 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Iterative Method for Unsupervised Robust Anomaly Detection Under Data Contamination
Sep 18, 2023
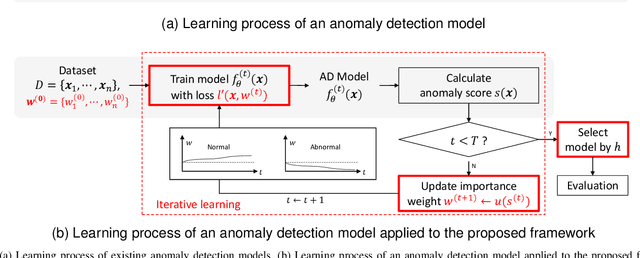

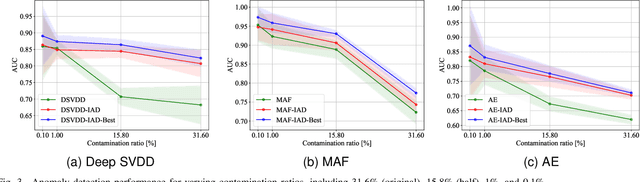
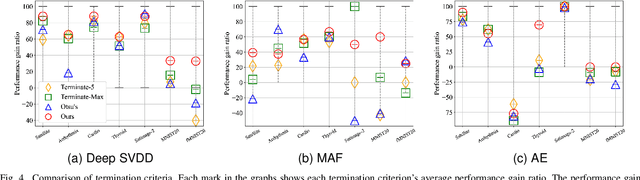
Most deep anomaly detection models are based on learning normality from datasets due to the difficulty of defining abnormality by its diverse and inconsistent nature. Therefore, it has been a common practice to learn normality under the assumption that anomalous data are absent in a training dataset, which we call normality assumption. However, in practice, the normality assumption is often violated due to the nature of real data distributions that includes anomalous tails, i.e., a contaminated dataset. Thereby, the gap between the assumption and actual training data affects detrimentally in learning of an anomaly detection model. In this work, we propose a learning framework to reduce this gap and achieve better normality representation. Our key idea is to identify sample-wise normality and utilize it as an importance weight, which is updated iteratively during the training. Our framework is designed to be model-agnostic and hyperparameter insensitive so that it applies to a wide range of existing methods without careful parameter tuning. We apply our framework to three different representative approaches of deep anomaly detection that are classified into one-class classification-, probabilistic model-, and reconstruction-based approaches. In addition, we address the importance of a termination condition for iterative methods and propose a termination criterion inspired by the anomaly detection objective. We validate that our framework improves the robustness of the anomaly detection models under different levels of contamination ratios on five anomaly detection benchmark datasets and two image datasets. On various contaminated datasets, our framework improves the performance of three representative anomaly detection methods, measured by area under the ROC curve.
PatchCT: Aligning Patch Set and Label Set with Conditional Transport for Multi-Label Image Classification
Jul 18, 2023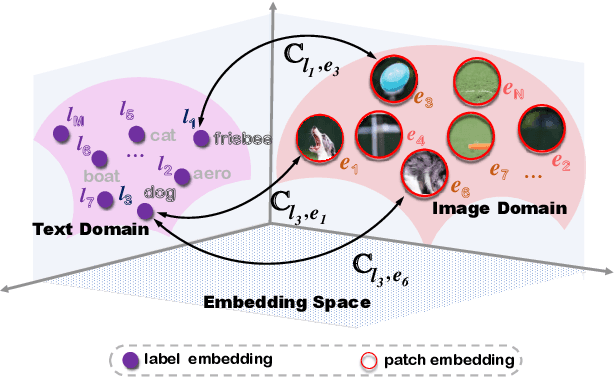
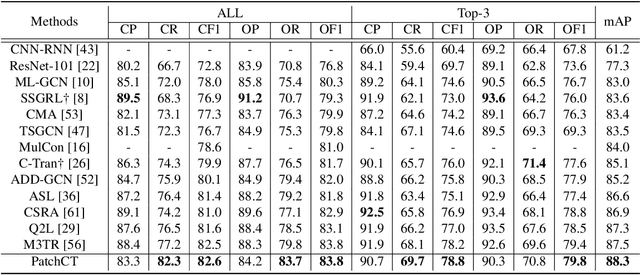
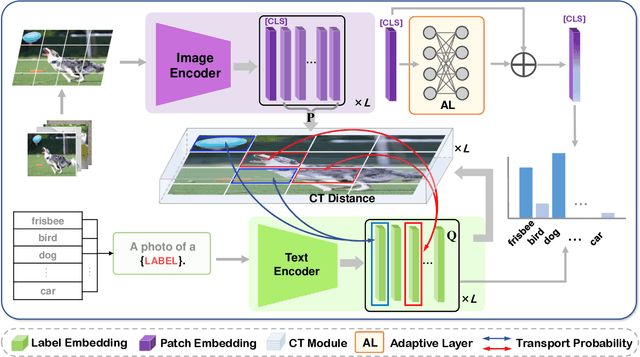
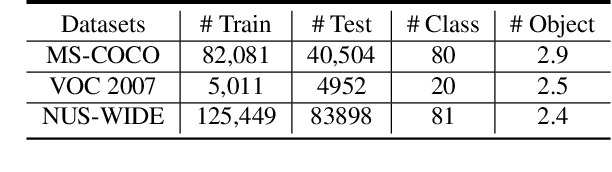
Multi-label image classification is a prediction task that aims to identify more than one label from a given image. This paper considers the semantic consistency of the latent space between the visual patch and linguistic label domains and introduces the conditional transport (CT) theory to bridge the acknowledged gap. While recent cross-modal attention-based studies have attempted to align such two representations and achieved impressive performance, they required carefully-designed alignment modules and extra complex operations in the attention computation. We find that by formulating the multi-label classification as a CT problem, we can exploit the interactions between the image and label efficiently by minimizing the bidirectional CT cost. Specifically, after feeding the images and textual labels into the modality-specific encoders, we view each image as a mixture of patch embeddings and a mixture of label embeddings, which capture the local region features and the class prototypes, respectively. CT is then employed to learn and align those two semantic sets by defining the forward and backward navigators. Importantly, the defined navigators in CT distance model the similarities between patches and labels, which provides an interpretable tool to visualize the learned prototypes. Extensive experiments on three public image benchmarks show that the proposed model consistently outperforms the previous methods. Our code is available at https://github.com/keepgoingjkg/PatchCT.
Breathing New Life into 3D Assets with Generative Repainting
Sep 15, 2023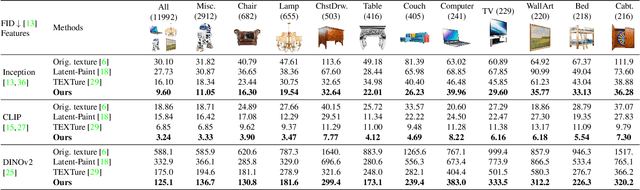

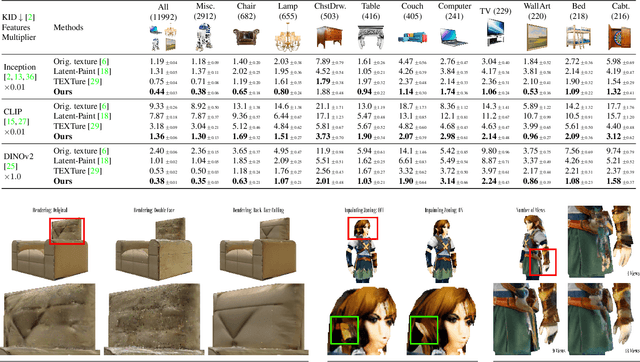
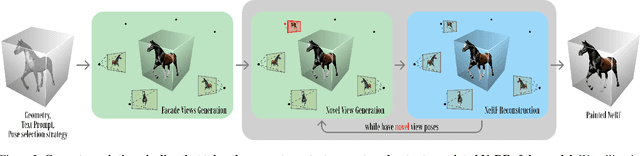
Diffusion-based text-to-image models ignited immense attention from the vision community, artists, and content creators. Broad adoption of these models is due to significant improvement in the quality of generations and efficient conditioning on various modalities, not just text. However, lifting the rich generative priors of these 2D models into 3D is challenging. Recent works have proposed various pipelines powered by the entanglement of diffusion models and neural fields. We explore the power of pretrained 2D diffusion models and standard 3D neural radiance fields as independent, standalone tools and demonstrate their ability to work together in a non-learned fashion. Such modularity has the intrinsic advantage of eased partial upgrades, which became an important property in such a fast-paced domain. Our pipeline accepts any legacy renderable geometry, such as textured or untextured meshes, orchestrates the interaction between 2D generative refinement and 3D consistency enforcement tools, and outputs a painted input geometry in several formats. We conduct a large-scale study on a wide range of objects and categories from the ShapeNetSem dataset and demonstrate the advantages of our approach, both qualitatively and quantitatively. Project page: https://www.obukhov.ai/repainting_3d_assets
Revisiting Latent Space of GAN Inversion for Real Image Editing
Jul 18, 2023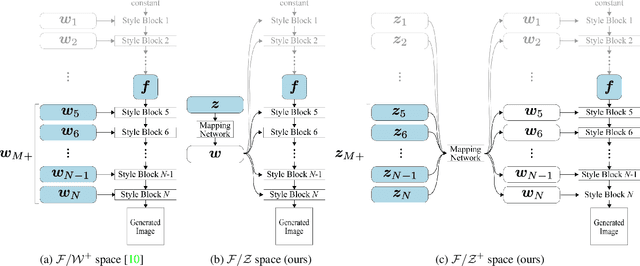


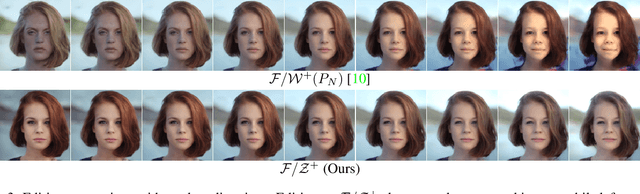
The exploration of the latent space in StyleGANs and GAN inversion exemplify impressive real-world image editing, yet the trade-off between reconstruction quality and editing quality remains an open problem. In this study, we revisit StyleGANs' hyperspherical prior $\mathcal{Z}$ and combine it with highly capable latent spaces to build combined spaces that faithfully invert real images while maintaining the quality of edited images. More specifically, we propose $\mathcal{F}/\mathcal{Z}^{+}$ space consisting of two subspaces: $\mathcal{F}$ space of an intermediate feature map of StyleGANs enabling faithful reconstruction and $\mathcal{Z}^{+}$ space of an extended StyleGAN prior supporting high editing quality. We project the real images into the proposed space to obtain the inverted codes, by which we then move along $\mathcal{Z}^{+}$, enabling semantic editing without sacrificing image quality. Comprehensive experiments show that $\mathcal{Z}^{+}$ can replace the most commonly-used $\mathcal{W}$, $\mathcal{W}^{+}$, and $\mathcal{S}$ spaces while preserving reconstruction quality, resulting in reduced distortion of edited images.
Electron Energy Regression in the CMS High-Granularity Calorimeter Prototype
Sep 12, 2023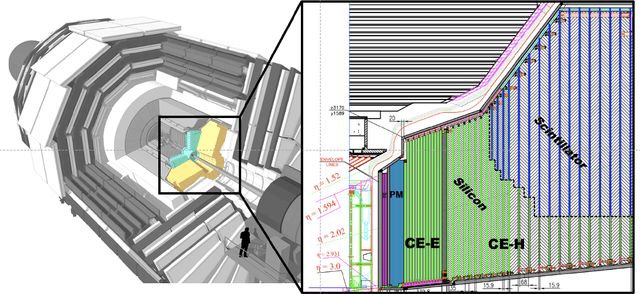
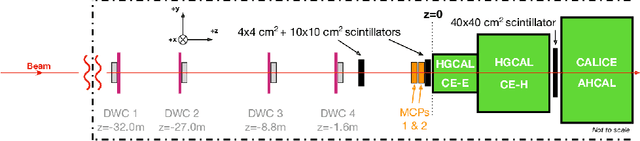
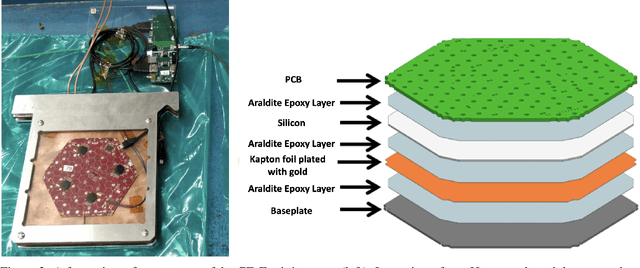
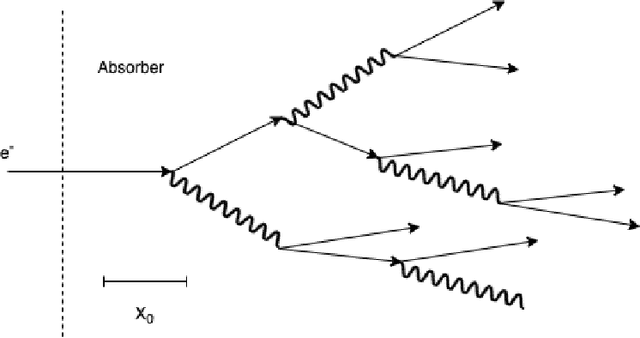
We present a new publicly available dataset that contains simulated data of a novel calorimeter to be installed at the CERN Large Hadron Collider. This detector will have more than six-million channels with each channel capable of position, ionisation and precision time measurement. Reconstructing these events in an efficient way poses an immense challenge which is being addressed with the latest machine learning techniques. As part of this development a large prototype with 12,000 channels was built and a beam of high-energy electrons incident on it. Using machine learning methods we have reconstructed the energy of incident electrons from the energies of three-dimensional hits, which is known to some precision. By releasing this data publicly we hope to encourage experts in the application of machine learning to develop efficient and accurate image reconstruction of these electrons.
Reference-based Motion Blur Removal: Learning to Utilize Sharpness in the Reference Image
Jul 06, 2023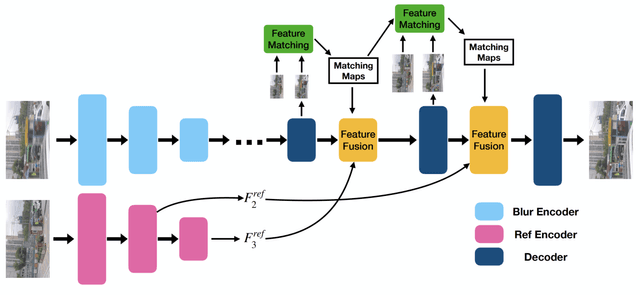
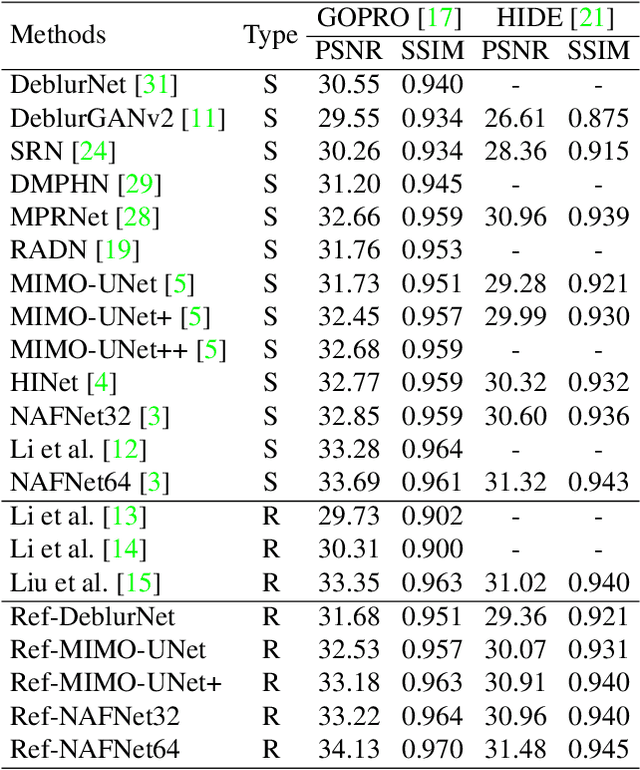
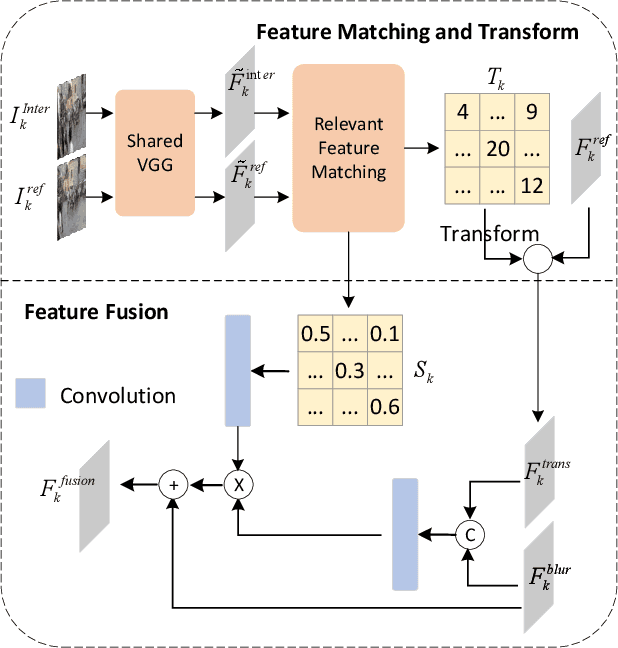
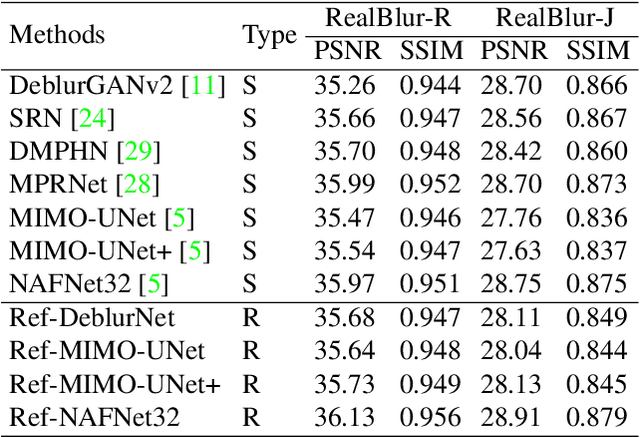
Despite the recent advancement in the study of removing motion blur in an image, it is still hard to deal with strong blurs. While there are limits in removing blurs from a single image, it has more potential to use multiple images, e.g., using an additional image as a reference to deblur a blurry image. A typical setting is deburring an image using a nearby sharp image(s) in a video sequence, as in the studies of video deblurring. This paper proposes a better method to use the information present in a reference image. The method does not need a strong assumption on the reference image. We can utilize an alternative shot of the identical scene, just like in video deblurring, or we can even employ a distinct image from another scene. Our method first matches local patches of the target and reference images and then fuses their features to estimate a sharp image. We employ a patch-based feature matching strategy to solve the difficult problem of matching the blurry image with the sharp reference. Our method can be integrated into pre-existing networks designed for single image deblurring. The experimental results show the effectiveness of the proposed method.
DRM-IR: Task-Adaptive Deep Unfolding Network for All-In-One Image Restoration
Jul 15, 2023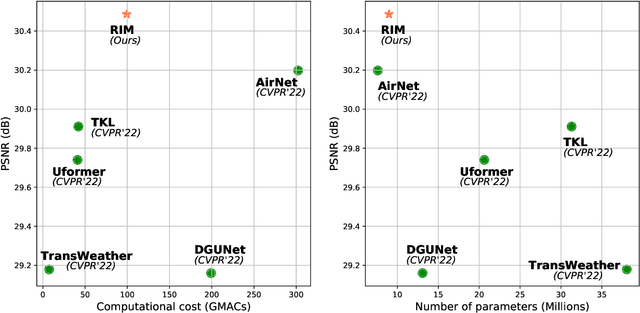
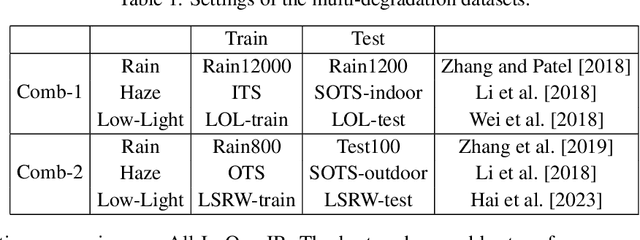
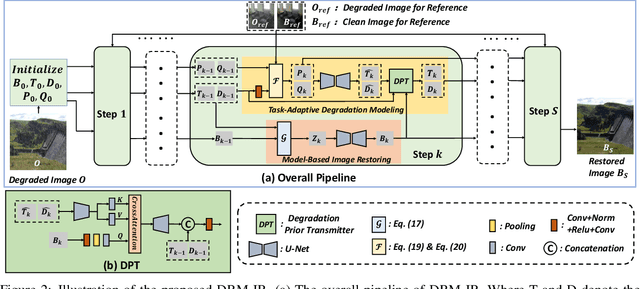
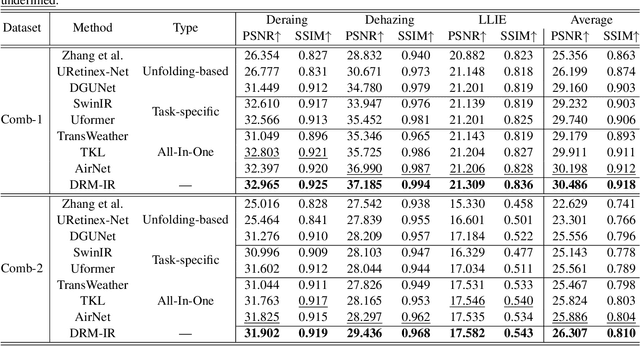
Existing All-In-One image restoration (IR) methods usually lack flexible modeling on various types of degradation, thus impeding the restoration performance. To achieve All-In-One IR with higher task dexterity, this work proposes an efficient Dynamic Reference Modeling paradigm (DRM-IR), which consists of task-adaptive degradation modeling and model-based image restoring. Specifically, these two subtasks are formalized as a pair of entangled reference-based maximum a posteriori (MAP) inferences, which are optimized synchronously in an unfolding-based manner. With the two cascaded subtasks, DRM-IR first dynamically models the task-specific degradation based on a reference image pair and further restores the image with the collected degradation statistics. Besides, to bridge the semantic gap between the reference and target degraded images, we further devise a Degradation Prior Transmitter (DPT) that restrains the instance-specific feature differences. DRM-IR explicitly provides superior flexibility for All-in-One IR while being interpretable. Extensive experiments on multiple benchmark datasets show that our DRM-IR achieves state-of-the-art in All-In-One IR.
Indoor Scene Reconstruction with Fine-Grained Details Using Hybrid Representation and Normal Prior Enhancement
Sep 14, 2023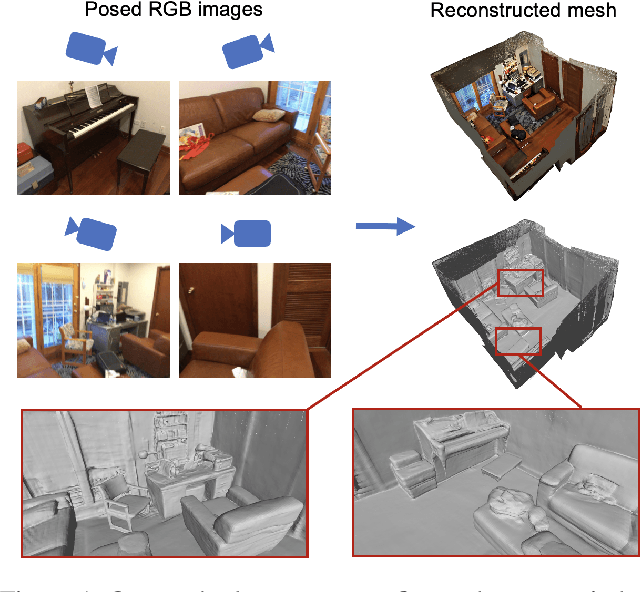
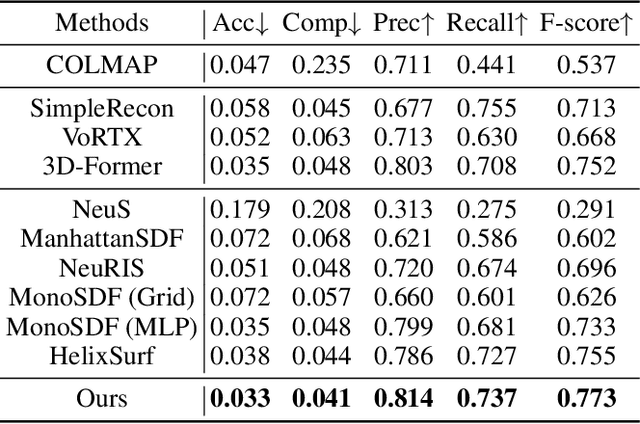
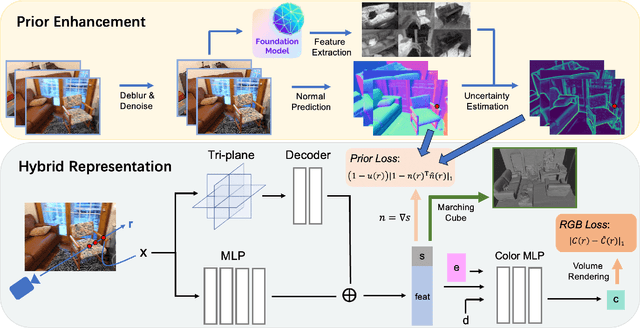
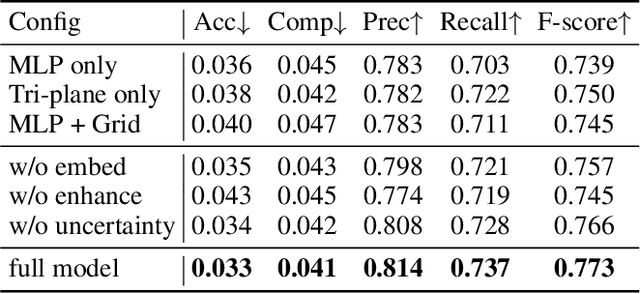
The reconstruction of indoor scenes from multi-view RGB images is challenging due to the coexistence of flat and texture-less regions alongside delicate and fine-grained regions. Recent methods leverage neural radiance fields aided by predicted surface normal priors to recover the scene geometry. These methods excel in producing complete and smooth results for floor and wall areas. However, they struggle to capture complex surfaces with high-frequency structures due to the inadequate neural representation and the inaccurately predicted normal priors. To improve the capacity of the implicit representation, we propose a hybrid architecture to represent low-frequency and high-frequency regions separately. To enhance the normal priors, we introduce a simple yet effective image sharpening and denoising technique, coupled with a network that estimates the pixel-wise uncertainty of the predicted surface normal vectors. Identifying such uncertainty can prevent our model from being misled by unreliable surface normal supervisions that hinder the accurate reconstruction of intricate geometries. Experiments on the benchmark datasets show that our method significantly outperforms existing methods in terms of reconstruction quality.
Understanding Vector-Valued Neural Networks and Their Relationship with Real and Hypercomplex-Valued Neural Networks
Sep 14, 2023Despite the many successful applications of deep learning models for multidimensional signal and image processing, most traditional neural networks process data represented by (multidimensional) arrays of real numbers. The intercorrelation between feature channels is usually expected to be learned from the training data, requiring numerous parameters and careful training. In contrast, vector-valued neural networks are conceived to process arrays of vectors and naturally consider the intercorrelation between feature channels. Consequently, they usually have fewer parameters and often undergo more robust training than traditional neural networks. This paper aims to present a broad framework for vector-valued neural networks, referred to as V-nets. In this context, hypercomplex-valued neural networks are regarded as vector-valued models with additional algebraic properties. Furthermore, this paper explains the relationship between vector-valued and traditional neural networks. Precisely, a vector-valued neural network can be obtained by placing restrictions on a real-valued model to consider the intercorrelation between feature channels. Finally, we show how V-nets, including hypercomplex-valued neural networks, can be implemented in current deep-learning libraries as real-valued networks.
Neural Field Representations of Articulated Objects for Robotic Manipulation Planning
Sep 14, 2023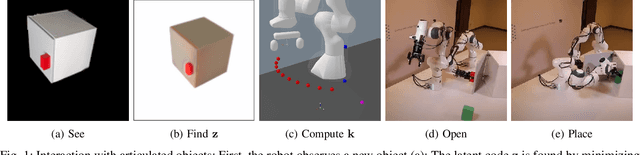
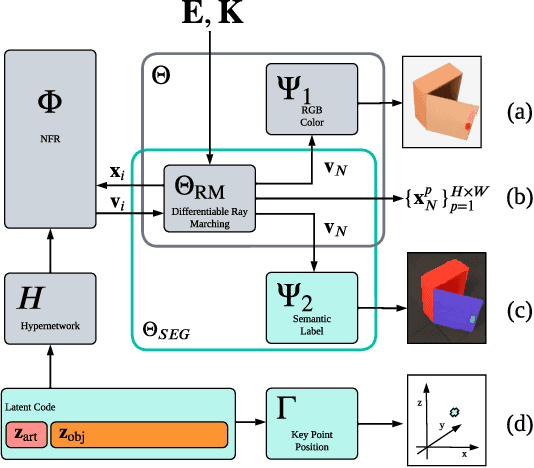

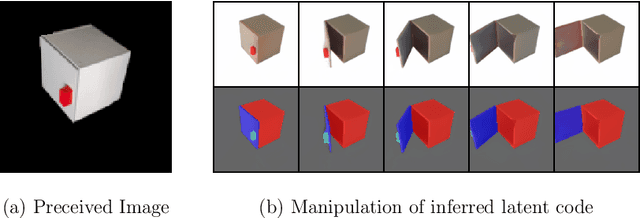
Traditional approaches for manipulation planning rely on an explicit geometric model of the environment to formulate a given task as an optimization problem. However, inferring an accurate model from raw sensor input is a hard problem in itself, in particular for articulated objects (e.g., closets, drawers). In this paper, we propose a Neural Field Representation (NFR) of articulated objects that enables manipulation planning directly from images. Specifically, after taking a few pictures of a new articulated object, we can forward simulate its possible movements, and, therefore, use this neural model directly for planning with trajectory optimization. Additionally, this representation can be used for shape reconstruction, semantic segmentation and image rendering, which provides a strong supervision signal during training and generalization. We show that our model, which was trained only on synthetic images, is able to extract a meaningful representation for unseen objects of the same class, both in simulation and with real images. Furthermore, we demonstrate that the representation enables robotic manipulation of an articulated object in the real world directly from images.