 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Not All Steps are Created Equal: Selective Diffusion Distillation for Image Manipulation
Jul 17, 2023

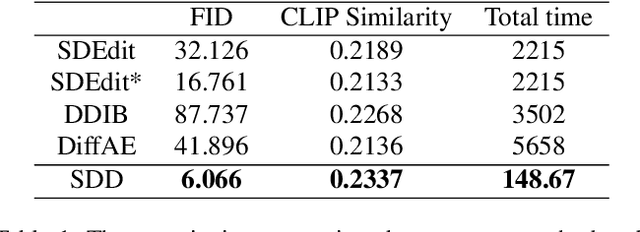

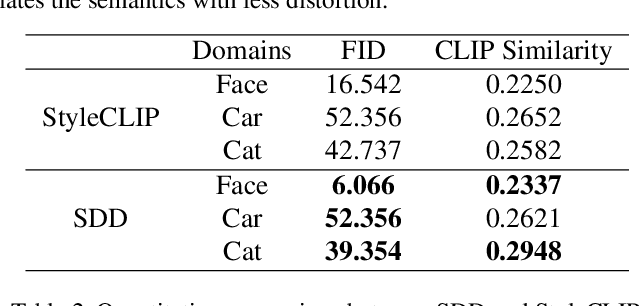
Conditional diffusion models have demonstrated impressive performance in image manipulation tasks. The general pipeline involves adding noise to the image and then denoising it. However, this method faces a trade-off problem: adding too much noise affects the fidelity of the image while adding too little affects its editability. This largely limits their practical applicability. In this paper, we propose a novel framework, Selective Diffusion Distillation (SDD), that ensures both the fidelity and editability of images. Instead of directly editing images with a diffusion model, we train a feedforward image manipulation network under the guidance of the diffusion model. Besides, we propose an effective indicator to select the semantic-related timestep to obtain the correct semantic guidance from the diffusion model. This approach successfully avoids the dilemma caused by the diffusion process. Our extensive experiments demonstrate the advantages of our framework. Code is released at https://github.com/AndysonYs/Selective-Diffusion-Distillation.
RobustCLEVR: A Benchmark and Framework for Evaluating Robustness in Object-centric Learning
Aug 28, 2023Object-centric representation learning offers the potential to overcome limitations of image-level representations by explicitly parsing image scenes into their constituent components. While image-level representations typically lack robustness to natural image corruptions, the robustness of object-centric methods remains largely untested. To address this gap, we present the RobustCLEVR benchmark dataset and evaluation framework. Our framework takes a novel approach to evaluating robustness by enabling the specification of causal dependencies in the image generation process grounded in expert knowledge and capable of producing a wide range of image corruptions unattainable in existing robustness evaluations. Using our framework, we define several causal models of the image corruption process which explicitly encode assumptions about the causal relationships and distributions of each corruption type. We generate dataset variants for each causal model on which we evaluate state-of-the-art object-centric methods. Overall, we find that object-centric methods are not inherently robust to image corruptions. Our causal evaluation approach exposes model sensitivities not observed using conventional evaluation processes, yielding greater insight into robustness differences across algorithms. Lastly, while conventional robustness evaluations view corruptions as out-of-distribution, we use our causal framework to show that even training on in-distribution image corruptions does not guarantee increased model robustness. This work provides a step towards more concrete and substantiated understanding of model performance and deterioration under complex corruption processes of the real-world.
Frequency-Aware Self-Supervised Long-Tailed Learning
Sep 09, 2023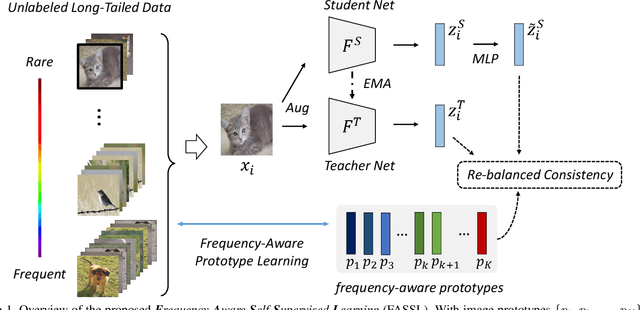
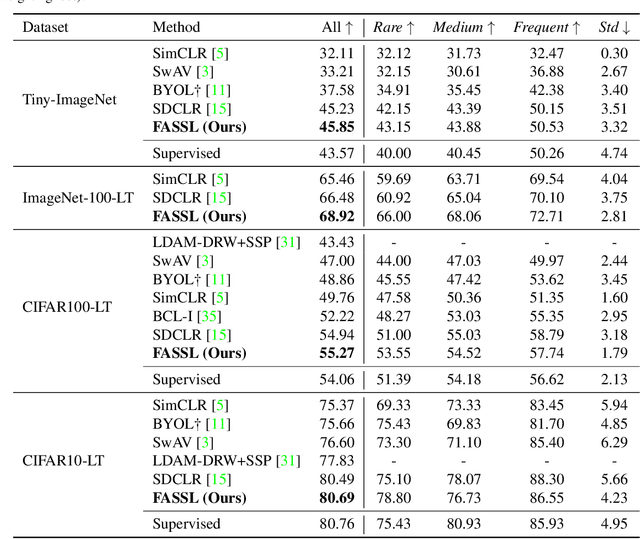
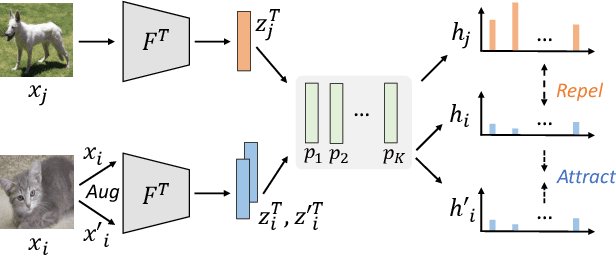
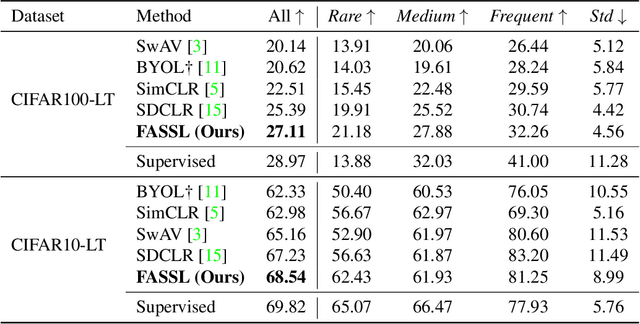
Data collected from the real world typically exhibit long-tailed distributions, where frequent classes contain abundant data while rare ones have only a limited number of samples. While existing supervised learning approaches have been proposed to tackle such data imbalance, the requirement of label supervision would limit their applicability to real-world scenarios in which label annotation might not be available. Without the access to class labels nor the associated class frequencies, we propose Frequency-Aware Self-Supervised Learning (FASSL) in this paper. Targeting at learning from unlabeled data with inherent long-tailed distributions, the goal of FASSL is to produce discriminative feature representations for downstream classification tasks. In FASSL, we first learn frequency-aware prototypes, reflecting the associated long-tailed distribution. Particularly focusing on rare-class samples, the relationships between image data and the derived prototypes are further exploited with the introduced self-supervised learning scheme. Experiments on long-tailed image datasets quantitatively and qualitatively verify the effectiveness of our learning scheme.
Exploring Robust Features for Improving Adversarial Robustness
Sep 09, 2023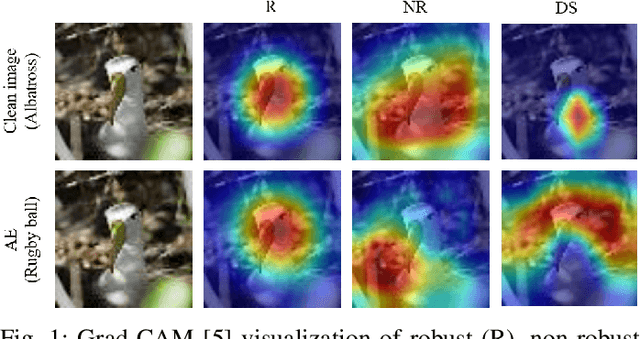
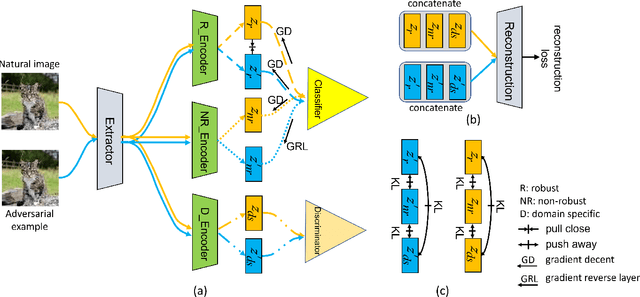
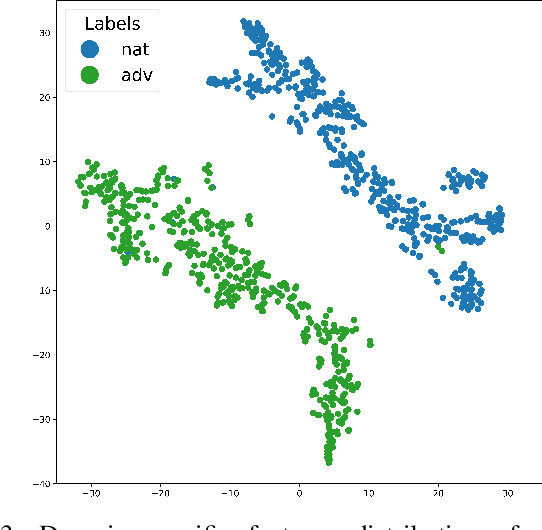
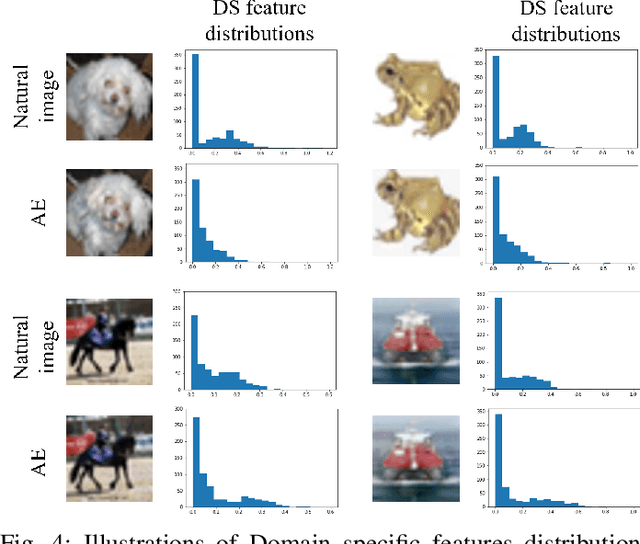
While deep neural networks (DNNs) have revolutionized many fields, their fragility to carefully designed adversarial attacks impedes the usage of DNNs in safety-critical applications. In this paper, we strive to explore the robust features which are not affected by the adversarial perturbations, i.e., invariant to the clean image and its adversarial examples, to improve the model's adversarial robustness. Specifically, we propose a feature disentanglement model to segregate the robust features from non-robust features and domain specific features. The extensive experiments on four widely used datasets with different attacks demonstrate that robust features obtained from our model improve the model's adversarial robustness compared to the state-of-the-art approaches. Moreover, the trained domain discriminator is able to identify the domain specific features from the clean images and adversarial examples almost perfectly. This enables adversarial example detection without incurring additional computational costs. With that, we can also specify different classifiers for clean images and adversarial examples, thereby avoiding any drop in clean image accuracy.
AmbientFlow: Invertible generative models from incomplete, noisy measurements
Sep 09, 2023


Generative models have gained popularity for their potential applications in imaging science, such as image reconstruction, posterior sampling and data sharing. Flow-based generative models are particularly attractive due to their ability to tractably provide exact density estimates along with fast, inexpensive and diverse samples. Training such models, however, requires a large, high quality dataset of objects. In applications such as computed imaging, it is often difficult to acquire such data due to requirements such as long acquisition time or high radiation dose, while acquiring noisy or partially observed measurements of these objects is more feasible. In this work, we propose AmbientFlow, a framework for learning flow-based generative models directly from noisy and incomplete data. Using variational Bayesian methods, a novel framework for establishing flow-based generative models from noisy, incomplete data is proposed. Extensive numerical studies demonstrate the effectiveness of AmbientFlow in correctly learning the object distribution. The utility of AmbientFlow in a downstream inference task of image reconstruction is demonstrated.
OpenIllumination: A Multi-Illumination Dataset for Inverse Rendering Evaluation on Real Objects
Sep 14, 2023
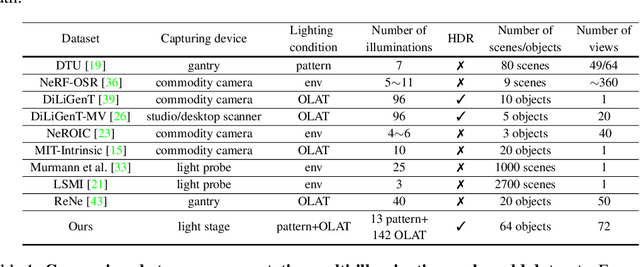

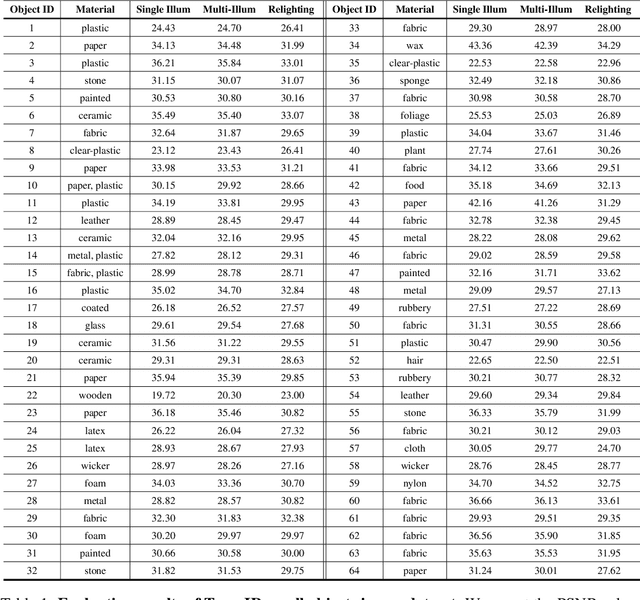
We introduce OpenIllumination, a real-world dataset containing over 108K images of 64 objects with diverse materials, captured under 72 camera views and a large number of different illuminations. For each image in the dataset, we provide accurate camera parameters, illumination ground truth, and foreground segmentation masks. Our dataset enables the quantitative evaluation of most inverse rendering and material decomposition methods for real objects. We examine several state-of-the-art inverse rendering methods on our dataset and compare their performances. The dataset and code can be found on the project page: https://oppo-us-research.github.io/OpenIllumination.
USL-Net: Uncertainty Self-Learning Network for Unsupervised Skin Lesion Segmentation
Sep 23, 2023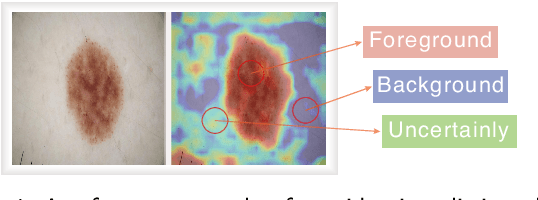
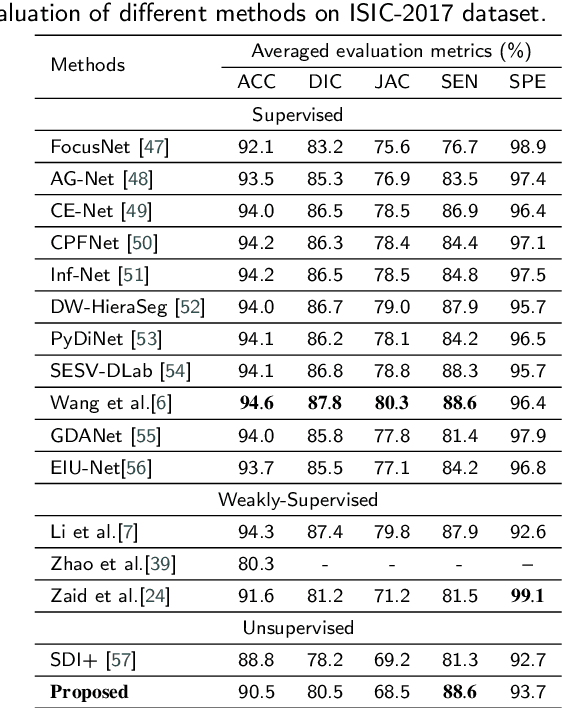
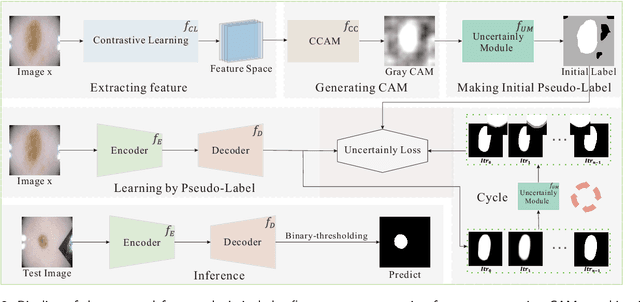
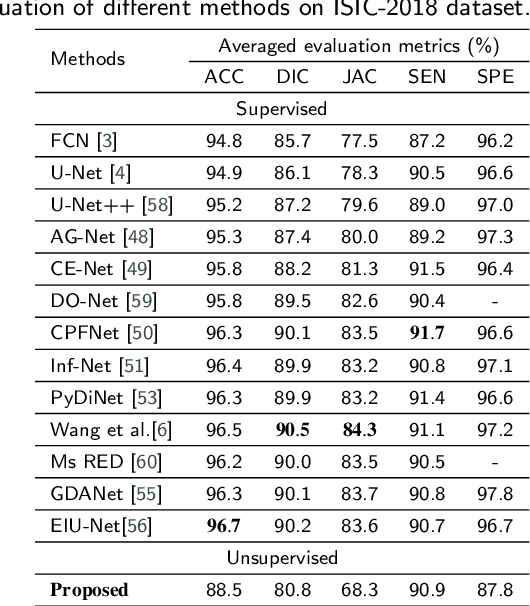
Unsupervised skin lesion segmentation offers several benefits, including conserving expert human resources, reducing discrepancies due to subjective human labeling, and adapting to novel environments. However, segmenting dermoscopic images without manual labeling guidance presents significant challenges due to dermoscopic image artifacts such as hair noise, blister noise, and subtle edge differences. To address these challenges, we introduce an innovative Uncertainty Self-Learning Network (USL-Net) designed for skin lesion segmentation. The USL-Net can effectively segment a range of lesions, eliminating the need for manual labeling guidance. Initially, features are extracted using contrastive learning, followed by the generation of Class Activation Maps (CAMs) as saliency maps using these features. The different CAM locations correspond to the importance of the lesion region based on their saliency. High-saliency regions in the map serve as pseudo-labels for lesion regions while low-saliency regions represent the background. However, intermediate regions can be hard to classify, often due to their proximity to lesion edges or interference from hair or blisters. Rather than risk potential pseudo-labeling errors or learning confusion by forcefully classifying these regions, we consider them as uncertainty regions, exempting them from pseudo-labeling and allowing the network to self-learn. Further, we employ connectivity detection and centrality detection to refine foreground pseudo-labels and reduce noise-induced errors. The application of cycle refining enhances performance further. Our method underwent thorough experimental validation on the ISIC-2017, ISIC-2018, and PH2 datasets, demonstrating that its performance is on par with weakly supervised and supervised methods, and exceeds that of other existing unsupervised methods.
FreeU: Free Lunch in Diffusion U-Net
Sep 20, 2023


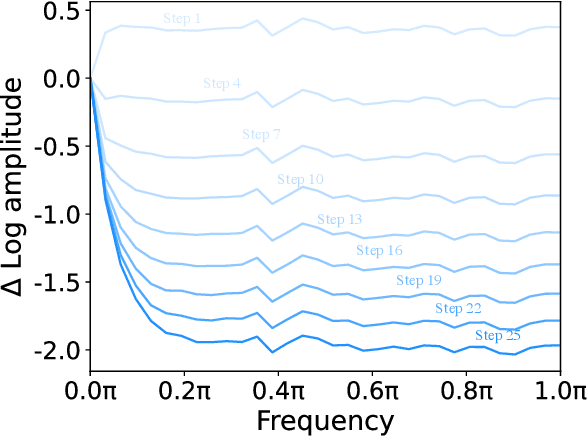
In this paper, we uncover the untapped potential of diffusion U-Net, which serves as a "free lunch" that substantially improves the generation quality on the fly. We initially investigate the key contributions of the U-Net architecture to the denoising process and identify that its main backbone primarily contributes to denoising, whereas its skip connections mainly introduce high-frequency features into the decoder module, causing the network to overlook the backbone semantics. Capitalizing on this discovery, we propose a simple yet effective method-termed "FreeU" - that enhances generation quality without additional training or finetuning. Our key insight is to strategically re-weight the contributions sourced from the U-Net's skip connections and backbone feature maps, to leverage the strengths of both components of the U-Net architecture. Promising results on image and video generation tasks demonstrate that our FreeU can be readily integrated to existing diffusion models, e.g., Stable Diffusion, DreamBooth, ModelScope, Rerender and ReVersion, to improve the generation quality with only a few lines of code. All you need is to adjust two scaling factors during inference. Project page: https://chenyangsi.top/FreeU/.
PRAT: PRofiling Adversarial aTtacks
Sep 20, 2023

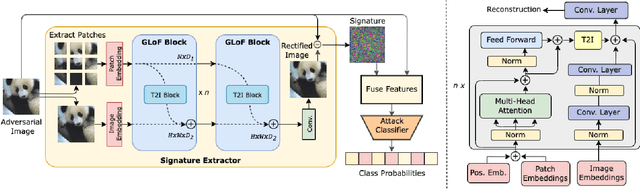
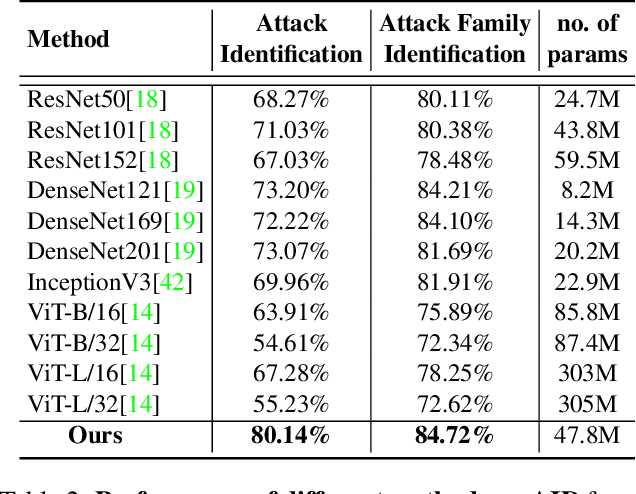
Intrinsic susceptibility of deep learning to adversarial examples has led to a plethora of attack techniques with a broad common objective of fooling deep models. However, we find slight compositional differences between the algorithms achieving this objective. These differences leave traces that provide important clues for attacker profiling in real-life scenarios. Inspired by this, we introduce a novel problem of PRofiling Adversarial aTtacks (PRAT). Given an adversarial example, the objective of PRAT is to identify the attack used to generate it. Under this perspective, we can systematically group existing attacks into different families, leading to the sub-problem of attack family identification, which we also study. To enable PRAT analysis, we introduce a large Adversarial Identification Dataset (AID), comprising over 180k adversarial samples generated with 13 popular attacks for image specific/agnostic white/black box setups. We use AID to devise a novel framework for the PRAT objective. Our framework utilizes a Transformer based Global-LOcal Feature (GLOF) module to extract an approximate signature of the adversarial attack, which in turn is used for the identification of the attack. Using AID and our framework, we provide multiple interesting benchmark results for the PRAT problem.
Multi-grained Temporal Prototype Learning for Few-shot Video Object Segmentation
Sep 20, 2023
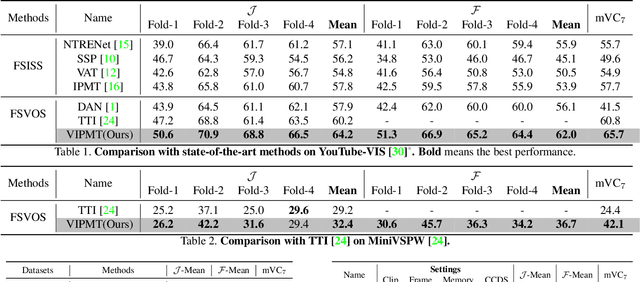
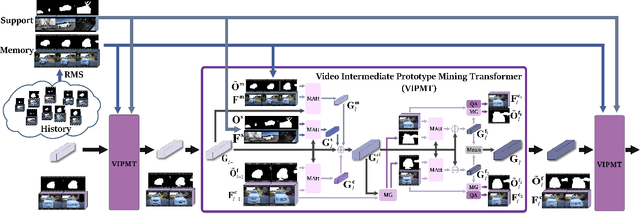
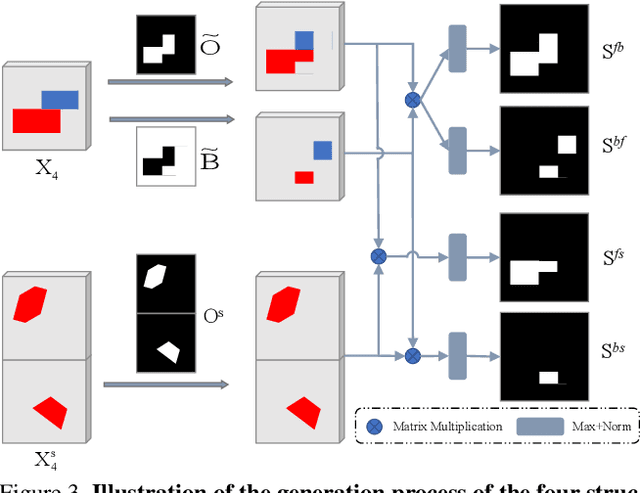
Few-Shot Video Object Segmentation (FSVOS) aims to segment objects in a query video with the same category defined by a few annotated support images. However, this task was seldom explored. In this work, based on IPMT, a state-of-the-art few-shot image segmentation method that combines external support guidance information with adaptive query guidance cues, we propose to leverage multi-grained temporal guidance information for handling the temporal correlation nature of video data. We decompose the query video information into a clip prototype and a memory prototype for capturing local and long-term internal temporal guidance, respectively. Frame prototypes are further used for each frame independently to handle fine-grained adaptive guidance and enable bidirectional clip-frame prototype communication. To reduce the influence of noisy memory, we propose to leverage the structural similarity relation among different predicted regions and the support for selecting reliable memory frames. Furthermore, a new segmentation loss is also proposed to enhance the category discriminability of the learned prototypes. Experimental results demonstrate that our proposed video IPMT model significantly outperforms previous models on two benchmark datasets. Code is available at https://github.com/nankepan/VIPMT.