 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BTSeg: Barlow Twins Regularization for Domain Adaptation in Semantic Segmentation
Aug 31, 2023
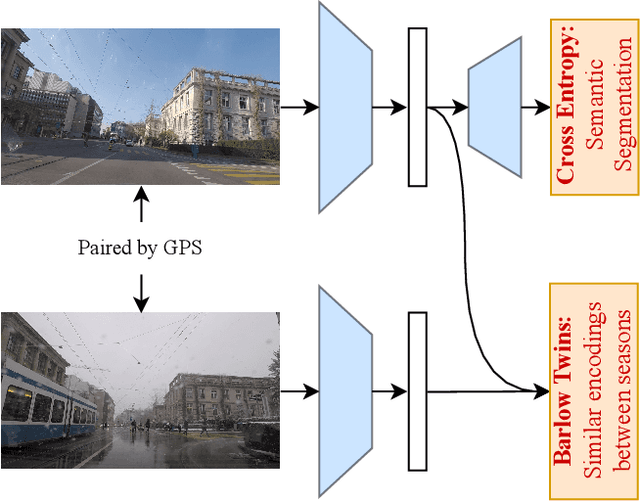
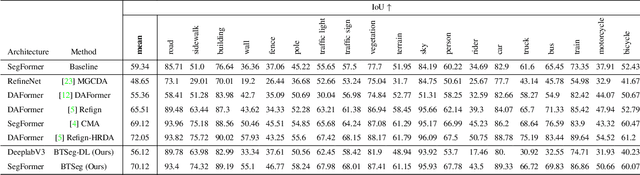
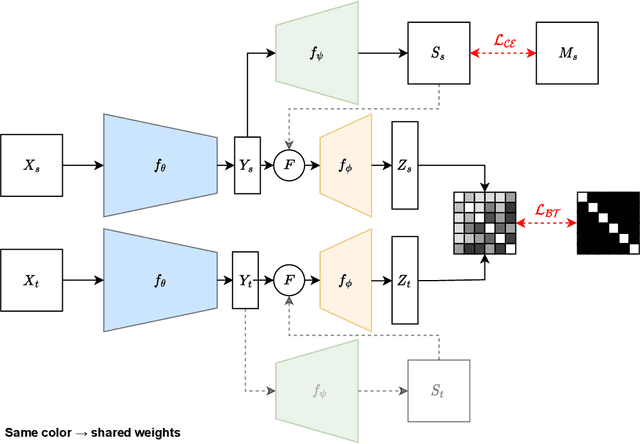
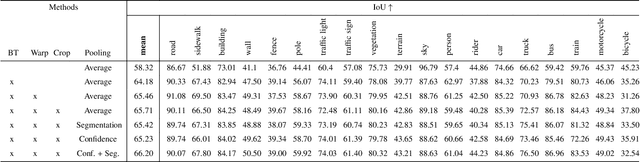
Semantic image segmentation is a critical component in many computer vision systems, such as autonomous driving. In such applications, adverse conditions (heavy rain, night time, snow, extreme lighting) on the one hand pose specific challenges, yet are typically underrepresented in the available datasets. Generating more training data is cumbersome and expensive, and the process itself is error-prone due to the inherent aleatoric uncertainty. To address this challenging problem, we propose BTSeg, which exploits image-level correspondences as weak supervision signal to learn a segmentation model that is agnostic to adverse conditions. To this end, our approach uses the Barlow twins loss from the field of unsupervised learning and treats images taken at the same location but under different adverse conditions as "augmentations" of the same unknown underlying base image. This allows the training of a segmentation model that is robust to appearance changes introduced by different adverse conditions. We evaluate our approach on ACDC and the new challenging ACG benchmark to demonstrate its robustness and generalization capabilities. Our approach performs favorably when compared to the current state-of-the-art methods, while also being simpler to implement and train. The code will be released upon acceptance.
Learning Channel Importance for High Content Imaging with Interpretable Deep Input Channel Mixing
Aug 31, 2023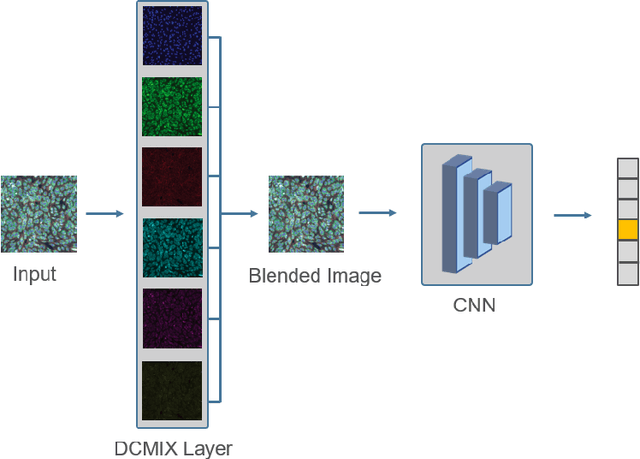

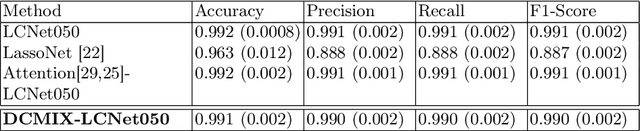
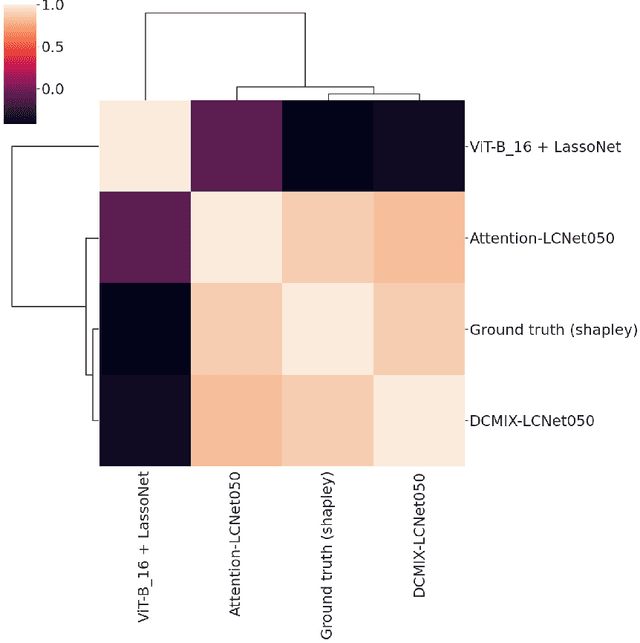
Uncovering novel drug candidates for treating complex diseases remain one of the most challenging tasks in early discovery research. To tackle this challenge, biopharma research established a standardized high content imaging protocol that tags different cellular compartments per image channel. In order to judge the experimental outcome, the scientist requires knowledge about the channel importance with respect to a certain phenotype for decoding the underlying biology. In contrast to traditional image analysis approaches, such experiments are nowadays preferably analyzed by deep learning based approaches which, however, lack crucial information about the channel importance. To overcome this limitation, we present a novel approach which utilizes multi-spectral information of high content images to interpret a certain aspect of cellular biology. To this end, we base our method on image blending concepts with alpha compositing for an arbitrary number of channels. More specifically, we introduce DCMIX, a lightweight, scaleable and end-to-end trainable mixing layer which enables interpretable predictions in high content imaging while retaining the benefits of deep learning based methods. We employ an extensive set of experiments on both MNIST and RXRX1 datasets, demonstrating that DCMIX learns the biologically relevant channel importance without scarifying prediction performance.
Can Pre-Trained Text-to-Image Models Generate Visual Goals for Reinforcement Learning?
Jul 15, 2023Pre-trained text-to-image generative models can produce diverse, semantically rich, and realistic images from natural language descriptions. Compared with language, images usually convey information with more details and less ambiguity. In this study, we propose Learning from the Void (LfVoid), a method that leverages the power of pre-trained text-to-image models and advanced image editing techniques to guide robot learning. Given natural language instructions, LfVoid can edit the original observations to obtain goal images, such as "wiping" a stain off a table. Subsequently, LfVoid trains an ensembled goal discriminator on the generated image to provide reward signals for a reinforcement learning agent, guiding it to achieve the goal. The ability of LfVoid to learn with zero in-domain training on expert demonstrations or true goal observations (the void) is attributed to the utilization of knowledge from web-scale generative models. We evaluate LfVoid across three simulated tasks and validate its feasibility in the corresponding real-world scenarios. In addition, we offer insights into the key considerations for the effective integration of visual generative models into robot learning workflows. We posit that our work represents an initial step towards the broader application of pre-trained visual generative models in the robotics field. Our project page: https://lfvoid-rl.github.io/.
Remote Sensing Image Change Detection with Graph Interaction
Jul 05, 2023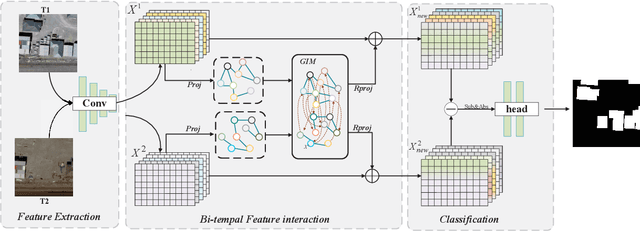
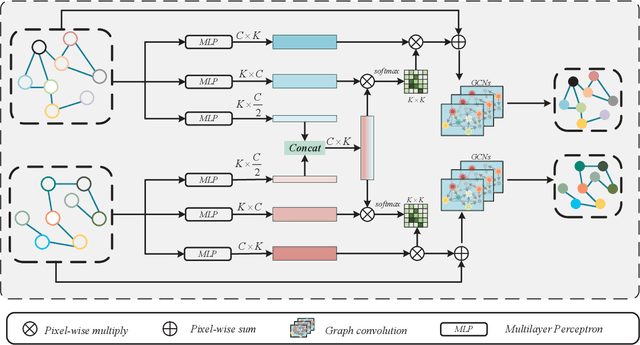

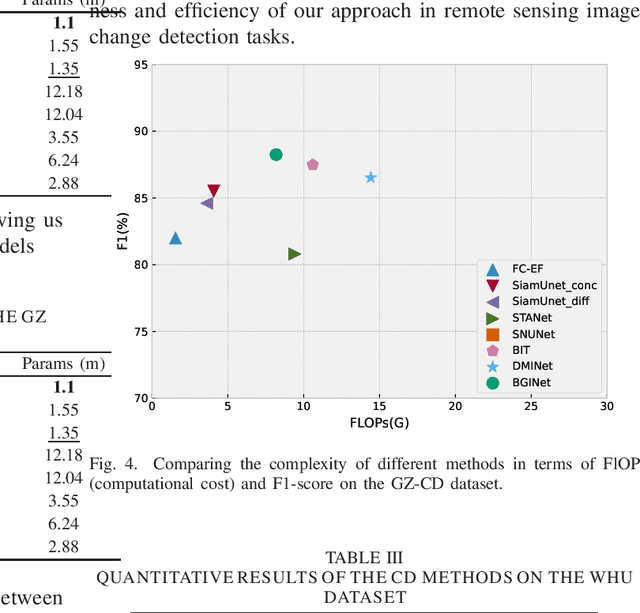
Modern remote sensing image change detection has witnessed substantial advancements by harnessing the potent feature extraction capabilities of CNNs and Transforms.Yet,prevailing change detection techniques consistently prioritize extracting semantic features related to significant alterations,overlooking the viability of directly interacting with bitemporal image features.In this letter,we propose a bitemporal image graph Interaction network for remote sensing change detection,namely BGINet-CD. More specifically,by leveraging the concept of non-local operations and mapping the features obtained from the backbone network to the graph structure space,we propose a unified self-focus mechanism for bitemporal images.This approach enhances the information coupling between the two temporal images while effectively suppressing task-irrelevant interference,Based on a streamlined backbone architecture,namely ResNet18,our model demonstrates superior performance compared to other state-of-the-art methods (SOTA) on the GZ CD dataset. Moreover,the model exhibits an enhanced trade-off between accuracy and computational efficiency,further improving its overall effectiveness
A horizon line annotation tool for streamlining autonomous sea navigation experiments
Sep 11, 2023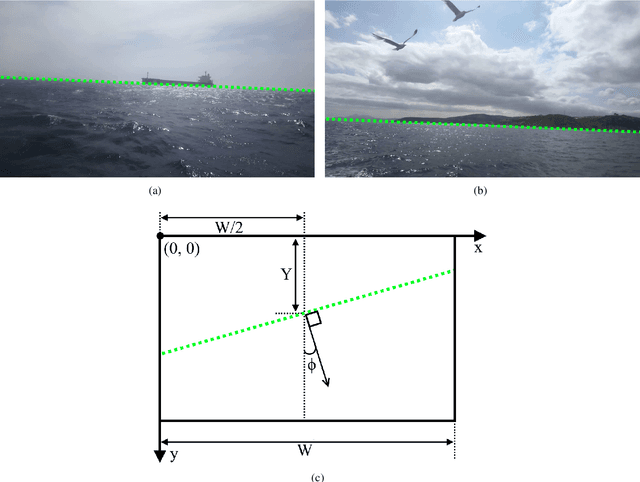
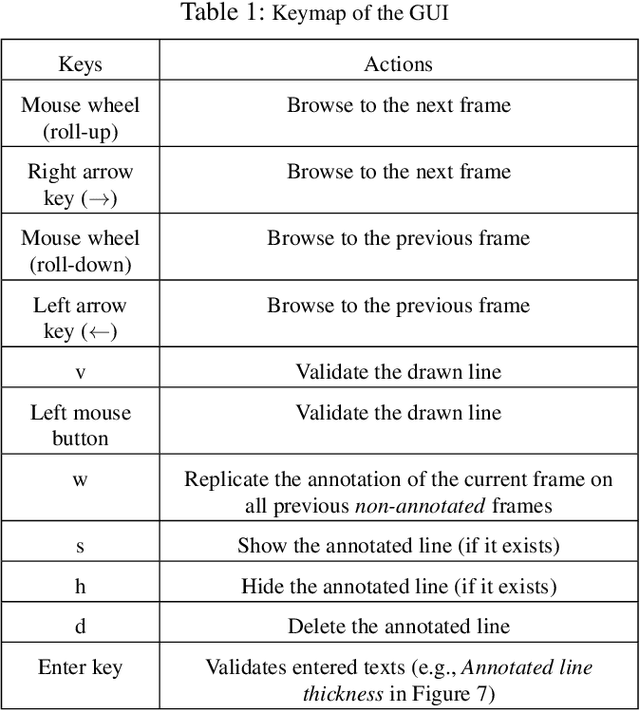

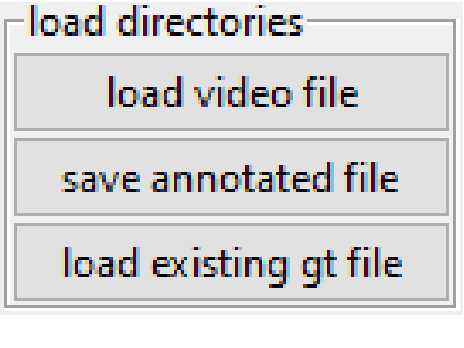
Horizon line (or sea line) detection (HLD) is a critical component in multiple marine autonomous navigation tasks, such as identifying the navigation area (i.e., the sea), obstacle detection and geo-localization, and digital video stabilization. A recent survey highlighted several weaknesses of such detectors, particularly on sea conditions lacking from the most extensive dataset currently used by HLD researchers. Experimental validation of more robust HLDs involves collecting an extensive set of these lacking sea conditions and annotating each collected image with the correct position and orientation of the horizon line. The annotation task is daunting without a proper tool. Therefore, we present the first public annotation software with tailored features to make the sea line annotation process fast and easy. The software is available at: https://drive.google.com/drive/folders/1c0ZmvYDckuQCPIWfh_70P7E1A_DWlIvF?usp=sharing
Augmenting Chest X-ray Datasets with Non-Expert Annotations
Sep 05, 2023The advancement of machine learning algorithms in medical image analysis requires the expansion of training datasets. A popular and cost-effective approach is automated annotation extraction from free-text medical reports, primarily due to the high costs associated with expert clinicians annotating chest X-ray images. However, it has been shown that the resulting datasets are susceptible to biases and shortcuts. Another strategy to increase the size of a dataset is crowdsourcing, a widely adopted practice in general computer vision with some success in medical image analysis. In a similar vein to crowdsourcing, we enhance two publicly available chest X-ray datasets by incorporating non-expert annotations. However, instead of using diagnostic labels, we annotate shortcuts in the form of tubes. We collect 3.5k chest drain annotations for CXR14, and 1k annotations for 4 different tube types in PadChest. We train a chest drain detector with the non-expert annotations that generalizes well to expert labels. Moreover, we compare our annotations to those provided by experts and show "moderate" to "almost perfect" agreement. Finally, we present a pathology agreement study to raise awareness about ground truth annotations. We make our annotations and code available.
SR-R$^2$KAC: Improving Single Image Defocus Deblurring
Jul 30, 2023
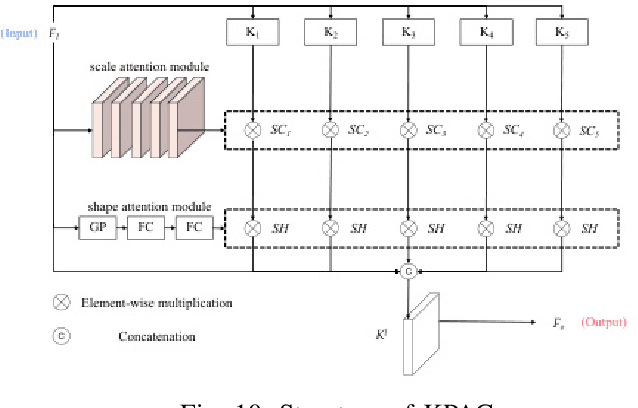


We propose an efficient deep learning method for single image defocus deblurring (SIDD) by further exploring inverse kernel properties. Although the current inverse kernel method, i.e., kernel-sharing parallel atrous convolution (KPAC), can address spatially varying defocus blurs, it has difficulty in handling large blurs of this kind. To tackle this issue, we propose a Residual and Recursive Kernel-sharing Atrous Convolution (R$^2$KAC). R$^2$KAC builds on a significant observation of inverse kernels, that is, successive use of inverse-kernel-based deconvolutions with fixed size helps remove unexpected large blurs but produces ringing artifacts. Specifically, on top of kernel-sharing atrous convolutions used to simulate multi-scale inverse kernels, R$^2$KAC applies atrous convolutions recursively to simulate a large inverse kernel. Specifically, on top of kernel-sharing atrous convolutions, R$^2$KAC stacks atrous convolutions recursively to simulate a large inverse kernel. To further alleviate the contingent effect of recursive stacking, i.e., ringing artifacts, we add identity shortcuts between atrous convolutions to simulate residual deconvolutions. Lastly, a scale recurrent module is embedded in the R$^2$KAC network, leading to SR-R$^2$KAC, so that multi-scale information from coarse to fine is exploited to progressively remove the spatially varying defocus blurs. Extensive experimental results show that our method achieves the state-of-the-art performance.
Delving into Multimodal Prompting for Fine-grained Visual Classification
Sep 16, 2023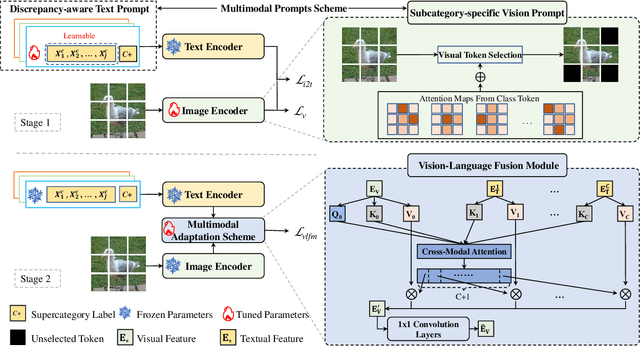
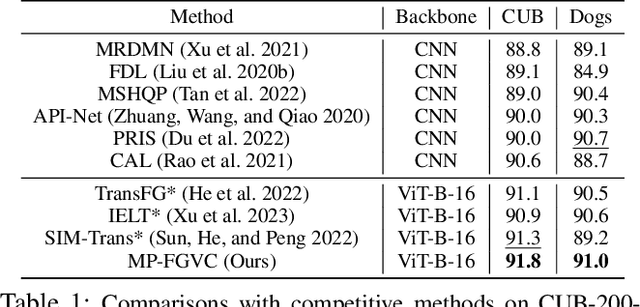
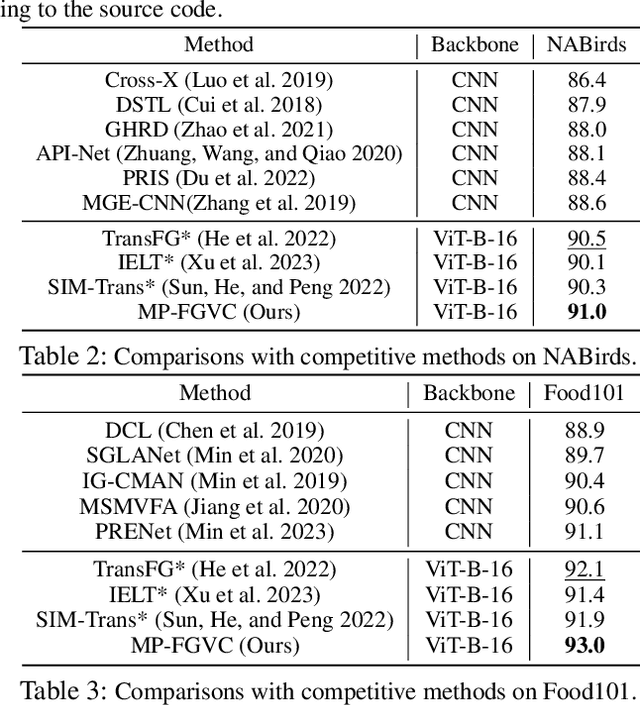
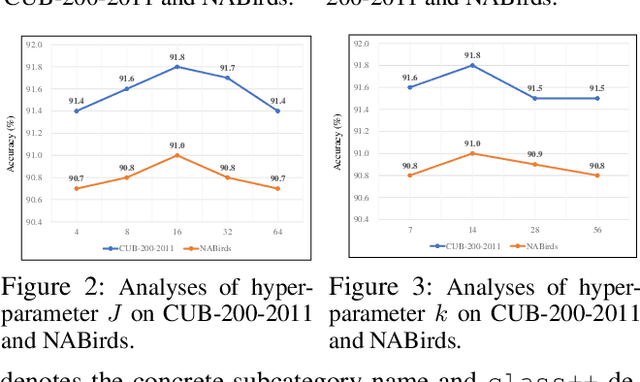
Fine-grained visual classification (FGVC) involves categorizing fine subdivisions within a broader category, which poses challenges due to subtle inter-class discrepancies and large intra-class variations. However, prevailing approaches primarily focus on uni-modal visual concepts. Recent advancements in pre-trained vision-language models have demonstrated remarkable performance in various high-level vision tasks, yet the applicability of such models to FGVC tasks remains uncertain. In this paper, we aim to fully exploit the capabilities of cross-modal description to tackle FGVC tasks and propose a novel multimodal prompting solution, denoted as MP-FGVC, based on the contrastive language-image pertaining (CLIP) model. Our MP-FGVC comprises a multimodal prompts scheme and a multimodal adaptation scheme. The former includes Subcategory-specific Vision Prompt (SsVP) and Discrepancy-aware Text Prompt (DaTP), which explicitly highlights the subcategory-specific discrepancies from the perspectives of both vision and language. The latter aligns the vision and text prompting elements in a common semantic space, facilitating cross-modal collaborative reasoning through a Vision-Language Fusion Module (VLFM) for further improvement on FGVC. Moreover, we tailor a two-stage optimization strategy for MP-FGVC to fully leverage the pre-trained CLIP model and expedite efficient adaptation for FGVC. Extensive experiments conducted on four FGVC datasets demonstrate the effectiveness of our MP-FGVC.
OmniLRS: A Photorealistic Simulator for Lunar Robotics
Sep 16, 2023


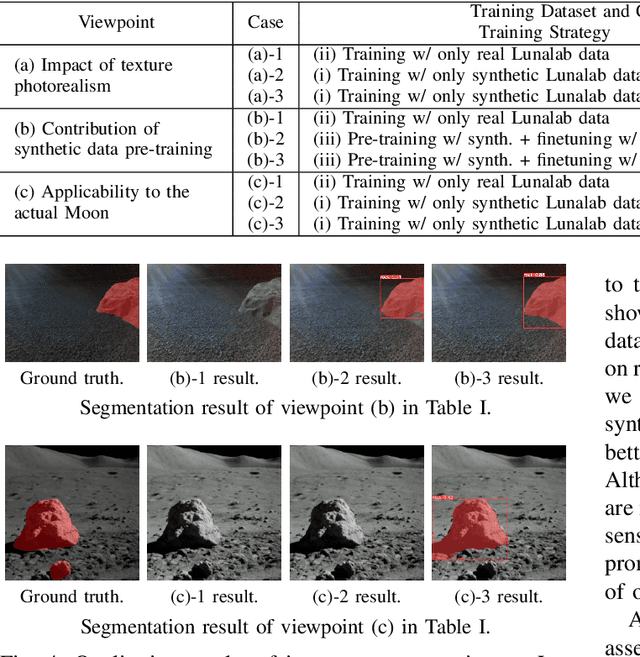
Developing algorithms for extra-terrestrial robotic exploration has always been challenging. Along with the complexity associated with these environments, one of the main issues remains the evaluation of said algorithms. With the regained interest in lunar exploration, there is also a demand for quality simulators that will enable the development of lunar robots. % In this paper, we explain how we built a Lunar simulator based on Isaac Sim, Nvidia's robotic simulator. In this paper, we propose Omniverse Lunar Robotic-Sim (OmniLRS) that is a photorealistic Lunar simulator based on Nvidia's robotic simulator. This simulation provides fast procedural environment generation, multi-robot capabilities, along with synthetic data pipeline for machine-learning applications. It comes with ROS1 and ROS2 bindings to control not only the robots, but also the environments. This work also performs sim-to-real rock instance segmentation to show the effectiveness of our simulator for image-based perception. Trained on our synthetic data, a yolov8 model achieves performance close to a model trained on real-world data, with 5% performance gap. When finetuned with real data, the model achieves 14% higher average precision than the model trained on real-world data, demonstrating our simulator's photorealism.% to realize sim-to-real. The code is fully open-source, accessible here: https://github.com/AntoineRichard/LunarSim, and comes with demonstrations.
Implicit Neural Feature Fusion Function for Multispectral and Hyperspectral Image Fusion
Jul 14, 2023Multispectral and Hyperspectral Image Fusion (MHIF) is a practical task that aims to fuse a high-resolution multispectral image (HR-MSI) and a low-resolution hyperspectral image (LR-HSI) of the same scene to obtain a high-resolution hyperspectral image (HR-HSI). Benefiting from powerful inductive bias capability, CNN-based methods have achieved great success in the MHIF task. However, they lack certain interpretability and require convolution structures be stacked to enhance performance. Recently, Implicit Neural Representation (INR) has achieved good performance and interpretability in 2D tasks due to its ability to locally interpolate samples and utilize multimodal content such as pixels and coordinates. Although INR-based approaches show promise, they require extra construction of high-frequency information (\emph{e.g.,} positional encoding). In this paper, inspired by previous work of MHIF task, we realize that HR-MSI could serve as a high-frequency detail auxiliary input, leading us to propose a novel INR-based hyperspectral fusion function named Implicit Neural Feature Fusion Function (INF). As an elaborate structure, it solves the MHIF task and addresses deficiencies in the INR-based approaches. Specifically, our INF designs a Dual High-Frequency Fusion (DHFF) structure that obtains high-frequency information twice from HR-MSI and LR-HSI, then subtly fuses them with coordinate information. Moreover, the proposed INF incorporates a parameter-free method named INR with cosine similarity (INR-CS) that uses cosine similarity to generate local weights through feature vectors. Based on INF, we construct an Implicit Neural Fusion Network (INFN) that achieves state-of-the-art performance for MHIF tasks of two public datasets, \emph{i.e.,} CAVE and Harvard. The code will soon be made available on GitHub.