 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning and Inverse Problems
Sep 02, 2023
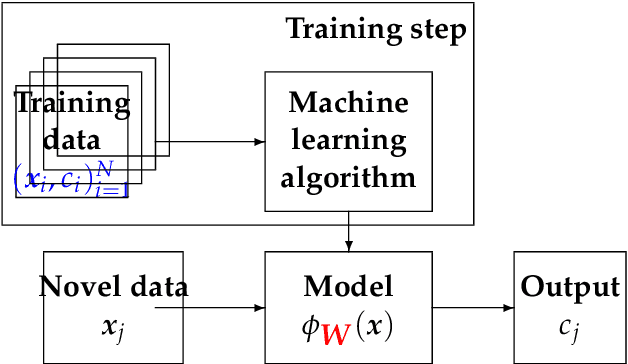
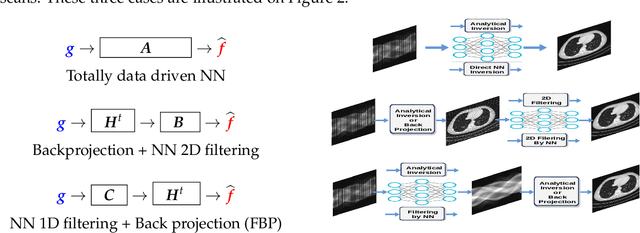
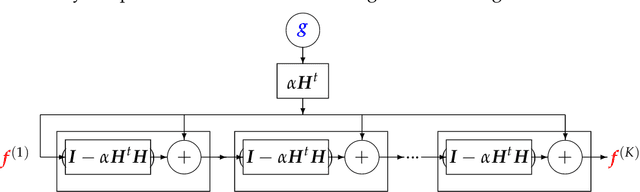
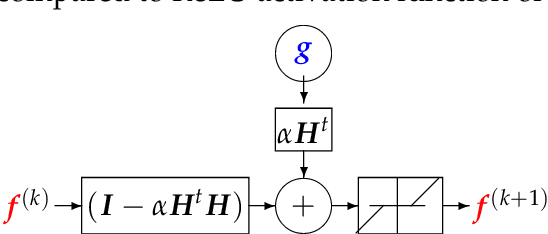
Machine Learning (ML) methods and tools have gained great success in many data, signal, image and video processing tasks, such as classification, clustering, object detection, semantic segmentation, language processing, Human-Machine interface, etc. In computer vision, image and video processing, these methods are mainly based on Neural Networks (NN) and in particular Convolutional NN (CNN), and more generally Deep NN. Inverse problems arise anywhere we have indirect measurement. As, in general, those inverse problems are ill-posed, to obtain satisfactory solutions for them needs prior information. Different regularization methods have been proposed, where the problem becomes the optimization of a criterion with a likelihood term and a regularization term. The main difficulty, however, in great dimensional real applications, remains the computational cost. Using NN, and in particular Deep Learning (DL) surrogate models and approximate computation, can become very helpful. In this work, we focus on NN and DL particularly adapted for inverse problems. We consider two cases: First the case where the forward operator is known and used as physics constraint, the second more general data driven DL methods.
PathLDM: Text conditioned Latent Diffusion Model for Histopathology
Sep 01, 2023To achieve high-quality results, diffusion models must be trained on large datasets. This can be notably prohibitive for models in specialized domains, such as computational pathology. Conditioning on labeled data is known to help in data-efficient model training. Therefore, histopathology reports, which are rich in valuable clinical information, are an ideal choice as guidance for a histopathology generative model. In this paper, we introduce PathLDM, the first text-conditioned Latent Diffusion Model tailored for generating high-quality histopathology images. Leveraging the rich contextual information provided by pathology text reports, our approach fuses image and textual data to enhance the generation process. By utilizing GPT's capabilities to distill and summarize complex text reports, we establish an effective conditioning mechanism. Through strategic conditioning and necessary architectural enhancements, we achieved a SoTA FID score of 7.64 for text-to-image generation on the TCGA-BRCA dataset, significantly outperforming the closest text-conditioned competitor with FID 30.1.
Improving the matching of deformable objects by learning to detect keypoints
Sep 01, 2023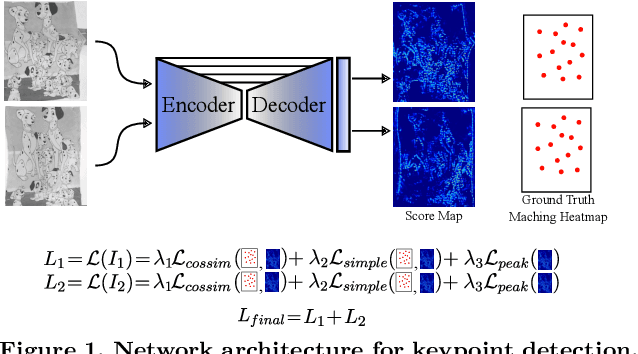
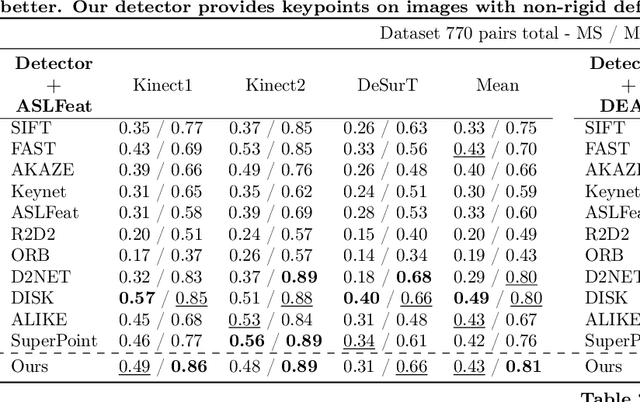
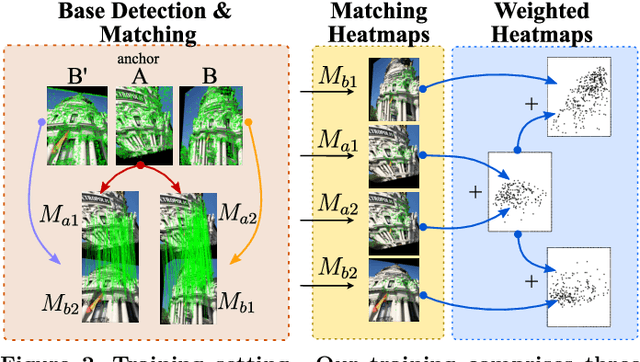

We propose a novel learned keypoint detection method to increase the number of correct matches for the task of non-rigid image correspondence. By leveraging true correspondences acquired by matching annotated image pairs with a specified descriptor extractor, we train an end-to-end convolutional neural network (CNN) to find keypoint locations that are more appropriate to the considered descriptor. For that, we apply geometric and photometric warpings to images to generate a supervisory signal, allowing the optimization of the detector. Experiments demonstrate that our method enhances the Mean Matching Accuracy of numerous descriptors when used in conjunction with our detection method, while outperforming the state-of-the-art keypoint detectors on real images of non-rigid objects by 20 p.p. We also apply our method on the complex real-world task of object retrieval where our detector performs on par with the finest keypoint detectors currently available for this task. The source code and trained models are publicly available at https://github.com/verlab/LearningToDetect_PRL_2023
* This is the accepted version of the paper to appear at Pattern Recognition Letters (PRL). The final journal version will be available at https://doi.org/10.1016/j.patrec.2023.08.012
Time Series Analysis of Urban Liveability
Sep 01, 2023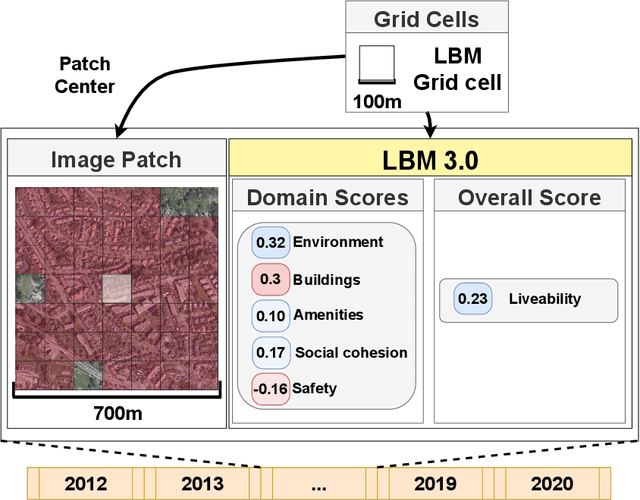
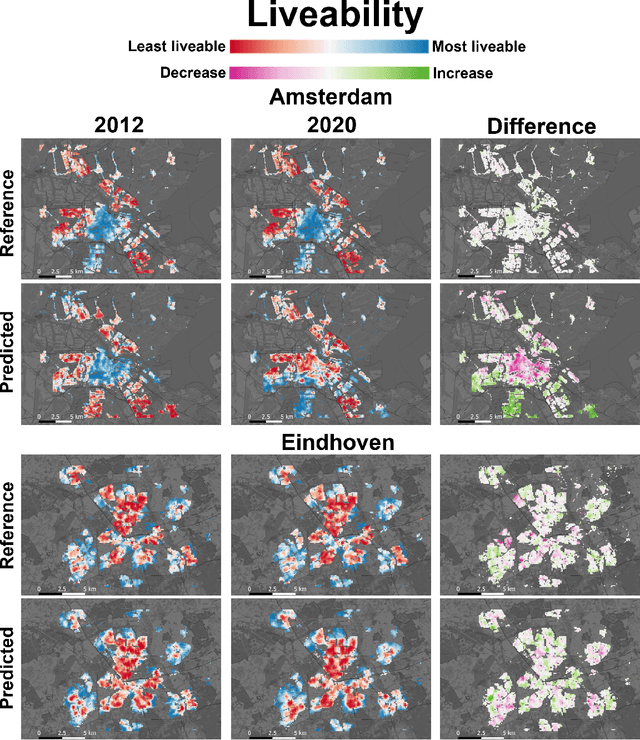
In this paper we explore deep learning models to monitor longitudinal liveability changes in Dutch cities at the neighbourhood level. Our liveability reference data is defined by a country-wise yearly survey based on a set of indicators combined into a liveability score, the Leefbaarometer. We pair this reference data with yearly-available high-resolution aerial images, which creates yearly timesteps at which liveability can be monitored. We deploy a convolutional neural network trained on an aerial image from 2016 and the Leefbaarometer score to predict liveability at new timesteps 2012 and 2020. The results in a city used for training (Amsterdam) and one never seen during training (Eindhoven) show some trends which are difficult to interpret, especially in light of the differences in image acquisitions at the different time steps. This demonstrates the complexity of liveability monitoring across time periods and the necessity for more sophisticated methods compensating for changes unrelated to liveability dynamics.
* Accepted at JURSE 2023
Fast Diffusion EM: a diffusion model for blind inverse problems with application to deconvolution
Sep 01, 2023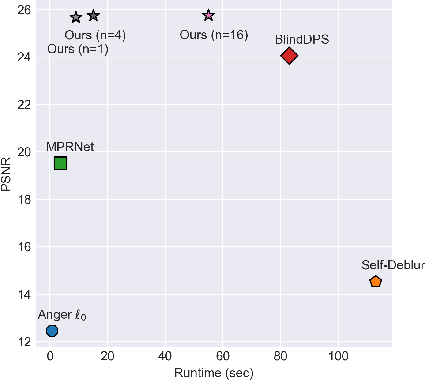
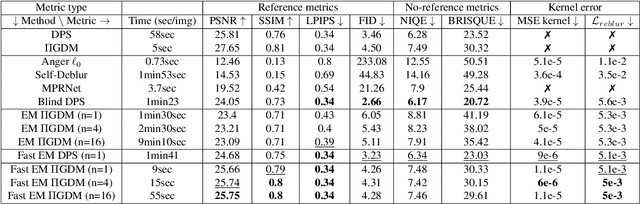

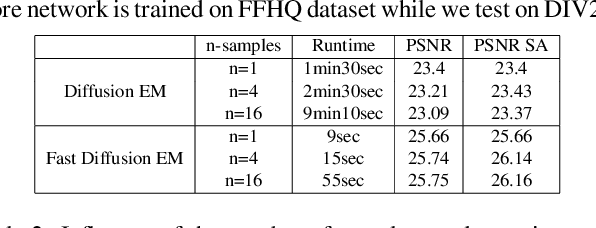
Using diffusion models to solve inverse problems is a growing field of research. Current methods assume the degradation to be known and provide impressive results in terms of restoration quality and diversity. In this work, we leverage the efficiency of those models to jointly estimate the restored image and unknown parameters of the degradation model. In particular, we designed an algorithm based on the well-known Expectation-Minimization (EM) estimation method and diffusion models. Our method alternates between approximating the expected log-likelihood of the inverse problem using samples drawn from a diffusion model and a maximization step to estimate unknown model parameters. For the maximization step, we also introduce a novel blur kernel regularization based on a Plug \& Play denoiser. Diffusion models are long to run, thus we provide a fast version of our algorithm. Extensive experiments on blind image deblurring demonstrate the effectiveness of our method when compared to other state-of-the-art approaches.
Spiking-Diffusion: Vector Quantized Discrete Diffusion Model with Spiking Neural Networks
Aug 26, 2023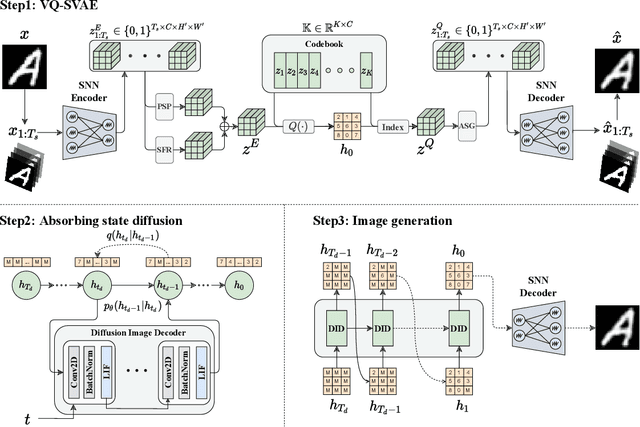
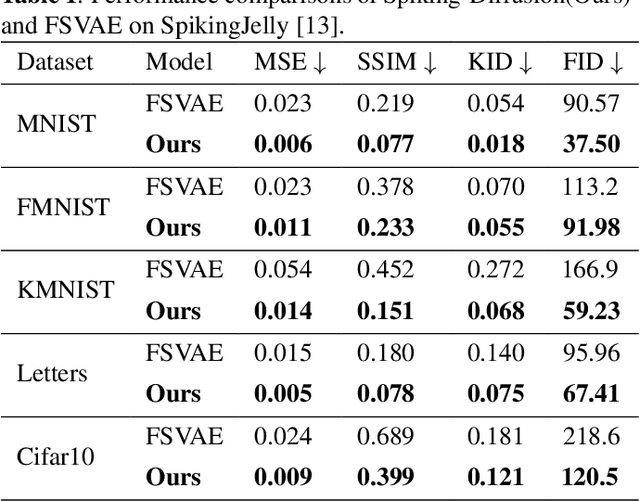

Spiking neural networks (SNNs) have tremendous potential for energy-efficient neuromorphic chips due to their binary and event-driven architecture. SNNs have been primarily used in classification tasks, but limited exploration on image generation tasks. To fill the gap, we propose a Spiking-Diffusion model, which is based on the vector quantized discrete diffusion model. First, we develop a vector quantized variational autoencoder with SNNs (VQ-SVAE) to learn a discrete latent space for images. In VQ-SVAE, image features are encoded using both the spike firing rate and postsynaptic potential, and an adaptive spike generator is designed to restore embedding features in the form of spike trains. Next, we perform absorbing state diffusion in the discrete latent space and construct a spiking diffusion image decoder (SDID) with SNNs to denoise the image. Our work is the first to build the diffusion model entirely from SNN layers. Experimental results on MNIST, FMNIST, KMNIST, Letters, and Cifar10 demonstrate that Spiking-Diffusion outperforms the existing SNN-based generation model. We achieve FIDs of 37.50, 91.98, 59.23, 67.41, and 120.5 on the above datasets respectively, with reductions of 58.60\%, 18.75\%, 64.51\%, 29.75\%, and 44.88\% in FIDs compared with the state-of-art work. Our code will be available at \url{https://github.com/Arktis2022/Spiking-Diffusion}.
NutritionVerse: Empirical Study of Various Dietary Intake Estimation Approaches
Sep 14, 2023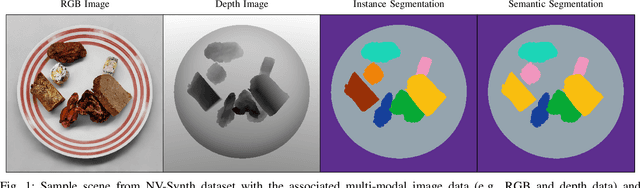



Accurate dietary intake estimation is critical for informing policies and programs to support healthy eating, as malnutrition has been directly linked to decreased quality of life. However self-reporting methods such as food diaries suffer from substantial bias. Other conventional dietary assessment techniques and emerging alternative approaches such as mobile applications incur high time costs and may necessitate trained personnel. Recent work has focused on using computer vision and machine learning to automatically estimate dietary intake from food images, but the lack of comprehensive datasets with diverse viewpoints, modalities and food annotations hinders the accuracy and realism of such methods. To address this limitation, we introduce NutritionVerse-Synth, the first large-scale dataset of 84,984 photorealistic synthetic 2D food images with associated dietary information and multimodal annotations (including depth images, instance masks, and semantic masks). Additionally, we collect a real image dataset, NutritionVerse-Real, containing 889 images of 251 dishes to evaluate realism. Leveraging these novel datasets, we develop and benchmark NutritionVerse, an empirical study of various dietary intake estimation approaches, including indirect segmentation-based and direct prediction networks. We further fine-tune models pretrained on synthetic data with real images to provide insights into the fusion of synthetic and real data. Finally, we release both datasets (NutritionVerse-Synth, NutritionVerse-Real) on https://www.kaggle.com/nutritionverse/datasets as part of an open initiative to accelerate machine learning for dietary sensing.
Virchow: A Million-Slide Digital Pathology Foundation Model
Sep 14, 2023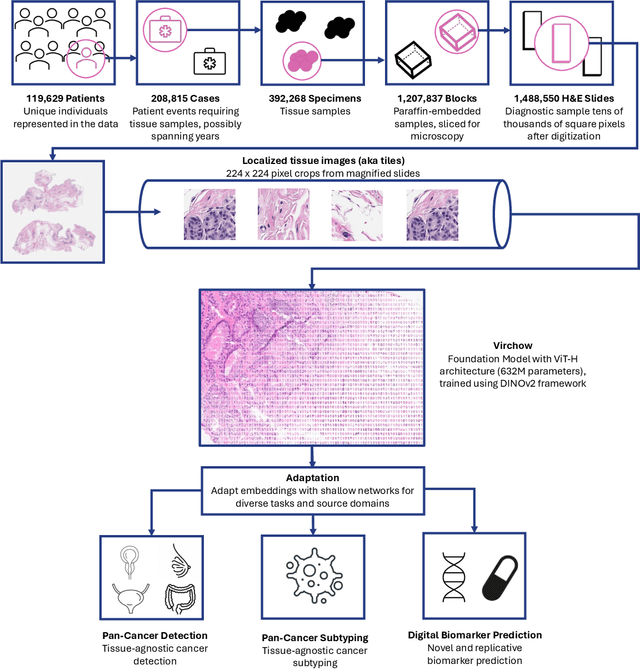
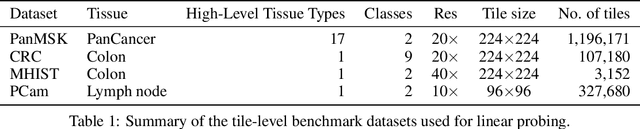
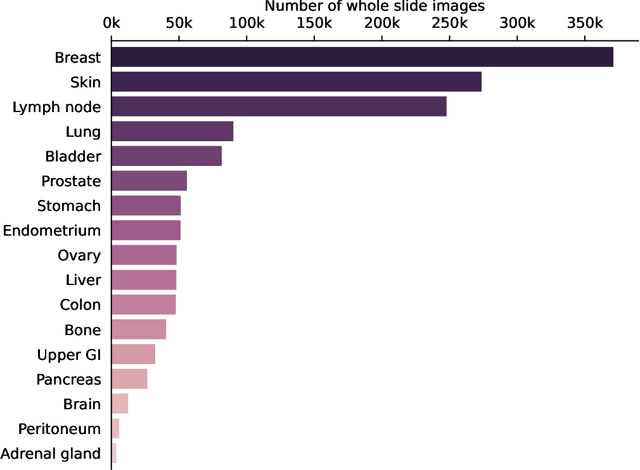
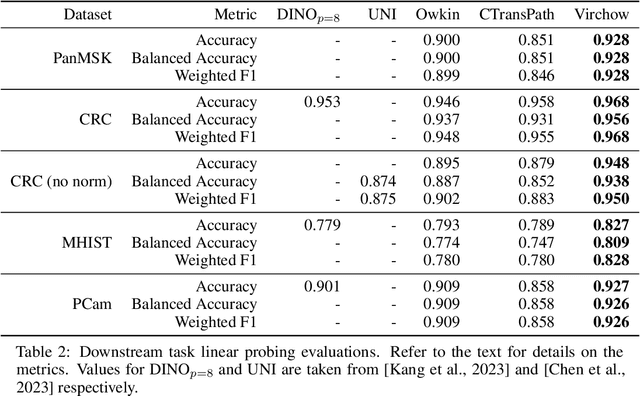
Computational pathology uses artificial intelligence to enable precision medicine and decision support systems through the analysis of whole slide images. It has the potential to revolutionize the diagnosis and treatment of cancer. However, a major challenge to this objective is that for many specific computational pathology tasks the amount of data is inadequate for development. To address this challenge, we created Virchow, a 632 million parameter deep neural network foundation model for computational pathology. Using self-supervised learning, Virchow is trained on 1.5 million hematoxylin and eosin stained whole slide images from diverse tissue groups, which is orders of magnitude more data than previous works. When evaluated on downstream tasks including tile-level pan-cancer detection and subtyping and slide-level biomarker prediction, Virchow outperforms state-of-the-art systems both on internal datasets drawn from the same population as the pretraining data as well as external public datasets. Virchow achieves 93% balanced accuracy for pancancer tile classification, and AUCs of 0.983 for colon microsatellite instability status prediction and 0.967 for breast CDH1 status prediction. The gains in performance highlight the importance of pretraining on massive pathology image datasets, suggesting pretraining on even larger datasets could continue improving performance for many high-impact applications where limited amounts of training data are available, such as drug outcome prediction.
GRID: Scene-Graph-based Instruction-driven Robotic Task Planning
Sep 14, 2023Recent works have shown that Large Language Models (LLMs) can promote grounding instructions to robotic task planning. Despite the progress, most existing works focused on utilizing raw images to help LLMs understand environmental information, which not only limits the observation scope but also typically requires massive multimodal data collection and large-scale models. In this paper, we propose a novel approach called Graph-based Robotic Instruction Decomposer (GRID), leverages scene graph instead of image to perceive global scene information and continuously plans subtask in each stage for a given instruction. Our method encodes object attributes and relationships in graphs through an LLM and Graph Attention Networks, integrating instruction features to predict subtasks consisting of pre-defined robot actions and target objects in the scene graph. This strategy enables robots to acquire semantic knowledge widely observed in the environment from the scene graph. To train and evaluate GRID, we build a dataset construction pipeline to generate synthetic datasets in graph-based robotic task planning. Experiments have shown that our method outperforms GPT-4 by over 25.4% in subtask accuracy and 43.6% in task accuracy. Experiments conducted on datasets of unseen scenes and scenes with different numbers of objects showed that the task accuracy of GRID declined by at most 3.8%, which demonstrates its good cross-scene generalization ability. We validate our method in both physical simulation and the real world.
The Co-12 Recipe for Evaluating Interpretable Part-Prototype Image Classifiers
Jul 26, 2023Interpretable part-prototype models are computer vision models that are explainable by design. The models learn prototypical parts and recognise these components in an image, thereby combining classification and explanation. Despite the recent attention for intrinsically interpretable models, there is no comprehensive overview on evaluating the explanation quality of interpretable part-prototype models. Based on the Co-12 properties for explanation quality as introduced in arXiv:2201.08164 (e.g., correctness, completeness, compactness), we review existing work that evaluates part-prototype models, reveal research gaps and outline future approaches for evaluation of the explanation quality of part-prototype models. This paper, therefore, contributes to the progression and maturity of this relatively new research field on interpretable part-prototype models. We additionally provide a ``Co-12 cheat sheet'' that acts as a concise summary of our findings on evaluating part-prototype models.