 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unified Brain MR-Ultrasound Synthesis using Multi-Modal Hierarchical Representations
Sep 19, 2023
We introduce MHVAE, a deep hierarchical variational auto-encoder (VAE) that synthesizes missing images from various modalities. Extending multi-modal VAEs with a hierarchical latent structure, we introduce a probabilistic formulation for fusing multi-modal images in a common latent representation while having the flexibility to handle incomplete image sets as input. Moreover, adversarial learning is employed to generate sharper images. Extensive experiments are performed on the challenging problem of joint intra-operative ultrasound (iUS) and Magnetic Resonance (MR) synthesis. Our model outperformed multi-modal VAEs, conditional GANs, and the current state-of-the-art unified method (ResViT) for synthesizing missing images, demonstrating the advantage of using a hierarchical latent representation and a principled probabilistic fusion operation. Our code is publicly available \url{https://github.com/ReubenDo/MHVAE}.
Contrastive Feature Masking Open-Vocabulary Vision Transformer
Sep 02, 2023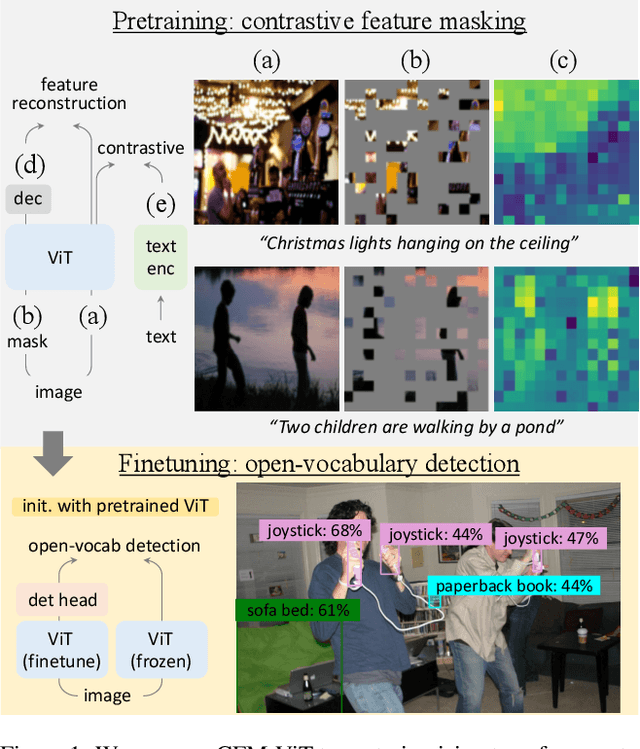
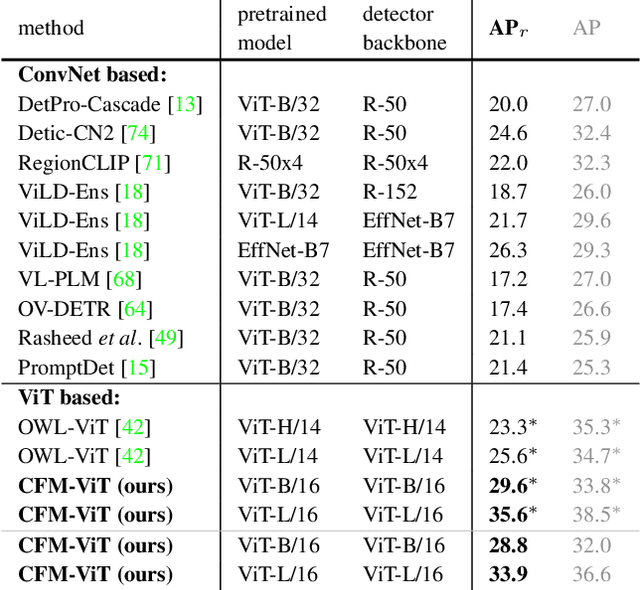
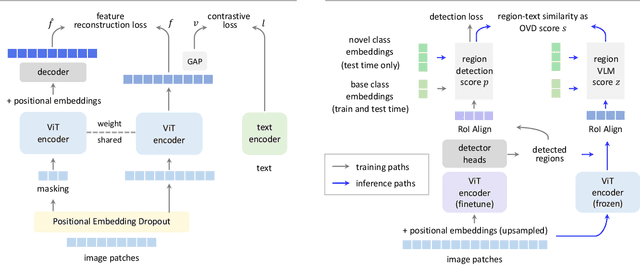
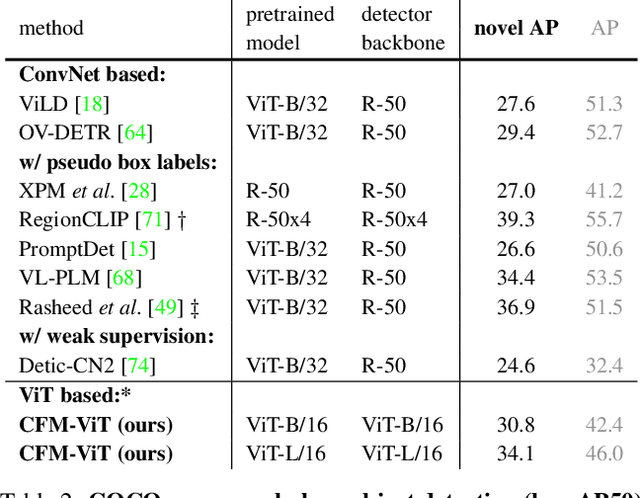
We present Contrastive Feature Masking Vision Transformer (CFM-ViT) - an image-text pretraining methodology that achieves simultaneous learning of image- and region-level representation for open-vocabulary object detection (OVD). Our approach combines the masked autoencoder (MAE) objective into the contrastive learning objective to improve the representation for localization tasks. Unlike standard MAE, we perform reconstruction in the joint image-text embedding space, rather than the pixel space as is customary with the classical MAE method, which causes the model to better learn region-level semantics. Moreover, we introduce Positional Embedding Dropout (PED) to address scale variation between image-text pretraining and detection finetuning by randomly dropping out the positional embeddings during pretraining. PED improves detection performance and enables the use of a frozen ViT backbone as a region classifier, preventing the forgetting of open-vocabulary knowledge during detection finetuning. On LVIS open-vocabulary detection benchmark, CFM-ViT achieves a state-of-the-art 33.9 AP$r$, surpassing the best approach by 7.6 points and achieves better zero-shot detection transfer. Finally, CFM-ViT acquires strong image-level representation, outperforming the state of the art on 8 out of 12 metrics on zero-shot image-text retrieval benchmarks.
Differentiable JPEG: The Devil is in the Details
Sep 13, 2023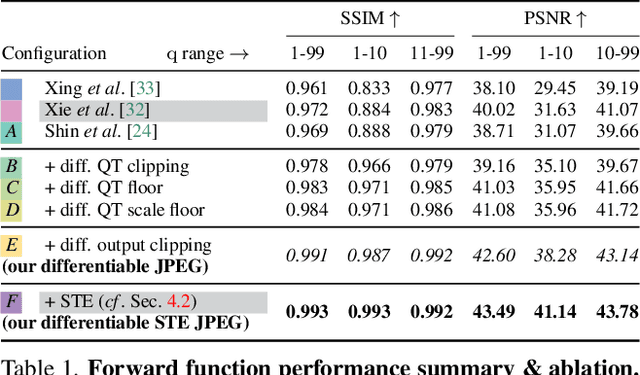
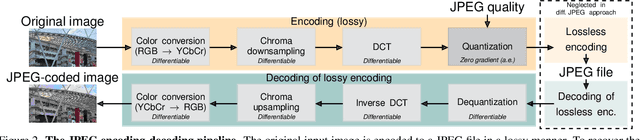
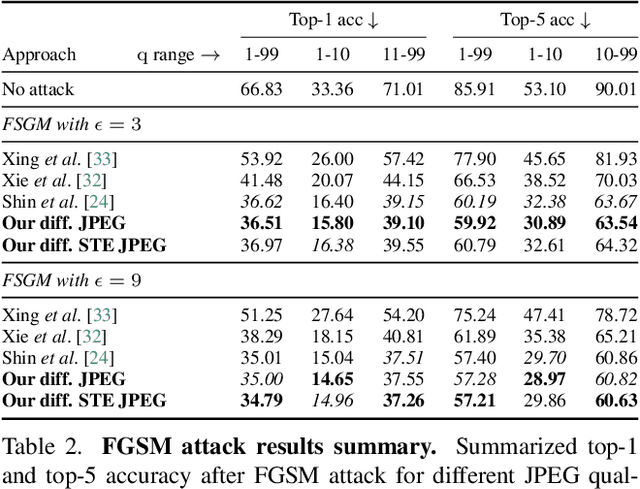

JPEG remains one of the most widespread lossy image coding methods. However, the non-differentiable nature of JPEG restricts the application in deep learning pipelines. Several differentiable approximations of JPEG have recently been proposed to address this issue. This paper conducts a comprehensive review of existing diff. JPEG approaches and identifies critical details that have been missed by previous methods. To this end, we propose a novel diff. JPEG approach, overcoming previous limitations. Our approach is differentiable w.r.t. the input image, the JPEG quality, the quantization tables, and the color conversion parameters. We evaluate the forward and backward performance of our diff. JPEG approach against existing methods. Additionally, extensive ablations are performed to evaluate crucial design choices. Our proposed diff. JPEG resembles the (non-diff.) reference implementation best, significantly surpassing the recent-best diff. approach by $3.47$dB (PSNR) on average. For strong compression rates, we can even improve PSNR by $9.51$dB. Strong adversarial attack results are yielded by our diff. JPEG, demonstrating the effective gradient approximation. Our code is available at https://github.com/necla-ml/Diff-JPEG.
Global k-Space Interpolation for Dynamic MRI Reconstruction using Masked Image Modeling
Jul 24, 2023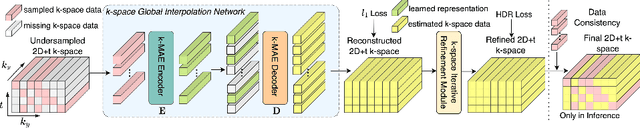
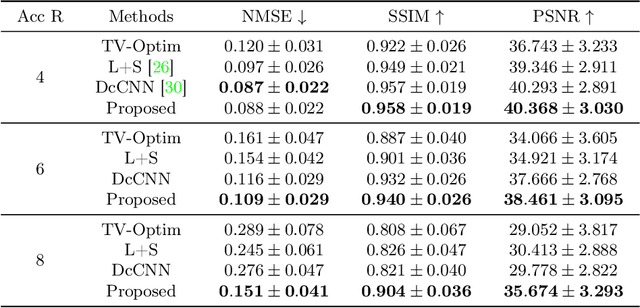
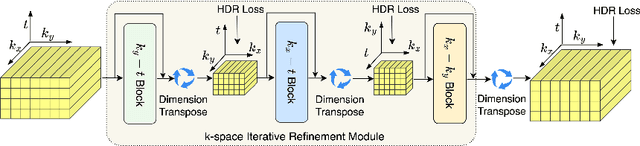
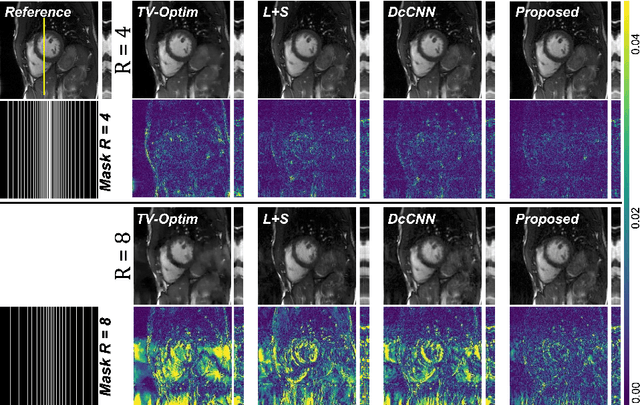
In dynamic Magnetic Resonance Imaging (MRI), k-space is typically undersampled due to limited scan time, resulting in aliasing artifacts in the image domain. Hence, dynamic MR reconstruction requires not only modeling spatial frequency components in the x and y directions of k-space but also considering temporal redundancy. Most previous works rely on image-domain regularizers (priors) to conduct MR reconstruction. In contrast, we focus on interpolating the undersampled k-space before obtaining images with Fourier transform. In this work, we connect masked image modeling with k-space interpolation and propose a novel Transformer-based k-space Global Interpolation Network, termed k-GIN. Our k-GIN learns global dependencies among low- and high-frequency components of 2D+t k-space and uses it to interpolate unsampled data. Further, we propose a novel k-space Iterative Refinement Module (k-IRM) to enhance the high-frequency components learning. We evaluate our approach on 92 in-house 2D+t cardiac MR subjects and compare it to MR reconstruction methods with image-domain regularizers. Experiments show that our proposed k-space interpolation method quantitatively and qualitatively outperforms baseline methods. Importantly, the proposed approach achieves substantially higher robustness and generalizability in cases of highly-undersampled MR data.
Enhancing Representation in Radiography-Reports Foundation Model: A Granular Alignment Algorithm Using Masked Contrastive Learning
Sep 12, 2023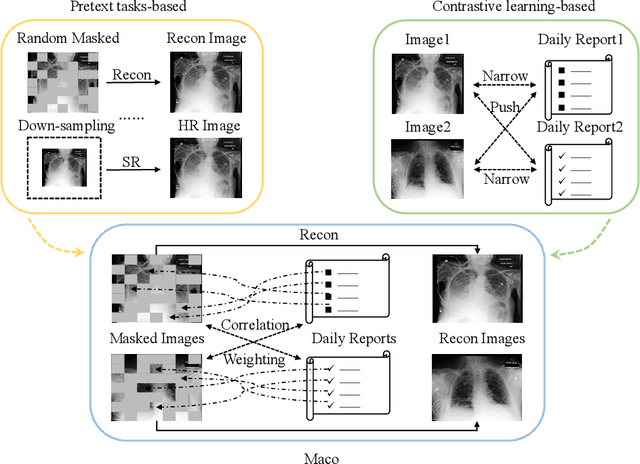
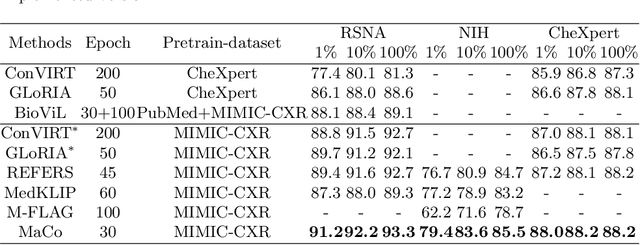

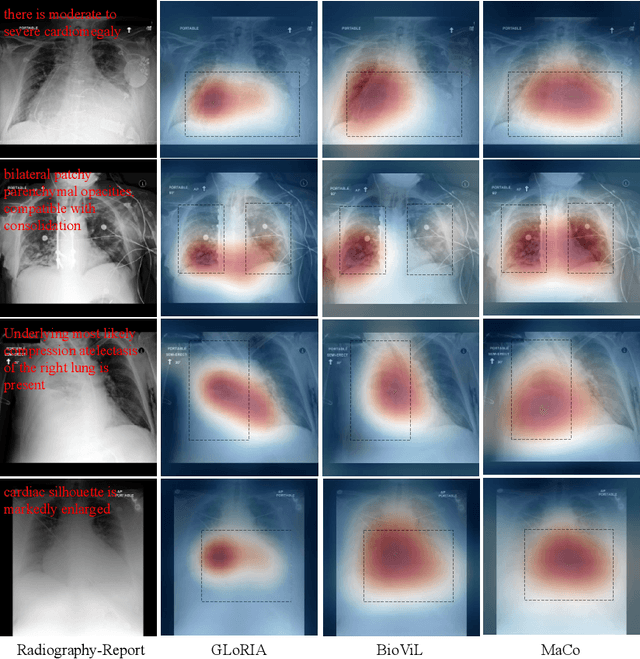
Recently, multi-modal vision-language foundation models have gained significant attention in the medical field. While these models offer great opportunities, they still face a number of challenges, such as the requirement for fine-grained knowledge understanding in computer-aided diagnosis and capability of utilizing very limited or no task-specific labeled data in real-world clinical applications. In this study, we present MaCo, a novel multi-modal medical foundation model that explores masked contrastive learning to achieve granular alignment and zero-shot learning for a variety of medical imaging tasks. MaCo incorporates a correlation weighting mechanism to adjust the correlation between masked image patches and their corresponding reports, thereby enhancing the representation learning capabilities. We evaluate MaCo on six well-known open-source X-ray datasets, and the experimental results show it outperforms seven state-of-the-art approaches for classification, segmentation, and zero-shot phase grounding, demonstrating its great potential to promote a wide range of medical image analysis tasks.
Improving the matching of deformable objects by learning to detect keypoints
Sep 12, 2023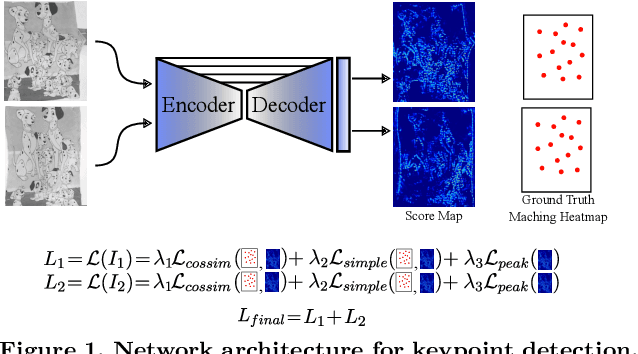
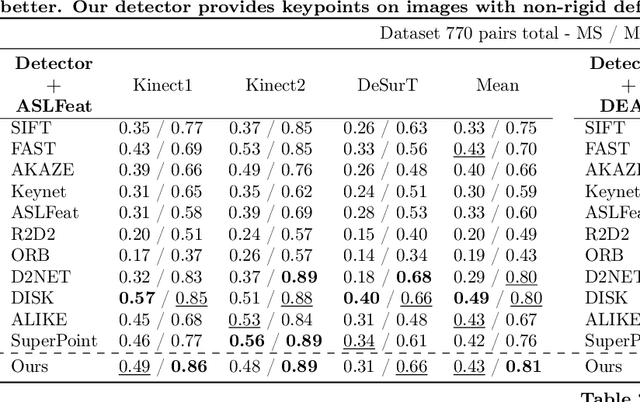
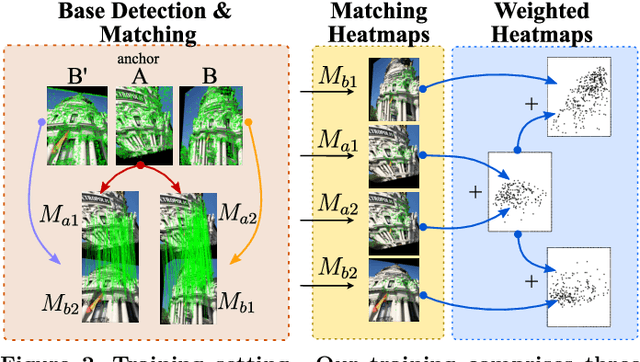

We propose a novel learned keypoint detection method to increase the number of correct matches for the task of non-rigid image correspondence. By leveraging true correspondences acquired by matching annotated image pairs with a specified descriptor extractor, we train an end-to-end convolutional neural network (CNN) to find keypoint locations that are more appropriate to the considered descriptor. For that, we apply geometric and photometric warpings to images to generate a supervisory signal, allowing the optimization of the detector. Experiments demonstrate that our method enhances the Mean Matching Accuracy of numerous descriptors when used in conjunction with our detection method, while outperforming the state-of-the-art keypoint detectors on real images of non-rigid objects by 20 p.p. We also apply our method on the complex real-world task of object retrieval where our detector performs on par with the finest keypoint detectors currently available for this task. The source code and trained models are publicly available at https://github.com/verlab/LearningToDetect_PRL_2023
* This is the accepted version of the paper to appear at Pattern Recognition Letters (PRL). The final journal version will be available at https://doi.org/10.1016/j.patrec.2023.08.012
NeRRF: 3D Reconstruction and View Synthesis for Transparent and Specular Objects with Neural Refractive-Reflective Fields
Sep 22, 2023Neural radiance fields (NeRF) have revolutionized the field of image-based view synthesis. However, NeRF uses straight rays and fails to deal with complicated light path changes caused by refraction and reflection. This prevents NeRF from successfully synthesizing transparent or specular objects, which are ubiquitous in real-world robotics and A/VR applications. In this paper, we introduce the refractive-reflective field. Taking the object silhouette as input, we first utilize marching tetrahedra with a progressive encoding to reconstruct the geometry of non-Lambertian objects and then model refraction and reflection effects of the object in a unified framework using Fresnel terms. Meanwhile, to achieve efficient and effective anti-aliasing, we propose a virtual cone supersampling technique. We benchmark our method on different shapes, backgrounds and Fresnel terms on both real-world and synthetic datasets. We also qualitatively and quantitatively benchmark the rendering results of various editing applications, including material editing, object replacement/insertion, and environment illumination estimation. Codes and data are publicly available at https://github.com/dawning77/NeRRF.
Angle Range and Identity Similarity Enhanced Gaze and Head Redirection based on Synthetic data
Sep 11, 2023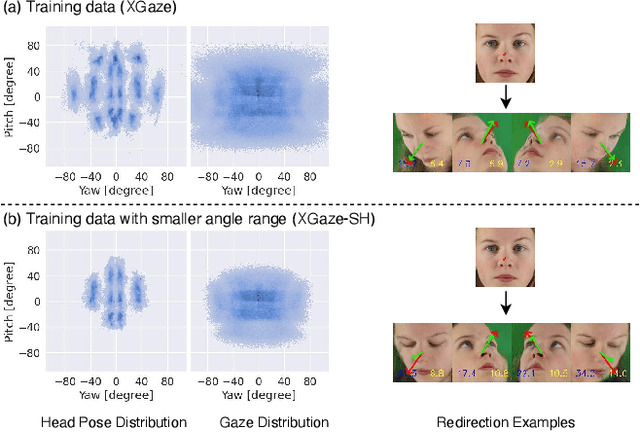

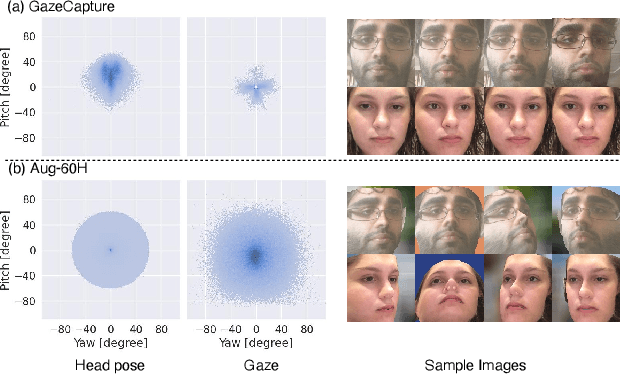
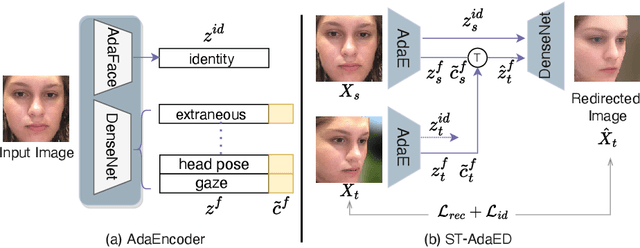
In this paper, we propose a method for improving the angular accuracy and photo-reality of gaze and head redirection in full-face images. The problem with current models is that they cannot handle redirection at large angles, and this limitation mainly comes from the lack of training data. To resolve this problem, we create data augmentation by monocular 3D face reconstruction to extend the head pose and gaze range of the real data, which allows the model to handle a wider redirection range. In addition to the main focus on data augmentation, we also propose a framework with better image quality and identity preservation of unseen subjects even training with synthetic data. Experiments show that our method significantly improves redirection performance in terms of redirection angular accuracy while maintaining high image quality, especially when redirecting to large angles.
Learning multi-domain feature relation for visible and Long-wave Infrared image patch matching
Aug 09, 2023Recently, learning-based algorithms have achieved promising performance on cross-spectral image patch matching, which, however, is still far from satisfactory for practical application. On the one hand, a lack of large-scale dataset with diverse scenes haunts its further improvement for learning-based algorithms, whose performances and generalization rely heavily on the dataset size and diversity. On the other hand, more emphasis has been put on feature relation in the spatial domain whereas the scale dependency between features has often been ignored, leading to performance degeneration especially when encountering significant appearance variations for cross-spectral patches. To address these issues, we publish, to be best of our knowledge, the largest visible and Long-wave Infrared (LWIR) image patch matching dataset, termed VL-CMIM, which contains 1300 pairs of strictly aligned visible and LWIR images and over 2 million patch pairs covering diverse scenes such as asteroid, field, country, build, street and water.In addition, a multi-domain feature relation learning network (MD-FRN) is proposed. Input by the features extracted from a four-branch network, both feature relations in spatial and scale domains are learned via a spatial correlation module (SCM) and multi-scale adaptive aggregation module (MSAG), respectively. To further aggregate the multi-domain relations, a deep domain interactive mechanism (DIM) is applied, where the learnt spatial-relation and scale-relation features are exchanged and further input into MSCRM and SCM. This mechanism allows our model to learn interactive cross-domain feature relations, leading to improved robustness to significant appearance changes due to different modality.
Causal-Story: Local Causal Attention Utilizing Parameter-Efficient Tuning For Visual Story Synthesis
Sep 21, 2023The excellent text-to-image synthesis capability of diffusion models has driven progress in synthesizing coherent visual stories. The current state-of-the-art method combines the features of historical captions, historical frames, and the current captions as conditions for generating the current frame. However, this method treats each historical frame and caption as the same contribution. It connects them in order with equal weights, ignoring that not all historical conditions are associated with the generation of the current frame. To address this issue, we propose Causal-Story. This model incorporates a local causal attention mechanism that considers the causal relationship between previous captions, frames, and current captions. By assigning weights based on this relationship, Causal-Story generates the current frame, thereby improving the global consistency of story generation. We evaluated our model on the PororoSV and FlintstonesSV datasets and obtained state-of-the-art FID scores, and the generated frames also demonstrate better storytelling in visuals.