 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
M3Dsynth: A dataset of medical 3D images with AI-generated local manipulations
Sep 14, 2023
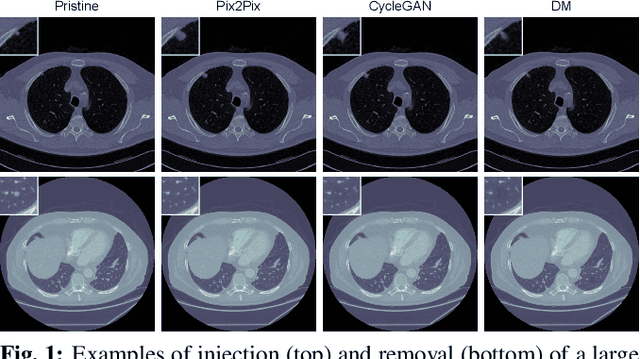
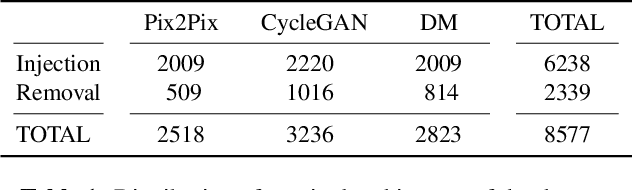
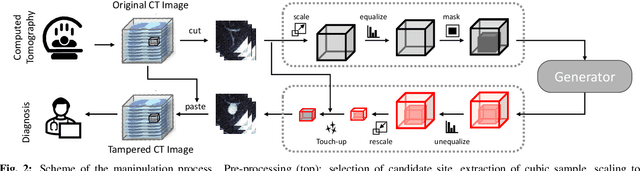
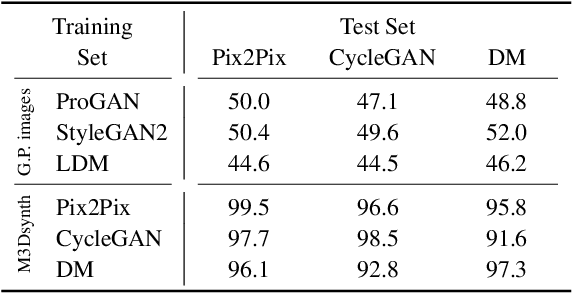
The ability to detect manipulated visual content is becoming increasingly important in many application fields, given the rapid advances in image synthesis methods. Of particular concern is the possibility of modifying the content of medical images, altering the resulting diagnoses. Despite its relevance, this issue has received limited attention from the research community. One reason is the lack of large and curated datasets to use for development and benchmarking purposes. Here, we investigate this issue and propose M3Dsynth, a large dataset of manipulated Computed Tomography (CT) lung images. We create manipulated images by injecting or removing lung cancer nodules in real CT scans, using three different methods based on Generative Adversarial Networks (GAN) or Diffusion Models (DM), for a total of 8,577 manipulated samples. Experiments show that these images easily fool automated diagnostic tools. We also tested several state-of-the-art forensic detectors and demonstrated that, once trained on the proposed dataset, they are able to accurately detect and localize manipulated synthetic content, including when training and test sets are not aligned, showing good generalization ability. Dataset and code will be publicly available at https://grip-unina.github.io/M3Dsynth/.
Padding Aware Neurons
Sep 14, 2023
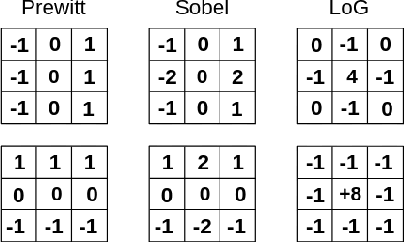

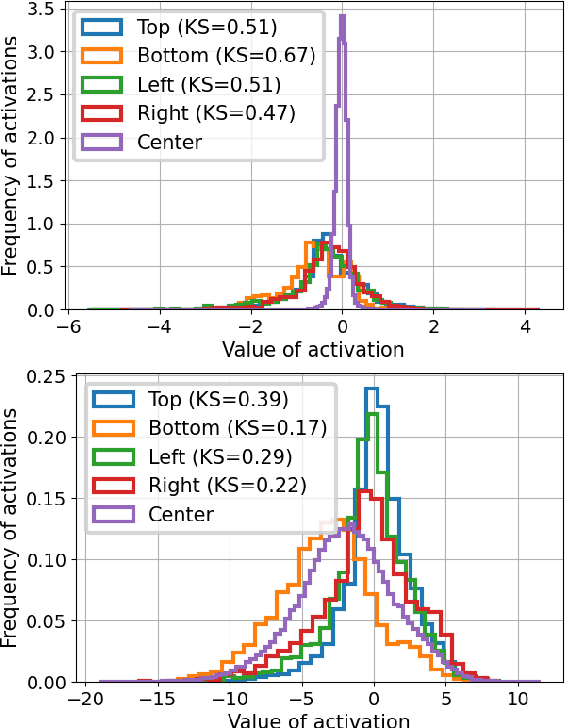
Convolutional layers are a fundamental component of most image-related models. These layers often implement by default a static padding policy (\eg zero padding), to control the scale of the internal representations, and to allow kernel activations centered on the border regions. In this work we identify Padding Aware Neurons (PANs), a type of filter that is found in most (if not all) convolutional models trained with static padding. PANs focus on the characterization and recognition of input border location, introducing a spatial inductive bias into the model (e.g., how close to the input's border a pattern typically is). We propose a method to identify PANs through their activations, and explore their presence in several popular pre-trained models, finding PANs on all models explored, from dozens to hundreds. We discuss and illustrate different types of PANs, their kernels and behaviour. To understand their relevance, we test their impact on model performance, and find padding and PANs to induce strong and characteristic biases in the data. Finally, we discuss whether or not PANs are desirable, as well as the potential side effects of their presence in the context of model performance, generalisation, efficiency and safety.
ACDMSR: Accelerated Conditional Diffusion Models for Single Image Super-Resolution
Jul 03, 2023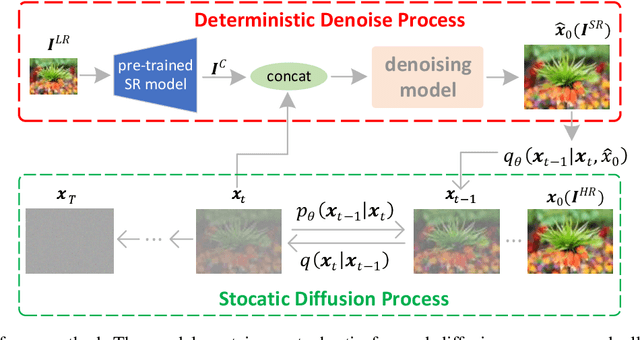
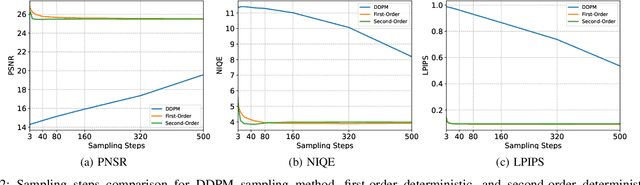
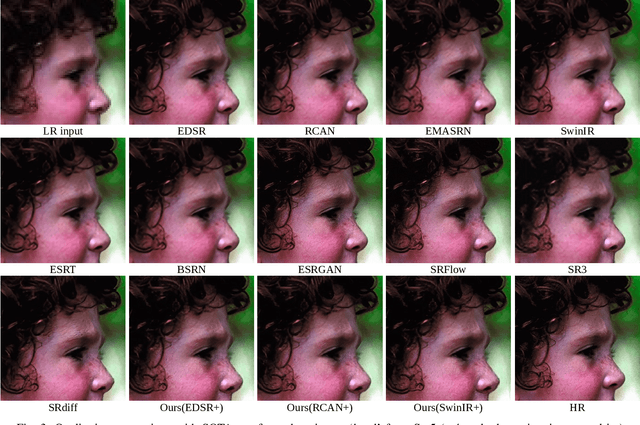

Diffusion models have gained significant popularity in the field of image-to-image translation. Previous efforts applying diffusion models to image super-resolution (SR) have demonstrated that iteratively refining pure Gaussian noise using a U-Net architecture trained on denoising at various noise levels can yield satisfactory high-resolution images from low-resolution inputs. However, this iterative refinement process comes with the drawback of low inference speed, which strongly limits its applications. To speed up inference and further enhance the performance, our research revisits diffusion models in image super-resolution and proposes a straightforward yet significant diffusion model-based super-resolution method called ACDMSR (accelerated conditional diffusion model for image super-resolution). Specifically, our method adapts the standard diffusion model to perform super-resolution through a deterministic iterative denoising process. Our study also highlights the effectiveness of using a pre-trained SR model to provide the conditional image of the given low-resolution (LR) image to achieve superior high-resolution results. We demonstrate that our method surpasses previous attempts in qualitative and quantitative results through extensive experiments conducted on benchmark datasets such as Set5, Set14, Urban100, BSD100, and Manga109. Moreover, our approach generates more visually realistic counterparts for low-resolution images, emphasizing its effectiveness in practical scenarios.
Tree-Structured Shading Decomposition
Sep 13, 2023We study inferring a tree-structured representation from a single image for object shading. Prior work typically uses the parametric or measured representation to model shading, which is neither interpretable nor easily editable. We propose using the shade tree representation, which combines basic shading nodes and compositing methods to factorize object surface shading. The shade tree representation enables novice users who are unfamiliar with the physical shading process to edit object shading in an efficient and intuitive manner. A main challenge in inferring the shade tree is that the inference problem involves both the discrete tree structure and the continuous parameters of the tree nodes. We propose a hybrid approach to address this issue. We introduce an auto-regressive inference model to generate a rough estimation of the tree structure and node parameters, and then we fine-tune the inferred shade tree through an optimization algorithm. We show experiments on synthetic images, captured reflectance, real images, and non-realistic vector drawings, allowing downstream applications such as material editing, vectorized shading, and relighting. Project website: https://chen-geng.com/inv-shade-trees
Ethnicity and Biometric Uniqueness: Iris Pattern Individuality in a West African Database
Sep 12, 2023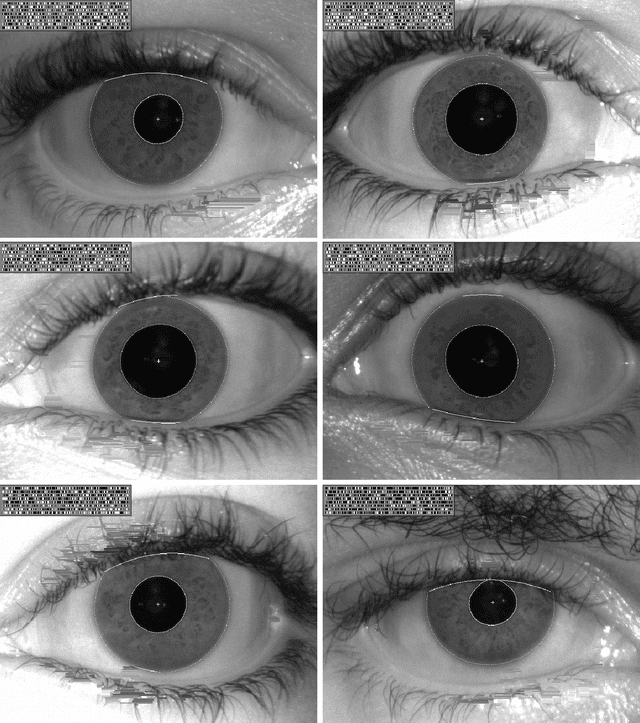
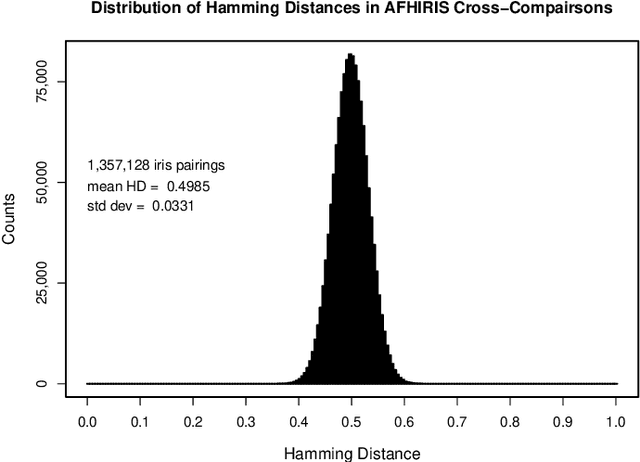
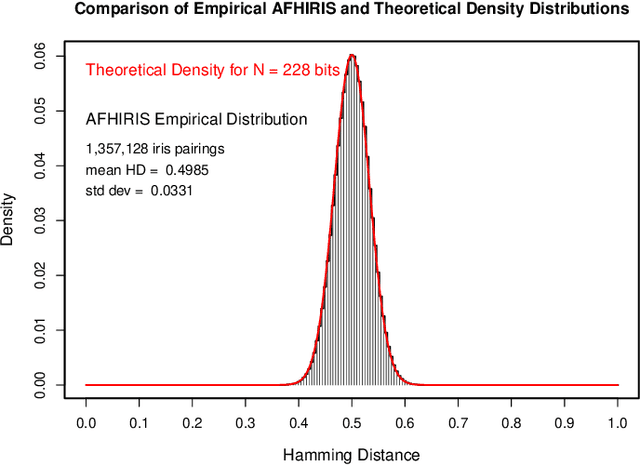
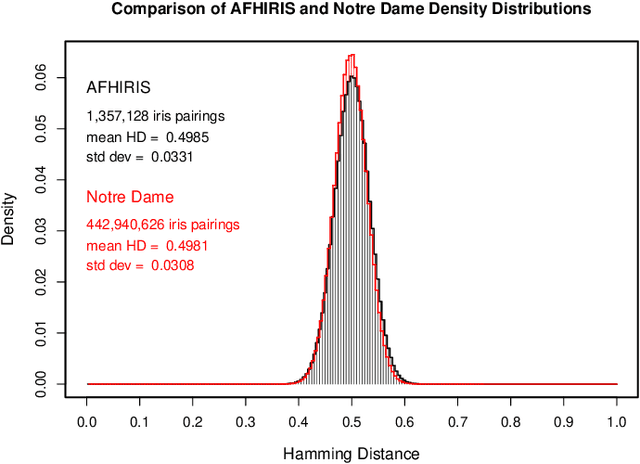
We conducted more than 1.3 million comparisons of iris patterns encoded from images collected at two Nigerian universities, which constitute the newly available African Human Iris (AFHIRIS) database. The purpose was to discover whether ethnic differences in iris structure and appearance such as the textural feature size, as contrasted with an all-Chinese image database or an American database in which only 1.53% were of African-American heritage, made a material difference for iris discrimination. We measured a reduction in entropy for the AFHIRIS database due to the coarser iris features created by the thick anterior layer of melanocytes, and we found stochastic parameters that accurately model the relevant empirical distributions. Quantile-Quantile analysis revealed that a very small change in operational decision thresholds for the African database would compensate for the reduced entropy and generate the same performance in terms of resistance to False Matches. We conclude that despite demographic difference, individuality can be robustly discerned by comparison of iris patterns in this West African population.
ATTA: Anomaly-aware Test-Time Adaptation for Out-of-Distribution Detection in Segmentation
Sep 12, 2023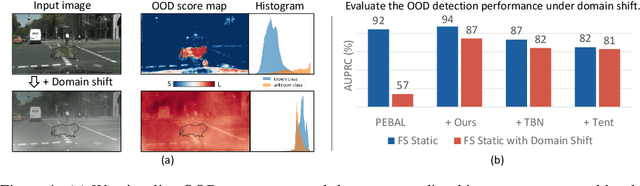

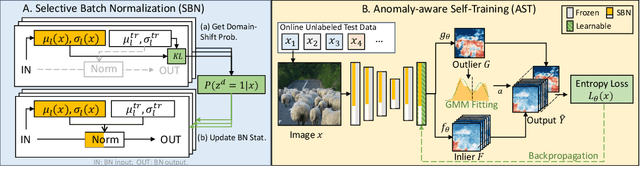
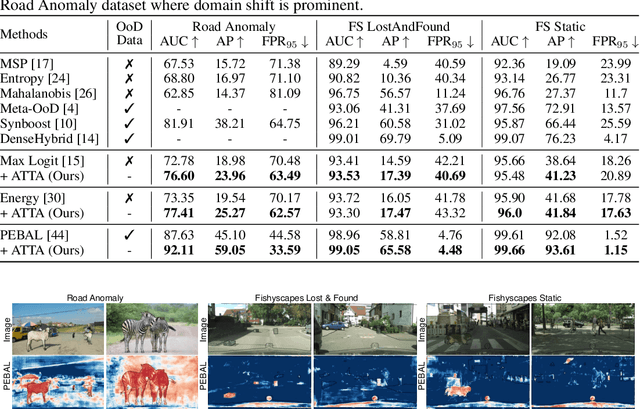
Recent advancements in dense out-of-distribution (OOD) detection have primarily focused on scenarios where the training and testing datasets share a similar domain, with the assumption that no domain shift exists between them. However, in real-world situations, domain shift often exits and significantly affects the accuracy of existing out-of-distribution (OOD) detection models. In this work, we propose a dual-level OOD detection framework to handle domain shift and semantic shift jointly. The first level distinguishes whether domain shift exists in the image by leveraging global low-level features, while the second level identifies pixels with semantic shift by utilizing dense high-level feature maps. In this way, we can selectively adapt the model to unseen domains as well as enhance model's capacity in detecting novel classes. We validate the efficacy of our proposed method on several OOD segmentation benchmarks, including those with significant domain shifts and those without, observing consistent performance improvements across various baseline models.
Towards a Holodeck-style Simulation Game
Sep 12, 2023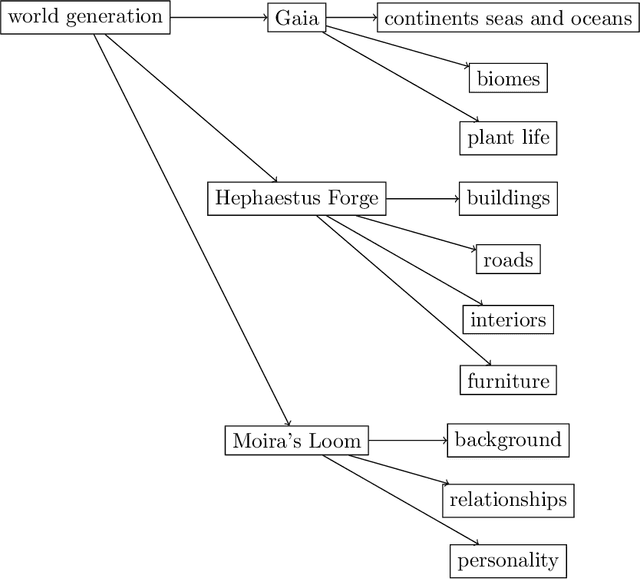


We introduce Infinitia, a simulation game system that uses generative image and language models at play time to reshape all aspects of the setting and NPCs based on a short description from the player, in a way similar to how settings are created on the fictional Holodeck. Building off the ideas of the Generative Agents paper, our system introduces gameplay elements, such as infinite generated fantasy worlds, controllability of NPC behavior, humorous dialogue, cost & time efficiency, collaboration between players and elements of non-determinism among in-game events. Infinitia is implemented in the Unity engine with a server-client architecture, facilitating the addition of exciting features by community developers in the future. Furthermore, it uses a multiplayer framework to allow humans to be present and interact in the simulation. The simulation will be available in open-alpha shortly at https://infinitia.ai/ and we are looking forward to building upon it with the community.
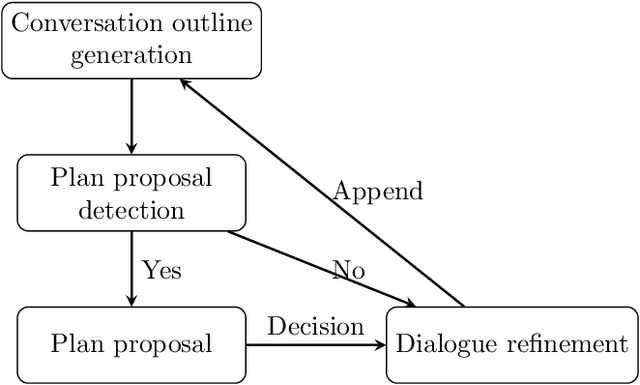
Framing image registration as a landmark detection problem for better representation of clinical relevance
Jul 31, 2023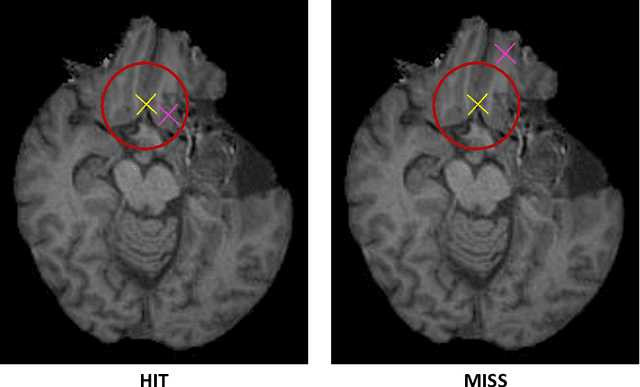
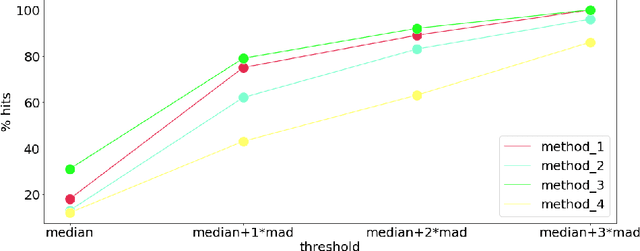
Nowadays, registration methods are typically evaluated based on sub-resolution tracking error differences. In an effort to reinfuse this evaluation process with clinical relevance, we propose to reframe image registration as a landmark detection problem. Ideally, landmark-specific detection thresholds are derived from an inter-rater analysis. To approximate this costly process, we propose to compute hit rate curves based on the distribution of errors of a sub-sample inter-rater analysis. Therefore, we suggest deriving thresholds from the error distribution using the formula: median + delta * median absolute deviation. The method promises differentiation of previously indistinguishable registration algorithms and further enables assessing the clinical significance in algorithm development.
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Jul 10, 2023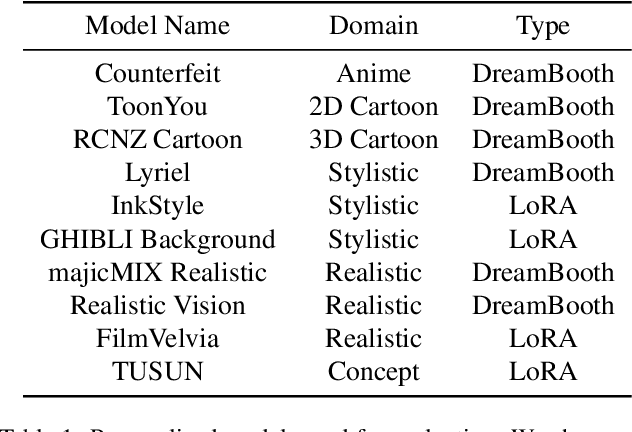
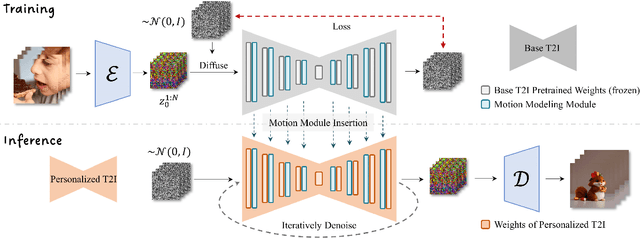
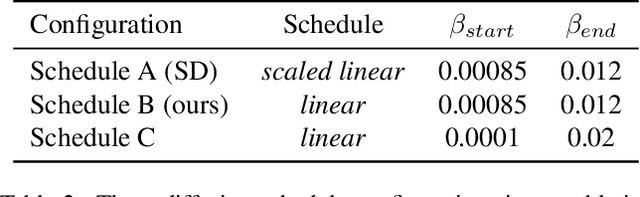
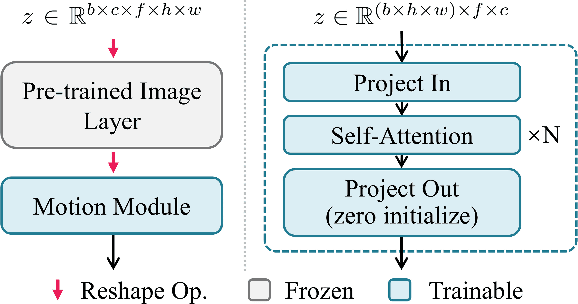
With the advance of text-to-image models (e.g., Stable Diffusion) and corresponding personalization techniques such as DreamBooth and LoRA, everyone can manifest their imagination into high-quality images at an affordable cost. Subsequently, there is a great demand for image animation techniques to further combine generated static images with motion dynamics. In this report, we propose a practical framework to animate most of the existing personalized text-to-image models once and for all, saving efforts in model-specific tuning. At the core of the proposed framework is to insert a newly initialized motion modeling module into the frozen text-to-image model and train it on video clips to distill reasonable motion priors. Once trained, by simply injecting this motion modeling module, all personalized versions derived from the same base T2I readily become text-driven models that produce diverse and personalized animated images. We conduct our evaluation on several public representative personalized text-to-image models across anime pictures and realistic photographs, and demonstrate that our proposed framework helps these models generate temporally smooth animation clips while preserving the domain and diversity of their outputs. Code and pre-trained weights will be publicly available at https://animatediff.github.io/ .
BoxDiff: Text-to-Image Synthesis with Training-Free Box-Constrained Diffusion
Jul 22, 2023


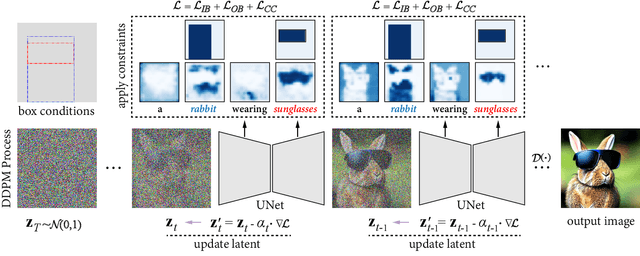
Recent text-to-image diffusion models have demonstrated an astonishing capacity to generate high-quality images. However, researchers mainly studied the way of synthesizing images with only text prompts. While some works have explored using other modalities as conditions, considerable paired data, e.g., box/mask-image pairs, and fine-tuning time are required for nurturing models. As such paired data is time-consuming and labor-intensive to acquire and restricted to a closed set, this potentially becomes the bottleneck for applications in an open world. This paper focuses on the simplest form of user-provided conditions, e.g., box or scribble. To mitigate the aforementioned problem, we propose a training-free method to control objects and contexts in the synthesized images adhering to the given spatial conditions. Specifically, three spatial constraints, i.e., Inner-Box, Outer-Box, and Corner Constraints, are designed and seamlessly integrated into the denoising step of diffusion models, requiring no additional training and massive annotated layout data. Extensive results show that the proposed constraints can control what and where to present in the images while retaining the ability of the Stable Diffusion model to synthesize with high fidelity and diverse concept coverage. The code is publicly available at https://github.com/Sierkinhane/BoxDiff.