 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeeDiff: Dynamic Uncertainty-Aware Early Exiting for Accelerating Diffusion Model Generation
Sep 29, 2023
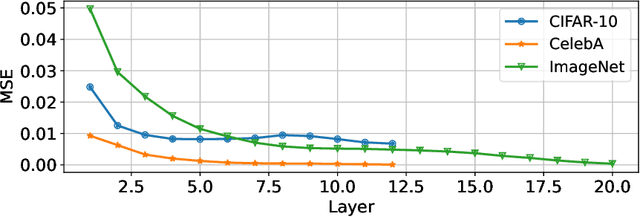
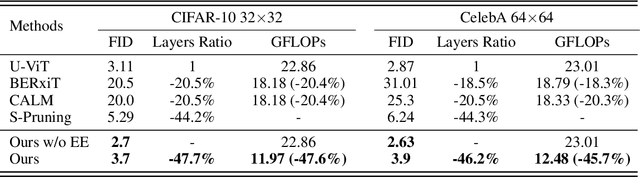
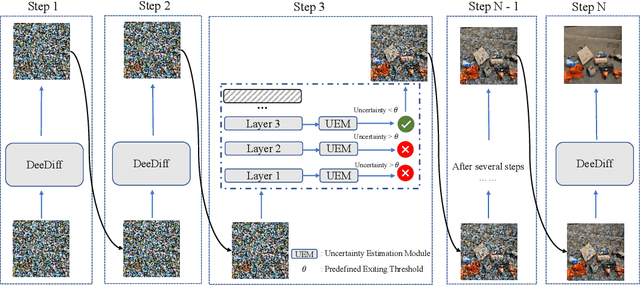
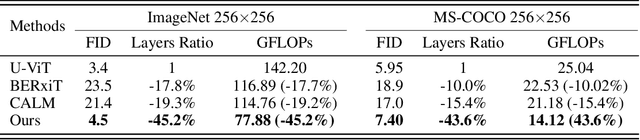
Diffusion models achieve great success in generating diverse and high-fidelity images. The performance improvements come with low generation speed per image, which hinders the application diffusion models in real-time scenarios. While some certain predictions benefit from the full computation of the model in each sample iteration, not every iteration requires the same amount of computation, potentially leading to computation waste. In this work, we propose DeeDiff, an early exiting framework that adaptively allocates computation resources in each sampling step to improve the generation efficiency of diffusion models. Specifically, we introduce a timestep-aware uncertainty estimation module (UEM) for diffusion models which is attached to each intermediate layer to estimate the prediction uncertainty of each layer. The uncertainty is regarded as the signal to decide if the inference terminates. Moreover, we propose uncertainty-aware layer-wise loss to fill the performance gap between full models and early-exited models. With such loss strategy, our model is able to obtain comparable results as full-layer models. Extensive experiments of class-conditional, unconditional, and text-guided generation on several datasets show that our method achieves state-of-the-art performance and efficiency trade-off compared with existing early exiting methods on diffusion models. More importantly, our method even brings extra benefits to baseline models and obtains better performance on CIFAR-10 and Celeb-A datasets. Full code and model are released for reproduction.
Segment Anything Model is a Good Teacher for Local Feature Learning
Sep 29, 2023Local feature detection and description play an important role in many computer vision tasks, which are designed to detect and describe keypoints in "any scene" and "any downstream task". Data-driven local feature learning methods need to rely on pixel-level correspondence for training, which is challenging to acquire at scale, thus hindering further improvements in performance. In this paper, we propose SAMFeat to introduce SAM (segment anything model), a fundamental model trained on 11 million images, as a teacher to guide local feature learning and thus inspire higher performance on limited datasets. To do so, first, we construct an auxiliary task of Pixel Semantic Relational Distillation (PSRD), which distillates feature relations with category-agnostic semantic information learned by the SAM encoder into a local feature learning network, to improve local feature description using semantic discrimination. Second, we develop a technique called Weakly Supervised Contrastive Learning Based on Semantic Grouping (WSC), which utilizes semantic groupings derived from SAM as weakly supervised signals, to optimize the metric space of local descriptors. Third, we design an Edge Attention Guidance (EAG) to further improve the accuracy of local feature detection and description by prompting the network to pay more attention to the edge region guided by SAM. SAMFeat's performance on various tasks such as image matching on HPatches, and long-term visual localization on Aachen Day-Night showcases its superiority over previous local features. The release code is available at https://github.com/vignywang/SAMFeat.
SCoRe: Submodular Combinatorial Representation Learning for Real-World Class-Imbalanced Settings
Sep 29, 2023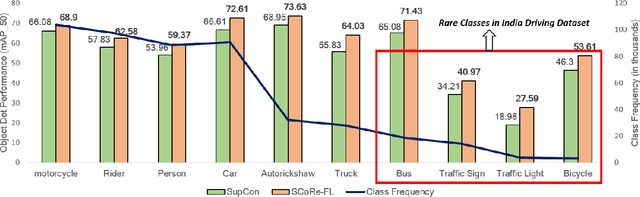
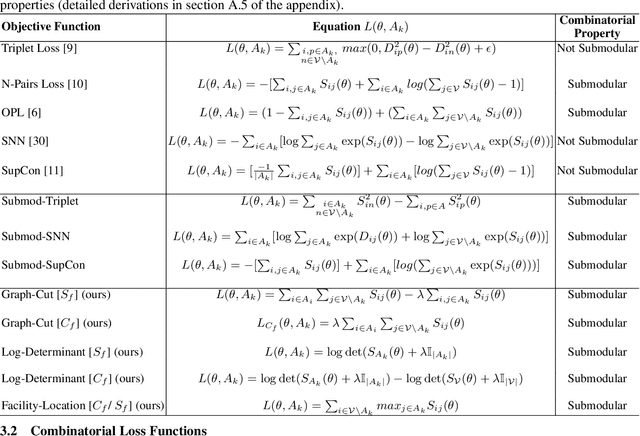
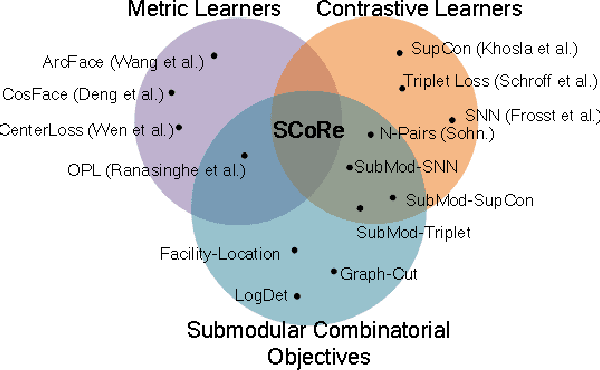
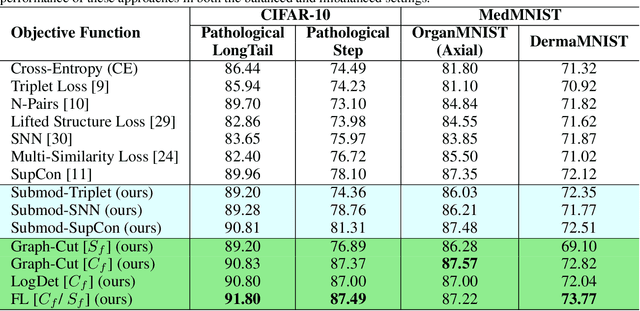
Representation Learning in real-world class-imbalanced settings has emerged as a challenging task in the evolution of deep learning. Lack of diversity in visual and structural features for rare classes restricts modern neural networks to learn discriminative feature clusters. This manifests in the form of large inter-class bias between rare object classes and elevated intra-class variance among abundant classes in the dataset. Although deep metric learning approaches have shown promise in this domain, significant improvements need to be made to overcome the challenges associated with class-imbalance in mission critical tasks like autonomous navigation and medical diagnostics. Set-based combinatorial functions like Submodular Information Measures exhibit properties that allow them to simultaneously model diversity and cooperation among feature clusters. In this paper, we introduce the SCoRe (Submodular Combinatorial Representation Learning) framework and propose a family of Submodular Combinatorial Loss functions to overcome these pitfalls in contrastive learning. We also show that existing contrastive learning approaches are either submodular or can be re-formulated to create their submodular counterparts. We conduct experiments on the newly introduced family of combinatorial objectives on two image classification benchmarks - pathologically imbalanced CIFAR-10, subsets of MedMNIST and a real-world road object detection benchmark - India Driving Dataset (IDD). Our experiments clearly show that the newly introduced objectives like Facility Location, Graph-Cut and Log Determinant outperform state-of-the-art metric learners by up to 7.6% for the imbalanced classification tasks and up to 19.4% for object detection tasks.
Feedback-guided Data Synthesis for Imbalanced Classification
Sep 29, 2023Current status quo in machine learning is to use static datasets of real images for training, which often come from long-tailed distributions. With the recent advances in generative models, researchers have started augmenting these static datasets with synthetic data, reporting moderate performance improvements on classification tasks. We hypothesize that these performance gains are limited by the lack of feedback from the classifier to the generative model, which would promote the usefulness of the generated samples to improve the classifier's performance. In this work, we introduce a framework for augmenting static datasets with useful synthetic samples, which leverages one-shot feedback from the classifier to drive the sampling of the generative model. In order for the framework to be effective, we find that the samples must be close to the support of the real data of the task at hand, and be sufficiently diverse. We validate three feedback criteria on a long-tailed dataset (ImageNet-LT) as well as a group-imbalanced dataset (NICO++). On ImageNet-LT, we achieve state-of-the-art results, with over 4 percent improvement on underrepresented classes while being twice efficient in terms of the number of generated synthetic samples. NICO++ also enjoys marked boosts of over 5 percent in worst group accuracy. With these results, our framework paves the path towards effectively leveraging state-of-the-art text-to-image models as data sources that can be queried to improve downstream applications.
Context-Aware 3D Object Localization from Single Calibrated Images: A Study of Basketballs
Sep 07, 2023
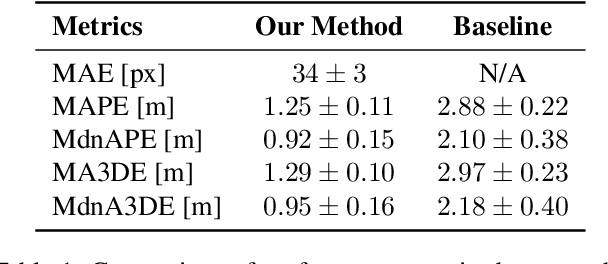

Accurately localizing objects in three dimensions (3D) is crucial for various computer vision applications, such as robotics, autonomous driving, and augmented reality. This task finds another important application in sports analytics and, in this work, we present a novel method for 3D basketball localization from a single calibrated image. Our approach predicts the object's height in pixels in image space by estimating its projection onto the ground plane within the image, leveraging the image itself and the object's location as inputs. The 3D coordinates of the ball are then reconstructed by exploiting the known projection matrix. Extensive experiments on the public DeepSport dataset, which provides ground truth annotations for 3D ball location alongside camera calibration information for each image, demonstrate the effectiveness of our method, offering substantial accuracy improvements compared to recent work. Our work opens up new possibilities for enhanced ball tracking and understanding, advancing computer vision in diverse domains. The source code of this work is made publicly available at \url{https://github.com/gabriel-vanzandycke/deepsport}.
Towards Content-based Pixel Retrieval in Revisited Oxford and Paris
Sep 11, 2023
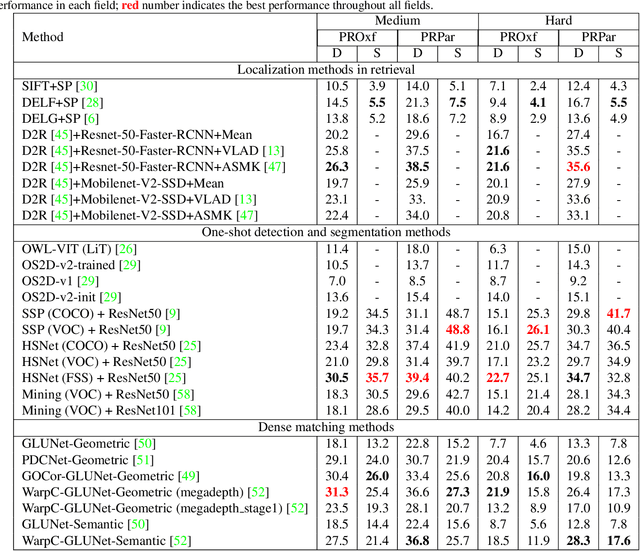
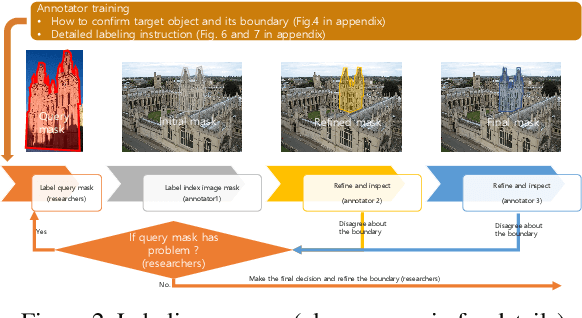
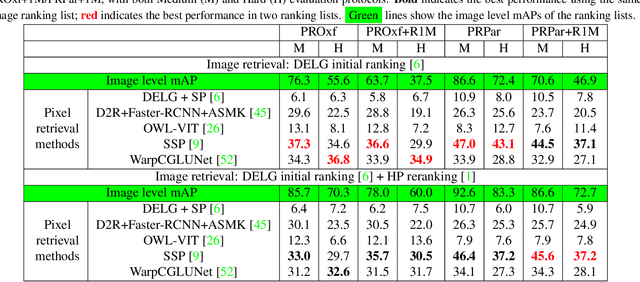
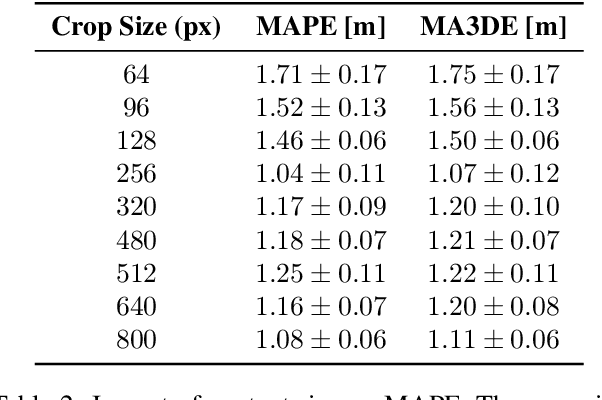
This paper introduces the first two pixel retrieval benchmarks. Pixel retrieval is segmented instance retrieval. Like semantic segmentation extends classification to the pixel level, pixel retrieval is an extension of image retrieval and offers information about which pixels are related to the query object. In addition to retrieving images for the given query, it helps users quickly identify the query object in true positive images and exclude false positive images by denoting the correlated pixels. Our user study results show pixel-level annotation can significantly improve the user experience. Compared with semantic and instance segmentation, pixel retrieval requires a fine-grained recognition capability for variable-granularity targets. To this end, we propose pixel retrieval benchmarks named PROxford and PRParis, which are based on the widely used image retrieval datasets, ROxford and RParis. Three professional annotators label 5,942 images with two rounds of double-checking and refinement. Furthermore, we conduct extensive experiments and analysis on the SOTA methods in image search, image matching, detection, segmentation, and dense matching using our pixel retrieval benchmarks. Results show that the pixel retrieval task is challenging to these approaches and distinctive from existing problems, suggesting that further research can advance the content-based pixel-retrieval and thus user search experience. The datasets can be downloaded from \href{https://github.com/anguoyuan/Pixel_retrieval-Segmented_instance_retrieval}{this link}.
Understanding Pose and Appearance Disentanglement in 3D Human Pose Estimation
Sep 20, 2023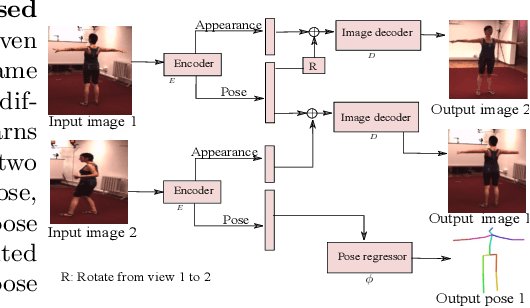


As 3D human pose estimation can now be achieved with very high accuracy in the supervised learning scenario, tackling the case where 3D pose annotations are not available has received increasing attention. In particular, several methods have proposed to learn image representations in a self-supervised fashion so as to disentangle the appearance information from the pose one. The methods then only need a small amount of supervised data to train a pose regressor using the pose-related latent vector as input, as it should be free of appearance information. In this paper, we carry out in-depth analysis to understand to what degree the state-of-the-art disentangled representation learning methods truly separate the appearance information from the pose one. First, we study disentanglement from the perspective of the self-supervised network, via diverse image synthesis experiments. Second, we investigate disentanglement with respect to the 3D pose regressor following an adversarial attack perspective. Specifically, we design an adversarial strategy focusing on generating natural appearance changes of the subject, and against which we could expect a disentangled network to be robust. Altogether, our analyses show that disentanglement in the three state-of-the-art disentangled representation learning frameworks if far from complete, and that their pose codes contain significant appearance information. We believe that our approach provides a valuable testbed to evaluate the degree of disentanglement of pose from appearance in self-supervised 3D human pose estimation.
How to turn your camera into a perfect pinhole model
Sep 20, 2023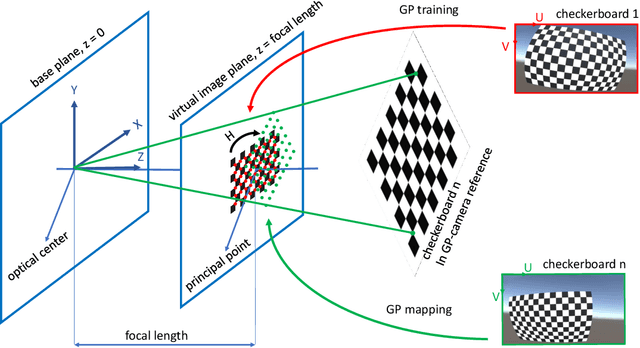
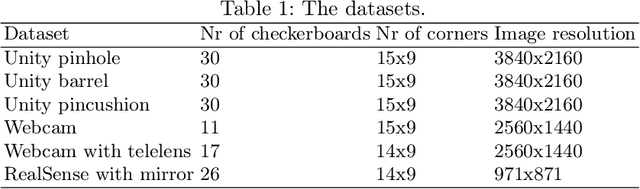

Camera calibration is a first and fundamental step in various computer vision applications. Despite being an active field of research, Zhang's method remains widely used for camera calibration due to its implementation in popular toolboxes. However, this method initially assumes a pinhole model with oversimplified distortion models. In this work, we propose a novel approach that involves a pre-processing step to remove distortions from images by means of Gaussian processes. Our method does not need to assume any distortion model and can be applied to severely warped images, even in the case of multiple distortion sources, e.g., a fisheye image of a curved mirror reflection. The Gaussian processes capture all distortions and camera imperfections, resulting in virtual images as though taken by an ideal pinhole camera with square pixels. Furthermore, this ideal GP-camera only needs one image of a square grid calibration pattern. This model allows for a serious upgrade of many algorithms and applications that are designed in a pure projective geometry setting but with a performance that is very sensitive to nonlinear lens distortions. We demonstrate the effectiveness of our method by simplifying Zhang's calibration method, reducing the number of parameters and getting rid of the distortion parameters and iterative optimization. We validate by means of synthetic data and real world images. The contributions of this work include the construction of a virtual ideal pinhole camera using Gaussian processes, a simplified calibration method and lens distortion removal.
Hybrid quantum transfer learning for crack image classification on NISQ hardware
Jul 31, 2023


Quantum computers possess the potential to process data using a remarkably reduced number of qubits compared to conventional bits, as per theoretical foundations. However, recent experiments have indicated that the practical feasibility of retrieving an image from its quantum encoded version is currently limited to very small image sizes. Despite this constraint, variational quantum machine learning algorithms can still be employed in the current noisy intermediate scale quantum (NISQ) era. An example is a hybrid quantum machine learning approach for edge detection. In our study, we present an application of quantum transfer learning for detecting cracks in gray value images. We compare the performance and training time of PennyLane's standard qubits with IBM's qasm\_simulator and real backends, offering insights into their execution efficiency.
Physics-Aware Semi-Supervised Underwater Image Enhancement
Jul 21, 2023
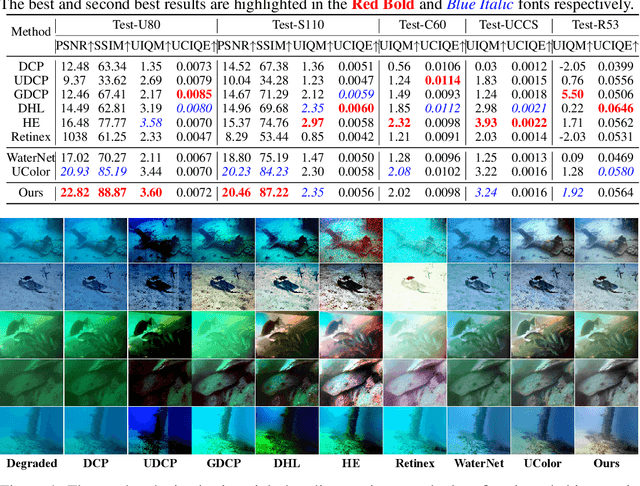
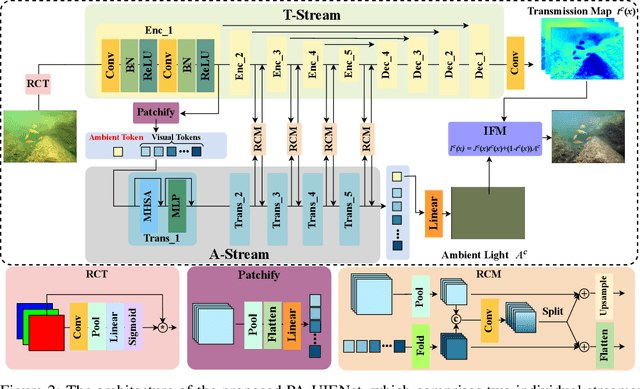
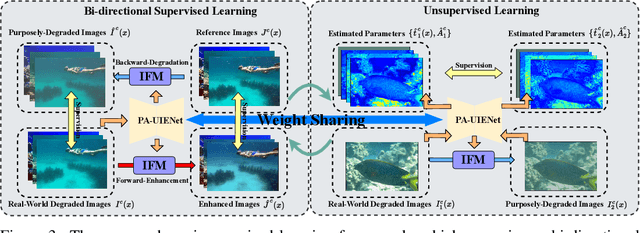
Underwater images normally suffer from degradation due to the transmission medium of water bodies. Both traditional prior-based approaches and deep learning-based methods have been used to address this problem. However, the inflexible assumption of the former often impairs their effectiveness in handling diverse underwater scenes, while the generalization of the latter to unseen images is usually weakened by insufficient data. In this study, we leverage both the physics-based underwater Image Formation Model (IFM) and deep learning techniques for Underwater Image Enhancement (UIE). To this end, we propose a novel Physics-Aware Dual-Stream Underwater Image Enhancement Network, i.e., PA-UIENet, which comprises a Transmission Estimation Steam (T-Stream) and an Ambient Light Estimation Stream (A-Stream). This network fulfills the UIE task by explicitly estimating the degradation parameters of the IFM. We also adopt an IFM-inspired semi-supervised learning framework, which exploits both the labeled and unlabeled images, to address the issue of insufficient data. Our method performs better than, or at least comparably to, eight baselines across five testing sets in the degradation estimation and UIE tasks. This should be due to the fact that it not only can model the degradation but also can learn the characteristics of diverse underwater scenes.