 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion-based Adversarial Purification for Robust Deep MRI Reconstruction
Sep 11, 2023
Deep learning (DL) methods have been extensively employed in magnetic resonance imaging (MRI) reconstruction, demonstrating remarkable performance improvements compared to traditional non-DL methods. However, recent studies have uncovered the susceptibility of these models to carefully engineered adversarial perturbations. In this paper, we tackle this issue by leveraging diffusion models. Specifically, we introduce a defense strategy that enhances the robustness of DL-based MRI reconstruction methods through the utilization of pre-trained diffusion models as adversarial purifiers. Unlike conventional state-of-the-art adversarial defense methods (e.g., adversarial training), our proposed approach eliminates the need to solve a minimax optimization problem to train the image reconstruction model from scratch, and only requires fine-tuning on purified adversarial examples. Our experimental findings underscore the effectiveness of our proposed technique when benchmarked against leading defense methodologies for MRI reconstruction such as adversarial training and randomized smoothing.
Implicit Neural Feature Fusion Function for Multispectral and Hyperspectral Image Fusion
Jul 14, 2023Multispectral and Hyperspectral Image Fusion (MHIF) is a practical task that aims to fuse a high-resolution multispectral image (HR-MSI) and a low-resolution hyperspectral image (LR-HSI) of the same scene to obtain a high-resolution hyperspectral image (HR-HSI). Benefiting from powerful inductive bias capability, CNN-based methods have achieved great success in the MHIF task. However, they lack certain interpretability and require convolution structures be stacked to enhance performance. Recently, Implicit Neural Representation (INR) has achieved good performance and interpretability in 2D tasks due to its ability to locally interpolate samples and utilize multimodal content such as pixels and coordinates. Although INR-based approaches show promise, they require extra construction of high-frequency information (\emph{e.g.,} positional encoding). In this paper, inspired by previous work of MHIF task, we realize that HR-MSI could serve as a high-frequency detail auxiliary input, leading us to propose a novel INR-based hyperspectral fusion function named Implicit Neural Feature Fusion Function (INF). As an elaborate structure, it solves the MHIF task and addresses deficiencies in the INR-based approaches. Specifically, our INF designs a Dual High-Frequency Fusion (DHFF) structure that obtains high-frequency information twice from HR-MSI and LR-HSI, then subtly fuses them with coordinate information. Moreover, the proposed INF incorporates a parameter-free method named INR with cosine similarity (INR-CS) that uses cosine similarity to generate local weights through feature vectors. Based on INF, we construct an Implicit Neural Fusion Network (INFN) that achieves state-of-the-art performance for MHIF tasks of two public datasets, \emph{i.e.,} CAVE and Harvard. The code will soon be made available on GitHub.
Impact of Visual Context on Noisy Multimodal NMT: An Empirical Study for English to Indian Languages
Aug 30, 2023
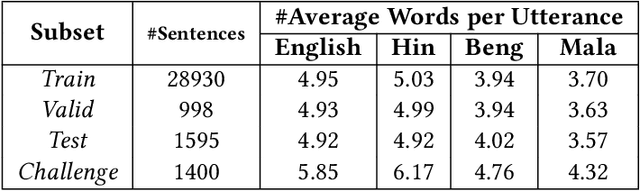
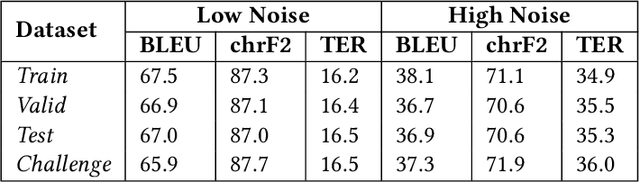
The study investigates the effectiveness of utilizing multimodal information in Neural Machine Translation (NMT). While prior research focused on using multimodal data in low-resource scenarios, this study examines how image features impact translation when added to a large-scale, pre-trained unimodal NMT system. Surprisingly, the study finds that images might be redundant in this context. Additionally, the research introduces synthetic noise to assess whether images help the model deal with textual noise. Multimodal models slightly outperform text-only models in noisy settings, even with random images. The study's experiments translate from English to Hindi, Bengali, and Malayalam, outperforming state-of-the-art benchmarks significantly. Interestingly, the effect of visual context varies with source text noise: no visual context works best for non-noisy translations, cropped image features are optimal for low noise, and full image features work better in high-noise scenarios. This sheds light on the role of visual context, especially in noisy settings, opening up a new research direction for Noisy Neural Machine Translation in multimodal setups. The research emphasizes the importance of combining visual and textual information for improved translation in various environments.
Towards Non-Parametric Models for Confidence Aware Image Prediction from Low Data using Gaussian Processes
Jul 20, 2023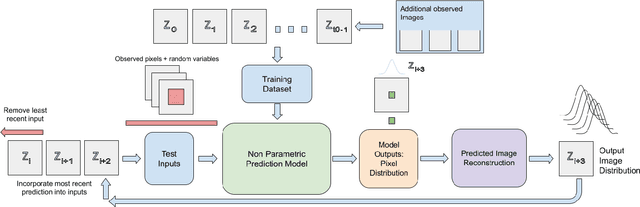
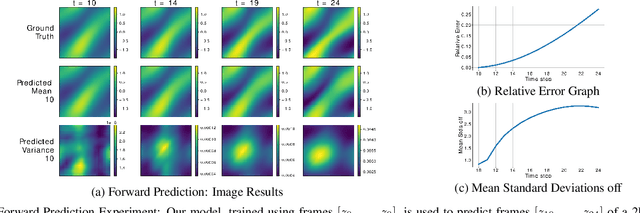

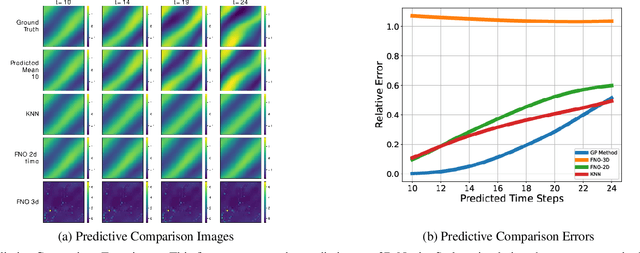
The ability to envision future states is crucial to informed decision making while interacting with dynamic environments. With cameras providing a prevalent and information rich sensing modality, the problem of predicting future states from image sequences has garnered a lot of attention. Current state of the art methods typically train large parametric models for their predictions. Though often able to predict with accuracy, these models rely on the availability of large training datasets to converge to useful solutions. In this paper we focus on the problem of predicting future images of an image sequence from very little training data. To approach this problem, we use non-parametric models to take a probabilistic approach to image prediction. We generate probability distributions over sequentially predicted images and propagate uncertainty through time to generate a confidence metric for our predictions. Gaussian Processes are used for their data efficiency and ability to readily incorporate new training data online. We showcase our method by successfully predicting future frames of a smooth fluid simulation environment.
Towards Robust Scene Text Image Super-resolution via Explicit Location Enhancement
Jul 19, 2023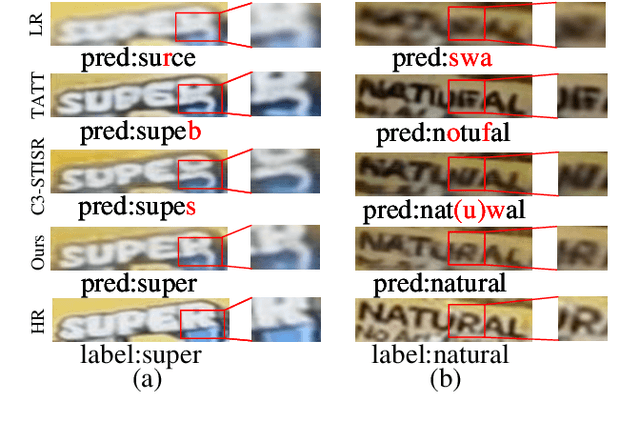

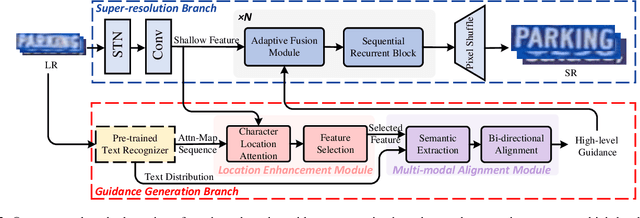

Scene text image super-resolution (STISR), aiming to improve image quality while boosting downstream scene text recognition accuracy, has recently achieved great success. However, most existing methods treat the foreground (character regions) and background (non-character regions) equally in the forward process, and neglect the disturbance from the complex background, thus limiting the performance. To address these issues, in this paper, we propose a novel method LEMMA that explicitly models character regions to produce high-level text-specific guidance for super-resolution. To model the location of characters effectively, we propose the location enhancement module to extract character region features based on the attention map sequence. Besides, we propose the multi-modal alignment module to perform bidirectional visual-semantic alignment to generate high-quality prior guidance, which is then incorporated into the super-resolution branch in an adaptive manner using the proposed adaptive fusion module. Experiments on TextZoom and four scene text recognition benchmarks demonstrate the superiority of our method over other state-of-the-art methods. Code is available at https://github.com/csguoh/LEMMA.
Frequency-mixed Single-source Domain Generalization for Medical Image Segmentation
Jul 18, 2023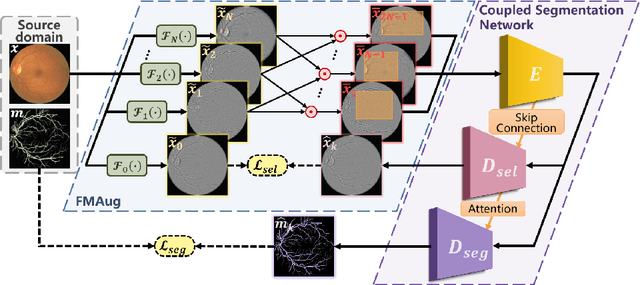
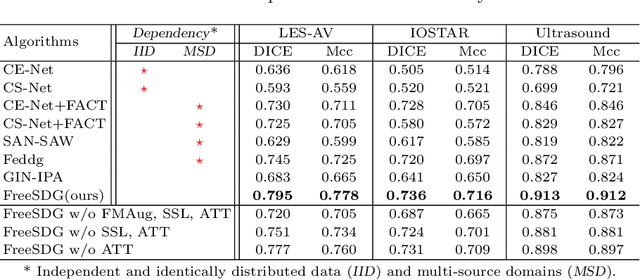
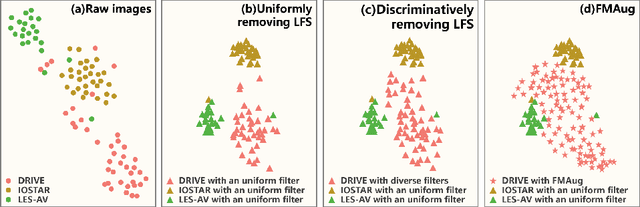
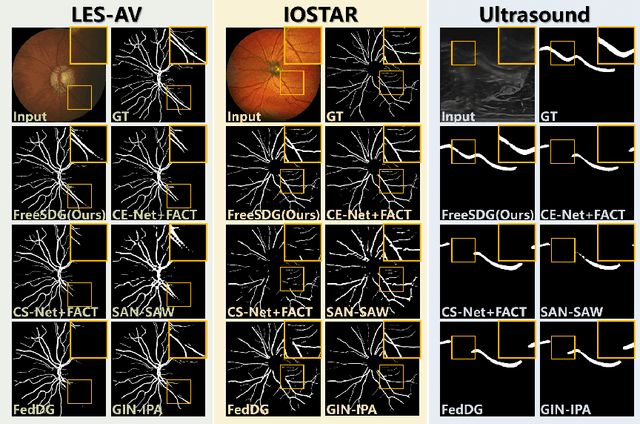
The annotation scarcity of medical image segmentation poses challenges in collecting sufficient training data for deep learning models. Specifically, models trained on limited data may not generalize well to other unseen data domains, resulting in a domain shift issue. Consequently, domain generalization (DG) is developed to boost the performance of segmentation models on unseen domains. However, the DG setup requires multiple source domains, which impedes the efficient deployment of segmentation algorithms in clinical scenarios. To address this challenge and improve the segmentation model's generalizability, we propose a novel approach called the Frequency-mixed Single-source Domain Generalization method (FreeSDG). By analyzing the frequency's effect on domain discrepancy, FreeSDG leverages a mixed frequency spectrum to augment the single-source domain. Additionally, self-supervision is constructed in the domain augmentation to learn robust context-aware representations for the segmentation task. Experimental results on five datasets of three modalities demonstrate the effectiveness of the proposed algorithm. FreeSDG outperforms state-of-the-art methods and significantly improves the segmentation model's generalizability. Therefore, FreeSDG provides a promising solution for enhancing the generalization of medical image segmentation models, especially when annotated data is scarce. The code is available at https://github.com/liamheng/Non-IID_Medical_Image_Segmentation.
Conditional 360-degree Image Synthesis for Immersive Indoor Scene Decoration
Jul 18, 2023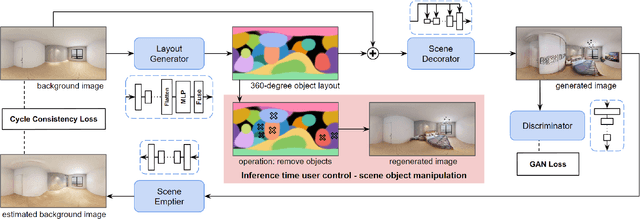
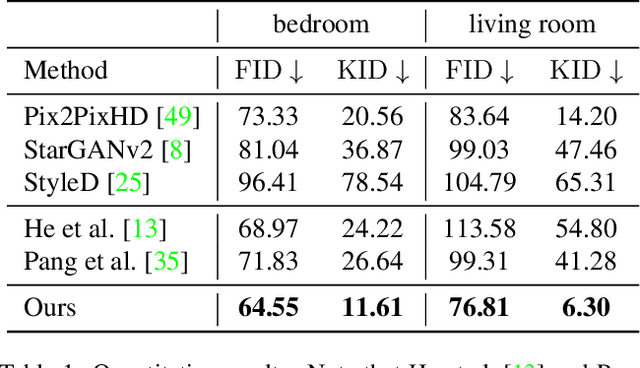
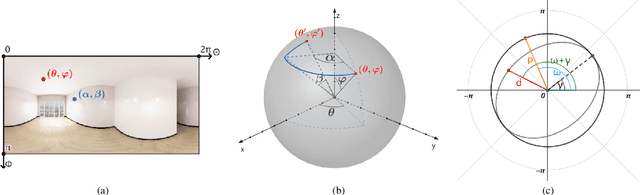
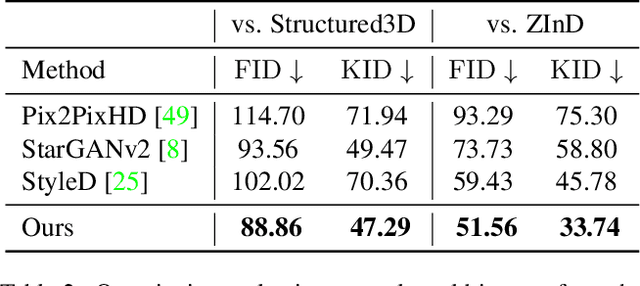
In this paper, we address the problem of conditional scene decoration for 360-degree images. Our method takes a 360-degree background photograph of an indoor scene and generates decorated images of the same scene in the panorama view. To do this, we develop a 360-aware object layout generator that learns latent object vectors in the 360-degree view to enable a variety of furniture arrangements for an input 360-degree background image. We use this object layout to condition a generative adversarial network to synthesize images of an input scene. To further reinforce the generation capability of our model, we develop a simple yet effective scene emptier that removes the generated furniture and produces an emptied scene for our model to learn a cyclic constraint. We train the model on the Structure3D dataset and show that our model can generate diverse decorations with controllable object layout. Our method achieves state-of-the-art performance on the Structure3D dataset and generalizes well to the Zillow indoor scene dataset. Our user study confirms the immersive experiences provided by the realistic image quality and furniture layout in our generation results. Our implementation will be made available.
Morphologically-Aware Consensus Computation via Heuristics-based IterATive Optimization (MACCHIatO)
Sep 14, 2023The extraction of consensus segmentations from several binary or probabilistic masks is important to solve various tasks such as the analysis of inter-rater variability or the fusion of several neural network outputs. One of the most widely used methods to obtain such a consensus segmentation is the STAPLE algorithm. In this paper, we first demonstrate that the output of that algorithm is heavily impacted by the background size of images and the choice of the prior. We then propose a new method to construct a binary or a probabilistic consensus segmentation based on the Fr\'{e}chet means of carefully chosen distances which makes it totally independent of the image background size. We provide a heuristic approach to optimize this criterion such that a voxel's class is fully determined by its voxel-wise distance to the different masks, the connected component it belongs to and the group of raters who segmented it. We compared extensively our method on several datasets with the STAPLE method and the naive segmentation averaging method, showing that it leads to binary consensus masks of intermediate size between Majority Voting and STAPLE and to different posterior probabilities than Mask Averaging and STAPLE methods. Our code is available at https://gitlab.inria.fr/dhamzaou/jaccardmap .
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2023:013
Detect, Augment, Compose, and Adapt: Four Steps for Unsupervised Domain Adaptation in Object Detection
Aug 29, 2023

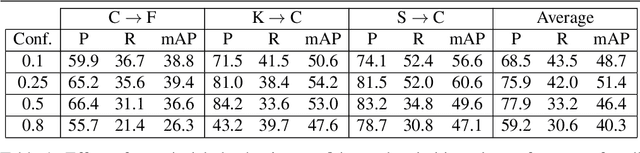

Unsupervised domain adaptation (UDA) plays a crucial role in object detection when adapting a source-trained detector to a target domain without annotated data. In this paper, we propose a novel and effective four-step UDA approach that leverages self-supervision and trains source and target data concurrently. We harness self-supervised learning to mitigate the lack of ground truth in the target domain. Our method consists of the following steps: (1) identify the region with the highest-confidence set of detections in each target image, which serve as our pseudo-labels; (2) crop the identified region and generate a collection of its augmented versions; (3) combine these latter into a composite image; (4) adapt the network to the target domain using the composed image. Through extensive experiments under cross-camera, cross-weather, and synthetic-to-real scenarios, our approach achieves state-of-the-art performance, improving upon the nearest competitor by more than 2% in terms of mean Average Precision (mAP). The code is available at https://github.com/MohamedTEV/DACA.
Correlated and Multi-frequency Diffusion Modeling for Highly Under-sampled MRI Reconstruction
Sep 02, 2023Most existing MRI reconstruction methods perform tar-geted reconstruction of the entire MR image without tak-ing specific tissue regions into consideration. This may fail to emphasize the reconstruction accuracy on im-portant tissues for diagnosis. In this study, leveraging a combination of the properties of k-space data and the diffusion process, our novel scheme focuses on mining the multi-frequency prior with different strategies to pre-serve fine texture details in the reconstructed image. In addition, a diffusion process can converge more quickly if its target distribution closely resembles the noise distri-bution in the process. This can be accomplished through various high-frequency prior extractors. The finding further solidifies the effectiveness of the score-based gen-erative model. On top of all the advantages, our method improves the accuracy of MRI reconstruction and accel-erates sampling process. Experimental results verify that the proposed method successfully obtains more accurate reconstruction and outperforms state-of-the-art methods.