 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Leveraging the Power of Data Augmentation for Transformer-based Tracking
Sep 15, 2023
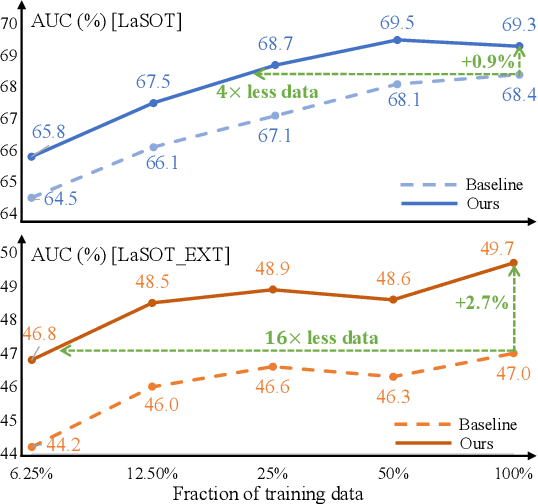



Due to long-distance correlation and powerful pretrained models, transformer-based methods have initiated a breakthrough in visual object tracking performance. Previous works focus on designing effective architectures suited for tracking, but ignore that data augmentation is equally crucial for training a well-performing model. In this paper, we first explore the impact of general data augmentations on transformer-based trackers via systematic experiments, and reveal the limited effectiveness of these common strategies. Motivated by experimental observations, we then propose two data augmentation methods customized for tracking. First, we optimize existing random cropping via a dynamic search radius mechanism and simulation for boundary samples. Second, we propose a token-level feature mixing augmentation strategy, which enables the model against challenges like background interference. Extensive experiments on two transformer-based trackers and six benchmarks demonstrate the effectiveness and data efficiency of our methods, especially under challenging settings, like one-shot tracking and small image resolutions.
HINT: Healthy Influential-Noise based Training to Defend against Data Poisoning Attacks
Sep 15, 2023While numerous defense methods have been proposed to prohibit potential poisoning attacks from untrusted data sources, most research works only defend against specific attacks, which leaves many avenues for an adversary to exploit. In this work, we propose an efficient and robust training approach to defend against data poisoning attacks based on influence functions, named Healthy Influential-Noise based Training. Using influence functions, we craft healthy noise that helps to harden the classification model against poisoning attacks without significantly affecting the generalization ability on test data. In addition, our method can perform effectively when only a subset of the training data is modified, instead of the current method of adding noise to all examples that has been used in several previous works. We conduct comprehensive evaluations over two image datasets with state-of-the-art poisoning attacks under different realistic attack scenarios. Our empirical results show that HINT can efficiently protect deep learning models against the effect of both untargeted and targeted poisoning attacks.
A Novel Truncated Norm Regularization Method for Multi-channel Color Image Denoising
Jul 16, 2023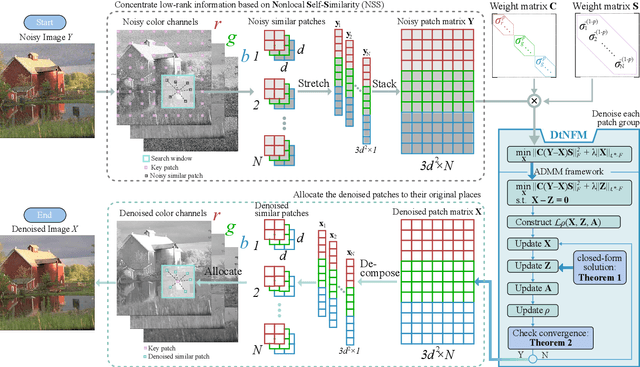
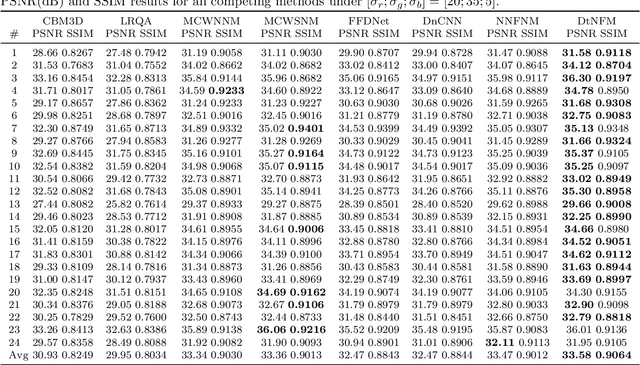
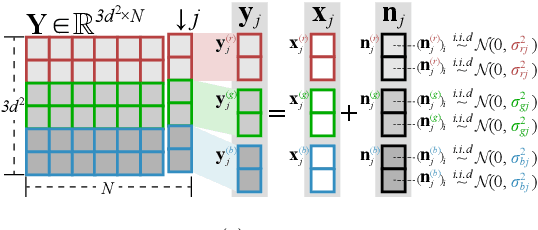
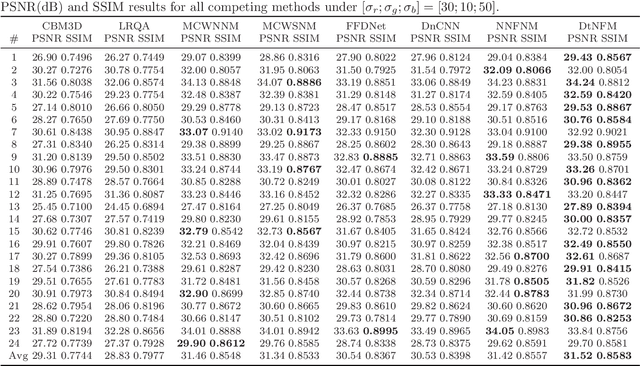
Due to the high flexibility and remarkable performance, low-rank approximation methods has been widely studied for color image denoising. However, those methods mostly ignore either the cross-channel difference or the spatial variation of noise, which limits their capacity in real world color image denoising. To overcome those drawbacks, this paper is proposed to denoise color images with a double-weighted truncated nuclear norm minus truncated Frobenius norm minimization (DtNFM) method. Through exploiting the nonlocal self-similarity of the noisy image, the similar structures are gathered and a series of similar patch matrices are constructed. For each group, the DtNFM model is conducted for estimating its denoised version. The denoised image would be obtained by concatenating all the denoised patch matrices. The proposed DtNFM model has two merits. First, it models and utilizes both the cross-channel difference and the spatial variation of noise. This provides sufficient flexibility for handling the complex distribution of noise in real world images. Second, the proposed DtNFM model provides a close approximation to the underlying clean matrix since it can treat different rank components flexibly. To solve the problem resulted from DtNFM model, an accurate and effective algorithm is proposed by exploiting the framework of the alternating direction method of multipliers (ADMM). The generated subproblems are discussed in detail. And their global optima can be easily obtained in closed-form. Rigorous mathematical derivation proves that the solution sequences generated by the algorithm converge to a single critical point. Extensive experiments on synthetic and real noise datasets demonstrate that the proposed method outperforms many state-of-the-art color image denoising methods.
Do humans and Convolutional Neural Networks attend to similar areas during scene classification: Effects of task and image type
Jul 25, 2023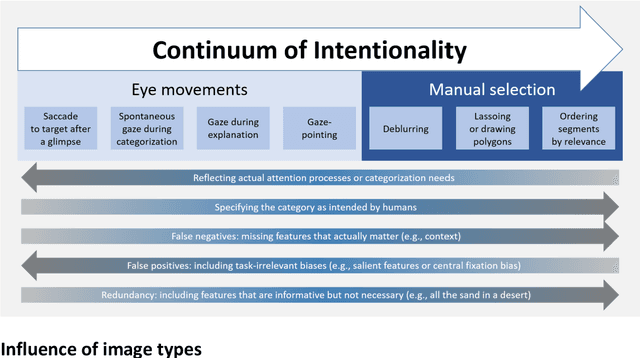
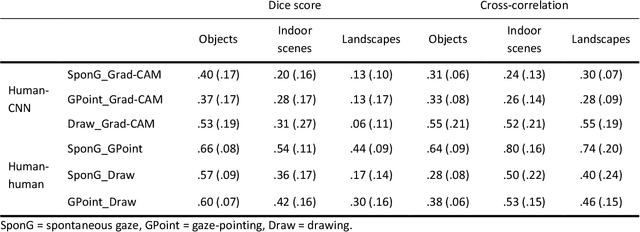

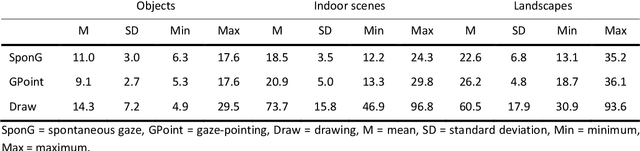
Deep Learning models like Convolutional Neural Networks (CNN) are powerful image classifiers, but what factors determine whether they attend to similar image areas as humans do? While previous studies have focused on technological factors, little is known about the role of factors that affect human attention. In the present study, we investigated how the tasks used to elicit human attention maps interact with image characteristics in modulating the similarity between humans and CNN. We varied the intentionality of human tasks, ranging from spontaneous gaze during categorization over intentional gaze-pointing up to manual area selection. Moreover, we varied the type of image to be categorized, using either singular, salient objects, indoor scenes consisting of object arrangements, or landscapes without distinct objects defining the category. The human attention maps generated in this way were compared to the CNN attention maps revealed by explainable artificial intelligence (Grad-CAM). The influence of human tasks strongly depended on image type: For objects, human manual selection produced maps that were most similar to CNN, while the specific eye movement task has little impact. For indoor scenes, spontaneous gaze produced the least similarity, while for landscapes, similarity was equally low across all human tasks. To better understand these results, we also compared the different human attention maps to each other. Our results highlight the importance of taking human factors into account when comparing the attention of humans and CNN.
ARTxAI: Explainable Artificial Intelligence Curates Deep Representation Learning for Artistic Images using Fuzzy Techniques
Aug 29, 2023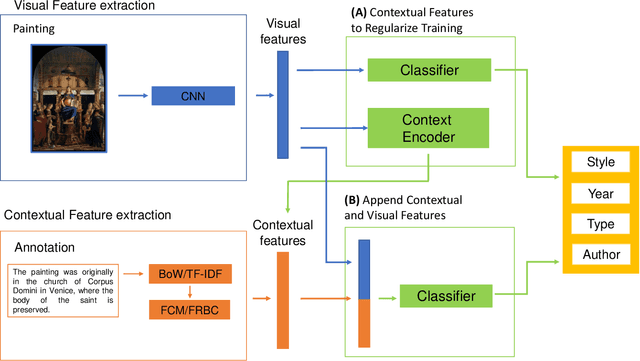
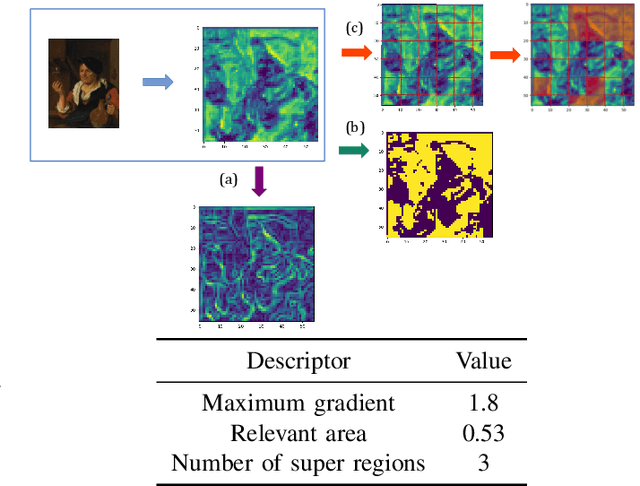
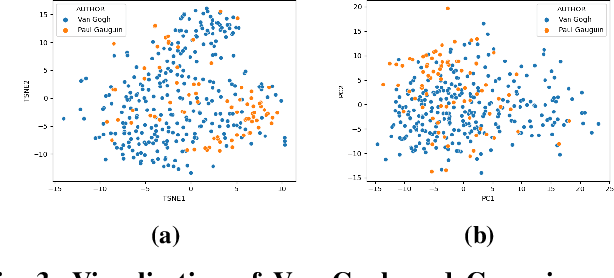

Automatic art analysis employs different image processing techniques to classify and categorize works of art. When working with artistic images, we need to take into account further considerations compared to classical image processing. This is because such artistic paintings change drastically depending on the author, the scene depicted, and their artistic style. This can result in features that perform very well in a given task but do not grasp the whole of the visual and symbolic information contained in a painting. In this paper, we show how the features obtained from different tasks in artistic image classification are suitable to solve other ones of similar nature. We present different methods to improve the generalization capabilities and performance of artistic classification systems. Furthermore, we propose an explainable artificial intelligence method to map known visual traits of an image with the features used by the deep learning model considering fuzzy rules. These rules show the patterns and variables that are relevant to solve each task and how effective is each of the patterns found. Our results show that our proposed context-aware features can achieve up to $6\%$ and $26\%$ more accurate results than other context- and non-context-aware solutions, respectively, depending on the specific task. We also show that some of the features used by these models can be more clearly correlated to visual traits in the original image than others.
Exploring Non-additive Randomness on ViT against Query-Based Black-Box Attacks
Sep 12, 2023Deep Neural Networks can be easily fooled by small and imperceptible perturbations. The query-based black-box attack (QBBA) is able to create the perturbations using model output probabilities of image queries requiring no access to the underlying models. QBBA poses realistic threats to real-world applications. Recently, various types of robustness have been explored to defend against QBBA. In this work, we first taxonomize the stochastic defense strategies against QBBA. Following our taxonomy, we propose to explore non-additive randomness in models to defend against QBBA. Specifically, we focus on underexplored Vision Transformers based on their flexible architectures. Extensive experiments show that the proposed defense approach achieves effective defense, without much sacrifice in performance.
Fine-grained Recognition with Learnable Semantic Data Augmentation
Sep 01, 2023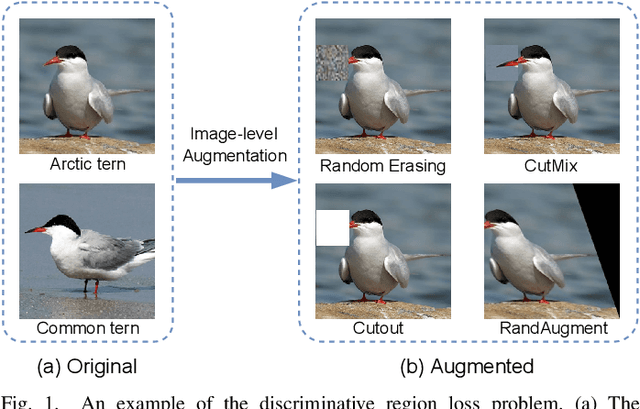
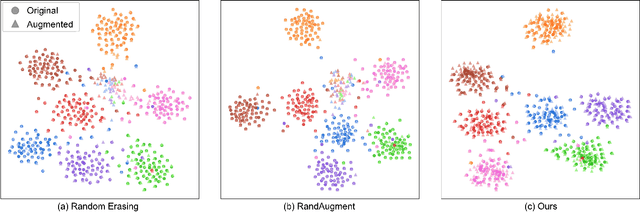
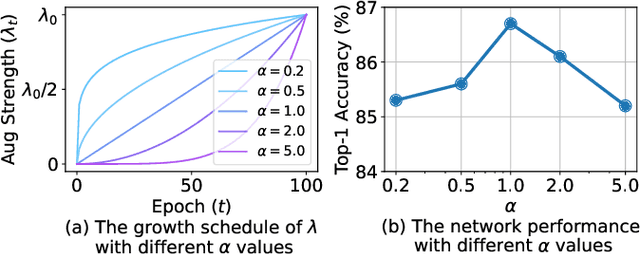
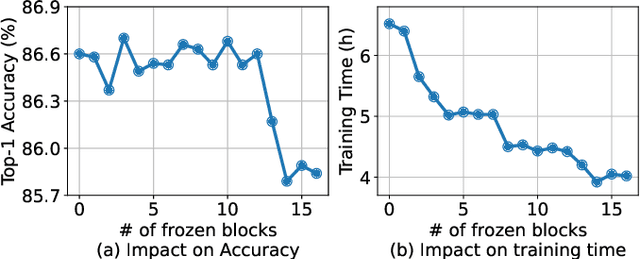
Fine-grained image recognition is a longstanding computer vision challenge that focuses on differentiating objects belonging to multiple subordinate categories within the same meta-category. Since images belonging to the same meta-category usually share similar visual appearances, mining discriminative visual cues is the key to distinguishing fine-grained categories. Although commonly used image-level data augmentation techniques have achieved great success in generic image classification problems, they are rarely applied in fine-grained scenarios, because their random editing-region behavior is prone to destroy the discriminative visual cues residing in the subtle regions. In this paper, we propose diversifying the training data at the feature-level to alleviate the discriminative region loss problem. Specifically, we produce diversified augmented samples by translating image features along semantically meaningful directions. The semantic directions are estimated with a covariance prediction network, which predicts a sample-wise covariance matrix to adapt to the large intra-class variation inherent in fine-grained images. Furthermore, the covariance prediction network is jointly optimized with the classification network in a meta-learning manner to alleviate the degenerate solution problem. Experiments on four competitive fine-grained recognition benchmarks (CUB-200-2011, Stanford Cars, FGVC Aircrafts, NABirds) demonstrate that our method significantly improves the generalization performance on several popular classification networks (e.g., ResNets, DenseNets, EfficientNets, RegNets and ViT). Combined with a recently proposed method, our semantic data augmentation approach achieves state-of-the-art performance on the CUB-200-2011 dataset. The source code will be released.
MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion
Jul 16, 2023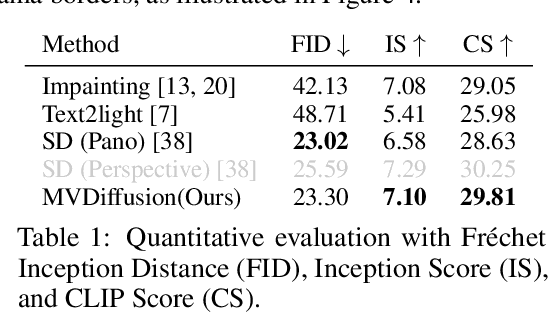
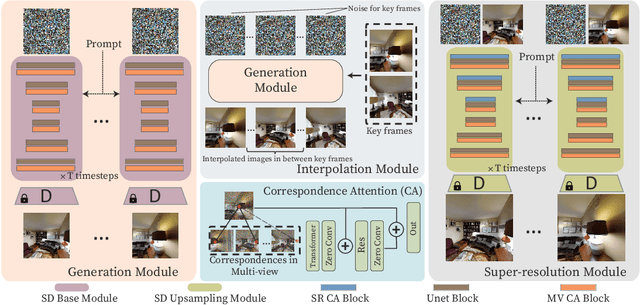
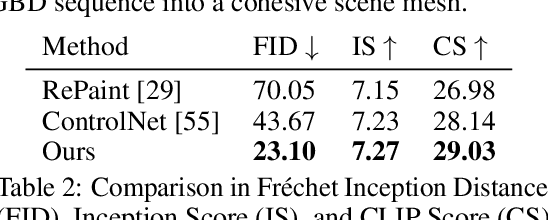
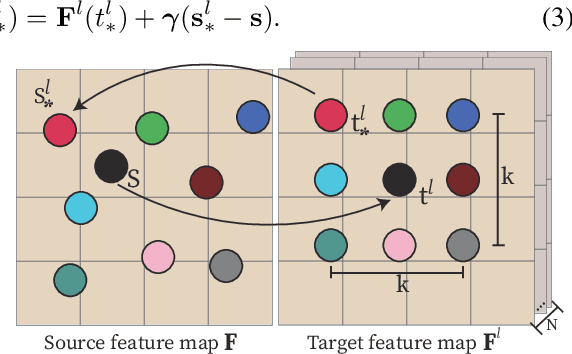
This paper introduces MVDiffusion, a simple yet effective multi-view image generation method for scenarios where pixel-to-pixel correspondences are available, such as perspective crops from panorama or multi-view images given geometry (depth maps and poses). Unlike prior models that rely on iterative image warping and inpainting, MVDiffusion concurrently generates all images with a global awareness, encompassing high resolution and rich content, effectively addressing the error accumulation prevalent in preceding models. MVDiffusion specifically incorporates a correspondence-aware attention mechanism, enabling effective cross-view interaction. This mechanism underpins three pivotal modules: 1) a generation module that produces low-resolution images while maintaining global correspondence, 2) an interpolation module that densifies spatial coverage between images, and 3) a super-resolution module that upscales into high-resolution outputs. In terms of panoramic imagery, MVDiffusion can generate high-resolution photorealistic images up to 1024$\times$1024 pixels. For geometry-conditioned multi-view image generation, MVDiffusion demonstrates the first method capable of generating a textured map of a scene mesh. The project page is at https://mvdiffusion.github.io.
Stage-by-stage Wavelet Optimization Refinement Diffusion Model for Sparse-View CT Reconstruction
Sep 03, 2023Diffusion models have emerged as potential tools to tackle the challenge of sparse-view CT reconstruction, displaying superior performance compared to conventional methods. Nevertheless, these prevailing diffusion models predominantly focus on the sinogram or image domains, which can lead to instability during model training, potentially culminating in convergence towards local minimal solutions. The wavelet trans-form serves to disentangle image contents and features into distinct frequency-component bands at varying scales, adeptly capturing diverse directional structures. Employing the Wavelet transform as a guiding sparsity prior significantly enhances the robustness of diffusion models. In this study, we present an innovative approach named the Stage-by-stage Wavelet Optimization Refinement Diffusion (SWORD) model for sparse-view CT reconstruction. Specifically, we establish a unified mathematical model integrating low-frequency and high-frequency generative models, achieving the solution with optimization procedure. Furthermore, we perform the low-frequency and high-frequency generative models on wavelet's decomposed components rather than sinogram or image domains, ensuring the stability of model training. Our method rooted in established optimization theory, comprising three distinct stages, including low-frequency generation, high-frequency refinement and domain transform. Our experimental results demonstrate that the proposed method outperforms existing state-of-the-art methods both quantitatively and qualitatively.
Symbolic Music Representations for Classification Tasks: A Systematic Evaluation
Sep 05, 2023
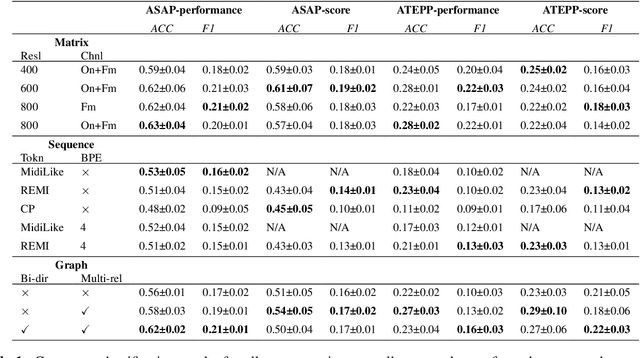
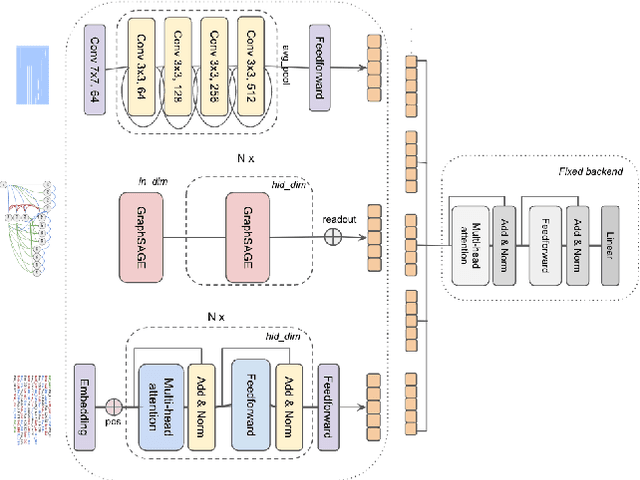
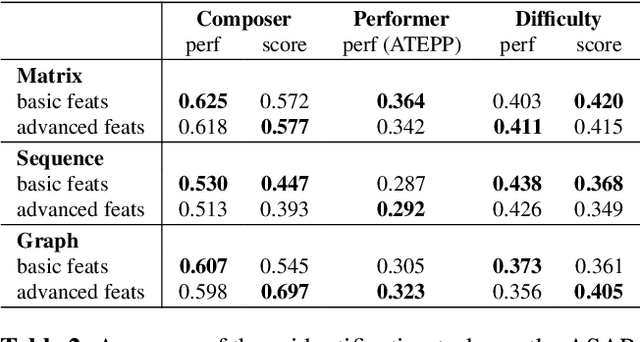
Music Information Retrieval (MIR) has seen a recent surge in deep learning-based approaches, which often involve encoding symbolic music (i.e., music represented in terms of discrete note events) in an image-like or language like fashion. However, symbolic music is neither an image nor a sentence, and research in the symbolic domain lacks a comprehensive overview of the different available representations. In this paper, we investigate matrix (piano roll), sequence, and graph representations and their corresponding neural architectures, in combination with symbolic scores and performances on three piece-level classification tasks. We also introduce a novel graph representation for symbolic performances and explore the capability of graph representations in global classification tasks. Our systematic evaluation shows advantages and limitations of each input representation. Our results suggest that the graph representation, as the newest and least explored among the three approaches, exhibits promising performance, while being more light-weight in training.