 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Extracting Semantic Knowledge from GANs with Unsupervised Learning
Nov 30, 2022



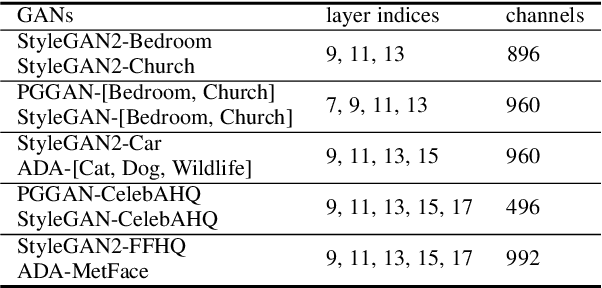
Recently, unsupervised learning has made impressive progress on various tasks. Despite the dominance of discriminative models, increasing attention is drawn to representations learned by generative models and in particular, Generative Adversarial Networks (GANs). Previous works on the interpretation of GANs reveal that GANs encode semantics in feature maps in a linearly separable form. In this work, we further find that GAN's features can be well clustered with the linear separability assumption. We propose a novel clustering algorithm, named KLiSH, which leverages the linear separability to cluster GAN's features. KLiSH succeeds in extracting fine-grained semantics of GANs trained on datasets of various objects, e.g., car, portrait, animals, and so on. With KLiSH, we can sample images from GANs along with their segmentation masks and synthesize paired image-segmentation datasets. Using the synthesized datasets, we enable two downstream applications. First, we train semantic segmentation networks on these datasets and test them on real images, realizing unsupervised semantic segmentation. Second, we train image-to-image translation networks on the synthesized datasets, enabling semantic-conditional image synthesis without human annotations.
Attribute Guided Unpaired Image-to-Image Translation with Semi-supervised Learning
Apr 29, 2019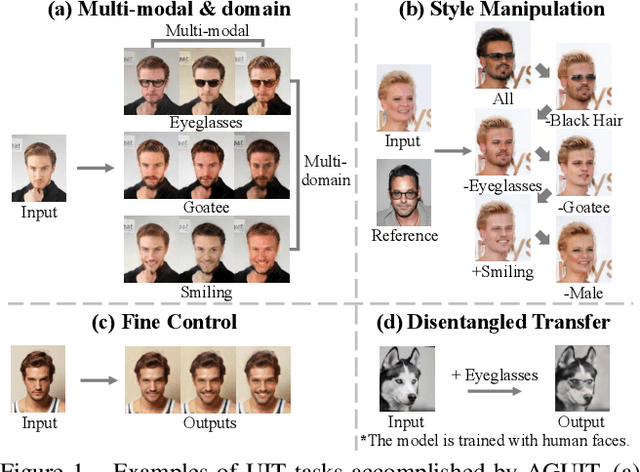

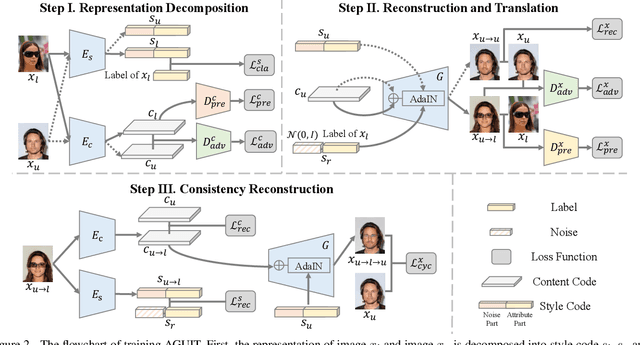
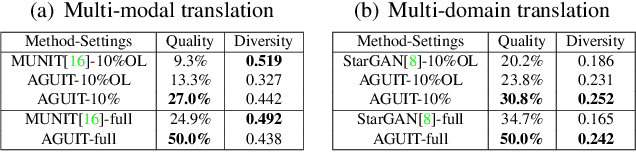
Unpaired Image-to-Image Translation (UIT) focuses on translating images among different domains by using unpaired data, which has received increasing research focus due to its practical usage. However, existing UIT schemes defect in the need of supervised training, as well as the lack of encoding domain information. In this paper, we propose an Attribute Guided UIT model termed AGUIT to tackle these two challenges. AGUIT considers multi-modal and multi-domain tasks of UIT jointly with a novel semi-supervised setting, which also merits in representation disentanglement and fine control of outputs. Especially, AGUIT benefits from two-fold: (1) It adopts a novel semi-supervised learning process by translating attributes of labeled data to unlabeled data, and then reconstructing the unlabeled data by a cycle consistency operation. (2) It decomposes image representation into domain-invariant content code and domain-specific style code. The redesigned style code embeds image style into two variables drawn from standard Gaussian distribution and the distribution of domain label, which facilitates the fine control of translation due to the continuity of both variables. Finally, we introduce a new challenge, i.e., disentangled transfer, for UIT models, which adopts the disentangled representation to translate data less related with the training set. Extensive experiments demonstrate the capacity of AGUIT over existing state-of-the-art models.
Semantics-Preserving Sketch Embedding for Face Generation
Nov 23, 2022



With recent advances in image-to-image translation tasks, remarkable progress has been witnessed in generating face images from sketches. However, existing methods frequently fail to generate images with details that are semantically and geometrically consistent with the input sketch, especially when various decoration strokes are drawn. To address this issue, we introduce a novel W-W+ encoder architecture to take advantage of the high expressive power of W+ space and semantic controllability of W space. We introduce an explicit intermediate representation for sketch semantic embedding. With a semantic feature matching loss for effective semantic supervision, our sketch embedding precisely conveys the semantics in the input sketches to the synthesized images. Moreover, a novel sketch semantic interpretation approach is designed to automatically extract semantics from vectorized sketches. We conduct extensive experiments on both synthesized sketches and hand-drawn sketches, and the results demonstrate the superiority of our method over existing approaches on both semantics-preserving and generalization ability.
Smoothing the Disentangled Latent Style Space for Unsupervised Image-to-Image Translation
Jun 16, 2021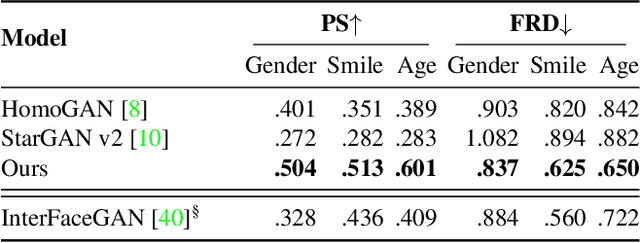
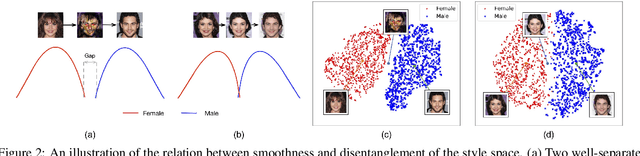
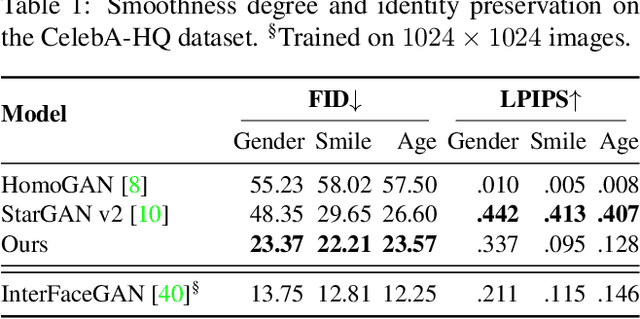

Image-to-Image (I2I) multi-domain translation models are usually evaluated also using the quality of their semantic interpolation results. However, state-of-the-art models frequently show abrupt changes in the image appearance during interpolation, and usually perform poorly in interpolations across domains. In this paper, we propose a new training protocol based on three specific losses which help a translation network to learn a smooth and disentangled latent style space in which: 1) Both intra- and inter-domain interpolations correspond to gradual changes in the generated images and 2) The content of the source image is better preserved during the translation. Moreover, we propose a novel evaluation metric to properly measure the smoothness of latent style space of I2I translation models. The proposed method can be plugged into existing translation approaches, and our extensive experiments on different datasets show that it can significantly boost the quality of the generated images and the graduality of the interpolations.
Generative Adversarial Network Applications in Creating a Meta-Universe
Jan 23, 2022


Generative Adversarial Networks (GANs) are machine learning methods that are used in many important and novel applications. For example, in imaging science, GANs are effectively utilized in generating image datasets, photographs of human faces, image and video captioning, image-to-image translation, text-to-image translation, video prediction, and 3D object generation to name a few. In this paper, we discuss how GANs can be used to create an artificial world. More specifically, we discuss how GANs help to describe an image utilizing image/video captioning methods and how to translate the image to a new image using image-to-image translation frameworks in a theme we desire. We articulate how GANs impact creating a customized world.
DGFont++: Robust Deformable Generative Networks for Unsupervised Font Generation
Dec 30, 2022
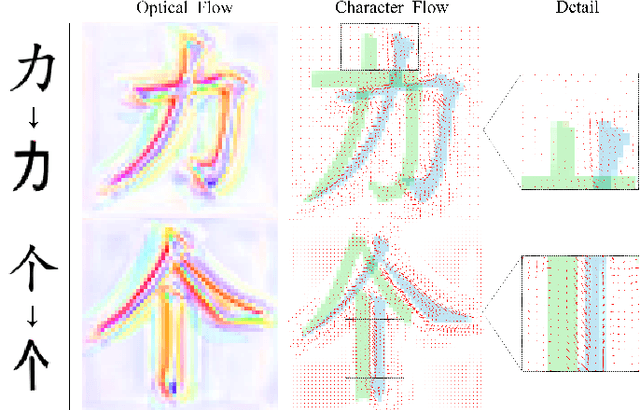


Automatic font generation without human experts is a practical and significant problem, especially for some languages that consist of a large number of characters. Existing methods for font generation are often in supervised learning. They require a large number of paired data, which are labor-intensive and expensive to collect. In contrast, common unsupervised image-to-image translation methods are not applicable to font generation, as they often define style as the set of textures and colors. In this work, we propose a robust deformable generative network for unsupervised font generation (abbreviated as DGFont++). We introduce a feature deformation skip connection (FDSC) to learn local patterns and geometric transformations between fonts. The FDSC predicts pairs of displacement maps and employs the predicted maps to apply deformable convolution to the low-level content feature maps. The outputs of FDSC are fed into a mixer to generate final results. Moreover, we introduce contrastive self-supervised learning to learn a robust style representation for fonts by understanding the similarity and dissimilarities of fonts. To distinguish different styles, we train our model with a multi-task discriminator, which ensures that each style can be discriminated independently. In addition to adversarial loss, another two reconstruction losses are adopted to constrain the domain-invariant characteristics between generated images and content images. Taking advantage of FDSC and the adopted loss functions, our model is able to maintain spatial information and generates high-quality character images in an unsupervised manner. Experiments demonstrate that our model is able to generate character images of higher quality than state-of-the-art methods.
StyleDomain: Analysis of StyleSpace for Domain Adaptation of StyleGAN
Dec 20, 2022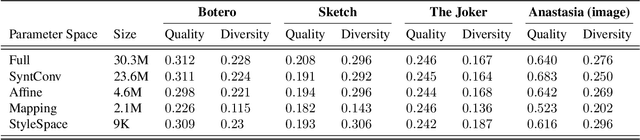
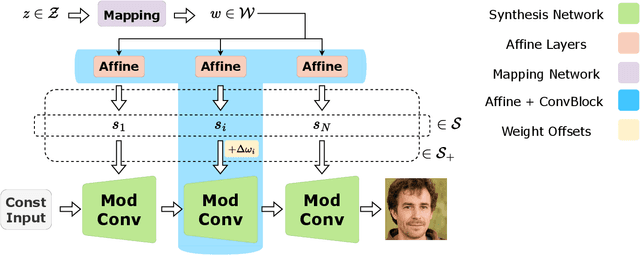
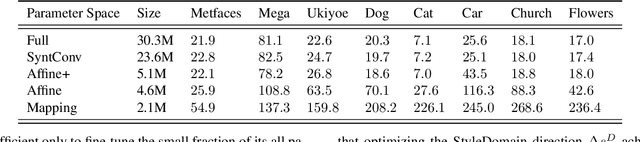

Domain adaptation of GANs is a problem of fine-tuning the state-of-the-art GAN models (e.g. StyleGAN) pretrained on a large dataset to a specific domain with few samples (e.g. painting faces, sketches, etc.). While there are a great number of methods that tackle this problem in different ways there are still many important questions that remain unanswered. In this paper, we provide a systematic and in-depth analysis of the domain adaptation problem of GANs, focusing on the StyleGAN model. First, we perform a detailed exploration of the most important parts of StyleGAN that are responsible for adapting the generator to a new domain depending on the similarity between the source and target domains. In particular, we show that affine layers of StyleGAN can be sufficient for fine-tuning to similar domains. Second, inspired by these findings, we investigate StyleSpace to utilize it for domain adaptation. We show that there exist directions in the StyleSpace that can adapt StyleGAN to new domains. Further, we examine these directions and discover their many surprising properties. Finally, we leverage our analysis and findings to deliver practical improvements and applications in such standard tasks as image-to-image translation and cross-domain morphing.
What and Where to Translate: Local Mask-based Image-to-Image Translation
Jun 09, 2019
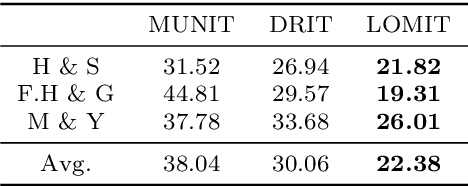

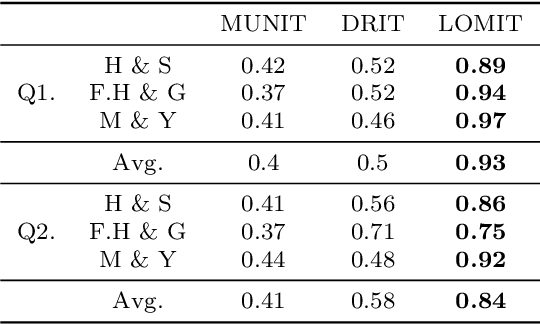
Recently, image-to-image translation has obtained significant attention. Among many, those approaches based on an exemplar image that contains the target style information has been actively studied, due to its capability to handle multimodality as well as its applicability in practical use. However, two intrinsic problems exist in the existing methods: what and where to transfer. First, those methods extract style from an entire exemplar which includes noisy information, which impedes a translation model from properly extracting the intended style of the exemplar. That is, we need to carefully determine what to transfer from the exemplar. Second, the extracted style is applied to the entire input image, which causes unnecessary distortion in irrelevant image regions. In response, we need to decide where to transfer the extracted style. In this paper, we propose a novel approach that extracts out a local mask from the exemplar that determines what style to transfer, and another local mask from the input image that determines where to transfer the extracted style. The main novelty of this paper lies in (1) the highway adaptive instance normalization technique and (2) an end-to-end translation framework which achieves an outstanding performance in reflecting a style of an exemplar. We demonstrate the quantitative and qualitative evaluation results to confirm the advantages of our proposed approach.
AdaWCT: Adaptive Whitening and Coloring Style Injection
Aug 01, 2022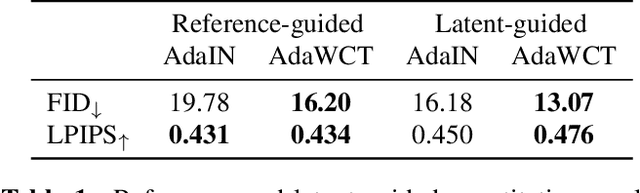

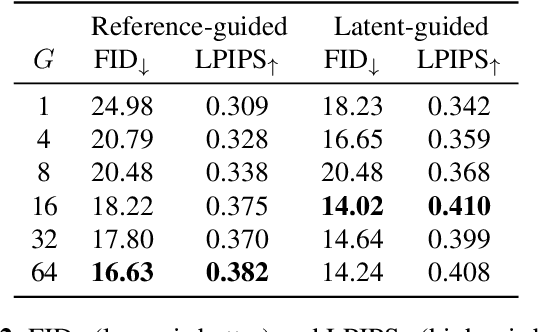

Adaptive instance normalization (AdaIN) has become the standard method for style injection: by re-normalizing features through scale-and-shift operations, it has found widespread use in style transfer, image generation, and image-to-image translation. In this work, we present a generalization of AdaIN which relies on the whitening and coloring transformation (WCT) which we dub AdaWCT, that we apply for style injection in large GANs. We show, through experiments on the StarGANv2 architecture, that this generalization, albeit conceptually simple, results in significant improvements in the quality of the generated images.
HealthyGAN: Learning from Unannotated Medical Images to Detect Anomalies Associated with Human Disease
Sep 05, 2022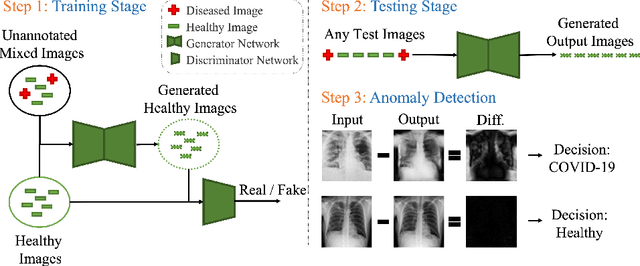
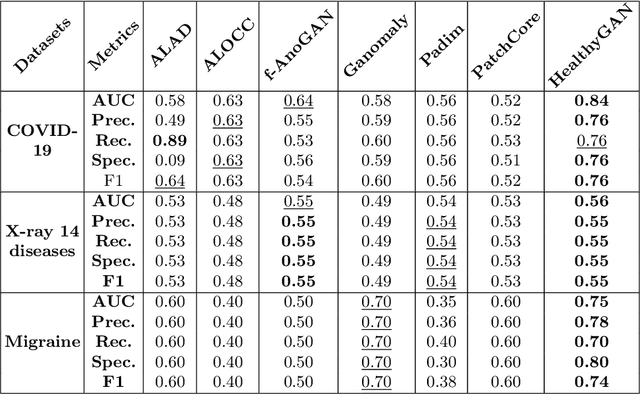
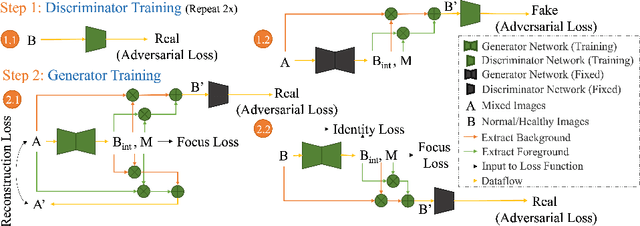
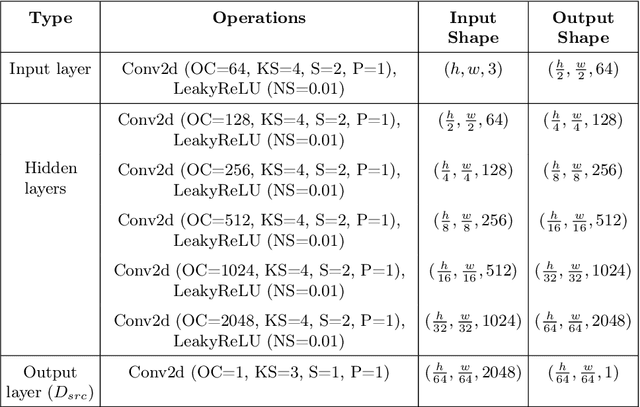
Automated anomaly detection from medical images, such as MRIs and X-rays, can significantly reduce human effort in disease diagnosis. Owing to the complexity of modeling anomalies and the high cost of manual annotation by domain experts (e.g., radiologists), a typical technique in the current medical imaging literature has focused on deriving diagnostic models from healthy subjects only, assuming the model will detect the images from patients as outliers. However, in many real-world scenarios, unannotated datasets with a mix of both healthy and diseased individuals are abundant. Therefore, this paper poses the research question of how to improve unsupervised anomaly detection by utilizing (1) an unannotated set of mixed images, in addition to (2) the set of healthy images as being used in the literature. To answer the question, we propose HealthyGAN, a novel one-directional image-to-image translation method, which learns to translate the images from the mixed dataset to only healthy images. Being one-directional, HealthyGAN relaxes the requirement of cycle consistency of existing unpaired image-to-image translation methods, which is unattainable with mixed unannotated data. Once the translation is learned, we generate a difference map for any given image by subtracting its translated output. Regions of significant responses in the difference map correspond to potential anomalies (if any). Our HealthyGAN outperforms the conventional state-of-the-art methods by significant margins on two publicly available datasets: COVID-19 and NIH ChestX-ray14, and one institutional dataset collected from Mayo Clinic. The implementation is publicly available at https://github.com/mahfuzmohammad/HealthyGAN.