 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reconstructing Existing Levels through Level Inpainting
Sep 18, 2023
Procedural Content Generation (PCG) and Procedural Content Generation via Machine Learning (PCGML) have been used in prior work for generating levels in various games. This paper introduces Content Augmentation and focuses on the subproblem of level inpainting, which involves reconstructing and extending video game levels. Drawing inspiration from image inpainting, we adapt two techniques from this domain to address our specific use case. We present two approaches for level inpainting: an Autoencoder and a U-net. Through a comprehensive case study, we demonstrate their superior performance compared to a baseline method and discuss their relative merits. Furthermore, we provide a practical demonstration of both approaches for the level inpainting task and offer insights into potential directions for future research.
Does Video Summarization Require Videos? Quantifying the Effectiveness of Language in Video Summarization
Sep 18, 2023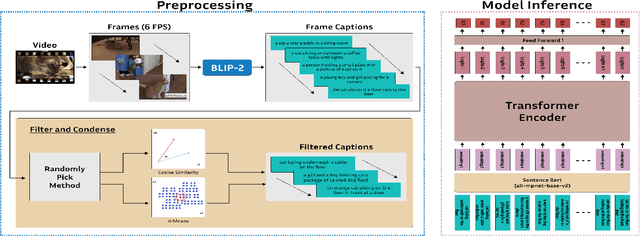
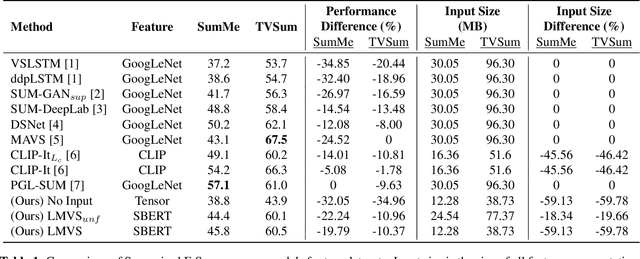

Video summarization remains a huge challenge in computer vision due to the size of the input videos to be summarized. We propose an efficient, language-only video summarizer that achieves competitive accuracy with high data efficiency. Using only textual captions obtained via a zero-shot approach, we train a language transformer model and forego image representations. This method allows us to perform filtration amongst the representative text vectors and condense the sequence. With our approach, we gain explainability with natural language that comes easily for human interpretation and textual summaries of the videos. An ablation study that focuses on modality and data compression shows that leveraging text modality only effectively reduces input data processing while retaining comparable results.
My Art My Choice: Adversarial Protection Against Unruly AI
Sep 06, 2023Generative AI is on the rise, enabling everyone to produce realistic content via publicly available interfaces. Especially for guided image generation, diffusion models are changing the creator economy by producing high quality low cost content. In parallel, artists are rising against unruly AI, since their artwork are leveraged, distributed, and dissimulated by large generative models. Our approach, My Art My Choice (MAMC), aims to empower content owners by protecting their copyrighted materials from being utilized by diffusion models in an adversarial fashion. MAMC learns to generate adversarially perturbed "protected" versions of images which can in turn "break" diffusion models. The perturbation amount is decided by the artist to balance distortion vs. protection of the content. MAMC is designed with a simple UNet-based generator, attacking black box diffusion models, combining several losses to create adversarial twins of the original artwork. We experiment on three datasets for various image-to-image tasks, with different user control values. Both protected image and diffusion output results are evaluated in visual, noise, structure, pixel, and generative spaces to validate our claims. We believe that MAMC is a crucial step for preserving ownership information for AI generated content in a flawless, based-on-need, and human-centric way.
Deep Networks as Denoising Algorithms: Sample-Efficient Learning of Diffusion Models in High-Dimensional Graphical Models
Sep 20, 2023We investigate the approximation efficiency of score functions by deep neural networks in diffusion-based generative modeling. While existing approximation theories utilize the smoothness of score functions, they suffer from the curse of dimensionality for intrinsically high-dimensional data. This limitation is pronounced in graphical models such as Markov random fields, common for image distributions, where the approximation efficiency of score functions remains unestablished. To address this, we observe score functions can often be well-approximated in graphical models through variational inference denoising algorithms. Furthermore, these algorithms are amenable to efficient neural network representation. We demonstrate this in examples of graphical models, including Ising models, conditional Ising models, restricted Boltzmann machines, and sparse encoding models. Combined with off-the-shelf discretization error bounds for diffusion-based sampling, we provide an efficient sample complexity bound for diffusion-based generative modeling when the score function is learned by deep neural networks.
VideoGen: A Reference-Guided Latent Diffusion Approach for High Definition Text-to-Video Generation
Sep 01, 2023
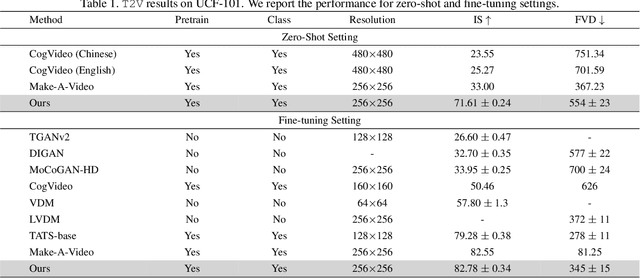

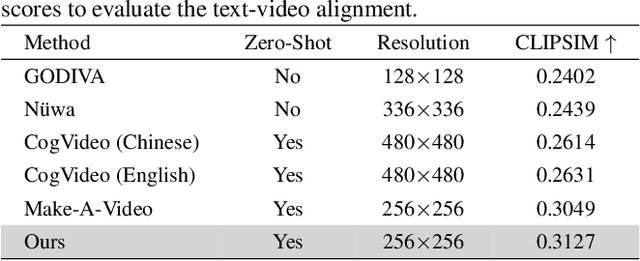
In this paper, we present VideoGen, a text-to-video generation approach, which can generate a high-definition video with high frame fidelity and strong temporal consistency using reference-guided latent diffusion. We leverage an off-the-shelf text-to-image generation model, e.g., Stable Diffusion, to generate an image with high content quality from the text prompt, as a reference image to guide video generation. Then, we introduce an efficient cascaded latent diffusion module conditioned on both the reference image and the text prompt, for generating latent video representations, followed by a flow-based temporal upsampling step to improve the temporal resolution. Finally, we map latent video representations into a high-definition video through an enhanced video decoder. During training, we use the first frame of a ground-truth video as the reference image for training the cascaded latent diffusion module. The main characterises of our approach include: the reference image generated by the text-to-image model improves the visual fidelity; using it as the condition makes the diffusion model focus more on learning the video dynamics; and the video decoder is trained over unlabeled video data, thus benefiting from high-quality easily-available videos. VideoGen sets a new state-of-the-art in text-to-video generation in terms of both qualitative and quantitative evaluation.
Compressive Image Scanning Microscope
Jul 19, 2023
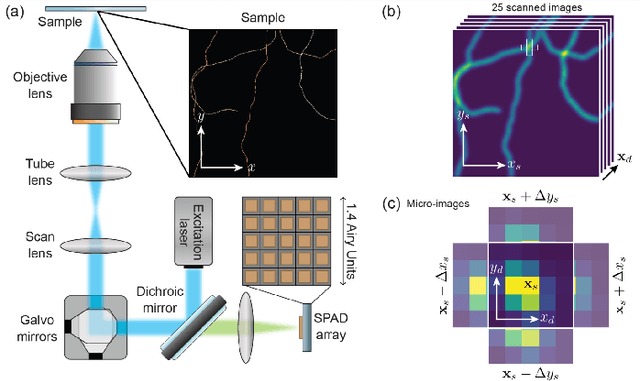

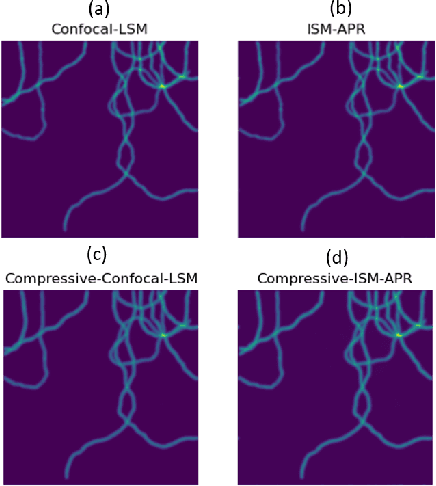
We present a novel approach to implement compressive sensing in laser scanning microscopes (LSM), specifically in image scanning microscopy (ISM), using a single-photon avalanche diode (SPAD) array detector. Our method addresses two significant limitations in applying compressive sensing to LSM: the time to compute the sampling matrix and the quality of reconstructed images. We employ a fixed sampling strategy, skipping alternate rows and columns during data acquisition, which reduces the number of points scanned by a factor of four and eliminates the need to compute different sampling matrices. By exploiting the parallel images generated by the SPAD array, we improve the quality of the reconstructed compressive-ISM images compared to standard compressive confocal LSM images. Our results demonstrate the effectiveness of our approach in producing higher-quality images with reduced data acquisition time and potential benefits in reducing photobleaching.
Knowledge Graph Embeddings for Multi-Lingual Structured Representations of Radiology Reports
Sep 14, 2023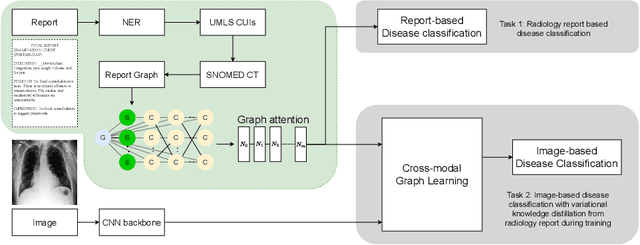
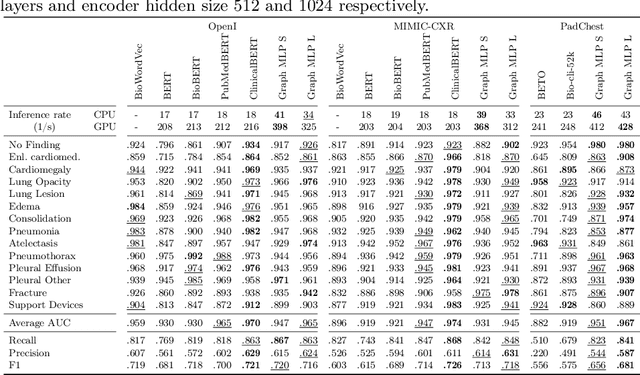

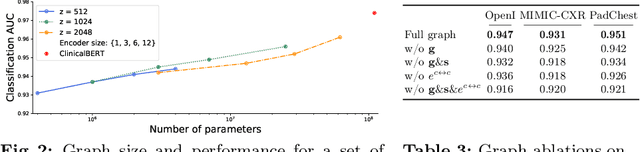
The way we analyse clinical texts has undergone major changes over the last years. The introduction of language models such as BERT led to adaptations for the (bio)medical domain like PubMedBERT and ClinicalBERT. These models rely on large databases of archived medical documents. While performing well in terms of accuracy, both the lack of interpretability and limitations to transfer across languages limit their use in clinical setting. We introduce a novel light-weight graph-based embedding method specifically catering radiology reports. It takes into account the structure and composition of the report, while also connecting medical terms in the report through the multi-lingual SNOMED Clinical Terms knowledge base. The resulting graph embedding uncovers the underlying relationships among clinical terms, achieving a representation that is better understandable for clinicians and clinically more accurate, without reliance on large pre-training datasets. We show the use of this embedding on two tasks namely disease classification of X-ray reports and image classification. For disease classification our model is competitive with its BERT-based counterparts, while being magnitudes smaller in size and training data requirements. For image classification, we show the effectiveness of the graph embedding leveraging cross-modal knowledge transfer and show how this method is usable across different languages.
NineRec: A Benchmark Dataset Suite for Evaluating Transferable Recommendation
Sep 14, 2023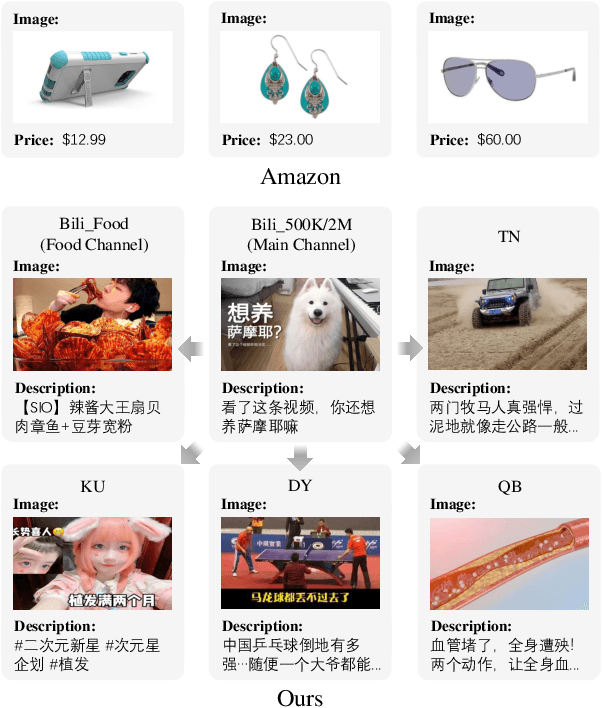
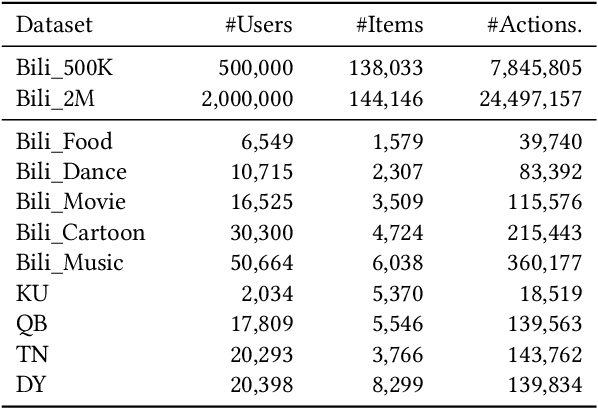
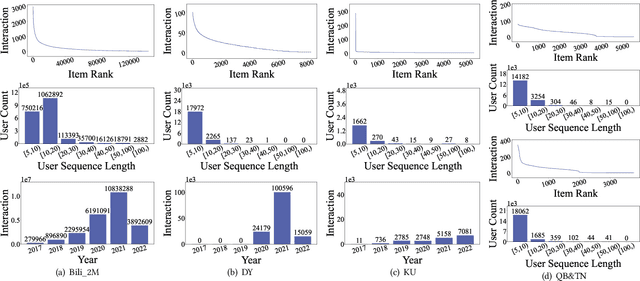
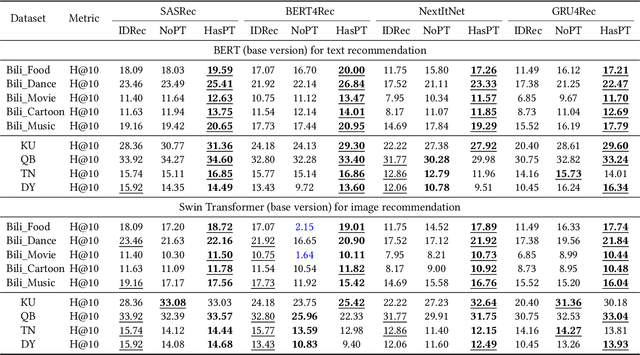
Learning a recommender system model from an item's raw modality features (such as image, text, audio, etc.), called MoRec, has attracted growing interest recently. One key advantage of MoRec is that it can easily benefit from advances in other fields, such as natural language processing (NLP) and computer vision (CV). Moreover, it naturally supports transfer learning across different systems through modality features, known as transferable recommender systems, or TransRec. However, so far, TransRec has made little progress, compared to groundbreaking foundation models in the fields of NLP and CV. The lack of large-scale, high-quality recommendation datasets poses a major obstacle. To this end, we introduce NineRec, a TransRec dataset suite that includes a large-scale source domain recommendation dataset and nine diverse target domain recommendation datasets. Each item in NineRec is represented by a text description and a high-resolution cover image. With NineRec, we can implement TransRec models in an end-to-end training manner instead of using pre-extracted invariant features. We conduct a benchmark study and empirical analysis of TransRec using NineRec, and our findings provide several valuable insights. To support further research, we make our code, datasets, benchmarks, and leaderboards publicly available at https://github.com/anonymous?ninerec/NineRec.
ALWOD: Active Learning for Weakly-Supervised Object Detection
Sep 14, 2023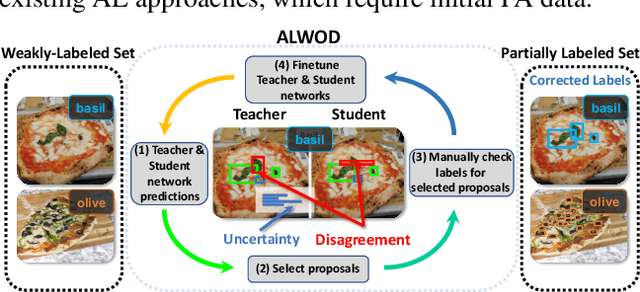

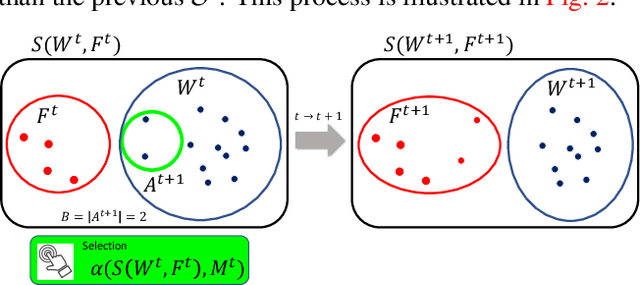
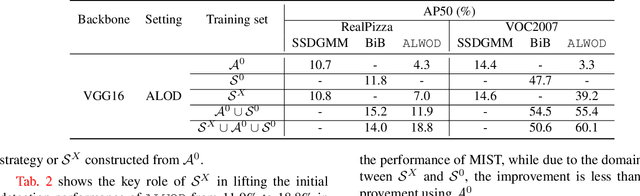
Object detection (OD), a crucial vision task, remains challenged by the lack of large training datasets with precise object localization labels. In this work, we propose ALWOD, a new framework that addresses this problem by fusing active learning (AL) with weakly and semi-supervised object detection paradigms. Because the performance of AL critically depends on the model initialization, we propose a new auxiliary image generator strategy that utilizes an extremely small labeled set, coupled with a large weakly tagged set of images, as a warm-start for AL. We then propose a new AL acquisition function, another critical factor in AL success, that leverages the student-teacher OD pair disagreement and uncertainty to effectively propose the most informative images to annotate. Finally, to complete the AL loop, we introduce a new labeling task delegated to human annotators, based on selection and correction of model-proposed detections, which is both rapid and effective in labeling the informative images. We demonstrate, across several challenging benchmarks, that ALWOD significantly narrows the gap between the ODs trained on few partially labeled but strategically selected image instances and those that rely on the fully-labeled data. Our code is publicly available on https://github.com/seqam-lab/ALWOD.
Interpretability-Aware Vision Transformer
Sep 14, 2023Vision Transformers (ViTs) have become prominent models for solving various vision tasks. However, the interpretability of ViTs has not kept pace with their promising performance. While there has been a surge of interest in developing {\it post hoc} solutions to explain ViTs' outputs, these methods do not generalize to different downstream tasks and various transformer architectures. Furthermore, if ViTs are not properly trained with the given data and do not prioritize the region of interest, the {\it post hoc} methods would be less effective. Instead of developing another {\it post hoc} approach, we introduce a novel training procedure that inherently enhances model interpretability. Our interpretability-aware ViT (IA-ViT) draws inspiration from a fresh insight: both the class patch and image patches consistently generate predicted distributions and attention maps. IA-ViT is composed of a feature extractor, a predictor, and an interpreter, which are trained jointly with an interpretability-aware training objective. Consequently, the interpreter simulates the behavior of the predictor and provides a faithful explanation through its single-head self-attention mechanism. Our comprehensive experimental results demonstrate the effectiveness of IA-ViT in several image classification tasks, with both qualitative and quantitative evaluations of model performance and interpretability. Source code is available from: https://github.com/qiangyao1988/IA-ViT.