 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Holistic Processing of Colour Images Using Novel Quaternion-Valued Wavelets on the Plane
Aug 31, 2023
We investigate the applicability of quaternion-valued wavelets on the plane to holistic colour image processing. We present a methodology for decomposing and reconstructing colour images using quaternionic wavelet filters associated to recently developed quaternion-valued wavelets on the plane. We consider compression, enhancement, segmentation, and denoising techniques to demonstrate quaternion-valued wavelets as a promising tool for holistic colour image processing.
Ego3DPose: Capturing 3D Cues from Binocular Egocentric Views
Sep 21, 2023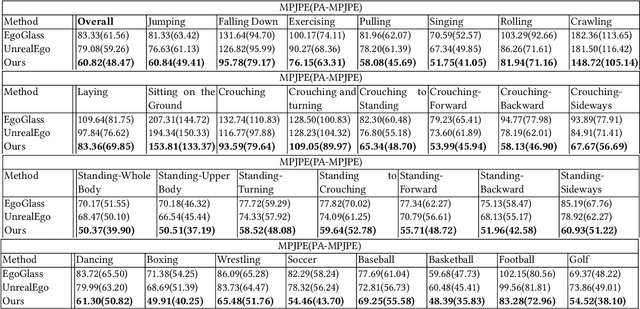
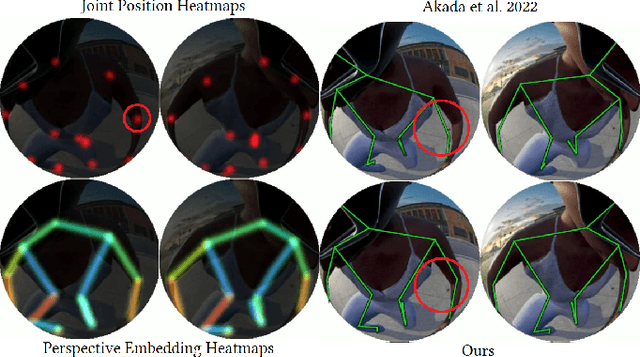
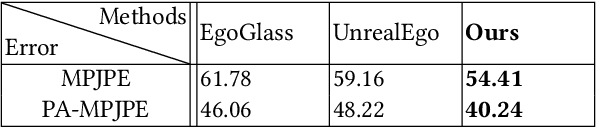
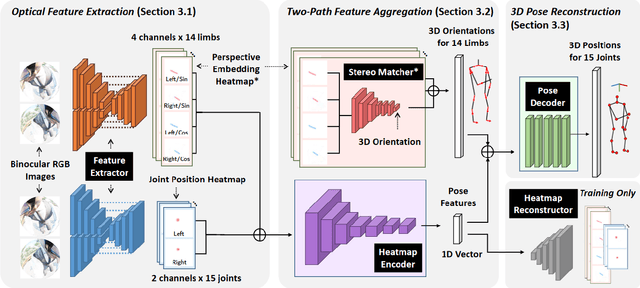
We present Ego3DPose, a highly accurate binocular egocentric 3D pose reconstruction system. The binocular egocentric setup offers practicality and usefulness in various applications, however, it remains largely under-explored. It has been suffering from low pose estimation accuracy due to viewing distortion, severe self-occlusion, and limited field-of-view of the joints in egocentric 2D images. Here, we notice that two important 3D cues, stereo correspondences, and perspective, contained in the egocentric binocular input are neglected. Current methods heavily rely on 2D image features, implicitly learning 3D information, which introduces biases towards commonly observed motions and leads to low overall accuracy. We observe that they not only fail in challenging occlusion cases but also in estimating visible joint positions. To address these challenges, we propose two novel approaches. First, we design a two-path network architecture with a path that estimates pose per limb independently with its binocular heatmaps. Without full-body information provided, it alleviates bias toward trained full-body distribution. Second, we leverage the egocentric view of body limbs, which exhibits strong perspective variance (e.g., a significantly large-size hand when it is close to the camera). We propose a new perspective-aware representation using trigonometry, enabling the network to estimate the 3D orientation of limbs. Finally, we develop an end-to-end pose reconstruction network that synergizes both techniques. Our comprehensive evaluations demonstrate that Ego3DPose outperforms state-of-the-art models by a pose estimation error (i.e., MPJPE) reduction of 23.1% in the UnrealEgo dataset. Our qualitative results highlight the superiority of our approach across a range of scenarios and challenges.
OmnimatteRF: Robust Omnimatte with 3D Background Modeling
Sep 14, 2023
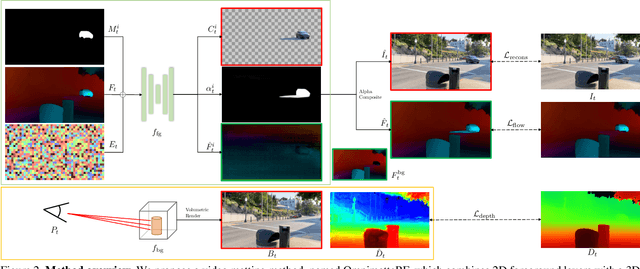

Video matting has broad applications, from adding interesting effects to casually captured movies to assisting video production professionals. Matting with associated effects such as shadows and reflections has also attracted increasing research activity, and methods like Omnimatte have been proposed to separate dynamic foreground objects of interest into their own layers. However, prior works represent video backgrounds as 2D image layers, limiting their capacity to express more complicated scenes, thus hindering application to real-world videos. In this paper, we propose a novel video matting method, OmnimatteRF, that combines dynamic 2D foreground layers and a 3D background model. The 2D layers preserve the details of the subjects, while the 3D background robustly reconstructs scenes in real-world videos. Extensive experiments demonstrate that our method reconstructs scenes with better quality on various videos.
Self-Supervised Super-Resolution Approach for Isotropic Reconstruction of 3D Electron Microscopy Images from Anisotropic Acquisition
Sep 19, 2023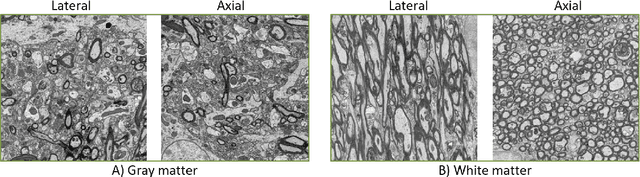
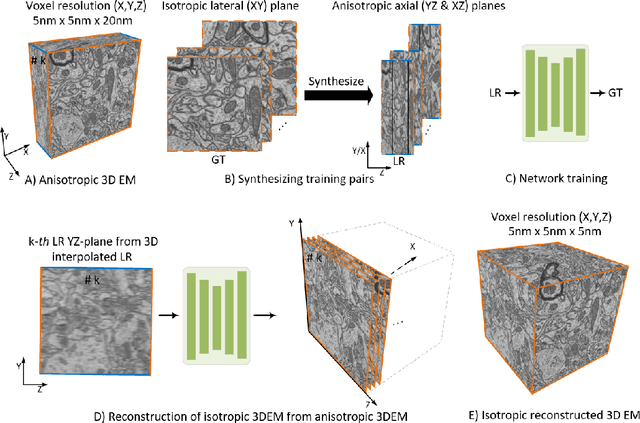
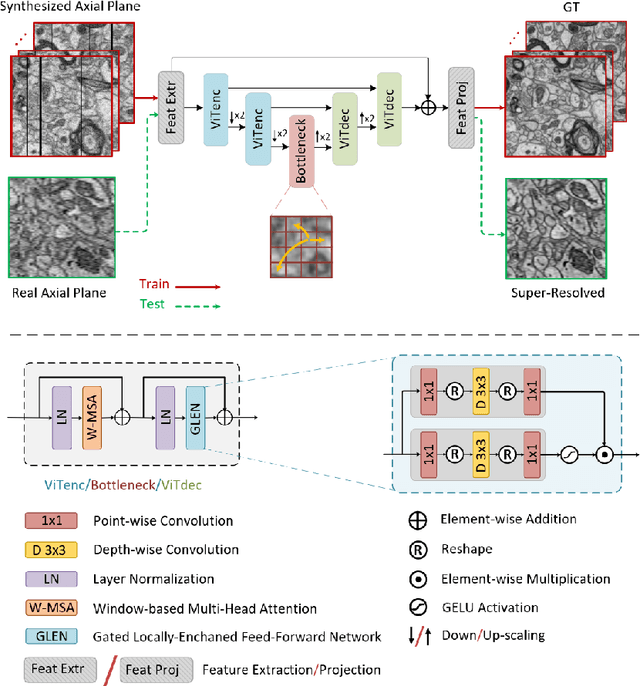

Three-dimensional electron microscopy (3DEM) is an essential technique to investigate volumetric tissue ultra-structure. Due to technical limitations and high imaging costs, samples are often imaged anisotropically, where resolution in the axial direction ($z$) is lower than in the lateral directions $(x,y)$. This anisotropy 3DEM can hamper subsequent analysis and visualization tasks. To overcome this limitation, we propose a novel deep-learning (DL)-based self-supervised super-resolution approach that computationally reconstructs isotropic 3DEM from the anisotropic acquisition. The proposed DL-based framework is built upon the U-shape architecture incorporating vision-transformer (ViT) blocks, enabling high-capability learning of local and global multi-scale image dependencies. To train the tailored network, we employ a self-supervised approach. Specifically, we generate pairs of anisotropic and isotropic training datasets from the given anisotropic 3DEM data. By feeding the given anisotropic 3DEM dataset in the trained network through our proposed framework, the isotropic 3DEM is obtained. Importantly, this isotropic reconstruction approach relies solely on the given anisotropic 3DEM dataset and does not require pairs of co-registered anisotropic and isotropic 3DEM training datasets. To evaluate the effectiveness of the proposed method, we conducted experiments using three 3DEM datasets acquired from brain. The experimental results demonstrated that our proposed framework could successfully reconstruct isotropic 3DEM from the anisotropic acquisition.
CoVR: Learning Composed Video Retrieval from Web Video Captions
Aug 28, 2023
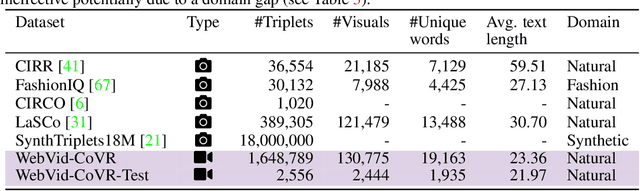
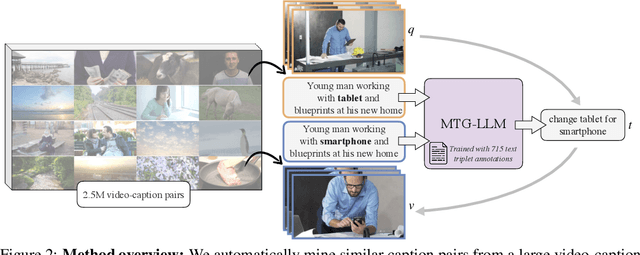
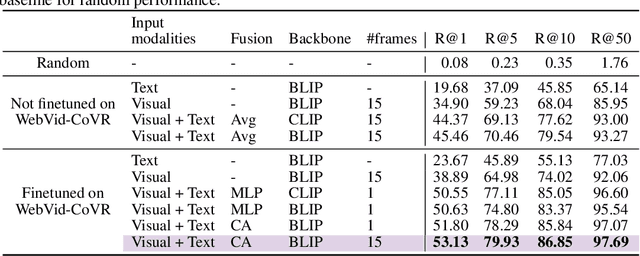
Composed Image Retrieval (CoIR) has recently gained popularity as a task that considers both text and image queries together, to search for relevant images in a database. Most CoIR approaches require manually annotated datasets, comprising image-text-image triplets, where the text describes a modification from the query image to the target image. However, manual curation of CoIR triplets is expensive and prevents scalability. In this work, we instead propose a scalable automatic dataset creation methodology that generates triplets given video-caption pairs, while also expanding the scope of the task to include composed video retrieval (CoVR). To this end, we mine paired videos with a similar caption from a large database, and leverage a large language model to generate the corresponding modification text. Applying this methodology to the extensive WebVid2M collection, we automatically construct our WebVid-CoVR dataset, resulting in 1.6 million triplets. Moreover, we introduce a new benchmark for CoVR with a manually annotated evaluation set, along with baseline results. Our experiments further demonstrate that training a CoVR model on our dataset effectively transfers to CoIR, leading to improved state-of-the-art performance in the zero-shot setup on both the CIRR and FashionIQ benchmarks. Our code, datasets, and models are publicly available at https://imagine.enpc.fr/~ventural/covr.
Discovering Image Usage Online: A Case Study With "Flatten the Curve''
Jul 12, 2023Understanding the spread of images across the web helps us understand the reuse of scientific visualizations and their relationship with the public. The "Flatten the Curve" graphic was heavily used during the COVID-19 pandemic to convey a complex concept in a simple form. It displays two curves comparing the impact on case loads for medical facilities if the populace either adopts or fails to adopt protective measures during a pandemic. We use five variants of the "Flatten the Curve" image as a case study for viewing the spread of an image online. To evaluate its spread, we leverage three information channels: reverse image search engines, social media, and web archives. Reverse image searches give us a current view into image reuse. Social media helps us understand a variant's popularity over time. Web archives help us see when it was preserved, highlighting a view of popularity for future researchers. Our case study leverages document URLs can be used as a proxy for images when studying the spread of images online.
Strong-Weak Integrated Semi-supervision for Unsupervised Single and Multi Target Domain Adaptation
Sep 12, 2023Unsupervised domain adaptation (UDA) focuses on transferring knowledge learned in the labeled source domain to the unlabeled target domain. Despite significant progress that has been achieved in single-target domain adaptation for image classification in recent years, the extension from single-target to multi-target domain adaptation is still a largely unexplored problem area. In general, unsupervised domain adaptation faces a major challenge when attempting to learn reliable information from a single unlabeled target domain. Increasing the number of unlabeled target domains further exacerbate the problem rather significantly. In this paper, we propose a novel strong-weak integrated semi-supervision (SWISS) learning strategy for image classification using unsupervised domain adaptation that works well for both single-target and multi-target scenarios. Under the proposed SWISS-UDA framework, a strong representative set with high confidence but low diversity target domain samples and a weak representative set with low confidence but high diversity target domain samples are updated constantly during the training process. Both sets are fused to generate an augmented strong-weak training batch with pseudo-labels to train the network during every iteration. The extension from single-target to multi-target domain adaptation is accomplished by exploring the class-wise distance relationship between domains and replacing the strong representative set with much stronger samples from peer domains via peer scaffolding. Moreover, a novel adversarial logit loss is proposed to reduce the intra-class divergence between source and target domains, which is back-propagated adversarially with a gradient reverse layer between the classifier and the rest of the network. Experimental results based on three benchmarks, Office-31, Office-Home, and DomainNet, show the effectiveness of the proposed SWISS framework.
Towards Top-Down Stereoscopic Image Quality Assessment via Stereo Attention
Aug 08, 2023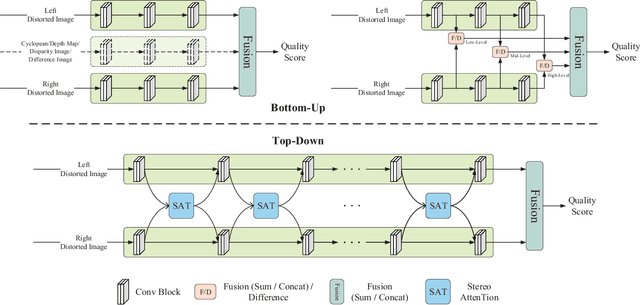
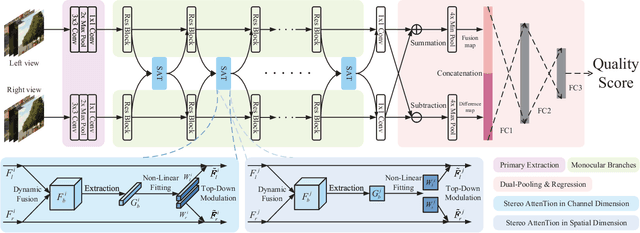
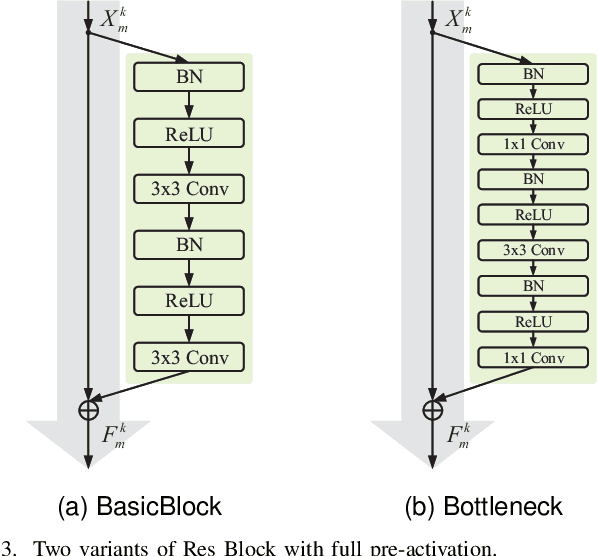
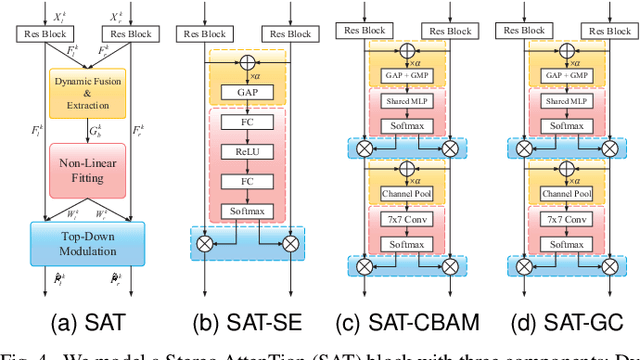
Stereoscopic image quality assessment (SIQA) plays a crucial role in evaluating and improving the visual experience of 3D content. Existing binocular properties and attention-based methods for SIQA have achieved promising performance. However, these bottom-up approaches are inadequate in exploiting the inherent characteristics of the human visual system (HVS). This paper presents a novel network for SIQA via stereo attention, employing a top-down perspective to guide the quality assessment process. Our proposed method realizes the guidance from high-level binocular signals down to low-level monocular signals, while the binocular and monocular information can be calibrated progressively throughout the processing pipeline. We design a generalized Stereo AttenTion (SAT) block to implement the top-down philosophy in stereo perception. This block utilizes the fusion-generated attention map as a high-level binocular modulator, influencing the representation of two low-level monocular features. Additionally, we introduce an Energy Coefficient (EC) to account for recent findings indicating that binocular responses in the primate primary visual cortex are less than the sum of monocular responses. The adaptive EC can tune the magnitude of binocular response flexibly, thus enhancing the formation of robust binocular features within our framework. To extract the most discriminative quality information from the summation and subtraction of the two branches of monocular features, we utilize a dual-pooling strategy that applies min-pooling and max-pooling operations to the respective branches. Experimental results highlight the superiority of our top-down method in simulating the property of visual perception and advancing the state-of-the-art in the SIQA field. The code of this work is available at https://github.com/Fanning-Zhang/SATNet.
AIGC for Various Data Modalities: A Survey
Sep 09, 2023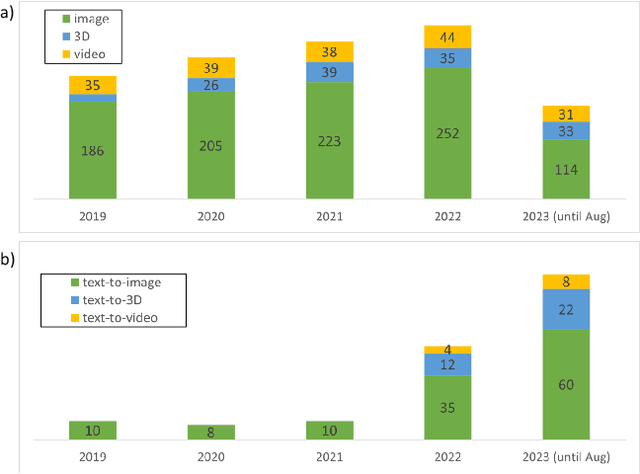
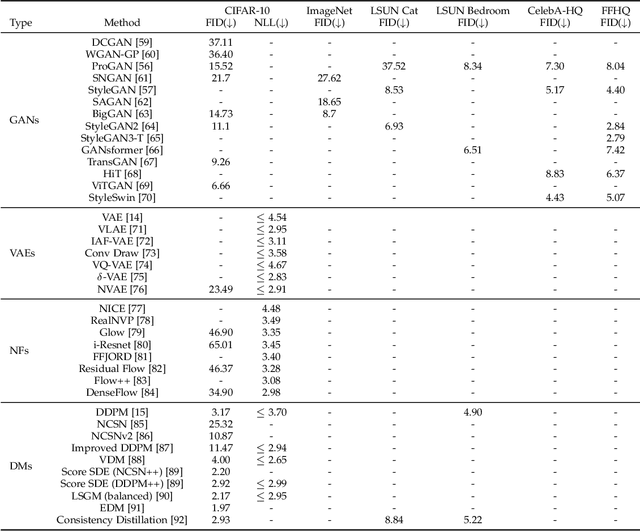
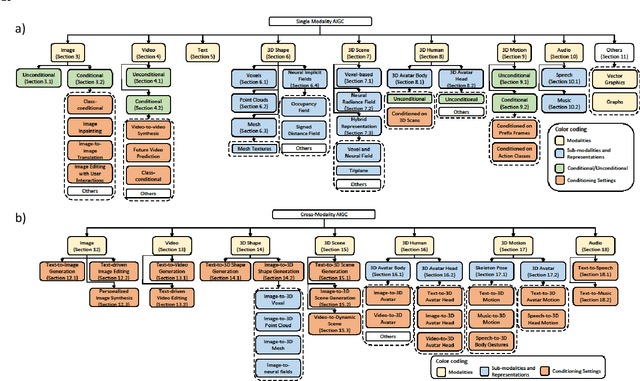
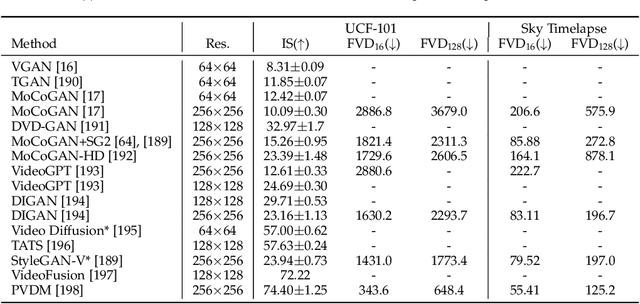
AI-generated content (AIGC) methods aim to produce text, images, videos, 3D assets, and other media using AI algorithms. Due to its wide range of applications and the demonstrated potential of recent works, AIGC developments have been attracting lots of attention recently, and AIGC methods have been developed for various data modalities, such as image, video, text, 3D shape (as voxels, point clouds, meshes, and neural implicit fields), 3D scene, 3D human avatar (body and head), 3D motion, and audio -- each presenting different characteristics and challenges. Furthermore, there have also been many significant developments in cross-modality AIGC methods, where generative methods can receive conditioning input in one modality and produce outputs in another. Examples include going from various modalities to image, video, 3D shape, 3D scene, 3D avatar (body and head), 3D motion (skeleton and avatar), and audio modalities. In this paper, we provide a comprehensive review of AIGC methods across different data modalities, including both single-modality and cross-modality methods, highlighting the various challenges, representative works, and recent technical directions in each setting. We also survey the representative datasets throughout the modalities, and present comparative results for various modalities. Moreover, we also discuss the challenges and potential future research directions.
Diffusion on the Probability Simplex
Sep 12, 2023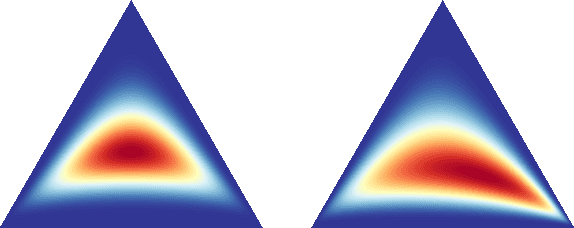
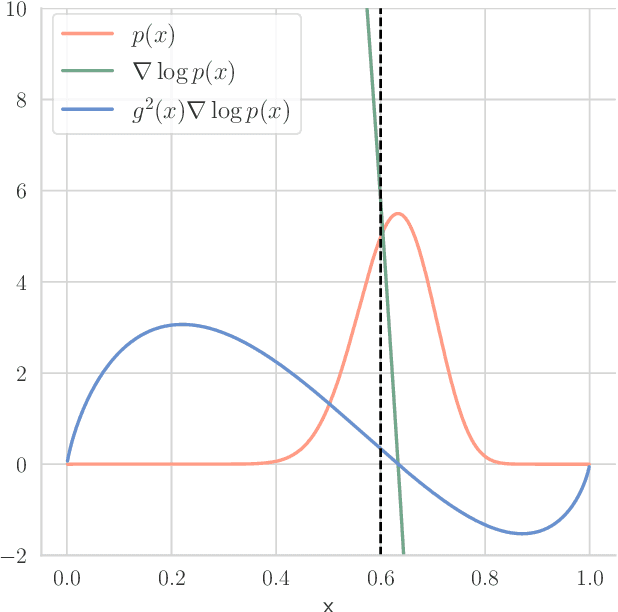

Diffusion models learn to reverse the progressive noising of a data distribution to create a generative model. However, the desired continuous nature of the noising process can be at odds with discrete data. To deal with this tension between continuous and discrete objects, we propose a method of performing diffusion on the probability simplex. Using the probability simplex naturally creates an interpretation where points correspond to categorical probability distributions. Our method uses the softmax function applied to an Ornstein-Unlenbeck Process, a well-known stochastic differential equation. We find that our methodology also naturally extends to include diffusion on the unit cube which has applications for bounded image generation.