 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Coco-Nut: Corpus of Japanese Utterance and Voice Characteristics Description for Prompt-based Control
Sep 24, 2023

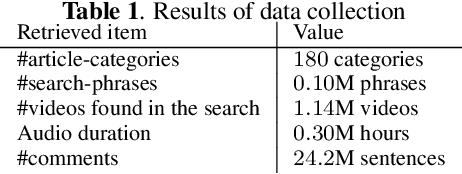
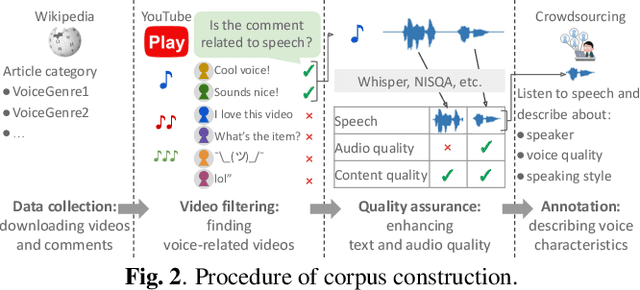

In text-to-speech, controlling voice characteristics is important in achieving various-purpose speech synthesis. Considering the success of text-conditioned generation, such as text-to-image, free-form text instruction should be useful for intuitive and complicated control of voice characteristics. A sufficiently large corpus of high-quality and diverse voice samples with corresponding free-form descriptions can advance such control research. However, neither an open corpus nor a scalable method is currently available. To this end, we develop Coco-Nut, a new corpus including diverse Japanese utterances, along with text transcriptions and free-form voice characteristics descriptions. Our methodology to construct this corpus consists of 1) automatic collection of voice-related audio data from the Internet, 2) quality assurance, and 3) manual annotation using crowdsourcing. Additionally, we benchmark our corpus on the prompt embedding model trained by contrastive speech-text learning.
Exploiting CLIP-based Multi-modal Approach for Artwork Classification and Retrieval
Sep 21, 2023Given the recent advances in multimodal image pretraining where visual models trained with semantically dense textual supervision tend to have better generalization capabilities than those trained using categorical attributes or through unsupervised techniques, in this work we investigate how recent CLIP model can be applied in several tasks in artwork domain. We perform exhaustive experiments on the NoisyArt dataset which is a dataset of artwork images crawled from public resources on the web. On such dataset CLIP achieves impressive results on (zero-shot) classification and promising results in both artwork-to-artwork and description-to-artwork domain.
Unsupervised 3D Perception with 2D Vision-Language Distillation for Autonomous Driving
Sep 25, 2023Closed-set 3D perception models trained on only a pre-defined set of object categories can be inadequate for safety critical applications such as autonomous driving where new object types can be encountered after deployment. In this paper, we present a multi-modal auto labeling pipeline capable of generating amodal 3D bounding boxes and tracklets for training models on open-set categories without 3D human labels. Our pipeline exploits motion cues inherent in point cloud sequences in combination with the freely available 2D image-text pairs to identify and track all traffic participants. Compared to the recent studies in this domain, which can only provide class-agnostic auto labels limited to moving objects, our method can handle both static and moving objects in the unsupervised manner and is able to output open-vocabulary semantic labels thanks to the proposed vision-language knowledge distillation. Experiments on the Waymo Open Dataset show that our approach outperforms the prior work by significant margins on various unsupervised 3D perception tasks.
Development of a Deep Learning Method to Identify Acute Ischemic Stroke Lesions on Brain CT
Sep 29, 2023
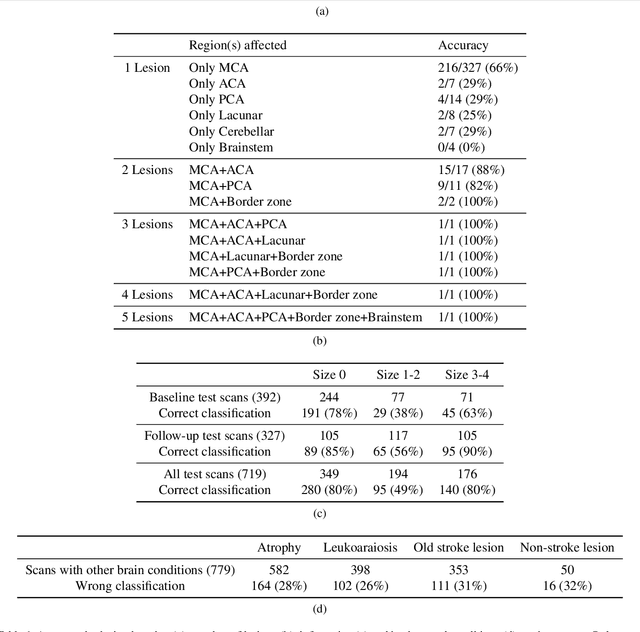
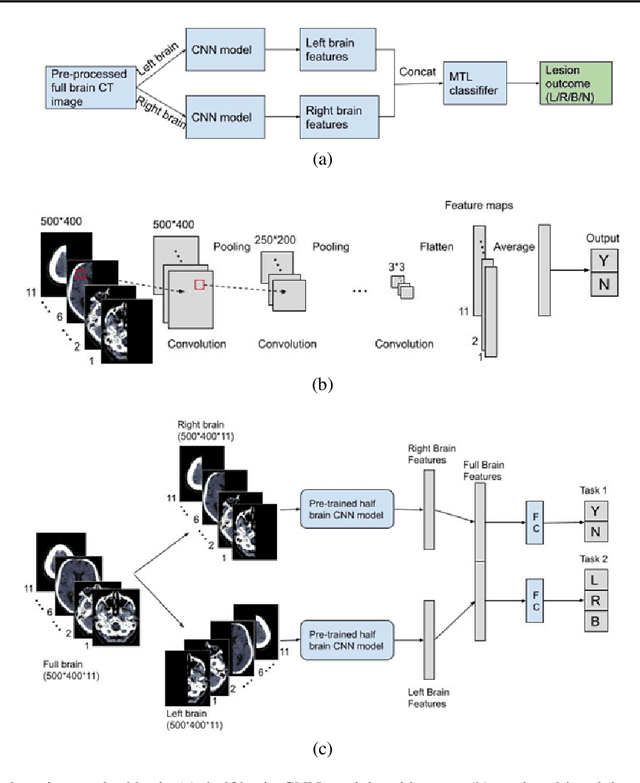
Computed Tomography (CT) is commonly used to image acute ischemic stroke (AIS) patients, but its interpretation by radiologists is time-consuming and subject to inter-observer variability. Deep learning (DL) techniques can provide automated CT brain scan assessment, but usually require annotated images. Aiming to develop a DL method for AIS using labelled but not annotated CT brain scans from patients with AIS, we designed a convolutional neural network-based DL algorithm using routinely-collected CT brain scans from the Third International Stroke Trial (IST-3), which were not acquired using strict research protocols. The DL model aimed to detect AIS lesions and classify the side of the brain affected. We explored the impact of AIS lesion features, background brain appearances, and timing on DL performance. From 5772 unique CT scans of 2347 AIS patients (median age 82), 54% had visible AIS lesions according to expert labelling. Our best-performing DL method achieved 72% accuracy for lesion presence and side. Lesions that were larger (80% accuracy) or multiple (87% accuracy for two lesions, 100% for three or more), were better detected. Follow-up scans had 76% accuracy, while baseline scans 67% accuracy. Chronic brain conditions reduced accuracy, particularly non-stroke lesions and old stroke lesions (32% and 31% error rates respectively). DL methods can be designed for AIS lesion detection on CT using the vast quantities of routinely-collected CT brain scan data. Ultimately, this should lead to more robust and widely-applicable methods.
DeeDiff: Dynamic Uncertainty-Aware Early Exiting for Accelerating Diffusion Model Generation
Sep 29, 2023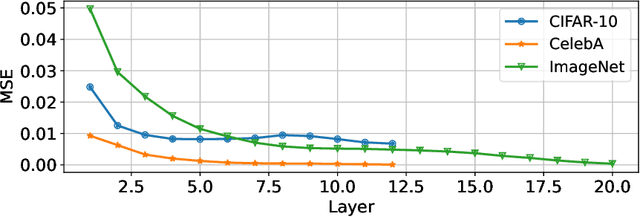
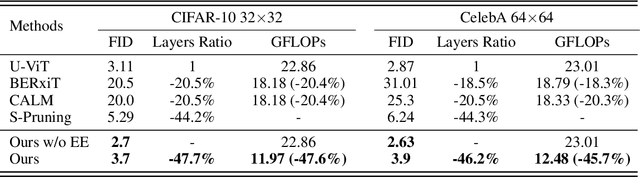
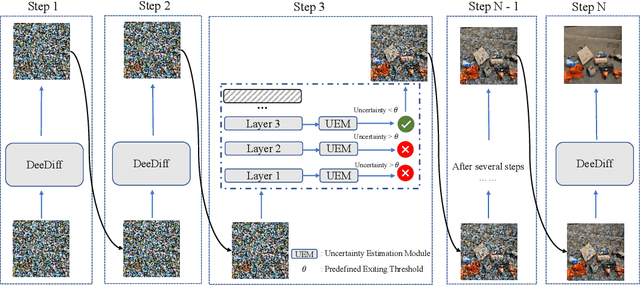
Diffusion models achieve great success in generating diverse and high-fidelity images. The performance improvements come with low generation speed per image, which hinders the application diffusion models in real-time scenarios. While some certain predictions benefit from the full computation of the model in each sample iteration, not every iteration requires the same amount of computation, potentially leading to computation waste. In this work, we propose DeeDiff, an early exiting framework that adaptively allocates computation resources in each sampling step to improve the generation efficiency of diffusion models. Specifically, we introduce a timestep-aware uncertainty estimation module (UEM) for diffusion models which is attached to each intermediate layer to estimate the prediction uncertainty of each layer. The uncertainty is regarded as the signal to decide if the inference terminates. Moreover, we propose uncertainty-aware layer-wise loss to fill the performance gap between full models and early-exited models. With such loss strategy, our model is able to obtain comparable results as full-layer models. Extensive experiments of class-conditional, unconditional, and text-guided generation on several datasets show that our method achieves state-of-the-art performance and efficiency trade-off compared with existing early exiting methods on diffusion models. More importantly, our method even brings extra benefits to baseline models and obtains better performance on CIFAR-10 and Celeb-A datasets. Full code and model are released for reproduction.
Segment Anything Model is a Good Teacher for Local Feature Learning
Sep 29, 2023Local feature detection and description play an important role in many computer vision tasks, which are designed to detect and describe keypoints in "any scene" and "any downstream task". Data-driven local feature learning methods need to rely on pixel-level correspondence for training, which is challenging to acquire at scale, thus hindering further improvements in performance. In this paper, we propose SAMFeat to introduce SAM (segment anything model), a fundamental model trained on 11 million images, as a teacher to guide local feature learning and thus inspire higher performance on limited datasets. To do so, first, we construct an auxiliary task of Pixel Semantic Relational Distillation (PSRD), which distillates feature relations with category-agnostic semantic information learned by the SAM encoder into a local feature learning network, to improve local feature description using semantic discrimination. Second, we develop a technique called Weakly Supervised Contrastive Learning Based on Semantic Grouping (WSC), which utilizes semantic groupings derived from SAM as weakly supervised signals, to optimize the metric space of local descriptors. Third, we design an Edge Attention Guidance (EAG) to further improve the accuracy of local feature detection and description by prompting the network to pay more attention to the edge region guided by SAM. SAMFeat's performance on various tasks such as image matching on HPatches, and long-term visual localization on Aachen Day-Night showcases its superiority over previous local features. The release code is available at https://github.com/vignywang/SAMFeat.
SCoRe: Submodular Combinatorial Representation Learning for Real-World Class-Imbalanced Settings
Sep 29, 2023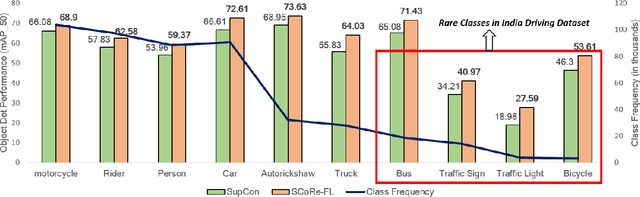
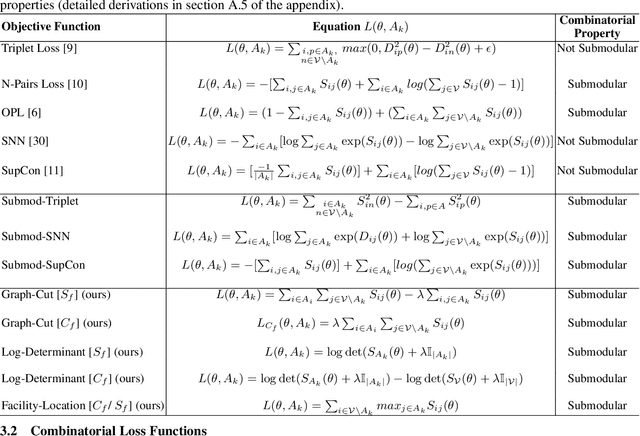
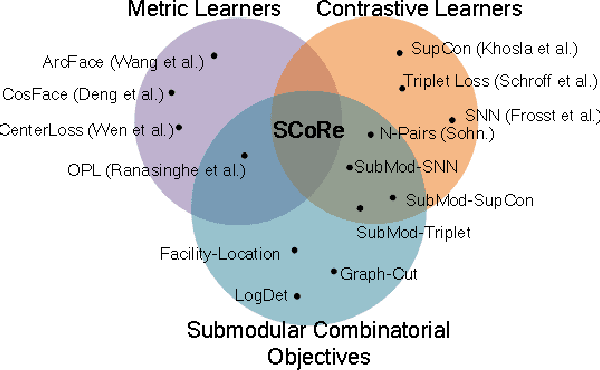
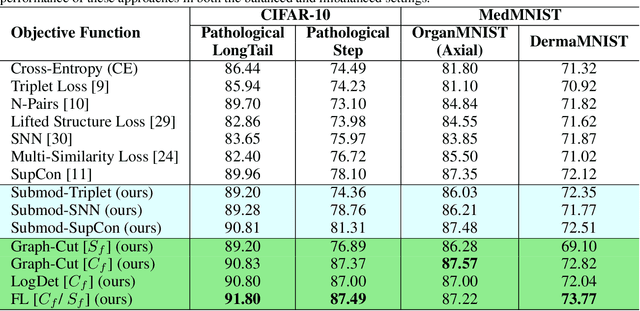
Representation Learning in real-world class-imbalanced settings has emerged as a challenging task in the evolution of deep learning. Lack of diversity in visual and structural features for rare classes restricts modern neural networks to learn discriminative feature clusters. This manifests in the form of large inter-class bias between rare object classes and elevated intra-class variance among abundant classes in the dataset. Although deep metric learning approaches have shown promise in this domain, significant improvements need to be made to overcome the challenges associated with class-imbalance in mission critical tasks like autonomous navigation and medical diagnostics. Set-based combinatorial functions like Submodular Information Measures exhibit properties that allow them to simultaneously model diversity and cooperation among feature clusters. In this paper, we introduce the SCoRe (Submodular Combinatorial Representation Learning) framework and propose a family of Submodular Combinatorial Loss functions to overcome these pitfalls in contrastive learning. We also show that existing contrastive learning approaches are either submodular or can be re-formulated to create their submodular counterparts. We conduct experiments on the newly introduced family of combinatorial objectives on two image classification benchmarks - pathologically imbalanced CIFAR-10, subsets of MedMNIST and a real-world road object detection benchmark - India Driving Dataset (IDD). Our experiments clearly show that the newly introduced objectives like Facility Location, Graph-Cut and Log Determinant outperform state-of-the-art metric learners by up to 7.6% for the imbalanced classification tasks and up to 19.4% for object detection tasks.
Feedback-guided Data Synthesis for Imbalanced Classification
Sep 29, 2023Current status quo in machine learning is to use static datasets of real images for training, which often come from long-tailed distributions. With the recent advances in generative models, researchers have started augmenting these static datasets with synthetic data, reporting moderate performance improvements on classification tasks. We hypothesize that these performance gains are limited by the lack of feedback from the classifier to the generative model, which would promote the usefulness of the generated samples to improve the classifier's performance. In this work, we introduce a framework for augmenting static datasets with useful synthetic samples, which leverages one-shot feedback from the classifier to drive the sampling of the generative model. In order for the framework to be effective, we find that the samples must be close to the support of the real data of the task at hand, and be sufficiently diverse. We validate three feedback criteria on a long-tailed dataset (ImageNet-LT) as well as a group-imbalanced dataset (NICO++). On ImageNet-LT, we achieve state-of-the-art results, with over 4 percent improvement on underrepresented classes while being twice efficient in terms of the number of generated synthetic samples. NICO++ also enjoys marked boosts of over 5 percent in worst group accuracy. With these results, our framework paves the path towards effectively leveraging state-of-the-art text-to-image models as data sources that can be queried to improve downstream applications.
ResWCAE: Biometric Pattern Image Denoising Using Residual Wavelet-Conditioned Autoencoder
Jul 23, 2023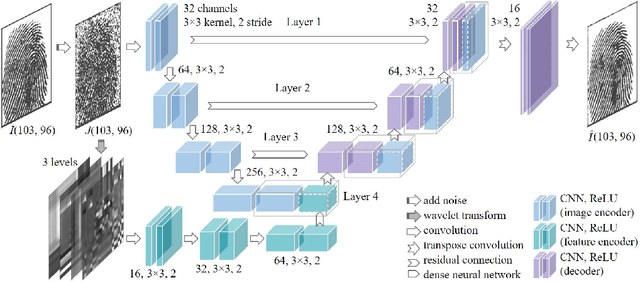
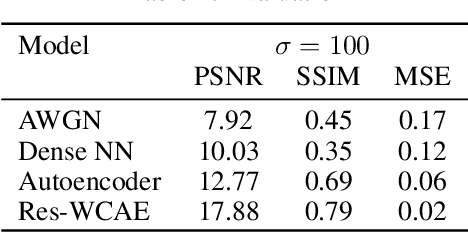
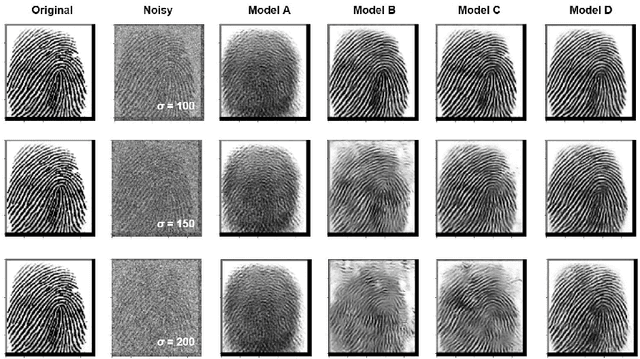
The utilization of biometric authentication with pattern images is increasingly popular in compact Internet of Things (IoT) devices. However, the reliability of such systems can be compromised by image quality issues, particularly in the presence of high levels of noise. While state-of-the-art deep learning algorithms designed for generic image denoising have shown promise, their large number of parameters and lack of optimization for unique biometric pattern retrieval make them unsuitable for these devices and scenarios. In response to these challenges, this paper proposes a lightweight and robust deep learning architecture, the Residual Wavelet-Conditioned Convolutional Autoencoder (Res-WCAE) with a Kullback-Leibler divergence (KLD) regularization, designed specifically for fingerprint image denoising. Res-WCAE comprises two encoders - an image encoder and a wavelet encoder - and one decoder. Residual connections between the image encoder and decoder are leveraged to preserve fine-grained spatial features, where the bottleneck layer conditioned on the compressed representation of features obtained from the wavelet encoder using approximation and detail subimages in the wavelet-transform domain. The effectiveness of Res-WCAE is evaluated against several state-of-the-art denoising methods, and the experimental results demonstrate that Res-WCAE outperforms these methods, particularly for heavily degraded fingerprint images in the presence of high levels of noise. Overall, Res-WCAE shows promise as a solution to the challenges faced by biometric authentication systems in compact IoT devices.
FedAutoMRI: Federated Neural Architecture Search for MR Image Reconstruction
Jul 21, 2023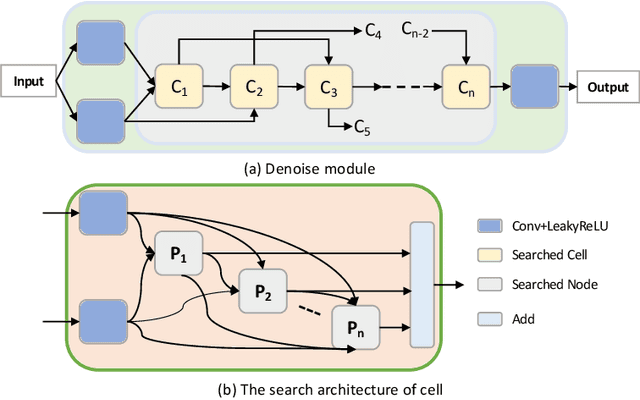
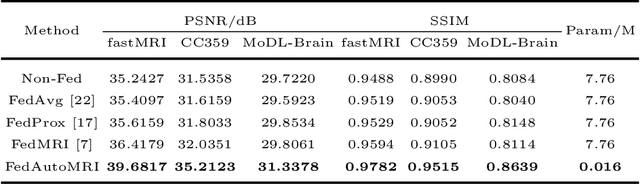
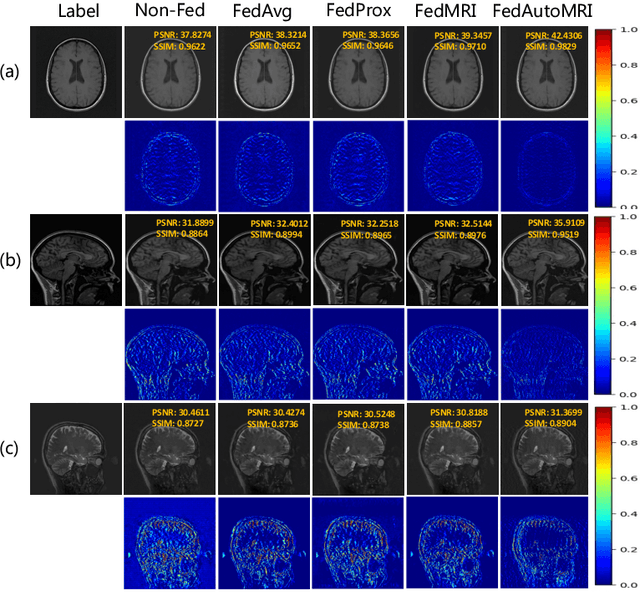
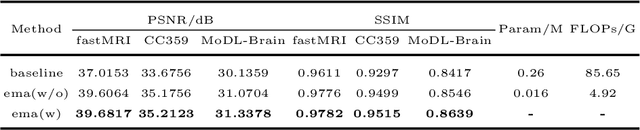
Centralized training methods have shown promising results in MR image reconstruction, but privacy concerns arise when gathering data from multiple institutions. Federated learning, a distributed collaborative training scheme, can utilize multi-center data without the need to transfer data between institutions. However, existing federated learning MR image reconstruction methods rely on manually designed models which have extensive parameters and suffer from performance degradation when facing heterogeneous data distributions. To this end, this paper proposes a novel FederAted neUral archiTecture search approach fOr MR Image reconstruction (FedAutoMRI). The proposed method utilizes differentiable architecture search to automatically find the optimal network architecture. In addition, an exponential moving average method is introduced to improve the robustness of the client model to address the data heterogeneity issue. To the best of our knowledge, this is the first work to use federated neural architecture search for MR image reconstruction. Experimental results demonstrate that our proposed FedAutoMRI can achieve promising performances while utilizing a lightweight model with only a small number of model parameters compared to the classical federated learning methods.