 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Selective Hourglass Mapping for Universal Image Restoration Based on Diffusion Model
Mar 17, 2024
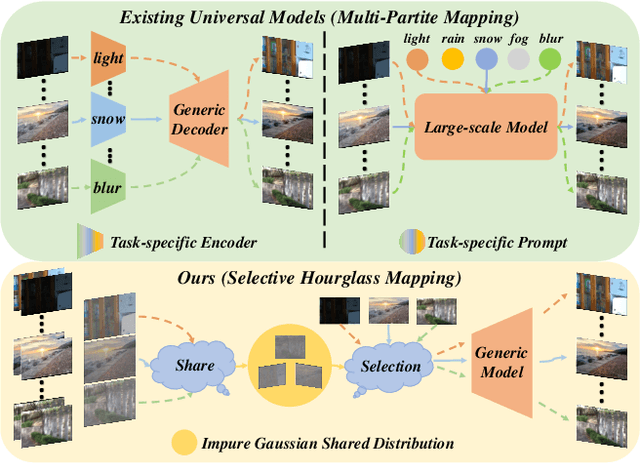


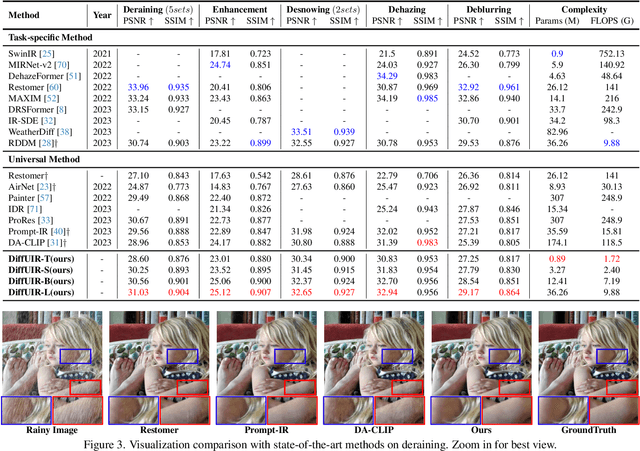
Universal image restoration is a practical and potential computer vision task for real-world applications. The main challenge of this task is handling the different degradation distributions at once. Existing methods mainly utilize task-specific conditions (e.g., prompt) to guide the model to learn different distributions separately, named multi-partite mapping. However, it is not suitable for universal model learning as it ignores the shared information between different tasks. In this work, we propose an advanced selective hourglass mapping strategy based on diffusion model, termed DiffUIR. Two novel considerations make our DiffUIR non-trivial. Firstly, we equip the model with strong condition guidance to obtain accurate generation direction of diffusion model (selective). More importantly, DiffUIR integrates a flexible shared distribution term (SDT) into the diffusion algorithm elegantly and naturally, which gradually maps different distributions into a shared one. In the reverse process, combined with SDT and strong condition guidance, DiffUIR iteratively guides the shared distribution to the task-specific distribution with high image quality (hourglass). Without bells and whistles, by only modifying the mapping strategy, we achieve state-of-the-art performance on five image restoration tasks, 22 benchmarks in the universal setting and zero-shot generalization setting. Surprisingly, by only using a lightweight model (only 0.89M), we could achieve outstanding performance. The source code and pre-trained models are available at https://github.com/iSEE-Laboratory/DiffUIR
SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion
Mar 18, 2024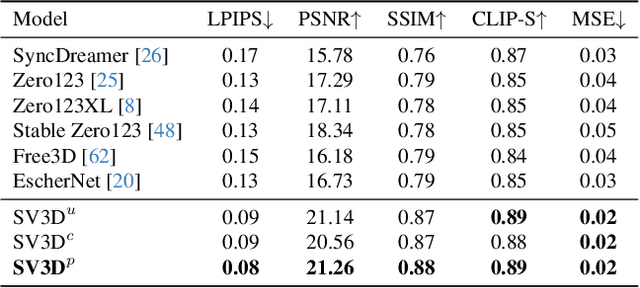
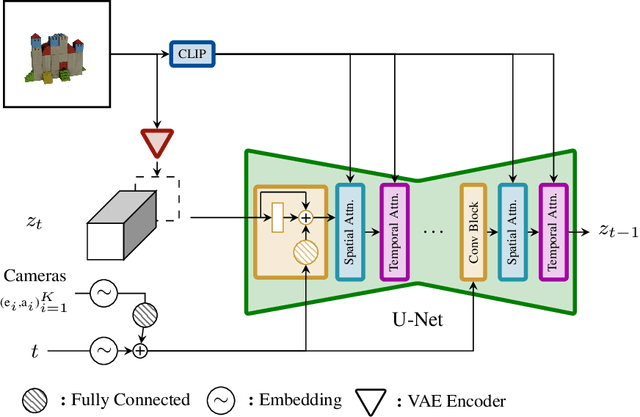
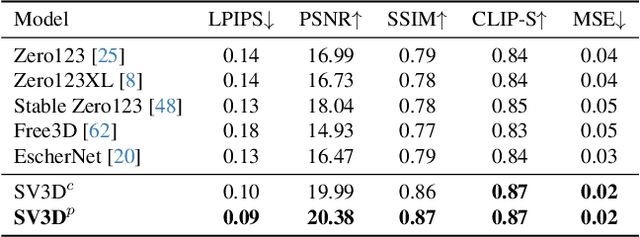
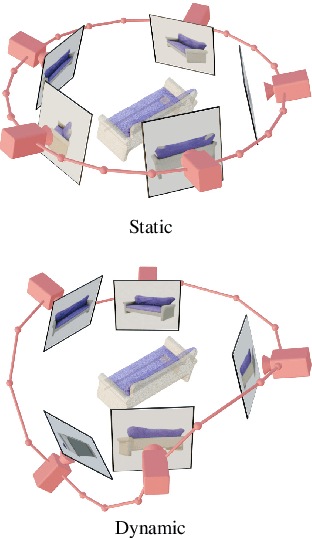
We present Stable Video 3D (SV3D) -- a latent video diffusion model for high-resolution, image-to-multi-view generation of orbital videos around a 3D object. Recent work on 3D generation propose techniques to adapt 2D generative models for novel view synthesis (NVS) and 3D optimization. However, these methods have several disadvantages due to either limited views or inconsistent NVS, thereby affecting the performance of 3D object generation. In this work, we propose SV3D that adapts image-to-video diffusion model for novel multi-view synthesis and 3D generation, thereby leveraging the generalization and multi-view consistency of the video models, while further adding explicit camera control for NVS. We also propose improved 3D optimization techniques to use SV3D and its NVS outputs for image-to-3D generation. Extensive experimental results on multiple datasets with 2D and 3D metrics as well as user study demonstrate SV3D's state-of-the-art performance on NVS as well as 3D reconstruction compared to prior works.
Enhancing Adversarial Training with Prior Knowledge Distillation for Robust Image Compression
Mar 16, 2024
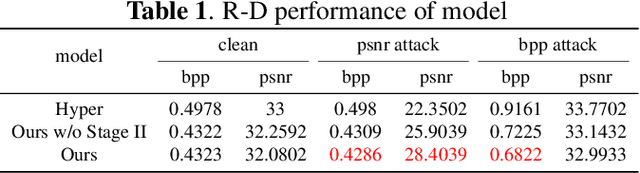
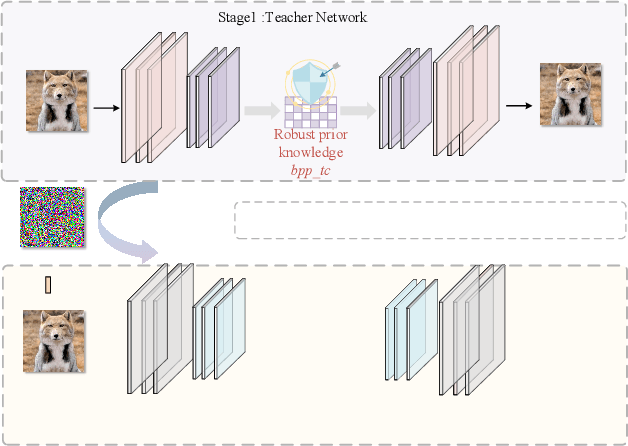
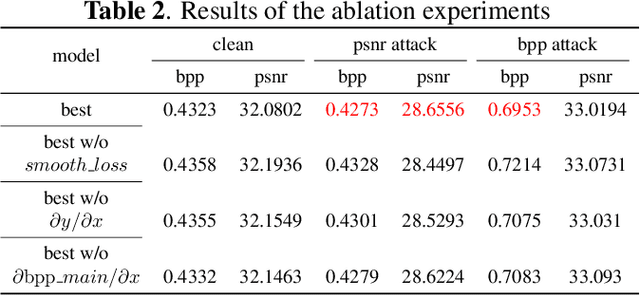
Deep neural network-based image compression (NIC) has achieved excellent performance, but NIC method models have been shown to be susceptible to backdoor attacks. Adversarial training has been validated in image compression models as a common method to enhance model robustness. However, the improvement effect of adversarial training on model robustness is limited. In this paper, we propose a prior knowledge-guided adversarial training framework for image compression models. Specifically, first, we propose a gradient regularization constraint for training robust teacher models. Subsequently, we design a knowledge distillation based strategy to generate a priori knowledge from the teacher model to the student model for guiding adversarial training. Experimental results show that our method improves the reconstruction quality by about 9dB when the Kodak dataset is elected as the backdoor attack object for psnr attack. Compared with Ma2023, our method has a 5dB higher PSNR output at high bitrate points.
Minimum-Norm Interpolation Under Covariate Shift
Mar 31, 2024Transfer learning is a critical part of real-world machine learning deployments and has been extensively studied in experimental works with overparameterized neural networks. However, even in the simplest setting of linear regression a notable gap still exists in the theoretical understanding of transfer learning. In-distribution research on high-dimensional linear regression has led to the identification of a phenomenon known as \textit{benign overfitting}, in which linear interpolators overfit to noisy training labels and yet still generalize well. This behavior occurs under specific conditions on the source covariance matrix and input data dimension. Therefore, it is natural to wonder how such high-dimensional linear models behave under transfer learning. We prove the first non-asymptotic excess risk bounds for benignly-overfit linear interpolators in the transfer learning setting. From our analysis, we propose a taxonomy of \textit{beneficial} and \textit{malignant} covariate shifts based on the degree of overparameterization. We follow our analysis with empirical studies that show these beneficial and malignant covariate shifts for linear interpolators on real image data, and for fully-connected neural networks in settings where the input data dimension is larger than the training sample size.
TexVocab: Texture Vocabulary-conditioned Human Avatars
Mar 31, 2024To adequately utilize the available image evidence in multi-view video-based avatar modeling, we propose TexVocab, a novel avatar representation that constructs a texture vocabulary and associates body poses with texture maps for animation. Given multi-view RGB videos, our method initially back-projects all the available images in the training videos to the posed SMPL surface, producing texture maps in the SMPL UV domain. Then we construct pairs of human poses and texture maps to establish a texture vocabulary for encoding dynamic human appearances under various poses. Unlike the commonly used joint-wise manner, we further design a body-part-wise encoding strategy to learn the structural effects of the kinematic chain. Given a driving pose, we query the pose feature hierarchically by decomposing the pose vector into several body parts and interpolating the texture features for synthesizing fine-grained human dynamics. Overall, our method is able to create animatable human avatars with detailed and dynamic appearances from RGB videos, and the experiments show that our method outperforms state-of-the-art approaches. The project page can be found at https://texvocab.github.io/.
DailyMAE: Towards Pretraining Masked Autoencoders in One Day
Mar 31, 2024Recently, masked image modeling (MIM), an important self-supervised learning (SSL) method, has drawn attention for its effectiveness in learning data representation from unlabeled data. Numerous studies underscore the advantages of MIM, highlighting how models pretrained on extensive datasets can enhance the performance of downstream tasks. However, the high computational demands of pretraining pose significant challenges, particularly within academic environments, thereby impeding the SSL research progress. In this study, we propose efficient training recipes for MIM based SSL that focuses on mitigating data loading bottlenecks and employing progressive training techniques and other tricks to closely maintain pretraining performance. Our library enables the training of a MAE-Base/16 model on the ImageNet 1K dataset for 800 epochs within just 18 hours, using a single machine equipped with 8 A100 GPUs. By achieving speed gains of up to 5.8 times, this work not only demonstrates the feasibility of conducting high-efficiency SSL training but also paves the way for broader accessibility and promotes advancement in SSL research particularly for prototyping and initial testing of SSL ideas. The code is available in https://github.com/erow/FastSSL.
Breaking the Limitations with Sparse Inputs by Variational Frameworks (BLIss) in Terahertz Super-Resolution 3D Reconstruction
Mar 27, 2024Data acquisition, image processing, and image quality are the long-lasting issues for terahertz (THz) 3D reconstructed imaging. Existing methods are primarily designed for 2D scenarios, given the challenges associated with obtaining super-resolution (SR) data and the absence of an efficient SR 3D reconstruction framework in conventional computed tomography (CT). Here, we demonstrate BLIss, a new approach for THz SR 3D reconstruction with sparse 2D data input. BLIss seamlessly integrates conventional CT techniques and variational framework with the core of the adapted Euler-Elastica-based model. The quantitative 3D image evaluation metrics, including the standard deviation of Gaussian, mean curvatures, and the multi-scale structural similarity index measure (MS-SSIM), validate the superior smoothness and fidelity achieved with our variational framework approach compared with conventional THz CT modal. Beyond its contributions to advancing THz SR 3D reconstruction, BLIss demonstrates potential applicability in other imaging modalities, such as X-ray and MRI. This suggests extensive impacts on the broader field of imaging applications.
* 15 pages, 7 figures. Supplemental Document: https://doi.org/10.6084/m9.figshare.24455206
DiffusionFace: Towards a Comprehensive Dataset for Diffusion-Based Face Forgery Analysis
Mar 27, 2024The rapid progress in deep learning has given rise to hyper-realistic facial forgery methods, leading to concerns related to misinformation and security risks. Existing face forgery datasets have limitations in generating high-quality facial images and addressing the challenges posed by evolving generative techniques. To combat this, we present DiffusionFace, the first diffusion-based face forgery dataset, covering various forgery categories, including unconditional and Text Guide facial image generation, Img2Img, Inpaint, and Diffusion-based facial exchange algorithms. Our DiffusionFace dataset stands out with its extensive collection of 11 diffusion models and the high-quality of the generated images, providing essential metadata and a real-world internet-sourced forgery facial image dataset for evaluation. Additionally, we provide an in-depth analysis of the data and introduce practical evaluation protocols to rigorously assess discriminative models' effectiveness in detecting counterfeit facial images, aiming to enhance security in facial image authentication processes. The dataset is available for download at \url{https://github.com/Rapisurazurite/DiffFace}.
Discriminative Probing and Tuning for Text-to-Image Generation
Mar 14, 2024
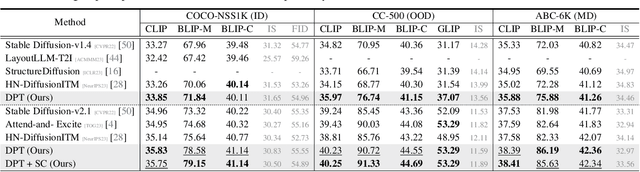
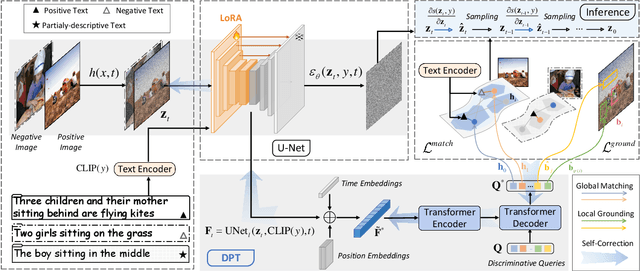
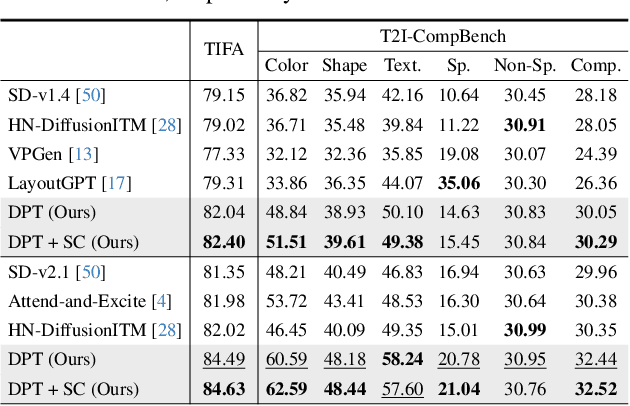
Despite advancements in text-to-image generation (T2I), prior methods often face text-image misalignment problems such as relation confusion in generated images. Existing solutions involve cross-attention manipulation for better compositional understanding or integrating large language models for improved layout planning. However, the inherent alignment capabilities of T2I models are still inadequate. By reviewing the link between generative and discriminative modeling, we posit that T2I models' discriminative abilities may reflect their text-image alignment proficiency during generation. In this light, we advocate bolstering the discriminative abilities of T2I models to achieve more precise text-to-image alignment for generation. We present a discriminative adapter built on T2I models to probe their discriminative abilities on two representative tasks and leverage discriminative fine-tuning to improve their text-image alignment. As a bonus of the discriminative adapter, a self-correction mechanism can leverage discriminative gradients to better align generated images to text prompts during inference. Comprehensive evaluations across three benchmark datasets, including both in-distribution and out-of-distribution scenarios, demonstrate our method's superior generation performance. Meanwhile, it achieves state-of-the-art discriminative performance on the two discriminative tasks compared to other generative models.
VIXEN: Visual Text Comparison Network for Image Difference Captioning
Mar 14, 2024We present VIXEN - a technique that succinctly summarizes in text the visual differences between a pair of images in order to highlight any content manipulation present. Our proposed network linearly maps image features in a pairwise manner, constructing a soft prompt for a pretrained large language model. We address the challenge of low volume of training data and lack of manipulation variety in existing image difference captioning (IDC) datasets by training on synthetically manipulated images from the recent InstructPix2Pix dataset generated via prompt-to-prompt editing framework. We augment this dataset with change summaries produced via GPT-3. We show that VIXEN produces state-of-the-art, comprehensible difference captions for diverse image contents and edit types, offering a potential mitigation against misinformation disseminated via manipulated image content. Code and data are available at http://github.com/alexblck/vixen