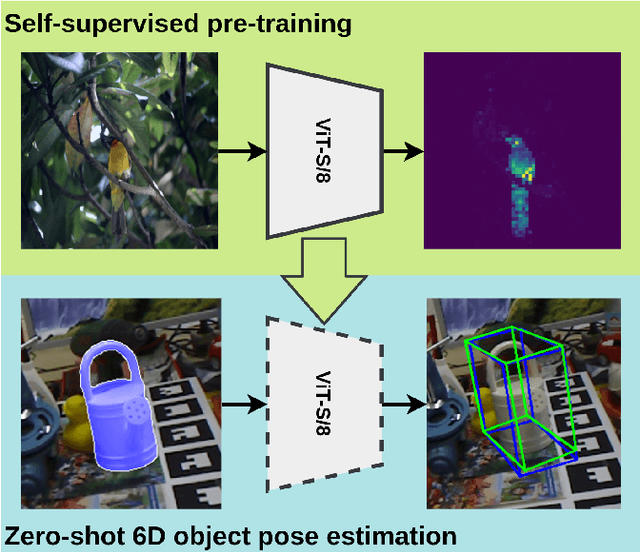
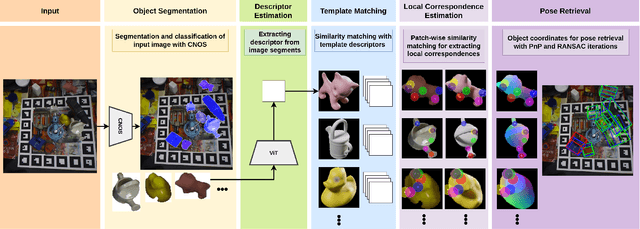

As robotic systems increasingly encounter complex and unconstrained real-world scenarios, there is a demand to recognize diverse objects. The state-of-the-art 6D object pose estimation methods rely on object-specific training and therefore do not generalize to unseen objects. Recent novel object pose estimation methods are solving this issue using task-specific fine-tuned CNNs for deep template matching. This adaptation for pose estimation still requires expensive data rendering and training procedures. MegaPose for example is trained on a dataset consisting of two million images showing 20,000 different objects to reach such generalization capabilities. To overcome this shortcoming we introduce ZS6D, for zero-shot novel object 6D pose estimation. Visual descriptors, extracted using pre-trained Vision Transformers (ViT), are used for matching rendered templates against query images of objects and for establishing local correspondences. These local correspondences enable deriving geometric correspondences and are used for estimating the object's 6D pose with RANSAC-based PnP. This approach showcases that the image descriptors extracted by pre-trained ViTs are well-suited to achieve a notable improvement over two state-of-the-art novel object 6D pose estimation methods, without the need for task-specific fine-tuning. Experiments are performed on LMO, YCBV, and TLESS. In comparison to one of the two methods we improve the Average Recall on all three datasets and compared to the second method we improve on two datasets.
Learned Visual Features to Textual Explanations
Sep 01, 2023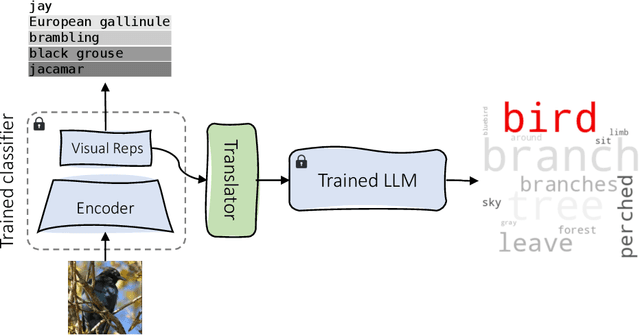

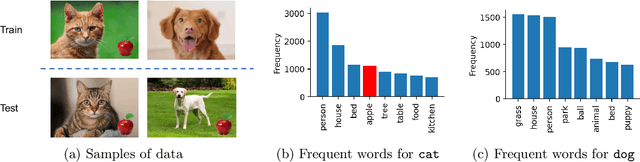

Interpreting the learned features of vision models has posed a longstanding challenge in the field of machine learning. To address this issue, we propose a novel method that leverages the capabilities of large language models (LLMs) to interpret the learned features of pre-trained image classifiers. Our method, called TExplain, tackles this task by training a neural network to establish a connection between the feature space of image classifiers and LLMs. Then, during inference, our approach generates a vast number of sentences to explain the features learned by the classifier for a given image. These sentences are then used to extract the most frequent words, providing a comprehensive understanding of the learned features and patterns within the classifier. Our method, for the first time, utilizes these frequent words corresponding to a visual representation to provide insights into the decision-making process of the independently trained classifier, enabling the detection of spurious correlations, biases, and a deeper comprehension of its behavior. To validate the effectiveness of our approach, we conduct experiments on diverse datasets, including ImageNet-9L and Waterbirds. The results demonstrate the potential of our method to enhance the interpretability and robustness of image classifiers.
A skeletonization algorithm for gradient-based optimization
Sep 05, 2023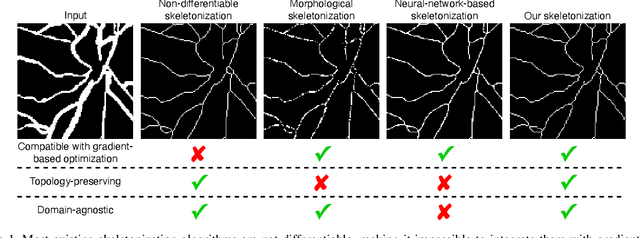
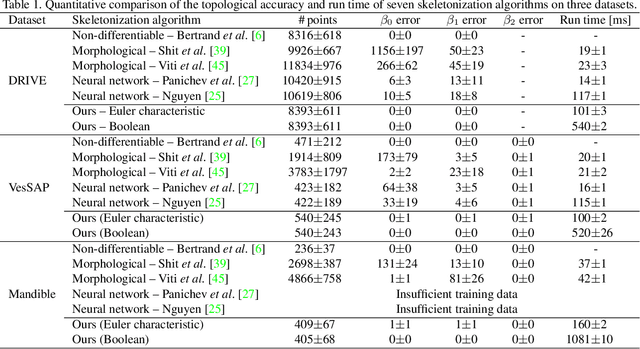
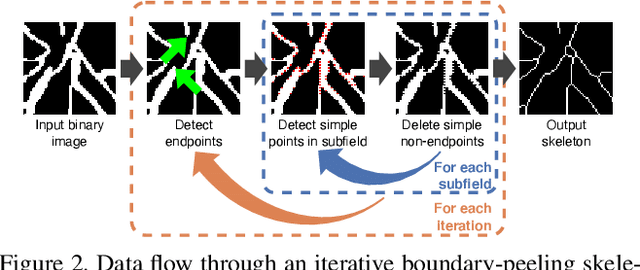
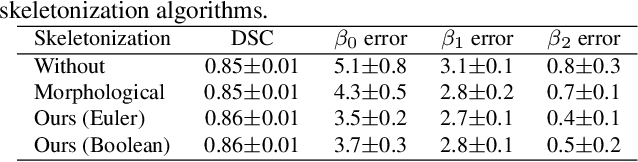
The skeleton of a digital image is a compact representation of its topology, geometry, and scale. It has utility in many computer vision applications, such as image description, segmentation, and registration. However, skeletonization has only seen limited use in contemporary deep learning solutions. Most existing skeletonization algorithms are not differentiable, making it impossible to integrate them with gradient-based optimization. Compatible algorithms based on morphological operations and neural networks have been proposed, but their results often deviate from the geometry and topology of the true medial axis. This work introduces the first three-dimensional skeletonization algorithm that is both compatible with gradient-based optimization and preserves an object's topology. Our method is exclusively based on matrix additions and multiplications, convolutional operations, basic non-linear functions, and sampling from a uniform probability distribution, allowing it to be easily implemented in any major deep learning library. In benchmarking experiments, we prove the advantages of our skeletonization algorithm compared to non-differentiable, morphological, and neural-network-based baselines. Finally, we demonstrate the utility of our algorithm by integrating it with two medical image processing applications that use gradient-based optimization: deep-learning-based blood vessel segmentation, and multimodal registration of the mandible in computed tomography and magnetic resonance images.
DWA: Differential Wavelet Amplifier for Image Super-Resolution
Jul 10, 2023
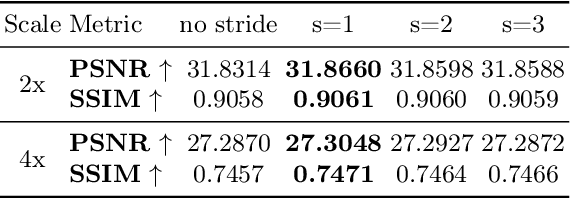
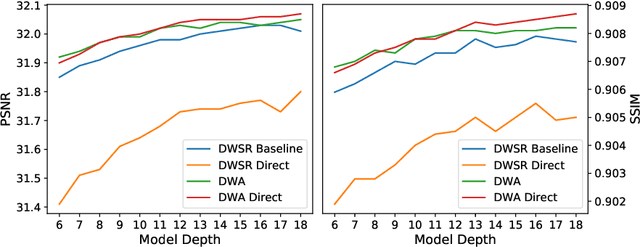
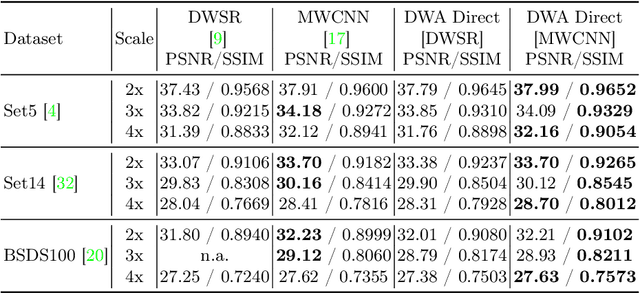
This work introduces Differential Wavelet Amplifier (DWA), a drop-in module for wavelet-based image Super-Resolution (SR). DWA invigorates an approach recently receiving less attention, namely Discrete Wavelet Transformation (DWT). DWT enables an efficient image representation for SR and reduces the spatial area of its input by a factor of 4, the overall model size, and computation cost, framing it as an attractive approach for sustainable ML. Our proposed DWA model improves wavelet-based SR models by leveraging the difference between two convolutional filters to refine relevant feature extraction in the wavelet domain, emphasizing local contrasts and suppressing common noise in the input signals. We show its effectiveness by integrating it into existing SR models, e.g., DWSR and MWCNN, and demonstrate a clear improvement in classical SR tasks. Moreover, DWA enables a direct application of DWSR and MWCNN to input image space, reducing the DWT representation channel-wise since it omits traditional DWT.
Software multiplataforma para a segmentação de vasos sanguíneos em imagens da retina
Aug 30, 2023In this work, we utilize image segmentation to visually identify blood vessels in retinal examination images. This process is typically carried out manually. However, we can employ heuristic methods and machine learning to automate or at least expedite the process. In this context, we propose a cross-platform, open-source, and responsive software that allows users to manually segment a retinal image. The purpose is to use the user-segmented image to retrain machine learning algorithms, thereby enhancing future automated segmentation results. Moreover, the software also incorporates and applies certain image filters established in the literature to improve vessel visualization. We propose the first solution of this kind in the literature. This is the inaugural integrated software that embodies the aforementioned attributes: open-source, responsive, and cross-platform. It offers a comprehensive solution encompassing manual vessel segmentation, as well as the automated execution of classification algorithms to refine predictive models.
Bridging Vision and Language Encoders: Parameter-Efficient Tuning for Referring Image Segmentation
Jul 21, 2023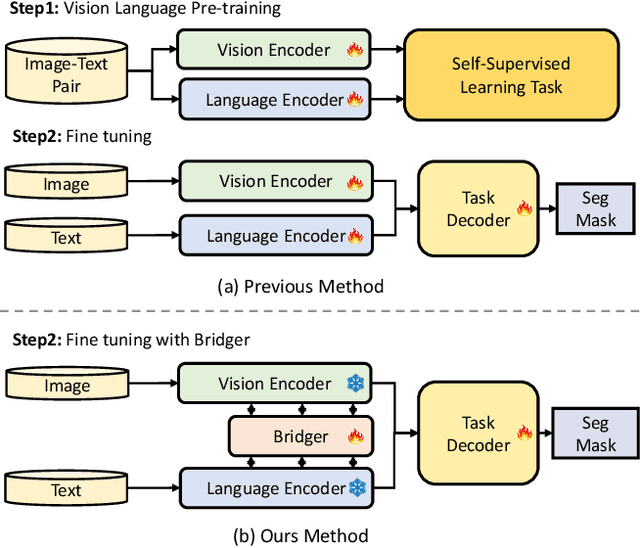
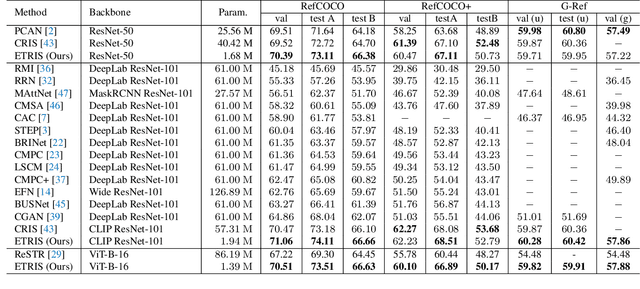
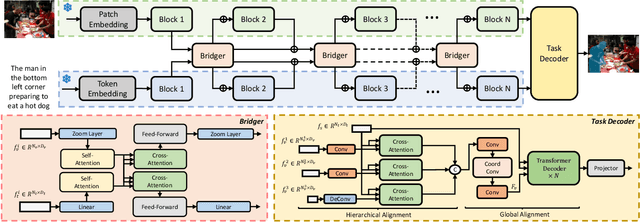
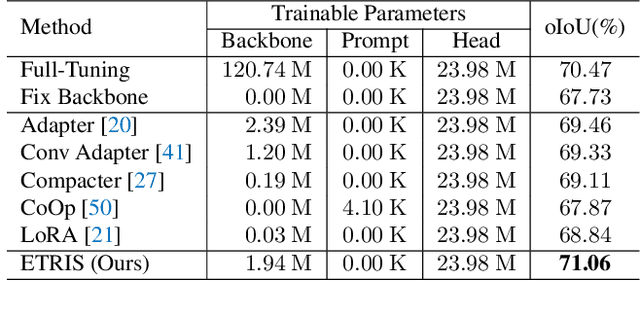
Parameter Efficient Tuning (PET) has gained attention for reducing the number of parameters while maintaining performance and providing better hardware resource savings, but few studies investigate dense prediction tasks and interaction between modalities. In this paper, we do an investigation of efficient tuning problems on referring image segmentation. We propose a novel adapter called Bridger to facilitate cross-modal information exchange and inject task-specific information into the pre-trained model. We also design a lightweight decoder for image segmentation. Our approach achieves comparable or superior performance with only 1.61\% to 3.38\% backbone parameter updates, evaluated on challenging benchmarks. The code is available at \url{https://github.com/kkakkkka/ETRIS}.
Toward Defensive Letter Design
Sep 04, 2023


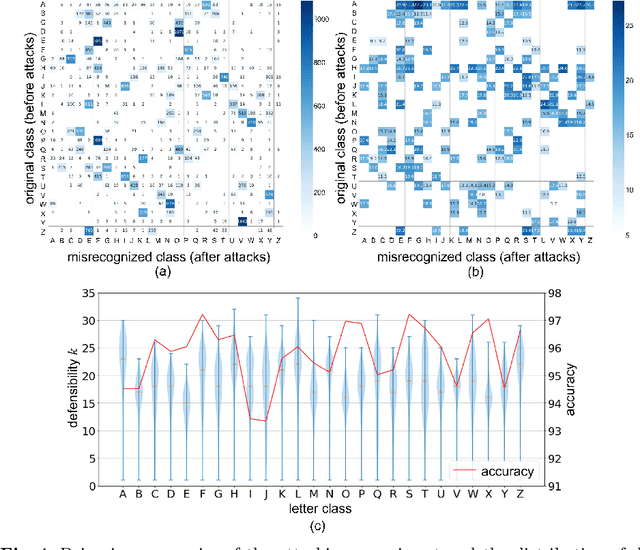
A major approach for defending against adversarial attacks aims at controlling only image classifiers to be more resilient, and it does not care about visual objects, such as pandas and cars, in images. This means that visual objects themselves cannot take any defensive actions, and they are still vulnerable to adversarial attacks. In contrast, letters are artificial symbols, and we can freely control their appearance unless losing their readability. In other words, we can make the letters more defensive to the attacks. This paper poses three research questions related to the adversarial vulnerability of letter images: (1) How defensive are the letters against adversarial attacks? (2) Can we estimate how defensive a given letter image is before attacks? (3) Can we control the letter images to be more defensive against adversarial attacks? For answering the first and second questions, we measure the defensibility of letters by employing Iterative Fast Gradient Sign Method (I-FGSM) and then build a deep regression model for estimating the defensibility of each letter image. We also propose a two-step method based on a generative adversarial network (GAN) for generating character images with higher defensibility, which solves the third research question.