 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SparseSwin: Swin Transformer with Sparse Transformer Block
Sep 11, 2023


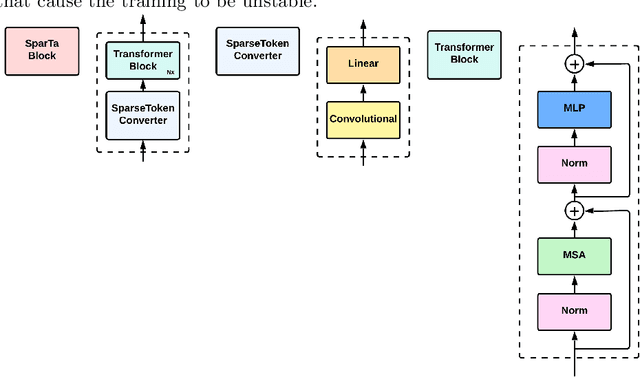
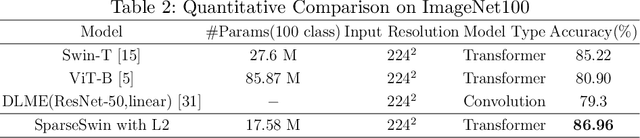
Advancements in computer vision research have put transformer architecture as the state of the art in computer vision tasks. One of the known drawbacks of the transformer architecture is the high number of parameters, this can lead to a more complex and inefficient algorithm. This paper aims to reduce the number of parameters and in turn, made the transformer more efficient. We present Sparse Transformer (SparTa) Block, a modified transformer block with an addition of a sparse token converter that reduces the number of tokens used. We use the SparTa Block inside the Swin T architecture (SparseSwin) to leverage Swin capability to downsample its input and reduce the number of initial tokens to be calculated. The proposed SparseSwin model outperforms other state of the art models in image classification with an accuracy of 86.96%, 97.43%, and 85.35% on the ImageNet100, CIFAR10, and CIFAR100 datasets respectively. Despite its fewer parameters, the result highlights the potential of a transformer architecture using a sparse token converter with a limited number of tokens to optimize the use of the transformer and improve its performance.
Exploration and Comparison of Deep Learning Architectures to Predict Brain Response to Realistic Pictures
Sep 11, 2023We present an exploration of machine learning architectures for predicting brain responses to realistic images on occasion of the Algonauts Challenge 2023. Our research involved extensive experimentation with various pretrained models. Initially, we employed simpler models to predict brain activity but gradually introduced more complex architectures utilizing available data and embeddings generated by large-scale pre-trained models. We encountered typical difficulties related to machine learning problems, e.g. regularization and overfitting, as well as issues specific to the challenge, such as difficulty in combining multiple input encodings, as well as the high dimensionality, unclear structure, and noisy nature of the output. To overcome these issues we tested single edge 3D position-based, multi-region of interest (ROI) and hemisphere predictor models, but we found that employing multiple simple models, each dedicated to a ROI in each hemisphere of the brain of each subject, yielded the best results - a single fully connected linear layer with image embeddings generated by CLIP as input. While we surpassed the challenge baseline, our results fell short of establishing a robust association with the data.
Unified Concept Editing in Diffusion Models
Aug 25, 2023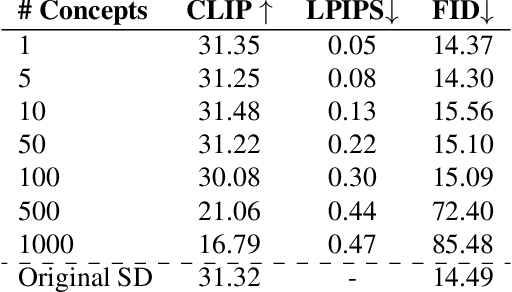
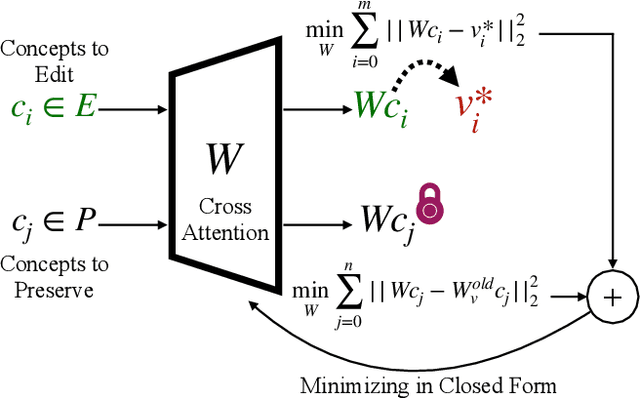
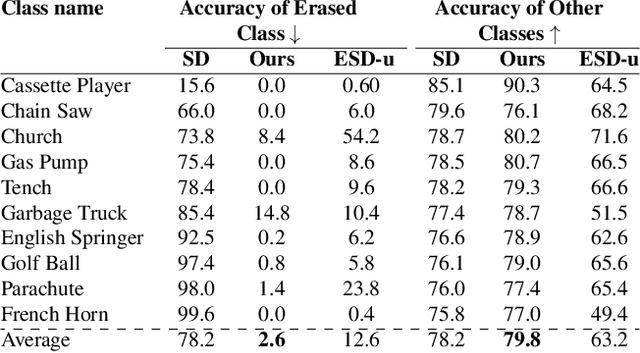

Text-to-image models suffer from various safety issues that may limit their suitability for deployment. Previous methods have separately addressed individual issues of bias, copyright, and offensive content in text-to-image models. However, in the real world, all of these issues appear simultaneously in the same model. We present a method that tackles all issues with a single approach. Our method, Unified Concept Editing (UCE), edits the model without training using a closed-form solution, and scales seamlessly to concurrent edits on text-conditional diffusion models. We demonstrate scalable simultaneous debiasing, style erasure, and content moderation by editing text-to-image projections, and we present extensive experiments demonstrating improved efficacy and scalability over prior work. Our code is available at https://unified.baulab.info
AdvisingNets: Learning to Distinguish Correct and Wrong Classifications via Nearest-Neighbor Explanations
Aug 25, 2023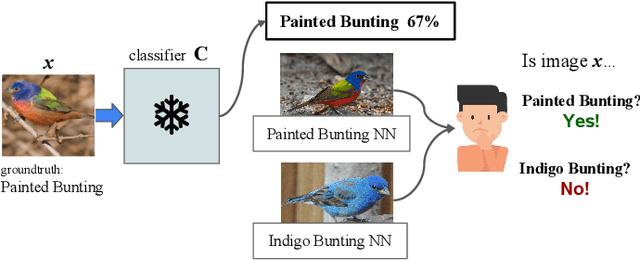
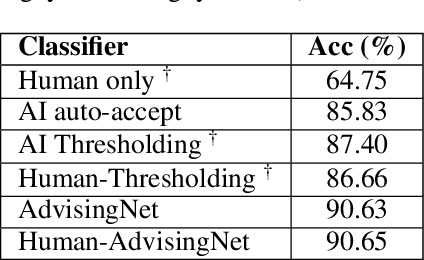
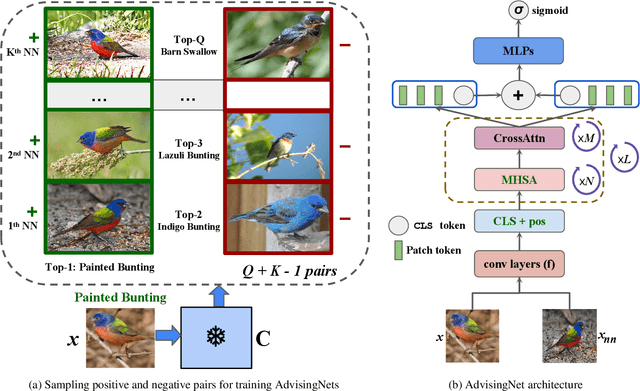
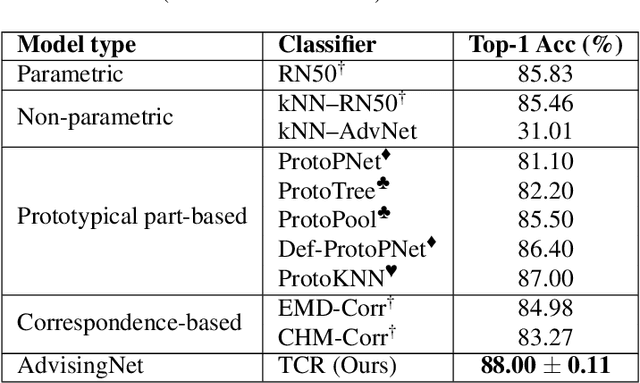
Besides providing insights into how an image classifier makes its predictions, nearest-neighbor examples also help humans make more accurate decisions. Yet, leveraging this type of explanation to improve both human-AI team accuracy and classifier's accuracy remains an open question. In this paper, we aim to increase both types of accuracy by (1) comparing the input image with post-hoc, nearest-neighbor explanations using a novel network (AdvisingNet), and (2) employing a new reranking algorithm. Over different baseline models, our method consistently improves the image classification accuracy on CUB-200 and Cars-196 datasets. Interestingly, we also reach the state-of-the-art human-AI team accuracy on CUB-200 where both humans and an AdvisingNet make decisions on complementary subsets of images.
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Jul 04, 2023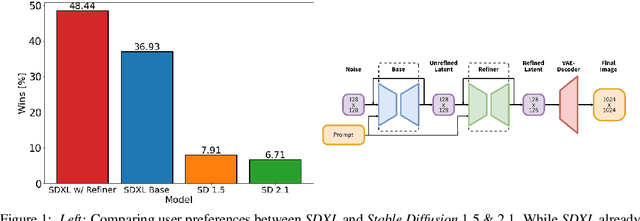

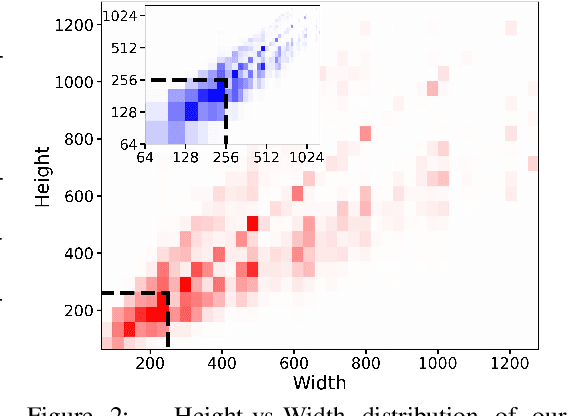
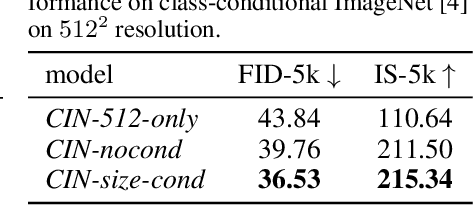
We present SDXL, a latent diffusion model for text-to-image synthesis. Compared to previous versions of Stable Diffusion, SDXL leverages a three times larger UNet backbone: The increase of model parameters is mainly due to more attention blocks and a larger cross-attention context as SDXL uses a second text encoder. We design multiple novel conditioning schemes and train SDXL on multiple aspect ratios. We also introduce a refinement model which is used to improve the visual fidelity of samples generated by SDXL using a post-hoc image-to-image technique. We demonstrate that SDXL shows drastically improved performance compared the previous versions of Stable Diffusion and achieves results competitive with those of black-box state-of-the-art image generators. In the spirit of promoting open research and fostering transparency in large model training and evaluation, we provide access to code and model weights at https://github.com/Stability-AI/generative-models
PromptCrafter: Crafting Text-to-Image Prompt through Mixed-Initiative Dialogue with LLM
Jul 18, 2023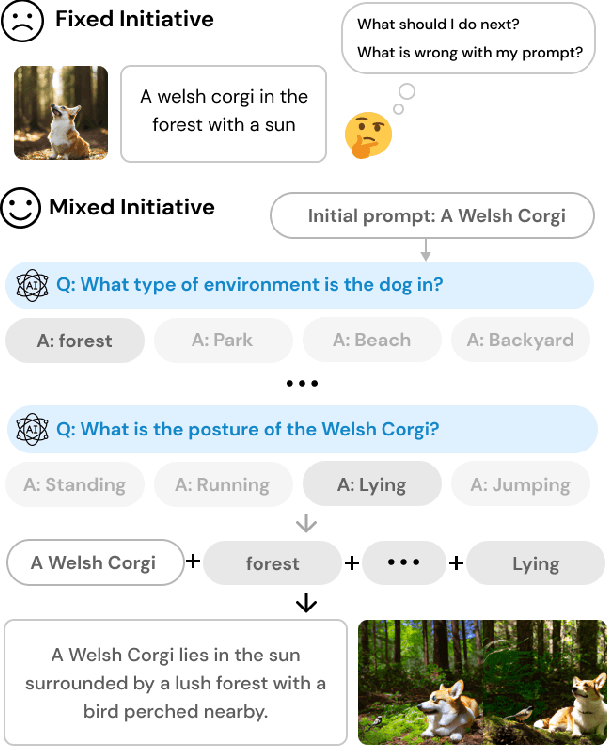
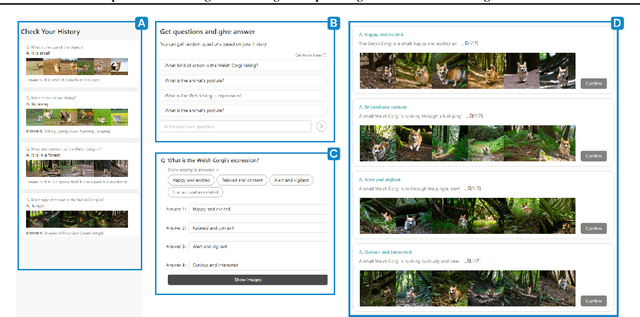
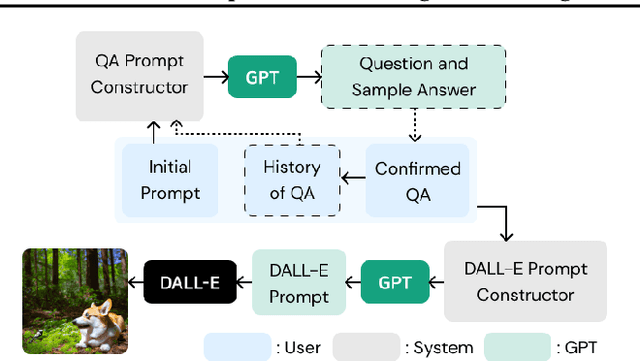
Text-to-image generation model is able to generate images across a diverse range of subjects and styles based on a single prompt. Recent works have proposed a variety of interaction methods that help users understand the capabilities of models and utilize them. However, how to support users to efficiently explore the model's capability and to create effective prompts are still open-ended research questions. In this paper, we present PromptCrafter, a novel mixed-initiative system that allows step-by-step crafting of text-to-image prompt. Through the iterative process, users can efficiently explore the model's capability, and clarify their intent. PromptCrafter also supports users to refine prompts by answering various responses to clarifying questions generated by a Large Language Model. Lastly, users can revert to a desired step by reviewing the work history. In this workshop paper, we discuss the design process of PromptCrafter and our plans for follow-up studies.
Stroke Extraction of Chinese Character Based on Deep Structure Deformable Image Registration
Jul 10, 2023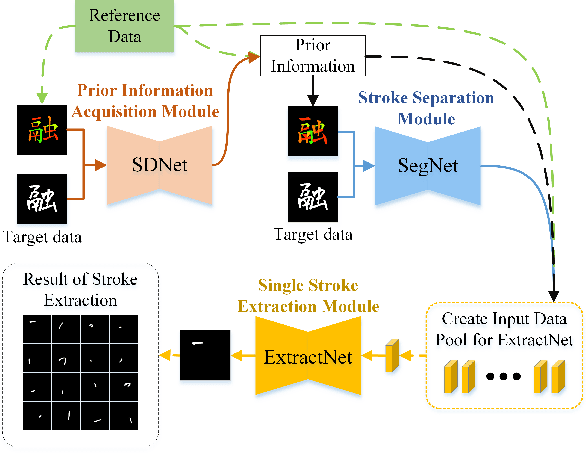
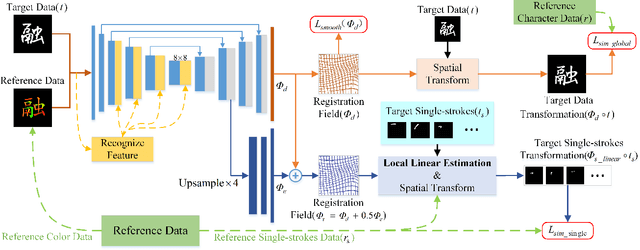
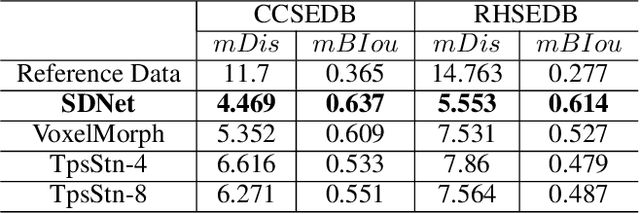
Stroke extraction of Chinese characters plays an important role in the field of character recognition and generation. The most existing character stroke extraction methods focus on image morphological features. These methods usually lead to errors of cross strokes extraction and stroke matching due to rarely using stroke semantics and prior information. In this paper, we propose a deep learning-based character stroke extraction method that takes semantic features and prior information of strokes into consideration. This method consists of three parts: image registration-based stroke registration that establishes the rough registration of the reference strokes and the target as prior information; image semantic segmentation-based stroke segmentation that preliminarily separates target strokes into seven categories; and high-precision extraction of single strokes. In the stroke registration, we propose a structure deformable image registration network to achieve structure-deformable transformation while maintaining the stable morphology of single strokes for character images with complex structures. In order to verify the effectiveness of the method, we construct two datasets respectively for calligraphy characters and regular handwriting characters. The experimental results show that our method strongly outperforms the baselines. Code is available at https://github.com/MengLi-l1/StrokeExtraction.
* 10 pages, 8 figures, published to AAAI-23 (oral)
Solving Quadratic Systems with Full-Rank Matrices Using Sparse or Generative Priors
Sep 16, 2023
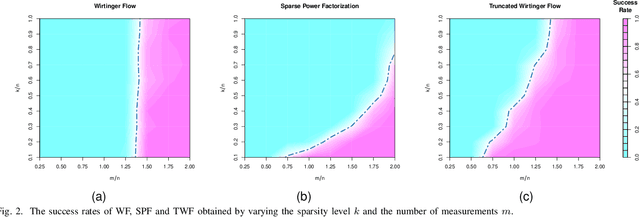

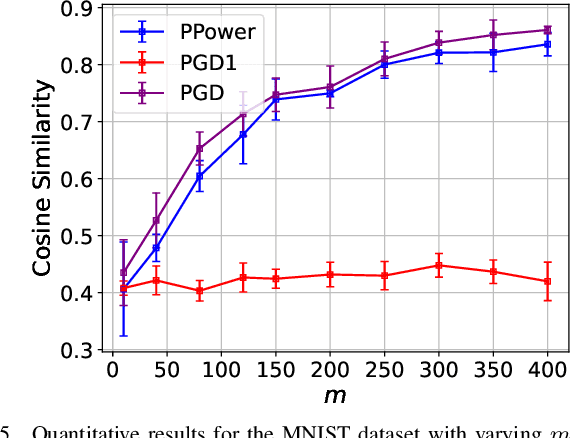
The problem of recovering a signal $\boldsymbol{x} \in \mathbb{R}^n$ from a quadratic system $\{y_i=\boldsymbol{x}^\top\boldsymbol{A}_i\boldsymbol{x},\ i=1,\ldots,m\}$ with full-rank matrices $\boldsymbol{A}_i$ frequently arises in applications such as unassigned distance geometry and sub-wavelength imaging. With i.i.d. standard Gaussian matrices $\boldsymbol{A}_i$, this paper addresses the high-dimensional case where $m\ll n$ by incorporating prior knowledge of $\boldsymbol{x}$. First, we consider a $k$-sparse $\boldsymbol{x}$ and introduce the thresholded Wirtinger flow (TWF) algorithm that does not require the sparsity level $k$. TWF comprises two steps: the spectral initialization that identifies a point sufficiently close to $\boldsymbol{x}$ (up to a sign flip) when $m=O(k^2\log n)$, and the thresholded gradient descent (with a good initialization) that produces a sequence linearly converging to $\boldsymbol{x}$ with $m=O(k\log n)$ measurements. Second, we explore the generative prior, assuming that $\boldsymbol{x}$ lies in the range of an $L$-Lipschitz continuous generative model with $k$-dimensional inputs in an $\ell_2$-ball of radius $r$. We develop the projected gradient descent (PGD) algorithm that also comprises two steps: the projected power method that provides an initial vector with $O\big(\sqrt{\frac{k \log L}{m}}\big)$ $\ell_2$-error given $m=O(k\log(Lnr))$ measurements, and the projected gradient descent that refines the $\ell_2$-error to $O(\delta)$ at a geometric rate when $m=O(k\log\frac{Lrn}{\delta^2})$. Experimental results corroborate our theoretical findings and show that: (i) our approach for the sparse case notably outperforms the existing provable algorithm sparse power factorization; (ii) leveraging the generative prior allows for precise image recovery in the MNIST dataset from a small number of quadratic measurements.
Mitigating Bias: Enhancing Image Classification by Improving Model Explanations
Jul 04, 2023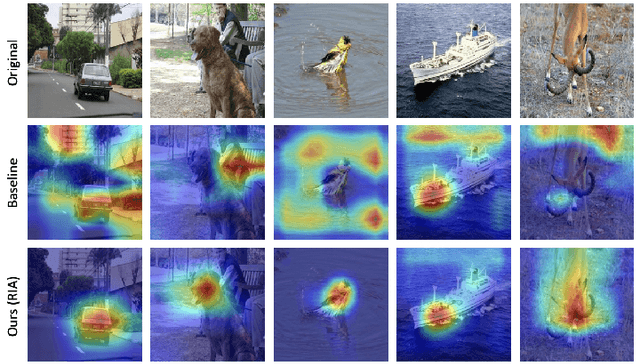
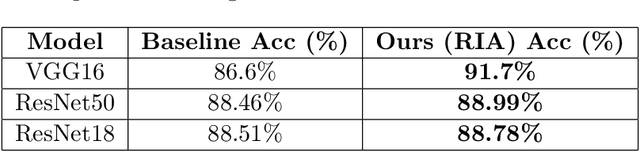
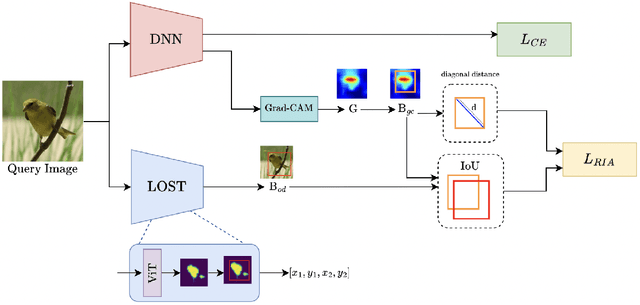

Deep learning models have demonstrated remarkable capabilities in learning complex patterns and concepts from training data. However, recent findings indicate that these models tend to rely heavily on simple and easily discernible features present in the background of images rather than the main concepts or objects they are intended to classify. This phenomenon poses a challenge to image classifiers as the crucial elements of interest in images may be overshadowed. In this paper, we propose a novel approach to address this issue and improve the learning of main concepts by image classifiers. Our central idea revolves around concurrently guiding the model's attention toward the foreground during the classification task. By emphasizing the foreground, which encapsulates the primary objects of interest, we aim to shift the focus of the model away from the dominant influence of the background. To accomplish this, we introduce a mechanism that encourages the model to allocate sufficient attention to the foreground. We investigate various strategies, including modifying the loss function or incorporating additional architectural components, to enable the classifier to effectively capture the primary concept within an image. Additionally, we explore the impact of different foreground attention mechanisms on model performance and provide insights into their effectiveness. Through extensive experimentation on benchmark datasets, we demonstrate the efficacy of our proposed approach in improving the classification accuracy of image classifiers. Our findings highlight the importance of foreground attention in enhancing model understanding and representation of the main concepts within images. The results of this study contribute to advancing the field of image classification and provide valuable insights for developing more robust and accurate deep-learning models.
Unveiling Camouflage: A Learnable Fourier-based Augmentation for Camouflaged Object Detection and Instance Segmentation
Aug 29, 2023
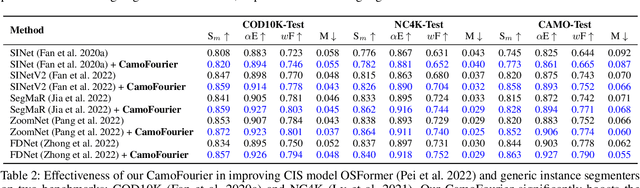
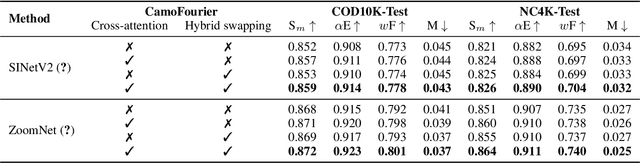

Camouflaged object detection (COD) and camouflaged instance segmentation (CIS) aim to recognize and segment objects that are blended into their surroundings, respectively. While several deep neural network models have been proposed to tackle those tasks, augmentation methods for COD and CIS have not been thoroughly explored. Augmentation strategies can help improve the performance of models by increasing the size and diversity of the training data and exposing the model to a wider range of variations in the data. Besides, we aim to automatically learn transformations that help to reveal the underlying structure of camouflaged objects and allow the model to learn to better identify and segment camouflaged objects. To achieve this, we propose a learnable augmentation method in the frequency domain for COD and CIS via Fourier transform approach, dubbed CamoFourier. Our method leverages a conditional generative adversarial network and cross-attention mechanism to generate a reference image and an adaptive hybrid swapping with parameters to mix the low-frequency component of the reference image and the high-frequency component of the input image. This approach aims to make camouflaged objects more visible for detection and segmentation models. Without bells and whistles, our proposed augmentation method boosts the performance of camouflaged object detectors and camouflaged instance segmenters by large margins.