 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Implicit Image Function for Efficient Arbitrary-Scale Image Representation
Jun 21, 2023
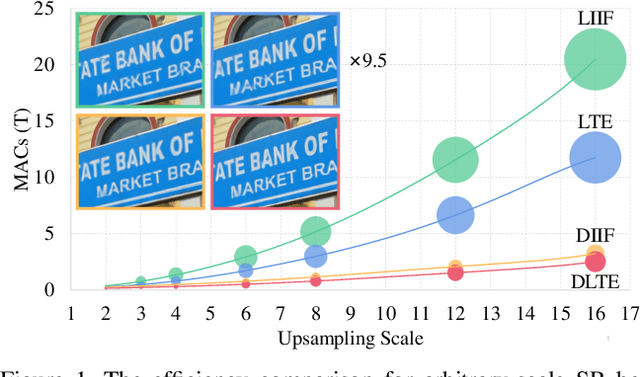
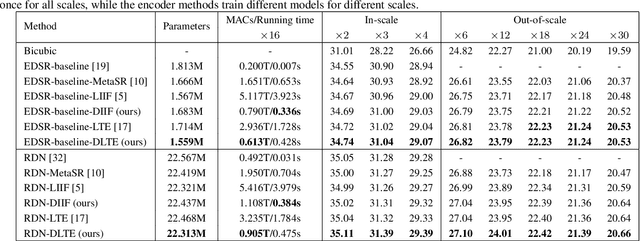

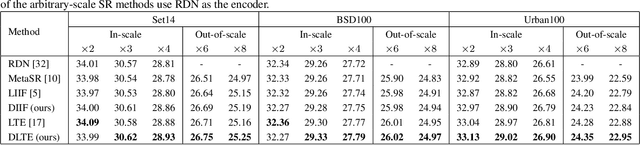
Recent years have witnessed the remarkable success of implicit neural representation methods. The recent work Local Implicit Image Function (LIIF) has achieved satisfactory performance for continuous image representation, where pixel values are inferred from a neural network in a continuous spatial domain. However, the computational cost of such implicit arbitrary-scale super-resolution (SR) methods increases rapidly as the scale factor increases, which makes arbitrary-scale SR time-consuming. In this paper, we propose Dynamic Implicit Image Function (DIIF), which is a fast and efficient method to represent images with arbitrary resolution. Instead of taking an image coordinate and the nearest 2D deep features as inputs to predict its pixel value, we propose a coordinate grouping and slicing strategy, which enables the neural network to perform decoding from coordinate slices to pixel value slices. We further propose a Coarse-to-Fine Multilayer Perceptron (C2F-MLP) to perform decoding with dynamic coordinate slicing, where the number of coordinates in each slice varies as the scale factor varies. With dynamic coordinate slicing, DIIF significantly reduces the computational cost when encountering arbitrary-scale SR. Experimental results demonstrate that DIIF can be integrated with implicit arbitrary-scale SR methods and achieves SOTA SR performance with significantly superior computational efficiency, thereby opening a path for real-time arbitrary-scale image representation. Our code can be found at https://github.com/HeZongyao/DIIF.
HQG-Net: Unpaired Medical Image Enhancement with High-Quality Guidance
Jul 15, 2023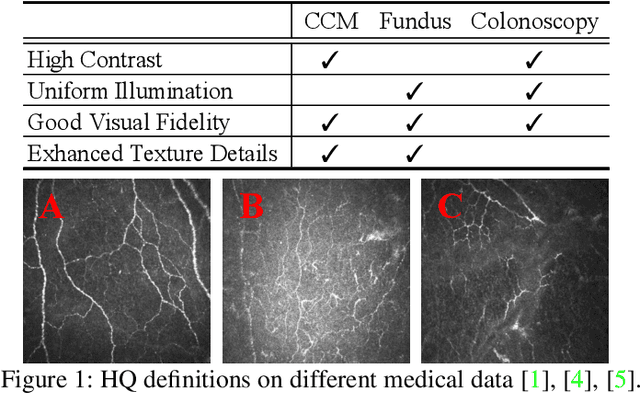
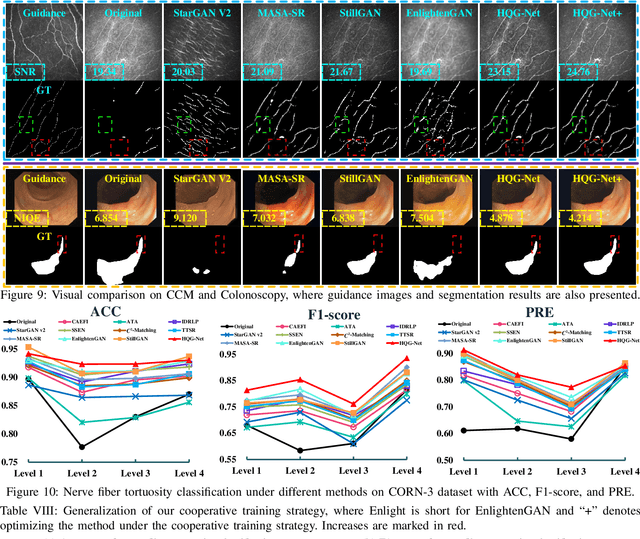
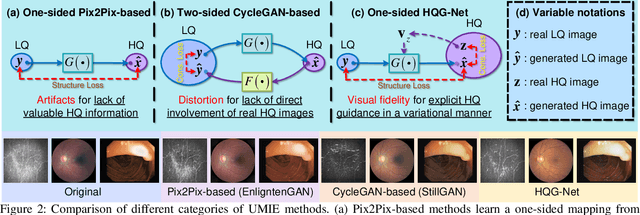
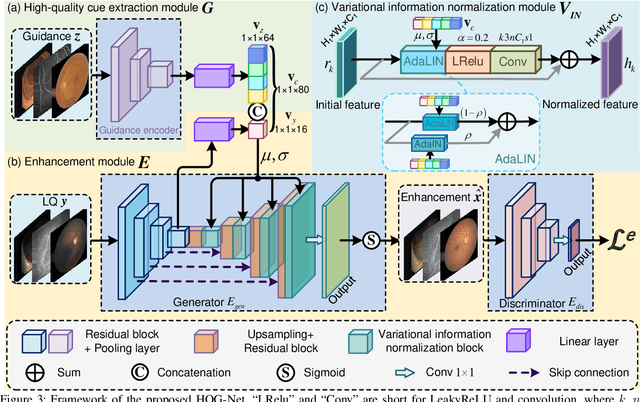
Unpaired Medical Image Enhancement (UMIE) aims to transform a low-quality (LQ) medical image into a high-quality (HQ) one without relying on paired images for training. While most existing approaches are based on Pix2Pix/CycleGAN and are effective to some extent, they fail to explicitly use HQ information to guide the enhancement process, which can lead to undesired artifacts and structural distortions. In this paper, we propose a novel UMIE approach that avoids the above limitation of existing methods by directly encoding HQ cues into the LQ enhancement process in a variational fashion and thus model the UMIE task under the joint distribution between the LQ and HQ domains. Specifically, we extract features from an HQ image and explicitly insert the features, which are expected to encode HQ cues, into the enhancement network to guide the LQ enhancement with the variational normalization module. We train the enhancement network adversarially with a discriminator to ensure the generated HQ image falls into the HQ domain. We further propose a content-aware loss to guide the enhancement process with wavelet-based pixel-level and multi-encoder-based feature-level constraints. Additionally, as a key motivation for performing image enhancement is to make the enhanced images serve better for downstream tasks, we propose a bi-level learning scheme to optimize the UMIE task and downstream tasks cooperatively, helping generate HQ images both visually appealing and favorable for downstream tasks. Experiments on three medical datasets, including two newly collected datasets, verify that the proposed method outperforms existing techniques in terms of both enhancement quality and downstream task performance. We will make the code and the newly collected datasets publicly available for community study.
PRISTA-Net: Deep Iterative Shrinkage Thresholding Network for Coded Diffraction Patterns Phase Retrieval
Sep 08, 2023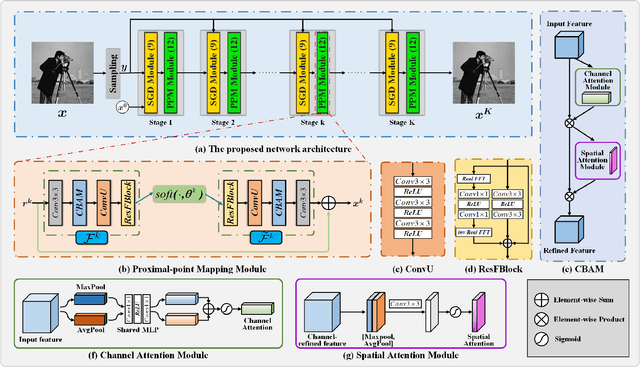

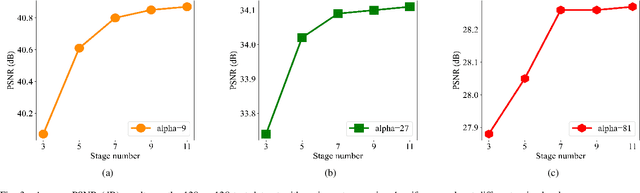

The problem of phase retrieval (PR) involves recovering an unknown image from limited amplitude measurement data and is a challenge nonlinear inverse problem in computational imaging and image processing. However, many of the PR methods are based on black-box network models that lack interpretability and plug-and-play (PnP) frameworks that are computationally complex and require careful parameter tuning. To address this, we have developed PRISTA-Net, a deep unfolding network (DUN) based on the first-order iterative shrinkage thresholding algorithm (ISTA). This network utilizes a learnable nonlinear transformation to address the proximal-point mapping sub-problem associated with the sparse priors, and an attention mechanism to focus on phase information containing image edges, textures, and structures. Additionally, the fast Fourier transform (FFT) is used to learn global features to enhance local information, and the designed logarithmic-based loss function leads to significant improvements when the noise level is low. All parameters in the proposed PRISTA-Net framework, including the nonlinear transformation, threshold parameters, and step size, are learned end-to-end instead of being manually set. This method combines the interpretability of traditional methods with the fast inference ability of deep learning and is able to handle noise at each iteration during the unfolding stage, thus improving recovery quality. Experiments on Coded Diffraction Patterns (CDPs) measurements demonstrate that our approach outperforms the existing state-of-the-art methods in terms of qualitative and quantitative evaluations. Our source codes are available at \emph{https://github.com/liuaxou/PRISTA-Net}.
Hierarchical Open-vocabulary Universal Image Segmentation
Jul 03, 2023
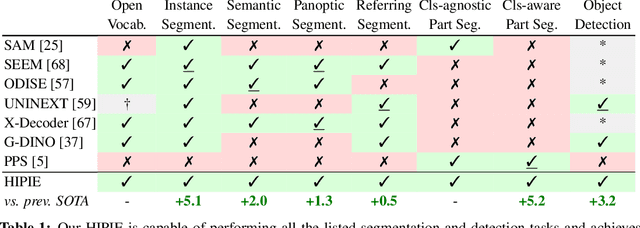
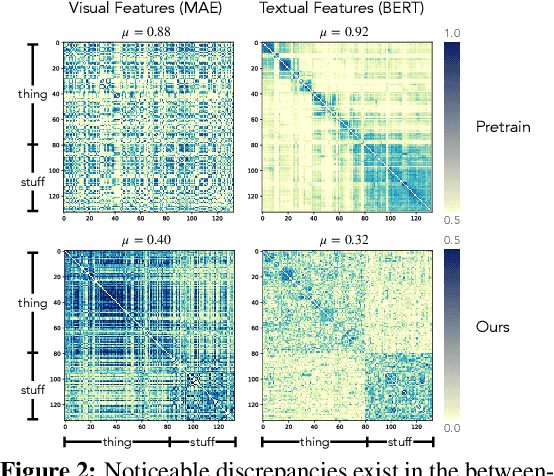
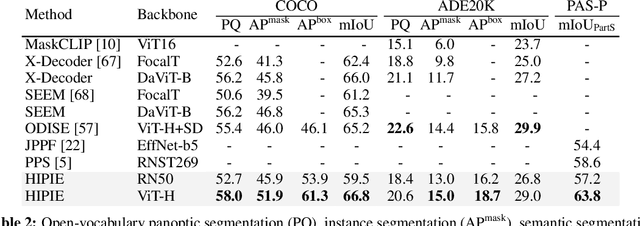
Open-vocabulary image segmentation aims to partition an image into semantic regions according to arbitrary text descriptions. However, complex visual scenes can be naturally decomposed into simpler parts and abstracted at multiple levels of granularity, introducing inherent segmentation ambiguity. Unlike existing methods that typically sidestep this ambiguity and treat it as an external factor, our approach actively incorporates a hierarchical representation encompassing different semantic-levels into the learning process. We propose a decoupled text-image fusion mechanism and representation learning modules for both "things" and "stuff".1 Additionally, we systematically examine the differences that exist in the textual and visual features between these types of categories. Our resulting model, named HIPIE, tackles HIerarchical, oPen-vocabulary, and unIvErsal segmentation tasks within a unified framework. Benchmarked on over 40 datasets, e.g., ADE20K, COCO, Pascal-VOC Part, RefCOCO/RefCOCOg, ODinW and SeginW, HIPIE achieves the state-of-the-art results at various levels of image comprehension, including semantic-level (e.g., semantic segmentation), instance-level (e.g., panoptic/referring segmentation and object detection), as well as part-level (e.g., part/subpart segmentation) tasks. Our code is released at https://github.com/berkeley-hipie/HIPIE.
Dual-view Curricular Optimal Transport for Cross-lingual Cross-modal Retrieval
Sep 11, 2023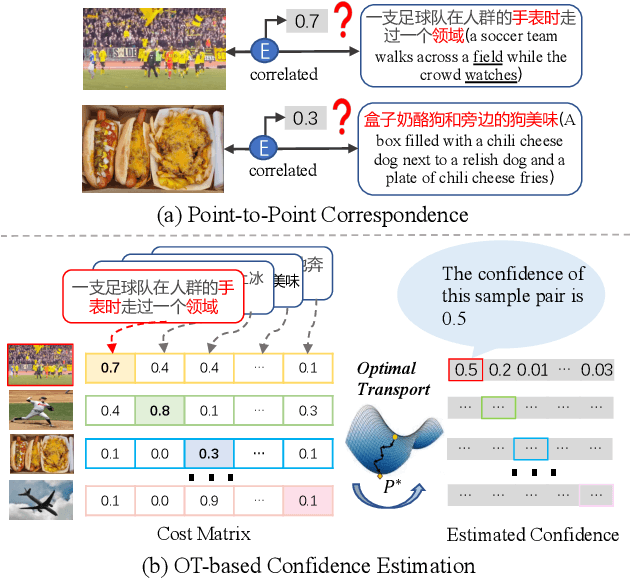
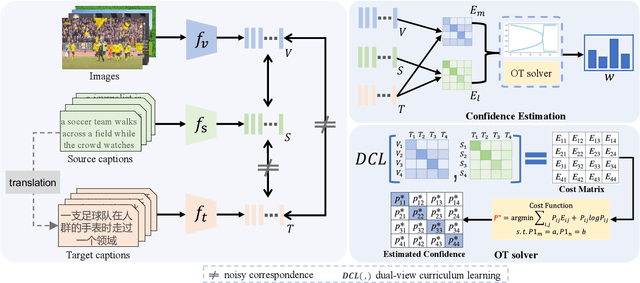
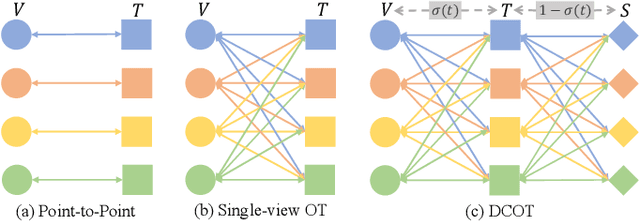
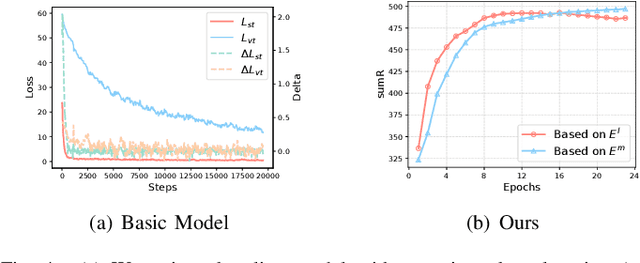
Current research on cross-modal retrieval is mostly English-oriented, as the availability of a large number of English-oriented human-labeled vision-language corpora. In order to break the limit of non-English labeled data, cross-lingual cross-modal retrieval (CCR) has attracted increasing attention. Most CCR methods construct pseudo-parallel vision-language corpora via Machine Translation (MT) to achieve cross-lingual transfer. However, the translated sentences from MT are generally imperfect in describing the corresponding visual contents. Improperly assuming the pseudo-parallel data are correctly correlated will make the networks overfit to the noisy correspondence. Therefore, we propose Dual-view Curricular Optimal Transport (DCOT) to learn with noisy correspondence in CCR. In particular, we quantify the confidence of the sample pair correlation with optimal transport theory from both the cross-lingual and cross-modal views, and design dual-view curriculum learning to dynamically model the transportation costs according to the learning stage of the two views. Extensive experiments are conducted on two multilingual image-text datasets and one video-text dataset, and the results demonstrate the effectiveness and robustness of the proposed method. Besides, our proposed method also shows a good expansibility to cross-lingual image-text baselines and a decent generalization on out-of-domain data.
Virchow: A Million-Slide Digital Pathology Foundation Model
Sep 21, 2023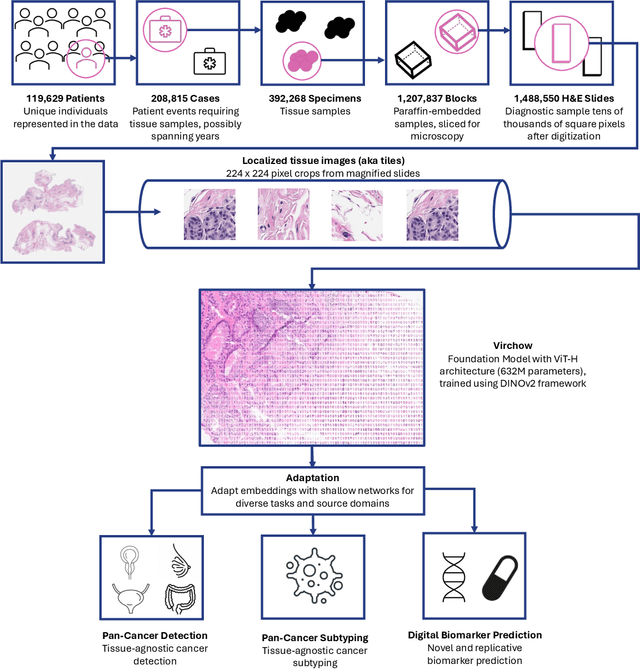
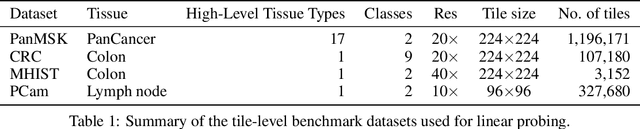
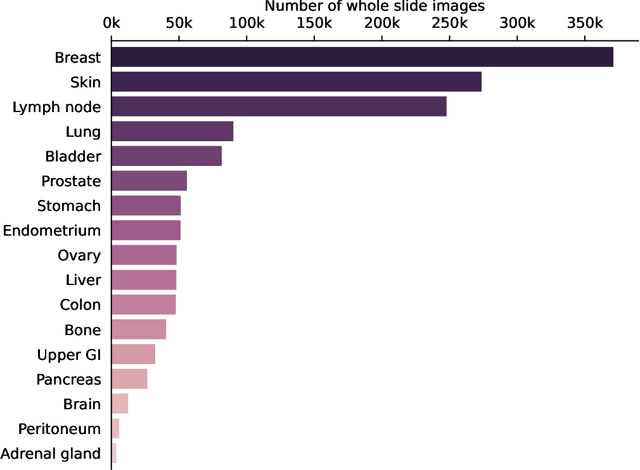
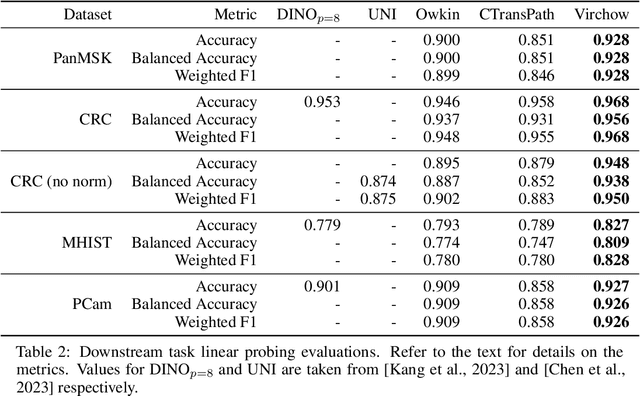
Computational pathology uses artificial intelligence to enable precision medicine and decision support systems through the analysis of whole slide images. It has the potential to revolutionize the diagnosis and treatment of cancer. However, a major challenge to this objective is that for many specific computational pathology tasks the amount of data is inadequate for development. To address this challenge, we created Virchow, a 632 million parameter deep neural network foundation model for computational pathology. Using self-supervised learning, Virchow is trained on 1.5 million hematoxylin and eosin stained whole slide images from diverse tissue groups, which is orders of magnitude more data than previous works. When evaluated on downstream tasks including tile-level pan-cancer detection and subtyping and slide-level biomarker prediction, Virchow outperforms state-of-the-art systems both on internal datasets drawn from the same population as the pretraining data as well as external public datasets. Virchow achieves 93% balanced accuracy for pancancer tile classification, and AUCs of 0.983 for colon microsatellite instability status prediction and 0.967 for breast CDH1 status prediction. The gains in performance highlight the importance of pretraining on massive pathology image datasets, suggesting pretraining on even larger datasets could continue improving performance for many high-impact applications where limited amounts of training data are available, such as drug outcome prediction.
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Sep 14, 2023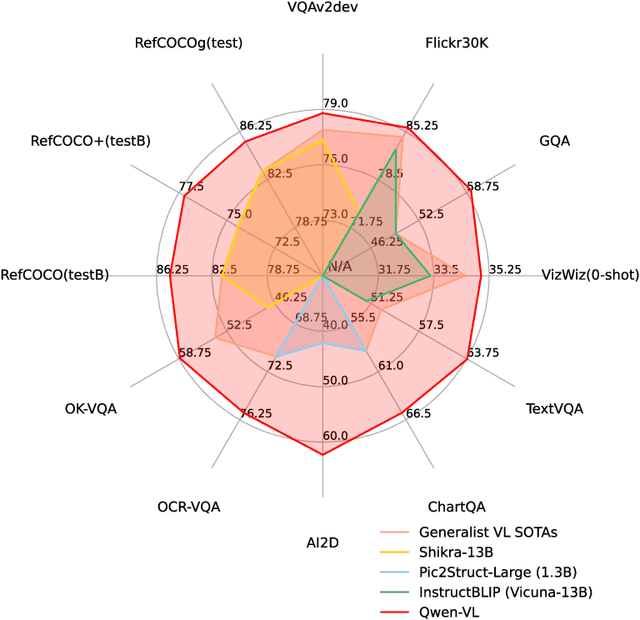

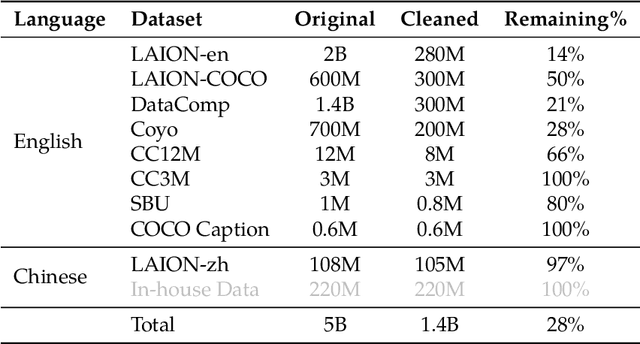
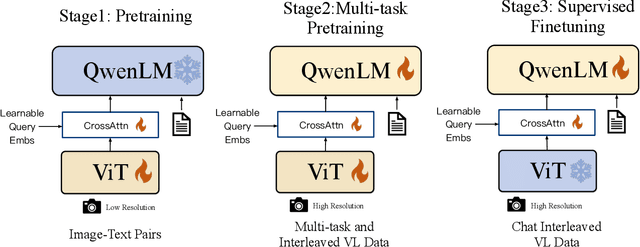
We introduce the Qwen-VL series, a set of large-scale vision-language models (LVLMs) designed to perceive and understand both text and images. Comprising Qwen-VL and Qwen-VL-Chat, these models exhibit remarkable performance in tasks like image captioning, question answering, visual localization, and flexible interaction. The evaluation covers a wide range of tasks including zero-shot captioning, visual or document visual question answering, and grounding. We demonstrate the Qwen-VL outperforms existing LVLMs. We present their architecture, training, capabilities, and performance, highlighting their contributions to advancing multimodal artificial intelligence. Code, demo and models are available at https://github.com/QwenLM/Qwen-VL.
Dhan-Shomadhan: A Dataset of Rice Leaf Disease Classification for Bangladeshi Local Rice
Sep 14, 2023This dataset represents almost all the harmful diseases for rice in Bangladesh. This dataset consists of 1106 image of five harmful diseases called Brown Spot, Leaf Scaled, Rice Blast, Rice Turngo, Steath Blight in two different background variation named field background picture and white background picture. Two different background variation helps the dataset to perform more accurately so that the user can use this data for field use as well as white background for decision making. The data is collected from rice field of Dhaka Division. This dataset can use for rice leaf diseases classification, diseases detection using Computer Vision and Pattern Recognition for different rice leaf disease.
A degree of image identification at sub-human scales could be possible with more advanced clusters
Aug 09, 2023
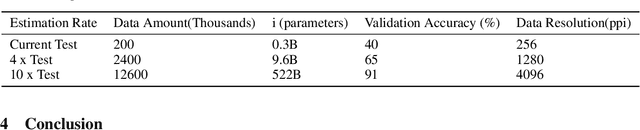
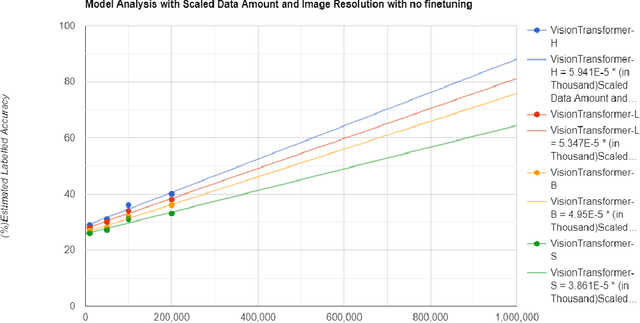
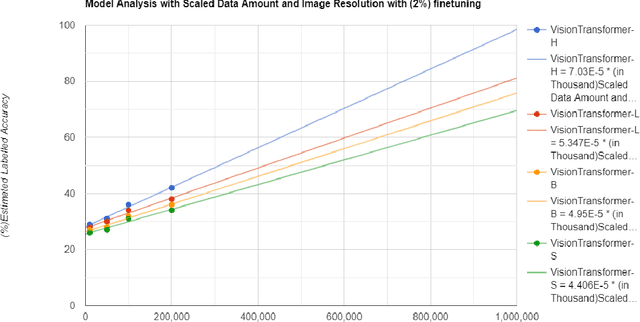
The purpose of the research is to determine if currently available self-supervised learning techniques can accomplish human level comprehension of visual images using the same degree and amount of sensory input that people acquire from. Initial research on this topic solely considered data volume scaling. Here, we scale both the volume of data and the quality of the image. This scaling experiment is a self-supervised learning method that may be done without any outside financing. We find that scaling up data volume and picture resolution at the same time enables human-level item detection performance at sub-human sizes.We run a scaling experiment with vision transformers trained on up to 200000 images up to 256 ppi.
Edge Guided GANs with Multi-Scale Contrastive Learning for Semantic Image Synthesis
Jul 22, 2023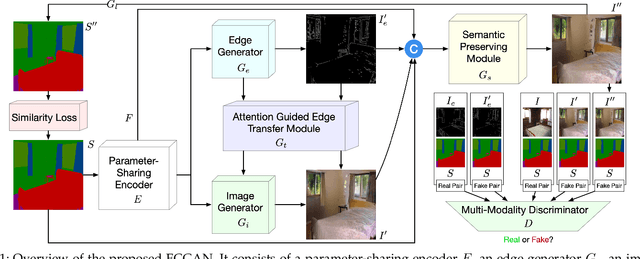
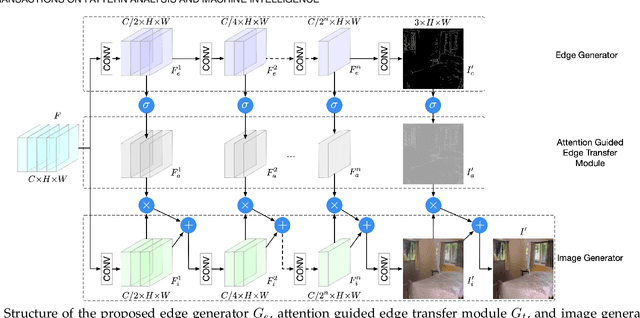
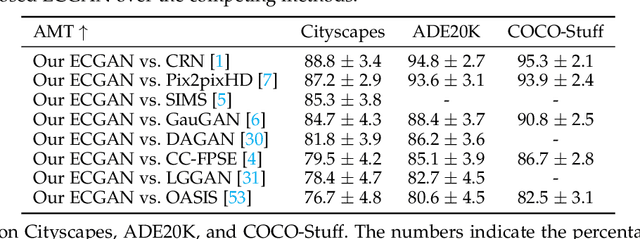
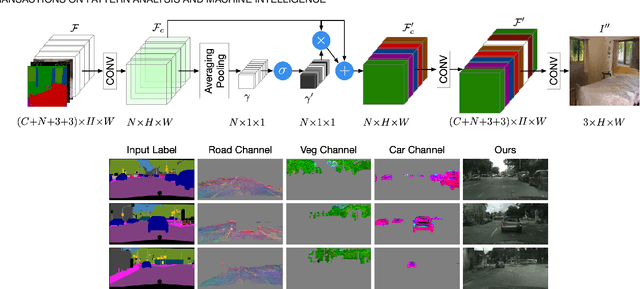
We propose a novel ECGAN for the challenging semantic image synthesis task. Although considerable improvements have been achieved by the community in the recent period, the quality of synthesized images is far from satisfactory due to three largely unresolved challenges. 1) The semantic labels do not provide detailed structural information, making it challenging to synthesize local details and structures; 2) The widely adopted CNN operations such as convolution, down-sampling, and normalization usually cause spatial resolution loss and thus cannot fully preserve the original semantic information, leading to semantically inconsistent results (e.g., missing small objects); 3) Existing semantic image synthesis methods focus on modeling 'local' semantic information from a single input semantic layout. However, they ignore 'global' semantic information of multiple input semantic layouts, i.e., semantic cross-relations between pixels across different input layouts. To tackle 1), we propose to use the edge as an intermediate representation which is further adopted to guide image generation via a proposed attention guided edge transfer module. To tackle 2), we design an effective module to selectively highlight class-dependent feature maps according to the original semantic layout to preserve the semantic information. To tackle 3), inspired by current methods in contrastive learning, we propose a novel contrastive learning method, which aims to enforce pixel embeddings belonging to the same semantic class to generate more similar image content than those from different classes. We further propose a novel multi-scale contrastive learning method that aims to push same-class features from different scales closer together being able to capture more semantic relations by explicitly exploring the structures of labeled pixels from multiple input semantic layouts from different scales.