 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SpikeExplorer: hardware-oriented Design Space Exploration for Spiking Neural Networks on FPGA
Apr 04, 2024
One of today's main concerns is to bring Artificial Intelligence power to embedded systems for edge applications. The hardware resources and power consumption required by state-of-the-art models are incompatible with the constrained environments observed in edge systems, such as IoT nodes and wearable devices. Spiking Neural Networks (SNNs) can represent a solution in this sense: inspired by neuroscience, they reach unparalleled power and resource efficiency when run on dedicated hardware accelerators. However, when designing such accelerators, the amount of choices that can be taken is huge. This paper presents SpikExplorer, a modular and flexible Python tool for hardware-oriented Automatic Design Space Exploration to automate the configuration of FPGA accelerators for SNNs. Using Bayesian optimizations, SpikerExplorer enables hardware-centric multi-objective optimization, supporting factors such as accuracy, area, latency, power, and various combinations during the exploration process. The tool searches the optimal network architecture, neuron model, and internal and training parameters, trying to reach the desired constraints imposed by the user. It allows for a straightforward network configuration, providing the full set of explored points for the user to pick the trade-off that best fits the needs. The potential of SpikExplorer is showcased using three benchmark datasets. It reaches 95.8% accuracy on the MNIST dataset, with a power consumption of 180mW/image and a latency of 0.12 ms/image, making it a powerful tool for automatically optimizing SNNs.
MaskSAM: Towards Auto-prompt SAM with Mask Classification for Medical Image Segmentation
Mar 21, 2024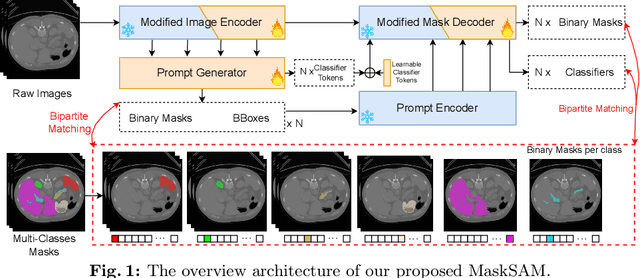
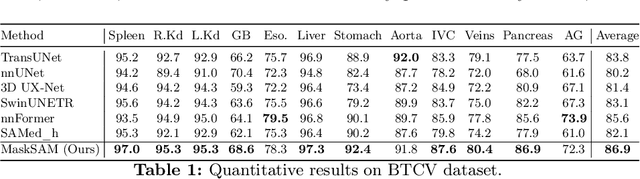
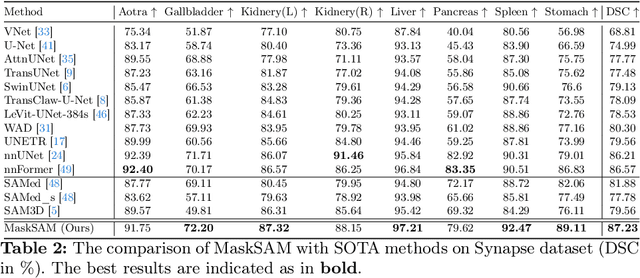
Segment Anything Model~(SAM), a prompt-driven foundation model for natural image segmentation, has demonstrated impressive zero-shot performance. However, SAM does not work when directly applied to medical image segmentation tasks, since SAM lacks the functionality to predict semantic labels for predicted masks and needs to provide extra prompts, such as points or boxes, to segment target regions. Meanwhile, there is a huge gap between 2D natural images and 3D medical images, so the performance of SAM is imperfect for medical image segmentation tasks. Following the above issues, we propose MaskSAM, a novel mask classification prompt-free SAM adaptation framework for medical image segmentation. We design a prompt generator combined with the image encoder in SAM to generate a set of auxiliary classifier tokens, auxiliary binary masks, and auxiliary bounding boxes. Each pair of auxiliary mask and box prompts, which can solve the requirements of extra prompts, is associated with class label predictions by the sum of the auxiliary classifier token and the learnable global classifier tokens in the mask decoder of SAM to solve the predictions of semantic labels. Meanwhile, we design a 3D depth-convolution adapter for image embeddings and a 3D depth-MLP adapter for prompt embeddings. We inject one of them into each transformer block in the image encoder and mask decoder to enable pre-trained 2D SAM models to extract 3D information and adapt to 3D medical images. Our method achieves state-of-the-art performance on AMOS2022, 90.52% Dice, which improved by 2.7% compared to nnUNet. Our method surpasses nnUNet by 1.7% on ACDC and 1.0% on Synapse datasets.
Latent Diffusion Models for Attribute-Preserving Image Anonymization
Mar 21, 2024Generative techniques for image anonymization have great potential to generate datasets that protect the privacy of those depicted in the images, while achieving high data fidelity and utility. Existing methods have focused extensively on preserving facial attributes, but failed to embrace a more comprehensive perspective that considers the scene and background into the anonymization process. This paper presents, to the best of our knowledge, the first approach to image anonymization based on Latent Diffusion Models (LDMs). Every element of a scene is maintained to convey the same meaning, yet manipulated in a way that makes re-identification difficult. We propose two LDMs for this purpose: CAMOUFLaGE-Base exploits a combination of pre-trained ControlNets, and a new controlling mechanism designed to increase the distance between the real and anonymized images. CAMOFULaGE-Light is based on the Adapter technique, coupled with an encoding designed to efficiently represent the attributes of different persons in a scene. The former solution achieves superior performance on most metrics and benchmarks, while the latter cuts the inference time in half at the cost of fine-tuning a lightweight module. We show through extensive experimental comparison that the proposed method is competitive with the state-of-the-art concerning identity obfuscation whilst better preserving the original content of the image and tackling unresolved challenges that current solutions fail to address.
Bridging Language, Vision and Action: Multimodal VAEs in Robotic Manipulation Tasks
Apr 02, 2024In this work, we focus on unsupervised vision-language-action mapping in the area of robotic manipulation. Recently, multiple approaches employing pre-trained large language and vision models have been proposed for this task. However, they are computationally demanding and require careful fine-tuning of the produced outputs. A more lightweight alternative would be the implementation of multimodal Variational Autoencoders (VAEs) which can extract the latent features of the data and integrate them into a joint representation, as has been demonstrated mostly on image-image or image-text data for the state-of-the-art models. Here we explore whether and how can multimodal VAEs be employed in unsupervised robotic manipulation tasks in a simulated environment. Based on the obtained results, we propose a model-invariant training alternative that improves the models' performance in a simulator by up to 55%. Moreover, we systematically evaluate the challenges raised by the individual tasks such as object or robot position variability, number of distractors or the task length. Our work thus also sheds light on the potential benefits and limitations of using the current multimodal VAEs for unsupervised learning of robotic motion trajectories based on vision and language.
The Solution for the CVPR 2023 1st foundation model challenge-Track2
Apr 02, 2024In this paper, we propose a solution for cross-modal transportation retrieval. Due to the cross-domain problem of traffic images, we divide the problem into two sub-tasks of pedestrian retrieval and vehicle retrieval through a simple strategy. In pedestrian retrieval tasks, we use IRRA as the base model and specifically design an Attribute Classification to mine the knowledge implied by attribute labels. More importantly, We use the strategy of Inclusion Relation Matching to make the image-text pairs with inclusion relation have similar representation in the feature space. For the vehicle retrieval task, we use BLIP as the base model. Since aligning the color attributes of vehicles is challenging, we introduce attribute-based object detection techniques to add color patch blocks to vehicle images for color data augmentation. This serves as strong prior information, helping the model perform the image-text alignment. At the same time, we incorporate labeled attributes into the image-text alignment loss to learn fine-grained alignment and prevent similar images and texts from being incorrectly separated. Our approach ranked first in the final B-board test with a score of 70.9.
Overfitted image coding at reduced complexity
Mar 18, 2024Overfitted image codecs offer compelling compression performance and low decoder complexity, through the overfitting of a lightweight decoder for each image. Such codecs include Cool-chic, which presents image coding performance on par with VVC while requiring around 2000 multiplications per decoded pixel. This paper proposes to decrease Cool-chic encoding and decoding complexity. The encoding complexity is reduced by shortening Cool-chic training, up to the point where no overfitting is performed at all. It is also shown that a tiny neural decoder with 300 multiplications per pixel still outperforms HEVC. A near real-time CPU implementation of this decoder is made available at https://orange-opensource.github.io/Cool-Chic/.
PIE: Physics-inspired Low-light Enhancement
Apr 06, 2024In this paper, we propose a physics-inspired contrastive learning paradigm for low-light enhancement, called PIE. PIE primarily addresses three issues: (i) To resolve the problem of existing learning-based methods often training a LLE model with strict pixel-correspondence image pairs, we eliminate the need for pixel-correspondence paired training data and instead train with unpaired images. (ii) To address the disregard for negative samples and the inadequacy of their generation in existing methods, we incorporate physics-inspired contrastive learning for LLE and design the Bag of Curves (BoC) method to generate more reasonable negative samples that closely adhere to the underlying physical imaging principle. (iii) To overcome the reliance on semantic ground truths in existing methods, we propose an unsupervised regional segmentation module, ensuring regional brightness consistency while eliminating the dependency on semantic ground truths. Overall, the proposed PIE can effectively learn from unpaired positive/negative samples and smoothly realize non-semantic regional enhancement, which is clearly different from existing LLE efforts. Besides the novel architecture of PIE, we explore the gain of PIE on downstream tasks such as semantic segmentation and face detection. Training on readily available open data and extensive experiments demonstrate that our method surpasses the state-of-the-art LLE models over six independent cross-scenes datasets. PIE runs fast with reasonable GFLOPs in test time, making it easy to use on mobile devices.
DesignEdit: Multi-Layered Latent Decomposition and Fusion for Unified & Accurate Image Editing
Mar 21, 2024
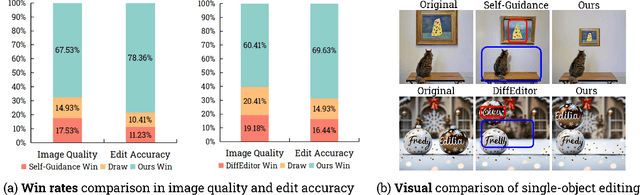

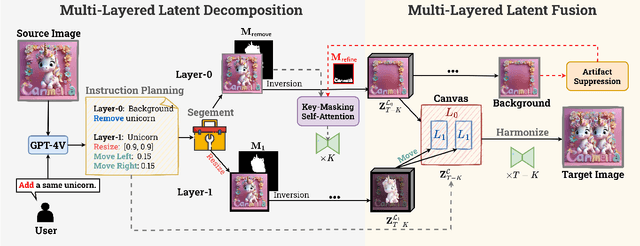
Recently, how to achieve precise image editing has attracted increasing attention, especially given the remarkable success of text-to-image generation models. To unify various spatial-aware image editing abilities into one framework, we adopt the concept of layers from the design domain to manipulate objects flexibly with various operations. The key insight is to transform the spatial-aware image editing task into a combination of two sub-tasks: multi-layered latent decomposition and multi-layered latent fusion. First, we segment the latent representations of the source images into multiple layers, which include several object layers and one incomplete background layer that necessitates reliable inpainting. To avoid extra tuning, we further explore the inner inpainting ability within the self-attention mechanism. We introduce a key-masking self-attention scheme that can propagate the surrounding context information into the masked region while mitigating its impact on the regions outside the mask. Second, we propose an instruction-guided latent fusion that pastes the multi-layered latent representations onto a canvas latent. We also introduce an artifact suppression scheme in the latent space to enhance the inpainting quality. Due to the inherent modular advantages of such multi-layered representations, we can achieve accurate image editing, and we demonstrate that our approach consistently surpasses the latest spatial editing methods, including Self-Guidance and DiffEditor. Last, we show that our approach is a unified framework that supports various accurate image editing tasks on more than six different editing tasks.
Translation-based Video-to-Video Synthesis
Apr 03, 2024Translation-based Video Synthesis (TVS) has emerged as a vital research area in computer vision, aiming to facilitate the transformation of videos between distinct domains while preserving both temporal continuity and underlying content features. This technique has found wide-ranging applications, encompassing video super-resolution, colorization, segmentation, and more, by extending the capabilities of traditional image-to-image translation to the temporal domain. One of the principal challenges faced in TVS is the inherent risk of introducing flickering artifacts and inconsistencies between frames during the synthesis process. This is particularly challenging due to the necessity of ensuring smooth and coherent transitions between video frames. Efforts to tackle this challenge have induced the creation of diverse strategies and algorithms aimed at mitigating these unwanted consequences. This comprehensive review extensively examines the latest progress in the realm of TVS. It thoroughly investigates emerging methodologies, shedding light on the fundamental concepts and mechanisms utilized for proficient video synthesis. This survey also illuminates their inherent strengths, limitations, appropriate applications, and potential avenues for future development.
Dual-modal Prior Semantic Guided Infrared and Visible Image Fusion for Intelligent Transportation System
Mar 24, 2024Infrared and visible image fusion (IVF) plays an important role in intelligent transportation system (ITS). The early works predominantly focus on boosting the visual appeal of the fused result, and only several recent approaches have tried to combine the high-level vision task with IVF. However, they prioritize the design of cascaded structure to seek unified suitable features and fit different tasks. Thus, they tend to typically bias toward to reconstructing raw pixels without considering the significance of semantic features. Therefore, we propose a novel prior semantic guided image fusion method based on the dual-modality strategy, improving the performance of IVF in ITS. Specifically, to explore the independent significant semantic of each modality, we first design two parallel semantic segmentation branches with a refined feature adaptive-modulation (RFaM) mechanism. RFaM can perceive the features that are semantically distinct enough in each semantic segmentation branch. Then, two pilot experiments based on the two branches are conducted to capture the significant prior semantic of two images, which then is applied to guide the fusion task in the integration of semantic segmentation branches and fusion branches. In addition, to aggregate both high-level semantics and impressive visual effects, we further investigate the frequency response of the prior semantics, and propose a multi-level representation-adaptive fusion (MRaF) module to explicitly integrate the low-frequent prior semantic with the high-frequent details. Extensive experiments on two public datasets demonstrate the superiority of our method over the state-of-the-art image fusion approaches, in terms of either the visual appeal or the high-level semantics.