 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
When to Learn What: Model-Adaptive Data Augmentation Curriculum
Sep 09, 2023
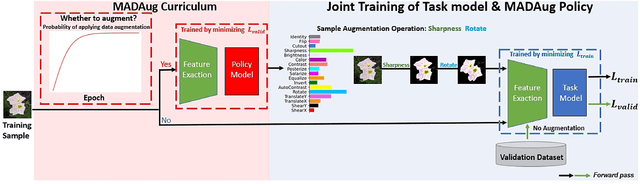
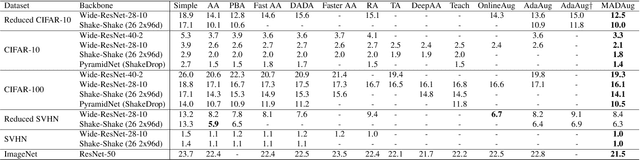
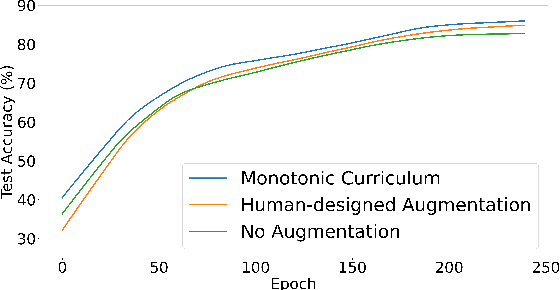

Data augmentation (DA) is widely used to improve the generalization of neural networks by enforcing the invariances and symmetries to pre-defined transformations applied to input data. However, a fixed augmentation policy may have different effects on each sample in different training stages but existing approaches cannot adjust the policy to be adaptive to each sample and the training model. In this paper, we propose Model Adaptive Data Augmentation (MADAug) that jointly trains an augmentation policy network to teach the model when to learn what. Unlike previous work, MADAug selects augmentation operators for each input image by a model-adaptive policy varying between training stages, producing a data augmentation curriculum optimized for better generalization. In MADAug, we train the policy through a bi-level optimization scheme, which aims to minimize a validation-set loss of a model trained using the policy-produced data augmentations. We conduct an extensive evaluation of MADAug on multiple image classification tasks and network architectures with thorough comparisons to existing DA approaches. MADAug outperforms or is on par with other baselines and exhibits better fairness: it brings improvement to all classes and more to the difficult ones. Moreover, MADAug learned policy shows better performance when transferred to fine-grained datasets. In addition, the auto-optimized policy in MADAug gradually introduces increasing perturbations and naturally forms an easy-to-hard curriculum.
Test Time Adaptation for Blind Image Quality Assessment
Jul 27, 2023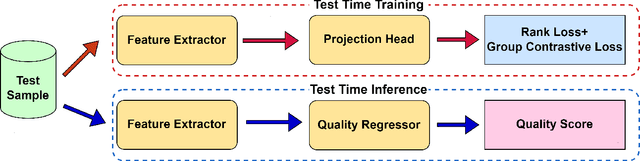
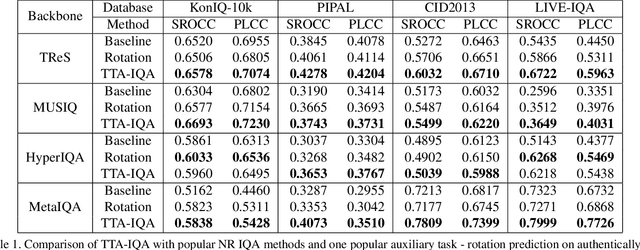
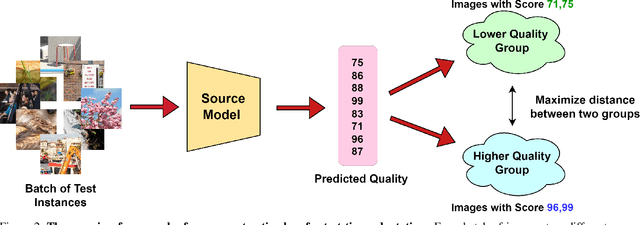
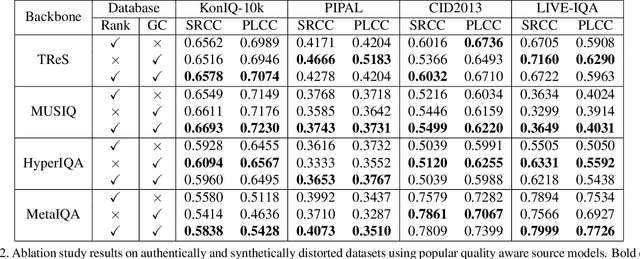
While the design of blind image quality assessment (IQA) algorithms has improved significantly, the distribution shift between the training and testing scenarios often leads to a poor performance of these methods at inference time. This motivates the study of test time adaptation (TTA) techniques to improve their performance at inference time. Existing auxiliary tasks and loss functions used for TTA may not be relevant for quality-aware adaptation of the pre-trained model. In this work, we introduce two novel quality-relevant auxiliary tasks at the batch and sample levels to enable TTA for blind IQA. In particular, we introduce a group contrastive loss at the batch level and a relative rank loss at the sample level to make the model quality aware and adapt to the target data. Our experiments reveal that even using a small batch of images from the test distribution helps achieve significant improvement in performance by updating the batch normalization statistics of the source model.
Bayesian uncertainty-weighted loss for improved generalisability on polyp segmentation task
Sep 13, 2023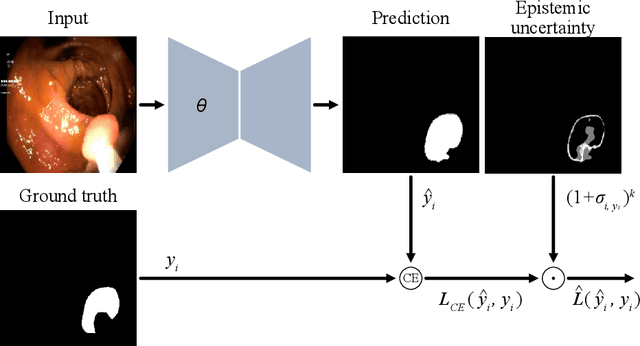
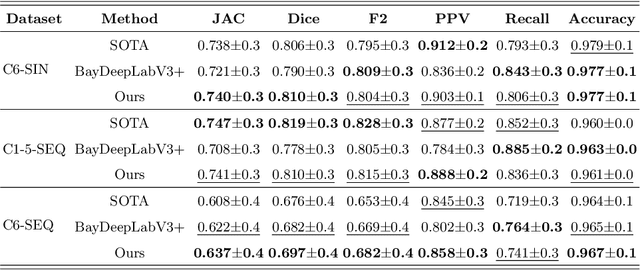
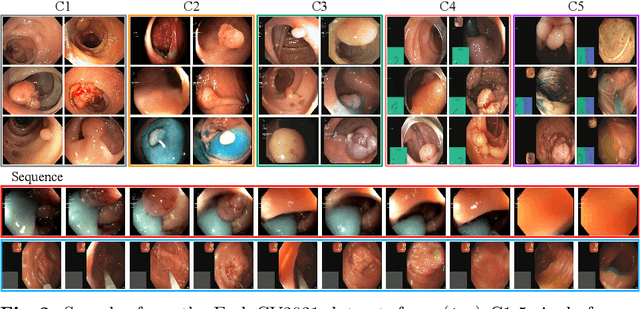
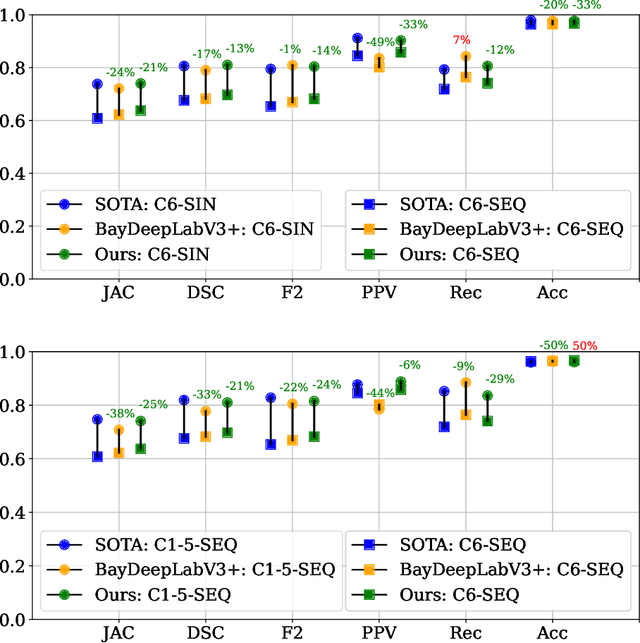
While several previous studies have devised methods for segmentation of polyps, most of these methods are not rigorously assessed on multi-center datasets. Variability due to appearance of polyps from one center to another, difference in endoscopic instrument grades, and acquisition quality result in methods with good performance on in-distribution test data, and poor performance on out-of-distribution or underrepresented samples. Unfair models have serious implications and pose a critical challenge to clinical applications. We adapt an implicit bias mitigation method which leverages Bayesian epistemic uncertainties during training to encourage the model to focus on underrepresented sample regions. We demonstrate the potential of this approach to improve generalisability without sacrificing state-of-the-art performance on a challenging multi-center polyp segmentation dataset (PolypGen) with different centers and image modalities.
Coco-LIC: Continuous-Time Tightly-Coupled LiDAR-Inertial-Camera Odometry using Non-Uniform B-spline
Sep 18, 2023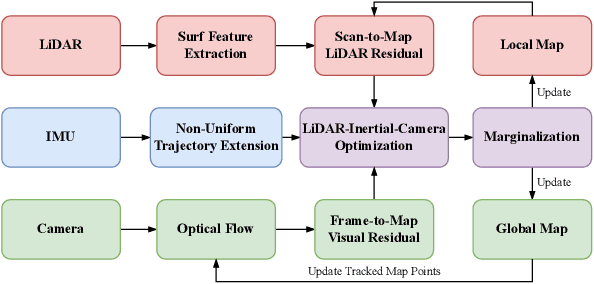
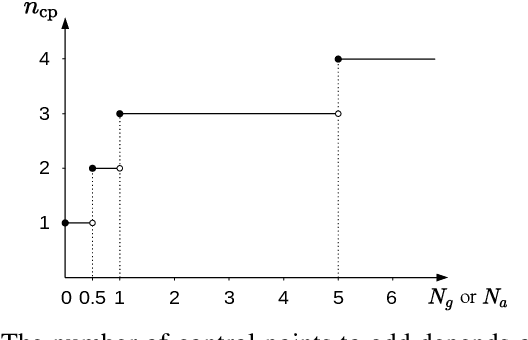
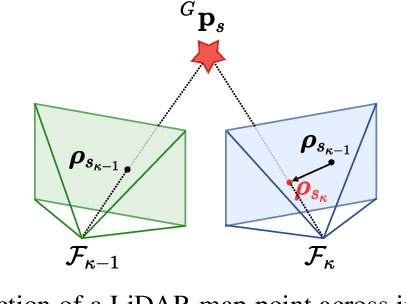
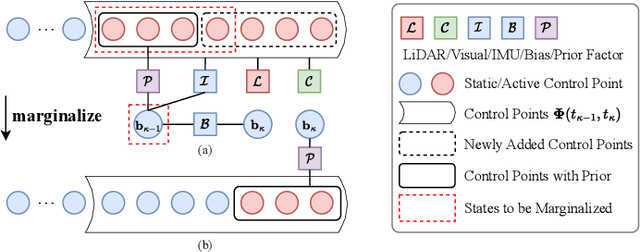
In this paper, we propose an efficient continuous-time LiDAR-Inertial-Camera Odometry, utilizing non-uniform B-splines to tightly couple measurements from the LiDAR, IMU, and camera. In contrast to uniform B-spline-based continuous-time methods, our non-uniform B-spline approach offers significant advantages in terms of achieving real-time efficiency and high accuracy. This is accomplished by dynamically and adaptively placing control points, taking into account the varying dynamics of the motion. To enable efficient fusion of heterogeneous LiDAR-Inertial-Camera data within a short sliding-window optimization, we assign depth to visual pixels using corresponding map points from a global LiDAR map, and formulate frame-to-map reprojection factors for the associated pixels in the current image frame. This way circumvents the necessity for depth optimization of visual pixels, which typically entails a lengthy sliding window with numerous control points for continuous-time trajectory estimation. We conduct dedicated experiments on real-world datasets to demonstrate the advantage and efficacy of adopting non-uniform continuous-time trajectory representation. Our LiDAR-Inertial-Camera odometry system is also extensively evaluated on both challenging scenarios with sensor degenerations and large-scale scenarios, and has shown comparable or higher accuracy than the state-of-the-art methods. The codebase of this paper will also be open-sourced at https://github.com/APRIL-ZJU/Coco-LIC.
FactoFormer: Factorized Hyperspectral Transformers with Self-Supervised Pre-Training
Sep 18, 2023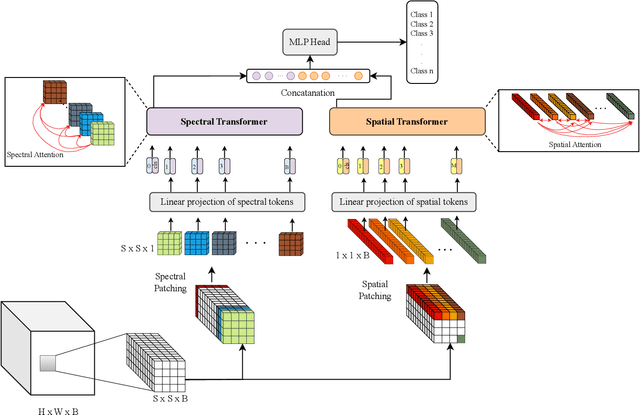
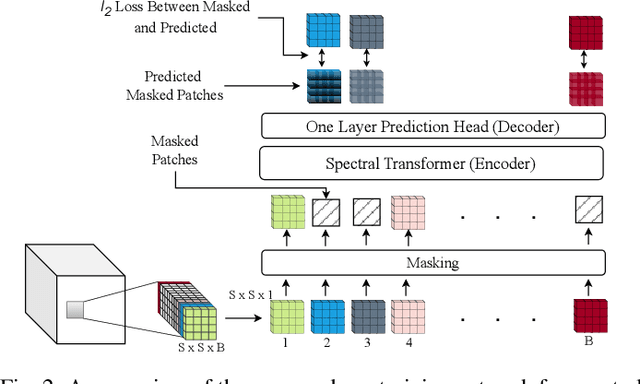
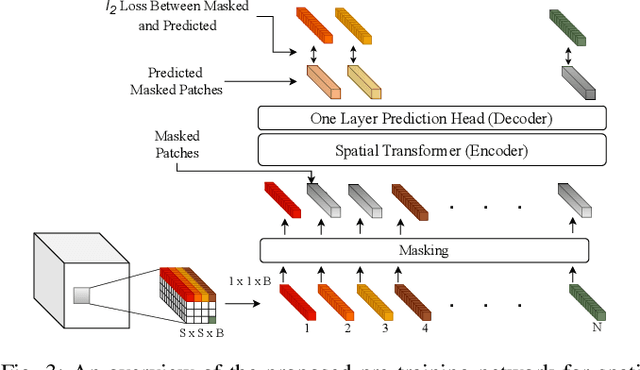
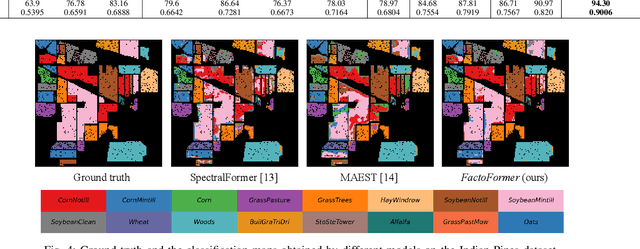
Hyperspectral images (HSIs) contain rich spectral and spatial information. Motivated by the success of transformers in the field of natural language processing and computer vision where they have shown the ability to learn long range dependencies within input data, recent research has focused on using transformers for HSIs. However, current state-of-the-art hyperspectral transformers only tokenize the input HSI sample along the spectral dimension, resulting in the under-utilization of spatial information. Moreover, transformers are known to be data-hungry and their performance relies heavily on large-scale pre-training, which is challenging due to limited annotated hyperspectral data. Therefore, the full potential of HSI transformers has not been fully realized. To overcome these limitations, we propose a novel factorized spectral-spatial transformer that incorporates factorized self-supervised pre-training procedures, leading to significant improvements in performance. The factorization of the inputs allows the spectral and spatial transformers to better capture the interactions within the hyperspectral data cubes. Inspired by masked image modeling pre-training, we also devise efficient masking strategies for pre-training each of the spectral and spatial transformers. We conduct experiments on three publicly available datasets for HSI classification task and demonstrate that our model achieves state-of-the-art performance in all three datasets. The code for our model will be made available at https://github.com/csiro-robotics/factoformer.
Object2Scene: Putting Objects in Context for Open-Vocabulary 3D Detection
Sep 18, 2023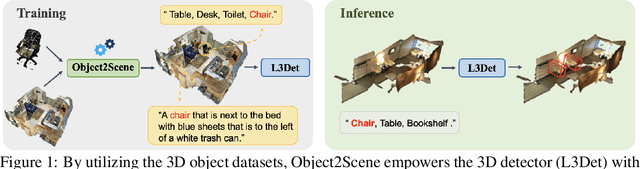

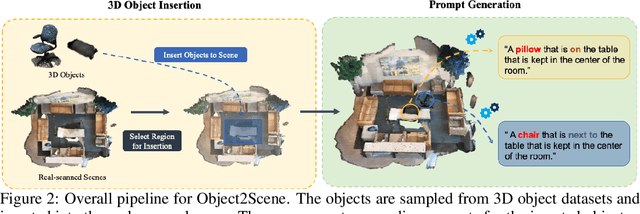
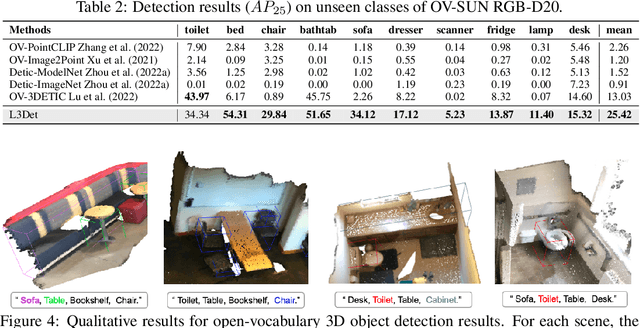
Point cloud-based open-vocabulary 3D object detection aims to detect 3D categories that do not have ground-truth annotations in the training set. It is extremely challenging because of the limited data and annotations (bounding boxes with class labels or text descriptions) of 3D scenes. Previous approaches leverage large-scale richly-annotated image datasets as a bridge between 3D and category semantics but require an extra alignment process between 2D images and 3D points, limiting the open-vocabulary ability of 3D detectors. Instead of leveraging 2D images, we propose Object2Scene, the first approach that leverages large-scale large-vocabulary 3D object datasets to augment existing 3D scene datasets for open-vocabulary 3D object detection. Object2Scene inserts objects from different sources into 3D scenes to enrich the vocabulary of 3D scene datasets and generates text descriptions for the newly inserted objects. We further introduce a framework that unifies 3D detection and visual grounding, named L3Det, and propose a cross-domain category-level contrastive learning approach to mitigate the domain gap between 3D objects from different datasets. Extensive experiments on existing open-vocabulary 3D object detection benchmarks show that Object2Scene obtains superior performance over existing methods. We further verify the effectiveness of Object2Scene on a new benchmark OV-ScanNet-200, by holding out all rare categories as novel categories not seen during training.
Symbolic Music Representations for Classification Tasks: A Systematic Evaluation
Sep 05, 2023
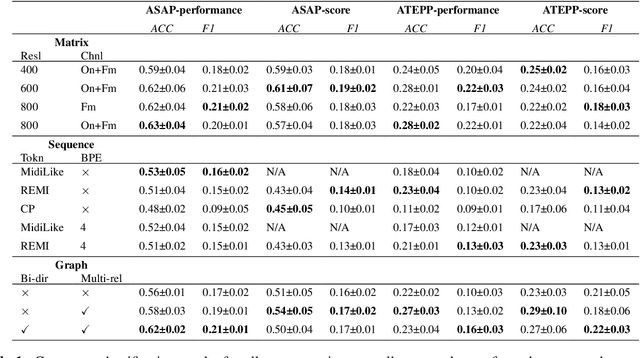
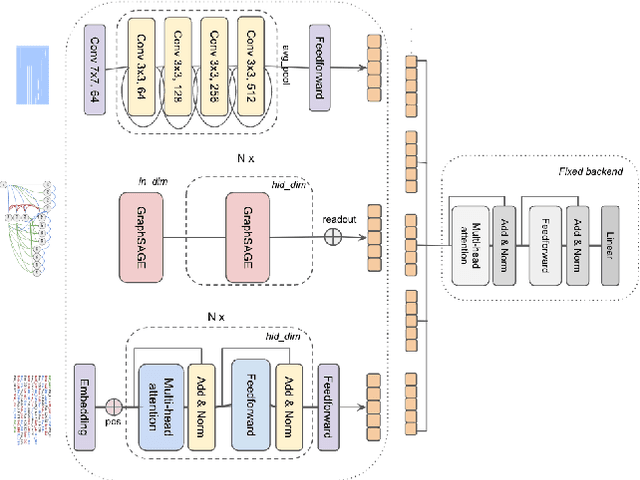
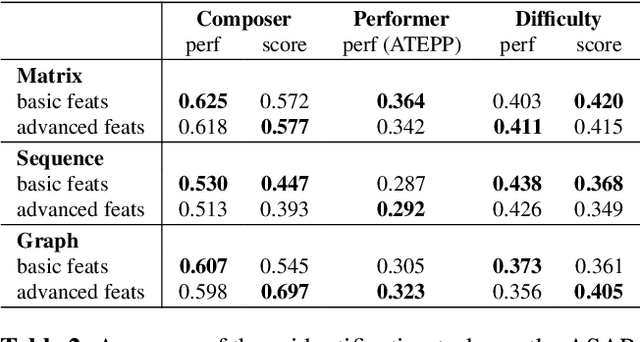
Music Information Retrieval (MIR) has seen a recent surge in deep learning-based approaches, which often involve encoding symbolic music (i.e., music represented in terms of discrete note events) in an image-like or language like fashion. However, symbolic music is neither an image nor a sentence, and research in the symbolic domain lacks a comprehensive overview of the different available representations. In this paper, we investigate matrix (piano roll), sequence, and graph representations and their corresponding neural architectures, in combination with symbolic scores and performances on three piece-level classification tasks. We also introduce a novel graph representation for symbolic performances and explore the capability of graph representations in global classification tasks. Our systematic evaluation shows advantages and limitations of each input representation. Our results suggest that the graph representation, as the newest and least explored among the three approaches, exhibits promising performance, while being more light-weight in training.
Unsupervised Skin Lesion Segmentation via Structural Entropy Minimization on Multi-Scale Superpixel Graphs
Sep 05, 2023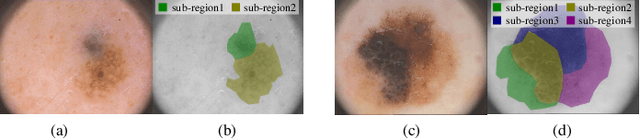
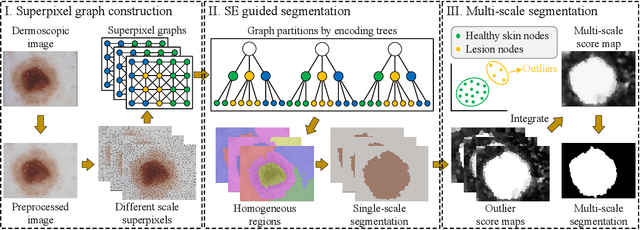
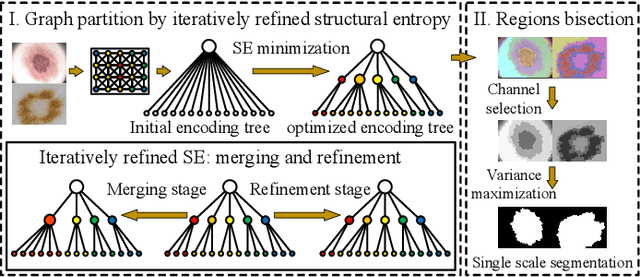

Skin lesion segmentation is a fundamental task in dermoscopic image analysis. The complex features of pixels in the lesion region impede the lesion segmentation accuracy, and existing deep learning-based methods often lack interpretability to this problem. In this work, we propose a novel unsupervised Skin Lesion sEgmentation framework based on structural entropy and isolation forest outlier Detection, namely SLED. Specifically, skin lesions are segmented by minimizing the structural entropy of a superpixel graph constructed from the dermoscopic image. Then, we characterize the consistency of healthy skin features and devise a novel multi-scale segmentation mechanism by outlier detection, which enhances the segmentation accuracy by leveraging the superpixel features from multiple scales. We conduct experiments on four skin lesion benchmarks and compare SLED with nine representative unsupervised segmentation methods. Experimental results demonstrate the superiority of the proposed framework. Additionally, some case studies are analyzed to demonstrate the effectiveness of SLED.
Empowering Visually Impaired Individuals: A Novel Use of Apple Live Photos and Android Motion Photos
Sep 14, 2023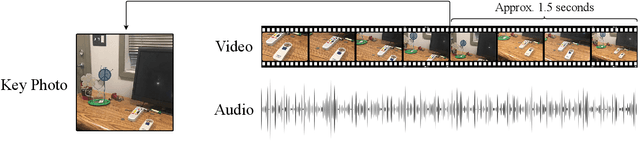



Numerous applications have been developed to assist visually impaired individuals that employ a machine learning unit to process visual input. However, a critical challenge with these applications is the sub-optimal quality of images captured by the users. Given the complexity of operating a camera for visually impaired individuals, we advocate for the use of Apple Live Photos and Android Motion Photos technologies. In this study, we introduce a straightforward methodology to evaluate and contrast the efficacy of Live/Motion Photos against traditional image-based approaches. Our findings reveal that both Live Photos and Motion Photos outperform single-frame images in common visual assisting tasks, specifically in object classification and VideoQA. We validate our results through extensive experiments on the ORBIT dataset, which consists of videos collected by visually impaired individuals. Furthermore, we conduct a series of ablation studies to delve deeper into the impact of deblurring and longer temporal crops.
A Novel Local-Global Feature Fusion Framework for Body-weight Exercise Recognition with Pressure Mapping Sensors
Sep 14, 2023We present a novel local-global feature fusion framework for body-weight exercise recognition with floor-based dynamic pressure maps. One step further from the existing studies using deep neural networks mainly focusing on global feature extraction, the proposed framework aims to combine local and global features using image processing techniques and the YOLO object detection to localize pressure profiles from different body parts and consider physical constraints. The proposed local feature extraction method generates two sets of high-level local features consisting of cropped pressure mapping and numerical features such as angular orientation, location on the mat, and pressure area. In addition, we adopt a knowledge distillation for regularization to preserve the knowledge of the global feature extraction and improve the performance of the exercise recognition. Our experimental results demonstrate a notable 11 percent improvement in F1 score for exercise recognition while preserving label-specific features.