 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Object2Scene: Putting Objects in Context for Open-Vocabulary 3D Detection
Sep 18, 2023
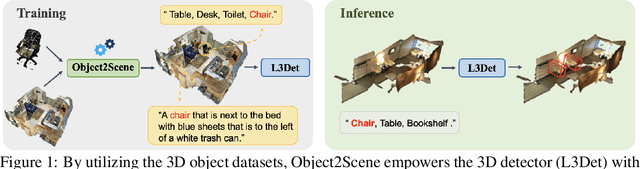

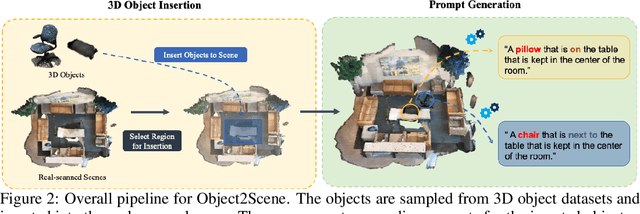
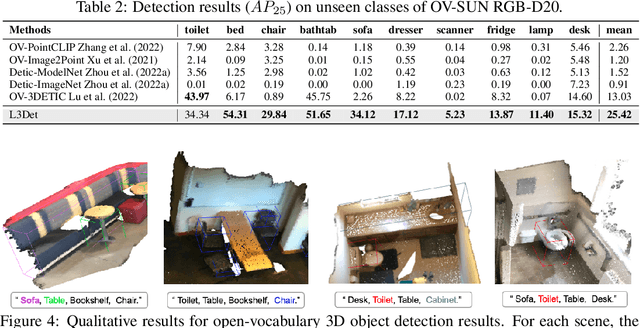
Point cloud-based open-vocabulary 3D object detection aims to detect 3D categories that do not have ground-truth annotations in the training set. It is extremely challenging because of the limited data and annotations (bounding boxes with class labels or text descriptions) of 3D scenes. Previous approaches leverage large-scale richly-annotated image datasets as a bridge between 3D and category semantics but require an extra alignment process between 2D images and 3D points, limiting the open-vocabulary ability of 3D detectors. Instead of leveraging 2D images, we propose Object2Scene, the first approach that leverages large-scale large-vocabulary 3D object datasets to augment existing 3D scene datasets for open-vocabulary 3D object detection. Object2Scene inserts objects from different sources into 3D scenes to enrich the vocabulary of 3D scene datasets and generates text descriptions for the newly inserted objects. We further introduce a framework that unifies 3D detection and visual grounding, named L3Det, and propose a cross-domain category-level contrastive learning approach to mitigate the domain gap between 3D objects from different datasets. Extensive experiments on existing open-vocabulary 3D object detection benchmarks show that Object2Scene obtains superior performance over existing methods. We further verify the effectiveness of Object2Scene on a new benchmark OV-ScanNet-200, by holding out all rare categories as novel categories not seen during training.
Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages
Aug 23, 2023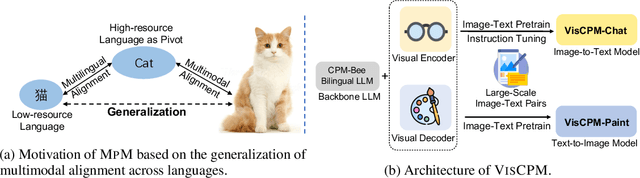
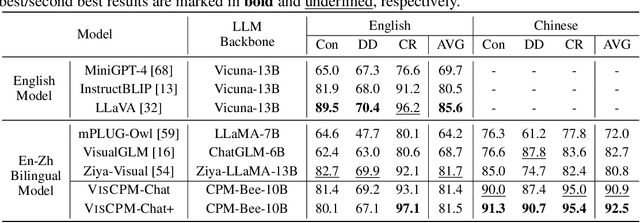
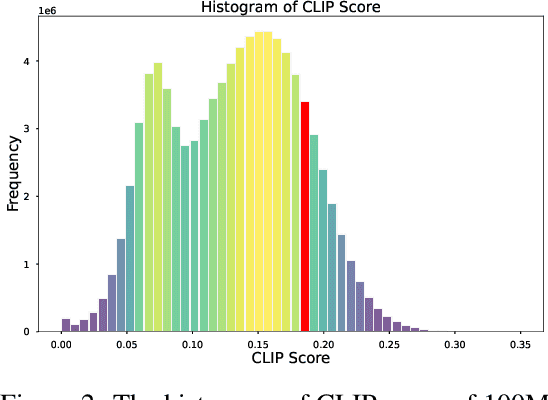
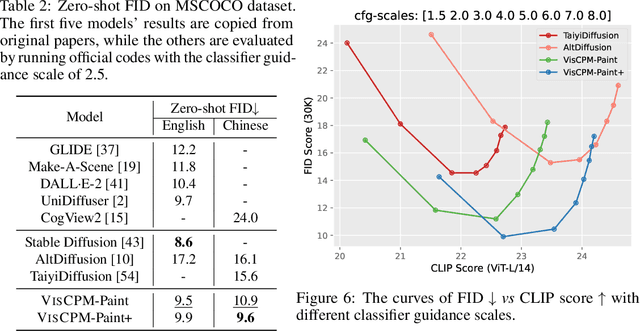
Recently there has been a significant surge in multimodal learning in terms of both image-to-text and text-to-image generation. However, the success is typically limited to English, leaving other languages largely behind. Building a competitive counterpart in other languages is highly challenging due to the low-resource nature of non-English multimodal data (i.e., lack of large-scale, high-quality image-text data). In this work, we propose MPM, an effective training paradigm for training large multimodal models in low-resource languages. MPM demonstrates that Multilingual language models can Pivot zero-shot Multimodal learning across languages. Specifically, based on a strong multilingual large language model, multimodal models pretrained on English-only image-text data can well generalize to other languages in a zero-shot manner for both image-to-text and text-to-image generation, even surpassing models trained on image-text data in native languages. Taking Chinese as a practice of MPM, we build large multimodal models VisCPM in image-to-text and text-to-image generation, which achieve state-of-the-art (open-source) performance in Chinese. To facilitate future research, we open-source codes and model weights at https://github.com/OpenBMB/VisCPM.git.
Socratis: Are large multimodal models emotionally aware?
Aug 31, 2023

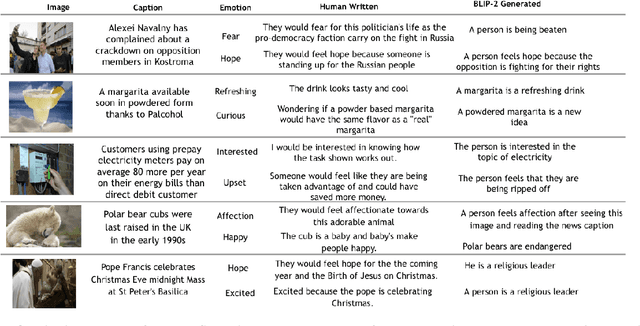
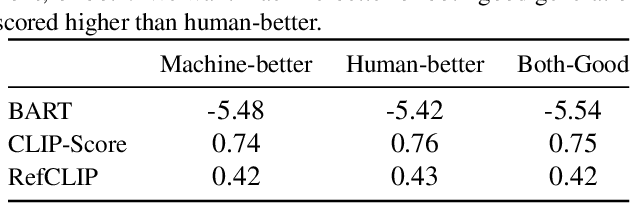
Existing emotion prediction benchmarks contain coarse emotion labels which do not consider the diversity of emotions that an image and text can elicit in humans due to various reasons. Learning diverse reactions to multimodal content is important as intelligent machines take a central role in generating and delivering content to society. To address this gap, we propose Socratis, a \underline{soc}ietal \underline{r}e\underline{a}c\underline{ti}on\underline{s} benchmark, where each image-caption (IC) pair is annotated with multiple emotions and the reasons for feeling them. Socratis contains 18K free-form reactions for 980 emotions on 2075 image-caption pairs from 5 widely-read news and image-caption (IC) datasets. We benchmark the capability of state-of-the-art multimodal large language models to generate the reasons for feeling an emotion given an IC pair. Based on a preliminary human study, we observe that humans prefer human-written reasons over 2 times more often than machine-generated ones. This shows our task is harder than standard generation tasks because it starkly contrasts recent findings where humans cannot tell apart machine vs human-written news articles, for instance. We further see that current captioning metrics based on large vision-language models also fail to correlate with human preferences. We hope that these findings and our benchmark will inspire further research on training emotionally aware models.
M3D-NCA: Robust 3D Segmentation with Built-in Quality Control
Sep 06, 2023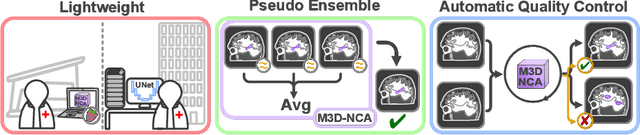
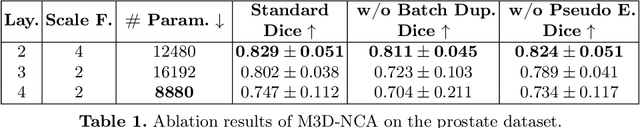
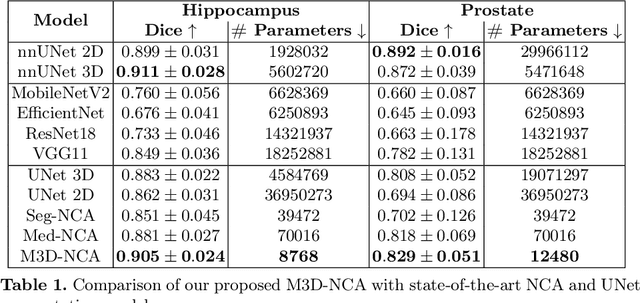
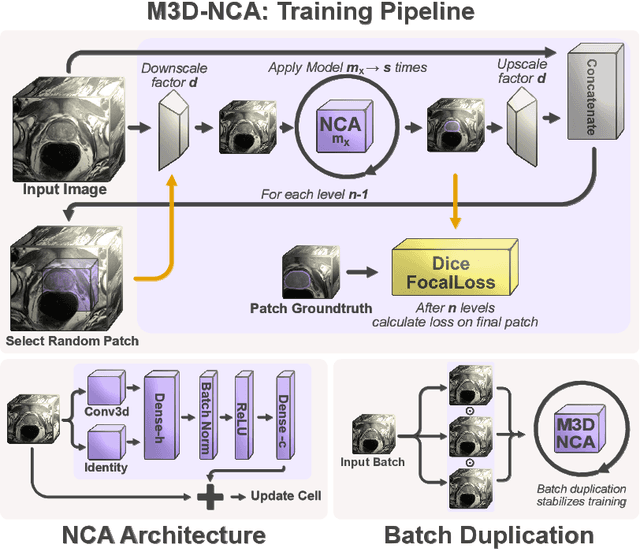
Medical image segmentation relies heavily on large-scale deep learning models, such as UNet-based architectures. However, the real-world utility of such models is limited by their high computational requirements, which makes them impractical for resource-constrained environments such as primary care facilities and conflict zones. Furthermore, shifts in the imaging domain can render these models ineffective and even compromise patient safety if such errors go undetected. To address these challenges, we propose M3D-NCA, a novel methodology that leverages Neural Cellular Automata (NCA) segmentation for 3D medical images using n-level patchification. Moreover, we exploit the variance in M3D-NCA to develop a novel quality metric which can automatically detect errors in the segmentation process of NCAs. M3D-NCA outperforms the two magnitudes larger UNet models in hippocampus and prostate segmentation by 2% Dice and can be run on a Raspberry Pi 4 Model B (2GB RAM). This highlights the potential of M3D-NCA as an effective and efficient alternative for medical image segmentation in resource-constrained environments.
Towards Addressing the Misalignment of Object Proposal Evaluation for Vision-Language Tasks via Semantic Grounding
Sep 01, 2023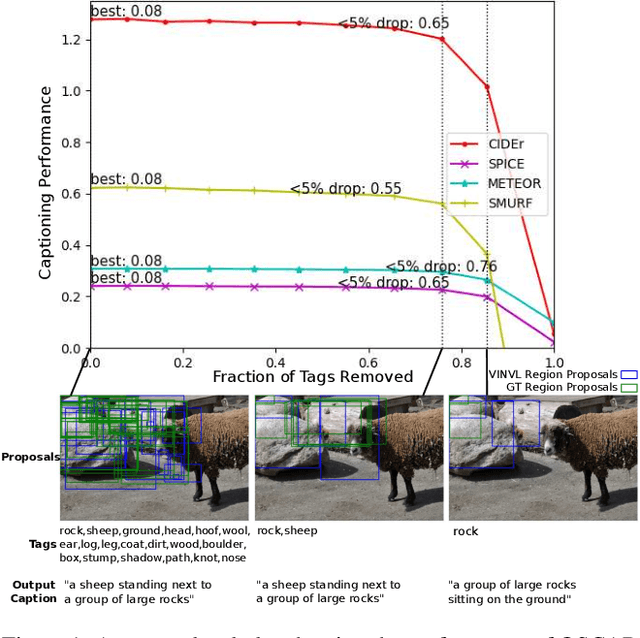
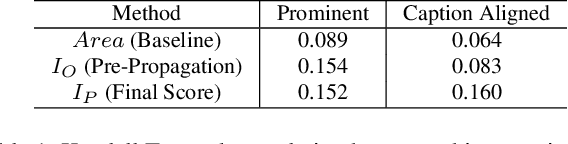
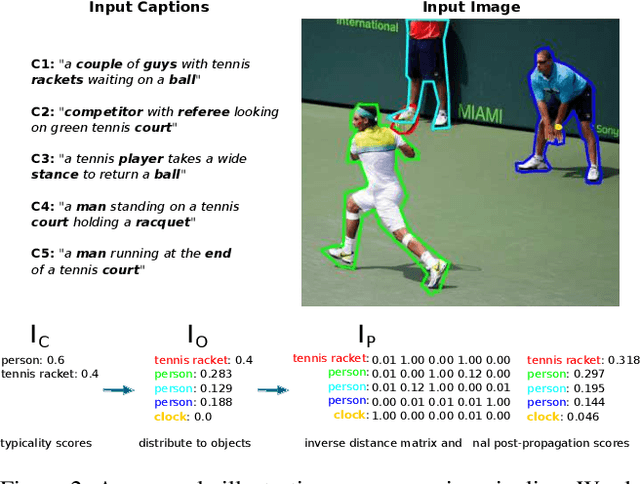
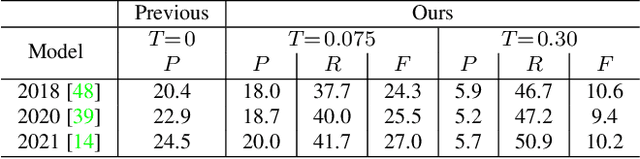
Object proposal generation serves as a standard pre-processing step in Vision-Language (VL) tasks (image captioning, visual question answering, etc.). The performance of object proposals generated for VL tasks is currently evaluated across all available annotations, a protocol that we show is misaligned - higher scores do not necessarily correspond to improved performance on downstream VL tasks. Our work serves as a study of this phenomenon and explores the effectiveness of semantic grounding to mitigate its effects. To this end, we propose evaluating object proposals against only a subset of available annotations, selected by thresholding an annotation importance score. Importance of object annotations to VL tasks is quantified by extracting relevant semantic information from text describing the image. We show that our method is consistent and demonstrates greatly improved alignment with annotations selected by image captioning metrics and human annotation when compared against existing techniques. Lastly, we compare current detectors used in the Scene Graph Generation (SGG) benchmark as a use case, which serves as an example of when traditional object proposal evaluation techniques are misaligned.
AnomalyGPT: Detecting Industrial Anomalies using Large Vision-Language Models
Sep 04, 2023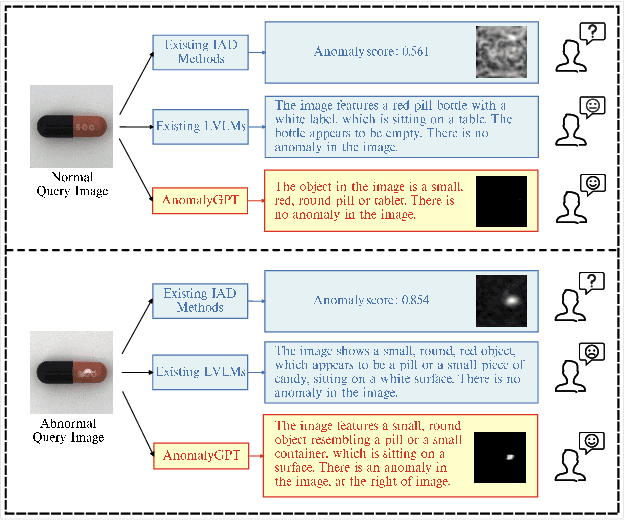

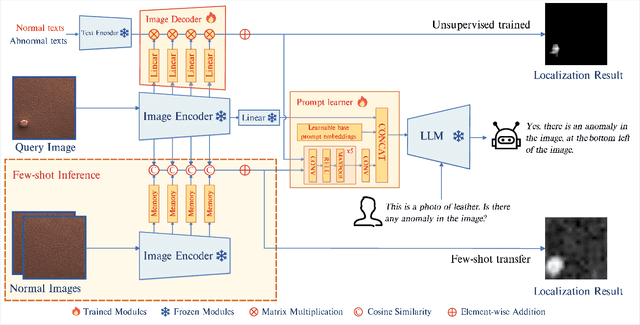
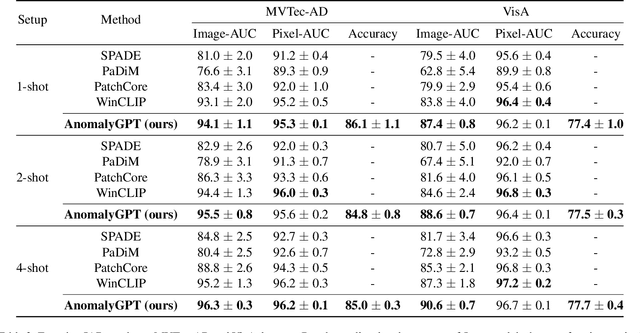
Large Vision-Language Models (LVLMs) such as MiniGPT-4 and LLaVA have demonstrated the capability of understanding images and achieved remarkable performance in various visual tasks. Despite their strong abilities in recognizing common objects due to extensive training datasets, they lack specific domain knowledge and have a weaker understanding of localized details within objects, which hinders their effectiveness in the Industrial Anomaly Detection (IAD) task. On the other hand, most existing IAD methods only provide anomaly scores and necessitate the manual setting of thresholds to distinguish between normal and abnormal samples, which restricts their practical implementation. In this paper, we explore the utilization of LVLM to address the IAD problem and propose AnomalyGPT, a novel IAD approach based on LVLM. We generate training data by simulating anomalous images and producing corresponding textual descriptions for each image. We also employ an image decoder to provide fine-grained semantic and design a prompt learner to fine-tune the LVLM using prompt embeddings. Our AnomalyGPT eliminates the need for manual threshold adjustments, thus directly assesses the presence and locations of anomalies. Additionally, AnomalyGPT supports multi-turn dialogues and exhibits impressive few-shot in-context learning capabilities. With only one normal shot, AnomalyGPT achieves the state-of-the-art performance with an accuracy of 86.1%, an image-level AUC of 94.1%, and a pixel-level AUC of 95.3% on the MVTec-AD dataset. Code is available at https://github.com/CASIA-IVA-Lab/AnomalyGPT.
DeViL: Decoding Vision features into Language
Sep 04, 2023Post-hoc explanation methods have often been criticised for abstracting away the decision-making process of deep neural networks. In this work, we would like to provide natural language descriptions for what different layers of a vision backbone have learned. Our DeViL method decodes vision features into language, not only highlighting the attribution locations but also generating textual descriptions of visual features at different layers of the network. We train a transformer network to translate individual image features of any vision layer into a prompt that a separate off-the-shelf language model decodes into natural language. By employing dropout both per-layer and per-spatial-location, our model can generalize training on image-text pairs to generate localized explanations. As it uses a pre-trained language model, our approach is fast to train, can be applied to any vision backbone, and produces textual descriptions at different layers of the vision network. Moreover, DeViL can create open-vocabulary attribution maps corresponding to words or phrases even outside the training scope of the vision model. We demonstrate that DeViL generates textual descriptions relevant to the image content on CC3M surpassing previous lightweight captioning models and attribution maps uncovering the learned concepts of the vision backbone. Finally, we show DeViL also outperforms the current state-of-the-art on the neuron-wise descriptions of the MILANNOTATIONS dataset. Code available at https://github.com/ExplainableML/DeViL
Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures
Sep 17, 2023
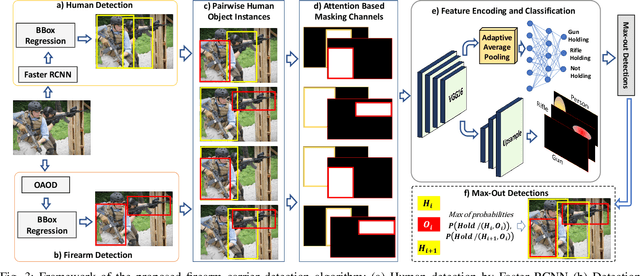
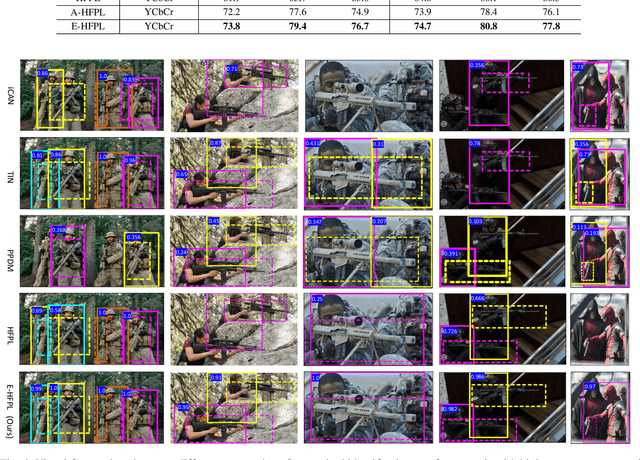

Detecting firearms and accurately localizing individuals carrying them in images or videos is of paramount importance in security, surveillance, and content customization. However, this task presents significant challenges in complex environments due to clutter and the diverse shapes of firearms. To address this problem, we propose a novel approach that leverages human-firearm interaction information, which provides valuable clues for localizing firearm carriers. Our approach incorporates an attention mechanism that effectively distinguishes humans and firearms from the background by focusing on relevant areas. Additionally, we introduce a saliency-driven locality-preserving constraint to learn essential features while preserving foreground information in the input image. By combining these components, our approach achieves exceptional results on a newly proposed dataset. To handle inputs of varying sizes, we pass paired human-firearm instances with attention masks as channels through a deep network for feature computation, utilizing an adaptive average pooling layer. We extensively evaluate our approach against existing methods in human-object interaction detection and achieve significant results (AP=77.8\%) compared to the baseline approach (AP=63.1\%). This demonstrates the effectiveness of leveraging attention mechanisms and saliency-driven locality preservation for accurate human-firearm interaction detection. Our findings contribute to advancing the fields of security and surveillance, enabling more efficient firearm localization and identification in diverse scenarios.
Active Learning for Semantic Segmentation with Multi-class Label Query
Sep 17, 2023This paper proposes a new active learning method for semantic segmentation. The core of our method lies in a new annotation query design. It samples informative local image regions (e.g., superpixels), and for each of such regions, asks an oracle for a multi-hot vector indicating all classes existing in the region. This multi-class labeling strategy is substantially more efficient than existing ones like segmentation, polygon, and even dominant class labeling in terms of annotation time per click. However, it introduces the class ambiguity issue in training since it assigns partial labels (i.e., a set of candidate classes) to individual pixels. We thus propose a new algorithm for learning semantic segmentation while disambiguating the partial labels in two stages. In the first stage, it trains a segmentation model directly with the partial labels through two new loss functions motivated by partial label learning and multiple instance learning. In the second stage, it disambiguates the partial labels by generating pixel-wise pseudo labels, which are used for supervised learning of the model. Equipped with a new acquisition function dedicated to the multi-class labeling, our method outperformed previous work on Cityscapes and PASCAL VOC 2012 while spending less annotation cost.
Shape of my heart: Cardiac models through learned signed distance functions
Sep 05, 2023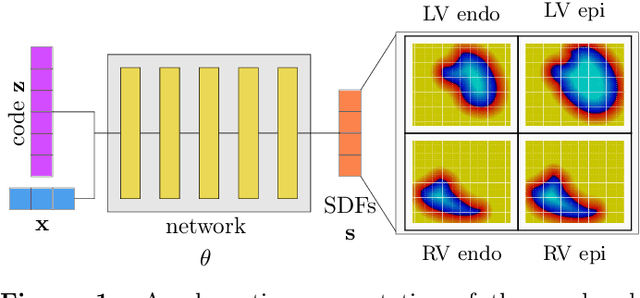
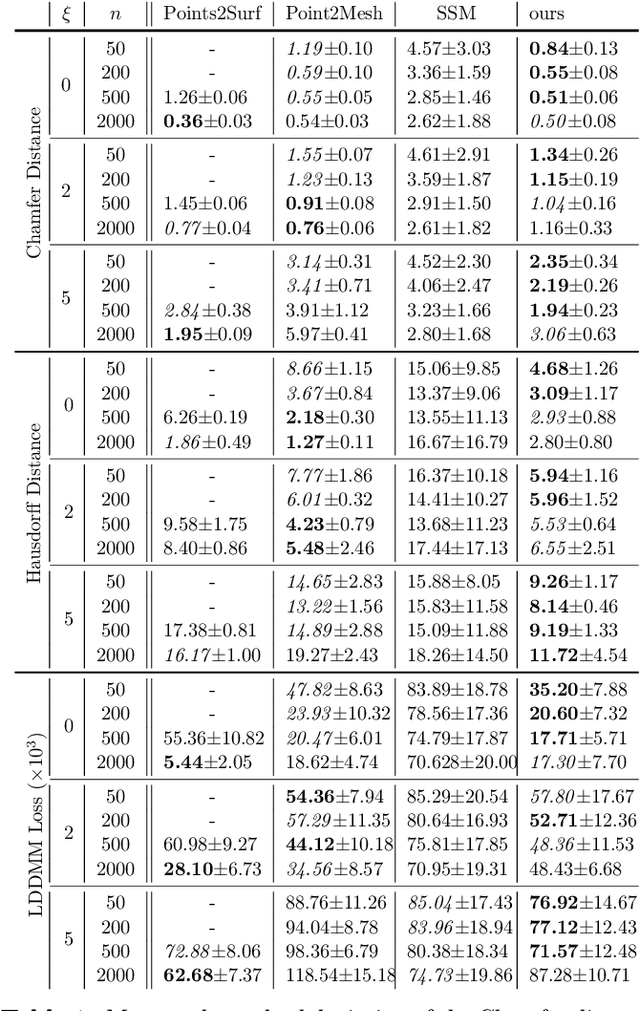
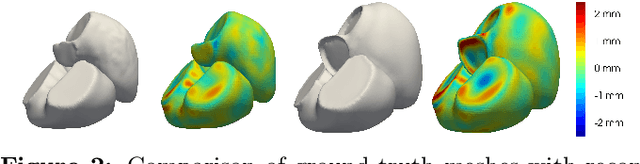
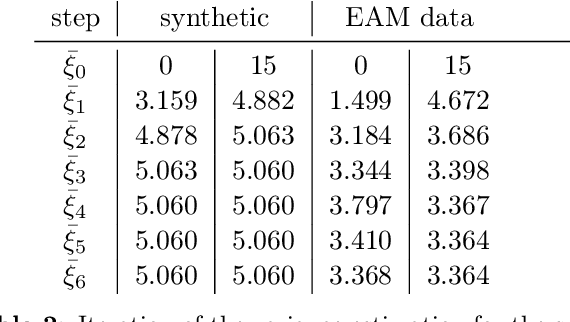
The efficient construction of an anatomical model is one of the major challenges of patient-specific in-silico models of the human heart. Current methods frequently rely on linear statistical models, allowing no advanced topological changes, or requiring medical image segmentation followed by a meshing pipeline, which strongly depends on image resolution, quality, and modality. These approaches are therefore limited in their transferability to other imaging domains. In this work, the cardiac shape is reconstructed by means of three-dimensional deep signed distance functions with Lipschitz regularity. For this purpose, the shapes of cardiac MRI reconstructions are learned from public databases to model the spatial relation of multiple chambers in Cartesian space. We demonstrate that this approach is also capable of reconstructing anatomical models from partial data, such as point clouds from a single ventricle, or modalities different from the trained MRI, such as electroanatomical mapping, and in addition, allows us to generate new anatomical shapes by randomly sampling latent vectors.