 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the Posterior Distribution in Denoising: Application to Uncertainty Quantification
Sep 24, 2023
Denoisers play a central role in many applications, from noise suppression in low-grade imaging sensors, to empowering score-based generative models. The latter category of methods makes use of Tweedie's formula, which links the posterior mean in Gaussian denoising (i.e., the minimum MSE denoiser) with the score of the data distribution. Here, we derive a fundamental relation between the higher-order central moments of the posterior distribution, and the higher-order derivatives of the posterior mean. We harness this result for uncertainty quantification of pre-trained denoisers. Particularly, we show how to efficiently compute the principal components of the posterior distribution for any desired region of an image, as well as to approximate the full marginal distribution along those (or any other) one-dimensional directions. Our method is fast and memory efficient, as it does not explicitly compute or store the high-order moment tensors and it requires no training or fine tuning of the denoiser. Code and examples are available on the project's webpage in https://hilamanor.github.io/GaussianDenoisingPosterior/
A matter of attitude: Focusing on positive and active gradients to boost saliency maps
Sep 22, 2023
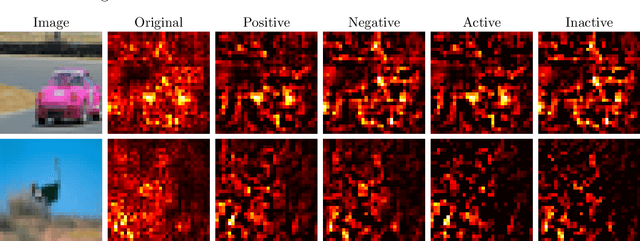
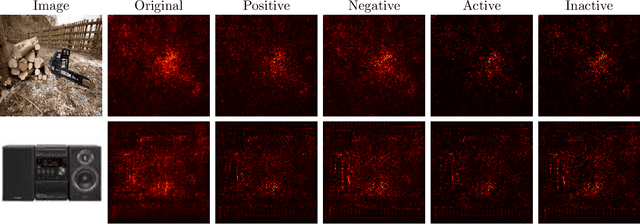

Saliency maps have become one of the most widely used interpretability techniques for convolutional neural networks (CNN) due to their simplicity and the quality of the insights they provide. However, there are still some doubts about whether these insights are a trustworthy representation of what CNNs use to come up with their predictions. This paper explores how rescuing the sign of the gradients from the saliency map can lead to a deeper understanding of multi-class classification problems. Using both pretrained and trained from scratch CNNs we unveil that considering the sign and the effect not only of the correct class, but also the influence of the other classes, allows to better identify the pixels of the image that the network is really focusing on. Furthermore, how occluding or altering those pixels is expected to affect the outcome also becomes clearer.
AnomalyGPT: Detecting Industrial Anomalies using Large Vision-Language Models
Sep 13, 2023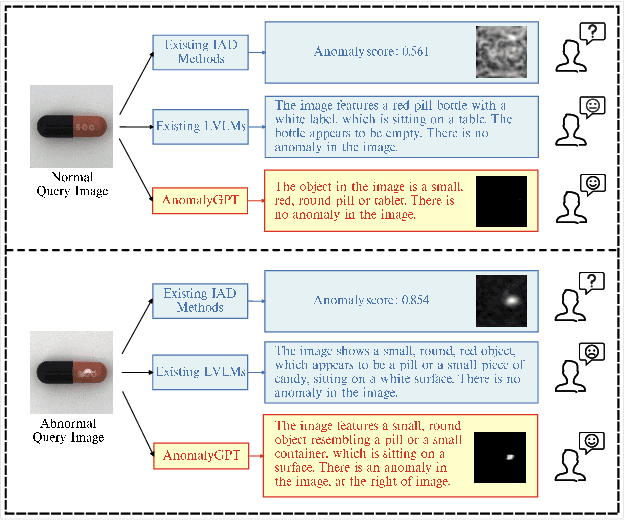

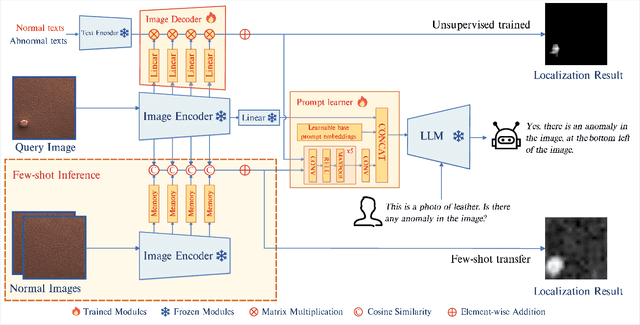
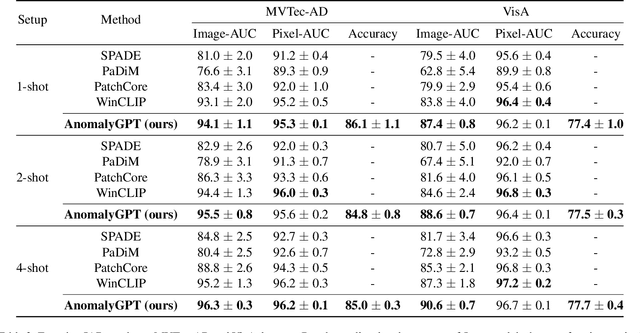
Large Vision-Language Models (LVLMs) such as MiniGPT-4 and LLaVA have demonstrated the capability of understanding images and achieved remarkable performance in various visual tasks. Despite their strong abilities in recognizing common objects due to extensive training datasets, they lack specific domain knowledge and have a weaker understanding of localized details within objects, which hinders their effectiveness in the Industrial Anomaly Detection (IAD) task. On the other hand, most existing IAD methods only provide anomaly scores and necessitate the manual setting of thresholds to distinguish between normal and abnormal samples, which restricts their practical implementation. In this paper, we explore the utilization of LVLM to address the IAD problem and propose AnomalyGPT, a novel IAD approach based on LVLM. We generate training data by simulating anomalous images and producing corresponding textual descriptions for each image. We also employ an image decoder to provide fine-grained semantic and design a prompt learner to fine-tune the LVLM using prompt embeddings. Our AnomalyGPT eliminates the need for manual threshold adjustments, thus directly assesses the presence and locations of anomalies. Additionally, AnomalyGPT supports multi-turn dialogues and exhibits impressive few-shot in-context learning capabilities. With only one normal shot, AnomalyGPT achieves the state-of-the-art performance with an accuracy of 86.1%, an image-level AUC of 94.1%, and a pixel-level AUC of 95.3% on the MVTec-AD dataset. Code is available at https://github.com/CASIA-IVA-Lab/AnomalyGPT.
StereoFlowGAN: Co-training for Stereo and Flow with Unsupervised Domain Adaptation
Sep 04, 2023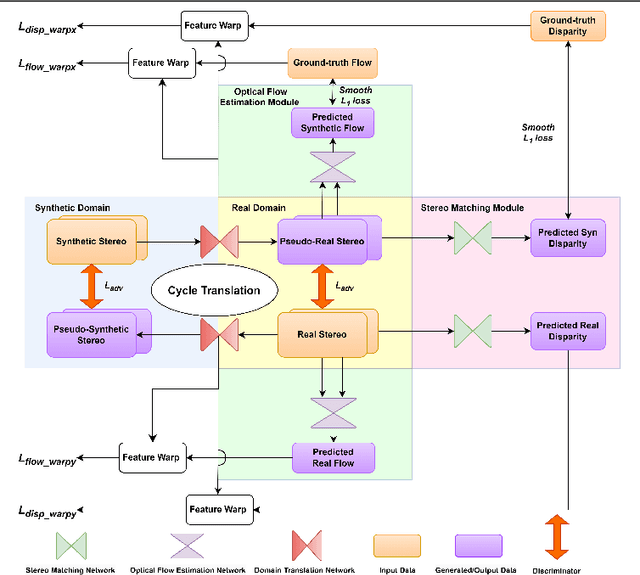

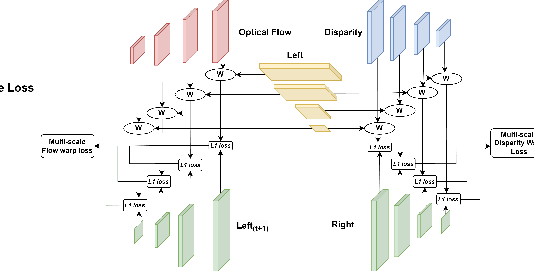

We introduce a novel training strategy for stereo matching and optical flow estimation that utilizes image-to-image translation between synthetic and real image domains. Our approach enables the training of models that excel in real image scenarios while relying solely on ground-truth information from synthetic images. To facilitate task-agnostic domain adaptation and the training of task-specific components, we introduce a bidirectional feature warping module that handles both left-right and forward-backward directions. Experimental results show competitive performance over previous domain translation-based methods, which substantiate the efficacy of our proposed framework, effectively leveraging the benefits of unsupervised domain adaptation, stereo matching, and optical flow estimation.
CCSPNet-Joint: Efficient Joint Training Method for Traffic Sign Detection Under Extreme Conditions
Sep 14, 2023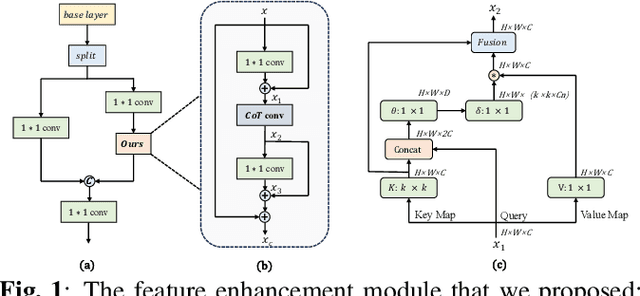
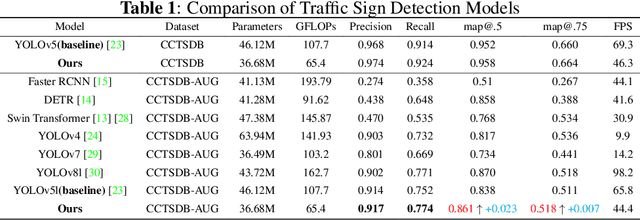
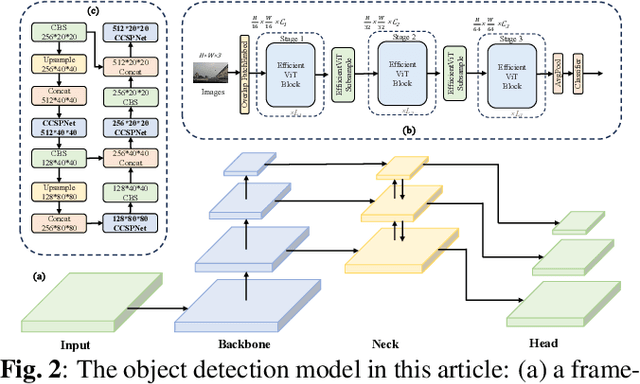
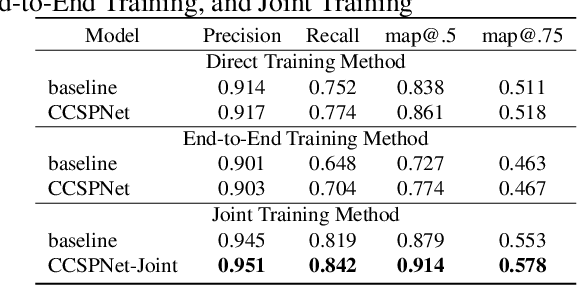
Traffic sign detection is an important research direction in intelligent driving. Unfortunately, existing methods often overlook extreme conditions such as fog, rain, and motion blur. Moreover, the end-to-end training strategy for image denoising and object detection models fails to utilize inter-model information effectively. To address these issues, we propose CCSPNet, an efficient feature extraction module based on Transformers and CNNs, which effectively leverages contextual information, achieves faster inference speed and provides stronger feature enhancement capabilities. Furthermore, we establish the correlation between object detection and image denoising tasks and propose a joint training model, CCSPNet-Joint, to improve data efficiency and generalization. Finally, to validate our approach, we create the CCTSDB-AUG dataset for traffic sign detection in extreme scenarios. Extensive experiments have shown that CCSPNet achieves state-of-the-art performance in traffic sign detection under extreme conditions. Compared to end-to-end methods, CCSPNet-Joint achieves a 5.32% improvement in precision and an 18.09% improvement in mAP@.5.
Subject-Diffusion:Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning
Jul 21, 2023Recent progress in personalized image generation using diffusion models has been significant. However, development in the area of open-domain and non-fine-tuning personalized image generation is proceeding rather slowly. In this paper, we propose Subject-Diffusion, a novel open-domain personalized image generation model that, in addition to not requiring test-time fine-tuning, also only requires a single reference image to support personalized generation of single- or multi-subject in any domain. Firstly, we construct an automatic data labeling tool and use the LAION-Aesthetics dataset to construct a large-scale dataset consisting of 76M images and their corresponding subject detection bounding boxes, segmentation masks and text descriptions. Secondly, we design a new unified framework that combines text and image semantics by incorporating coarse location and fine-grained reference image control to maximize subject fidelity and generalization. Furthermore, we also adopt an attention control mechanism to support multi-subject generation. Extensive qualitative and quantitative results demonstrate that our method outperforms other SOTA frameworks in single, multiple, and human customized image generation. Please refer to our \href{https://oppo-mente-lab.github.io/subject_diffusion/}{project page}
SuperInpaint: Learning Detail-Enhanced Attentional Implicit Representation for Super-resolutional Image Inpainting
Jul 26, 2023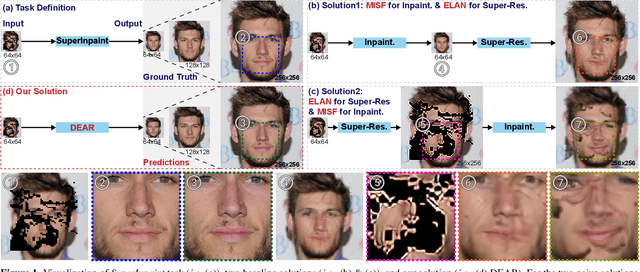
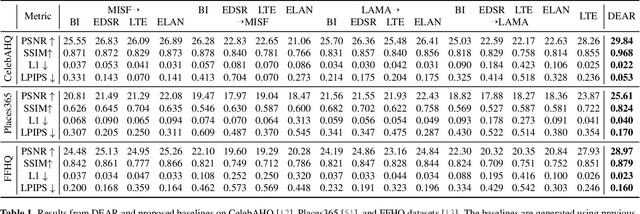
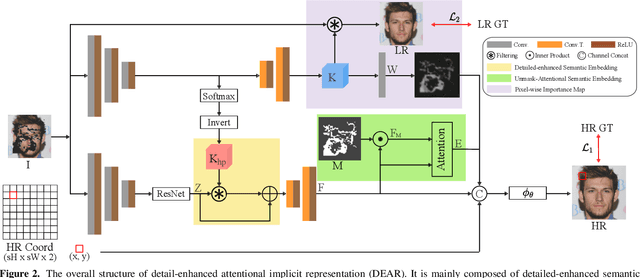
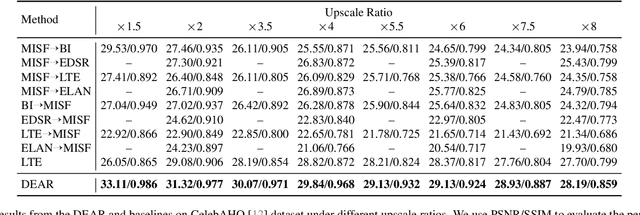
In this work, we introduce a challenging image restoration task, referred to as SuperInpaint, which aims to reconstruct missing regions in low-resolution images and generate completed images with arbitrarily higher resolutions. We have found that this task cannot be effectively addressed by stacking state-of-the-art super-resolution and image inpainting methods as they amplify each other's flaws, leading to noticeable artifacts. To overcome these limitations, we propose the detail-enhanced attentional implicit representation (DEAR) that can achieve SuperInpaint with a single model, resulting in high-quality completed images with arbitrary resolutions. Specifically, we use a deep convolutional network to extract the latent embedding of an input image and then enhance the high-frequency components of the latent embedding via an adaptive high-pass filter. This leads to detail-enhanced semantic embedding. We further feed the semantic embedding into an unmask-attentional module that suppresses embeddings from ineffective masked pixels. Additionally, we extract a pixel-wise importance map that indicates which pixels should be used for image reconstruction. Given the coordinates of a pixel we want to reconstruct, we first collect its neighboring pixels in the input image and extract their detail-enhanced semantic embeddings, unmask-attentional semantic embeddings, importance values, and spatial distances to the desired pixel. Then, we feed all the above terms into an implicit representation and generate the color of the specified pixel. To evaluate our method, we extend three existing datasets for this new task and build 18 meaningful baselines using SOTA inpainting and super-resolution methods. Extensive experimental results demonstrate that our method outperforms all existing methods by a significant margin on four widely used metrics.
Class-Specific Distribution Alignment for Semi-Supervised Medical Image Classification
Jul 29, 2023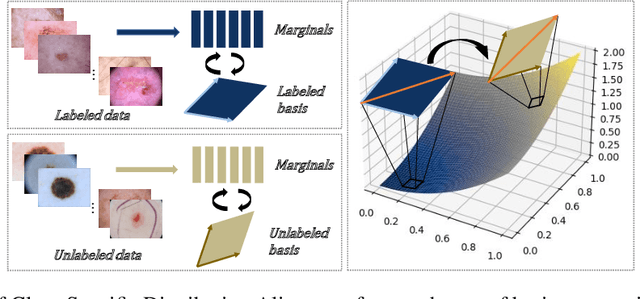

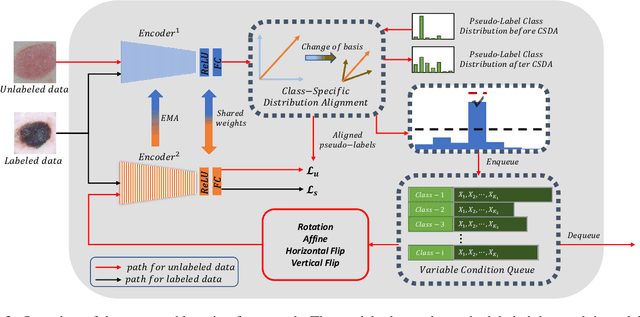
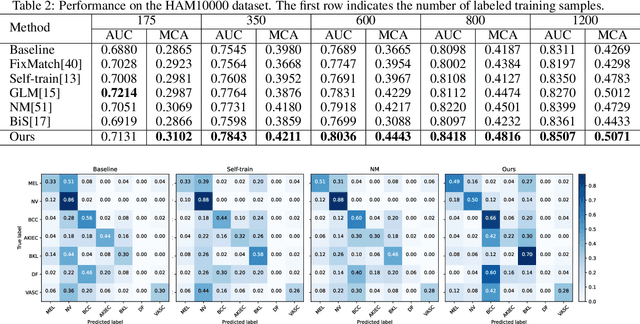
Despite the success of deep neural networks in medical image classification, the problem remains challenging as data annotation is time-consuming, and the class distribution is imbalanced due to the relative scarcity of diseases. To address this problem, we propose Class-Specific Distribution Alignment (CSDA), a semi-supervised learning framework based on self-training that is suitable to learn from highly imbalanced datasets. Specifically, we first provide a new perspective to distribution alignment by considering the process as a change of basis in the vector space spanned by marginal predictions, and then derive CSDA to capture class-dependent marginal predictions on both labeled and unlabeled data, in order to avoid the bias towards majority classes. Furthermore, we propose a Variable Condition Queue (VCQ) module to maintain a proportionately balanced number of unlabeled samples for each class. Experiments on three public datasets HAM10000, CheXpert and Kvasir show that our method provides competitive performance on semi-supervised skin disease, thoracic disease, and endoscopic image classification tasks.
MindGPT: Interpreting What You See with Non-invasive Brain Recordings
Sep 27, 2023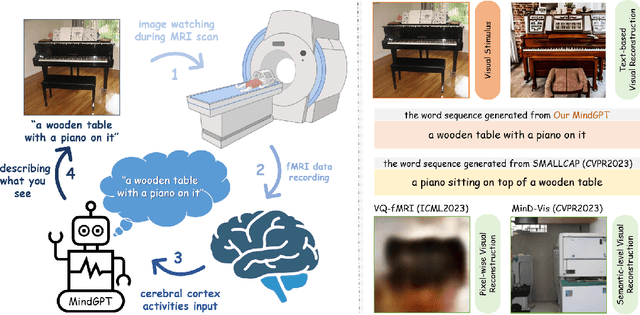
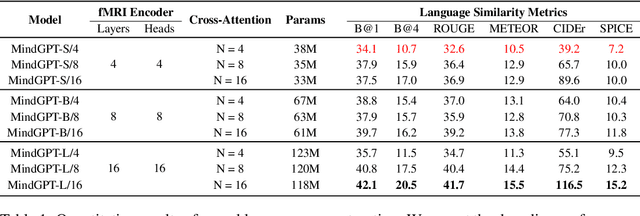
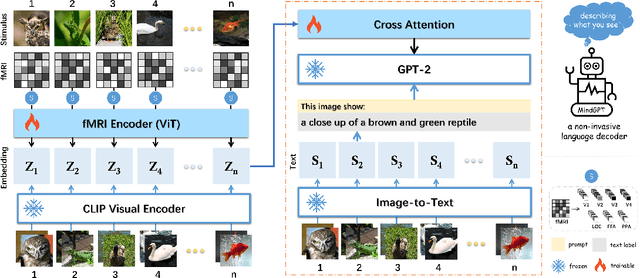
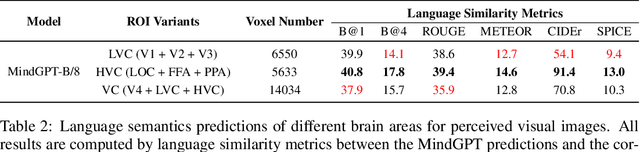
Decoding of seen visual contents with non-invasive brain recordings has important scientific and practical values. Efforts have been made to recover the seen images from brain signals. However, most existing approaches cannot faithfully reflect the visual contents due to insufficient image quality or semantic mismatches. Compared with reconstructing pixel-level visual images, speaking is a more efficient and effective way to explain visual information. Here we introduce a non-invasive neural decoder, termed as MindGPT, which interprets perceived visual stimuli into natural languages from fMRI signals. Specifically, our model builds upon a visually guided neural encoder with a cross-attention mechanism, which permits us to guide latent neural representations towards a desired language semantic direction in an end-to-end manner by the collaborative use of the large language model GPT. By doing so, we found that the neural representations of the MindGPT are explainable, which can be used to evaluate the contributions of visual properties to language semantics. Our experiments show that the generated word sequences truthfully represented the visual information (with essential details) conveyed in the seen stimuli. The results also suggested that with respect to language decoding tasks, the higher visual cortex (HVC) is more semantically informative than the lower visual cortex (LVC), and using only the HVC can recover most of the semantic information. The code of the MindGPT model will be publicly available at https://github.com/JxuanC/MindGPT.
Fine-grained Text and Image Guided Point Cloud Completion with CLIP Model
Aug 17, 2023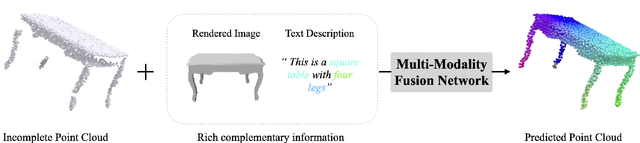
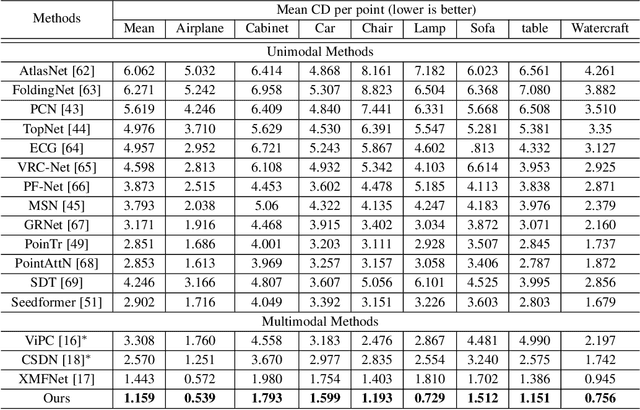
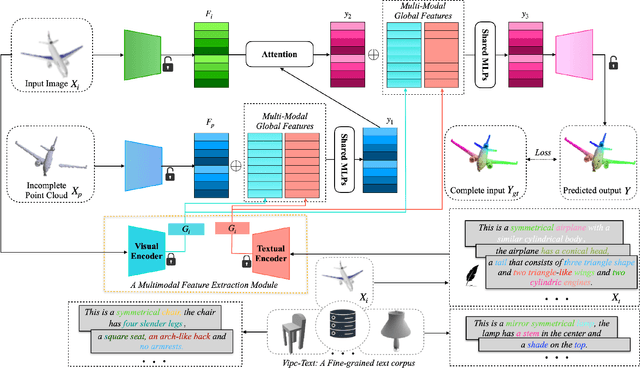
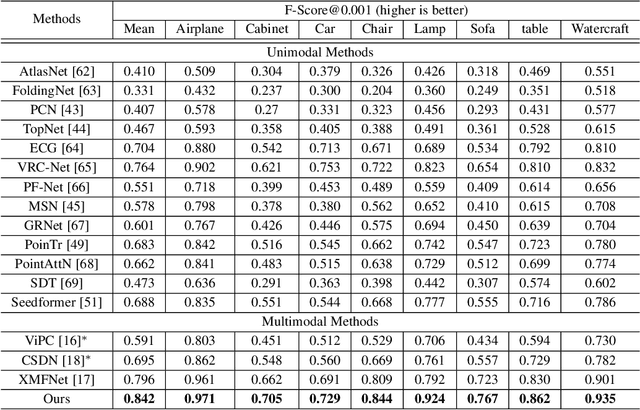
This paper focuses on the recently popular task of point cloud completion guided by multimodal information. Although existing methods have achieved excellent performance by fusing auxiliary images, there are still some deficiencies, including the poor generalization ability of the model and insufficient fine-grained semantic information for extracted features. In this work, we propose a novel multimodal fusion network for point cloud completion, which can simultaneously fuse visual and textual information to predict the semantic and geometric characteristics of incomplete shapes effectively. Specifically, to overcome the lack of prior information caused by the small-scale dataset, we employ a pre-trained vision-language model that is trained with a large amount of image-text pairs. Therefore, the textual and visual encoders of this large-scale model have stronger generalization ability. Then, we propose a multi-stage feature fusion strategy to fuse the textual and visual features into the backbone network progressively. Meanwhile, to further explore the effectiveness of fine-grained text descriptions for point cloud completion, we also build a text corpus with fine-grained descriptions, which can provide richer geometric details for 3D shapes. The rich text descriptions can be used for training and evaluating our network. Extensive quantitative and qualitative experiments demonstrate the superior performance of our method compared to state-of-the-art point cloud completion networks.