 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Artifact Removal in Histopathology Images
Nov 29, 2022
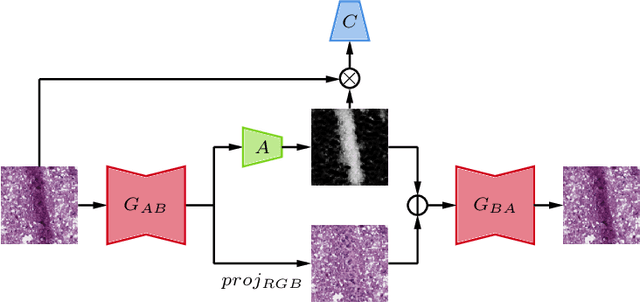

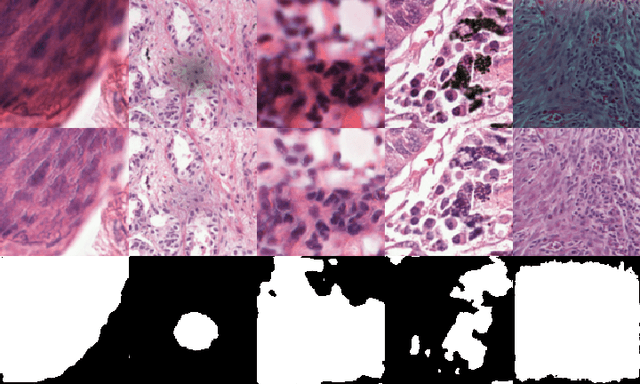

In the clinical setting of histopathology, whole-slide image (WSI) artifacts frequently arise, distorting regions of interest, and having a pernicious impact on WSI analysis. Image-to-image translation networks such as CycleGANs are in principle capable of learning an artifact removal function from unpaired data. However, we identify a surjection problem with artifact removal, and propose an weakly-supervised extension to CycleGAN to address this. We assemble a pan-cancer dataset comprising artifact and clean tiles from the TCGA database. Promising results highlight the soundness of our method.
Exploring Explicit Domain Supervision for Latent Space Disentanglement in Unpaired Image-to-Image Translation
Mar 26, 2019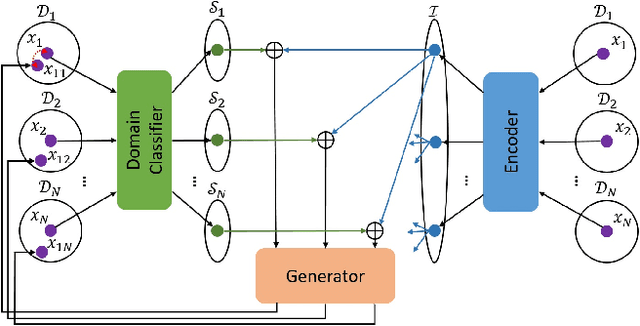
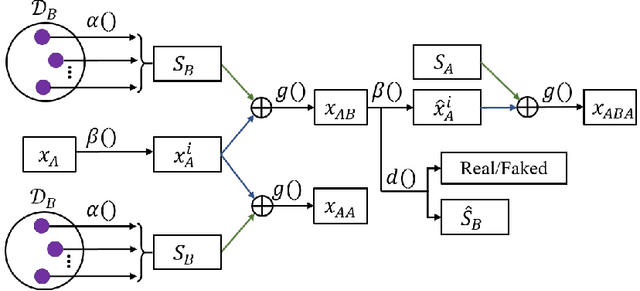

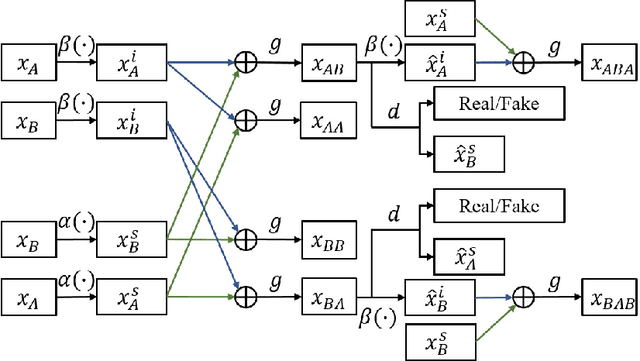
Image-to-image translation tasks have been widely investigated with Generative Adversarial Networks (GANs). However, existing approaches are mostly designed in an unsupervised manner while little attention has been paid to domain information within unpaired data. In this paper, we treat domain information as explicit supervision and design an unpaired image-to-image translation framework, Domain-supervised GAN (DosGAN), which takes the first step towards the exploration of explicit domain supervision. In contrast to representing domain characteristics using different generators in CycleGAN or multiple domain codes in StarGAN, we pre-train a classification network to explicitly classify the domain of an image. After pre-training, this network is used to extract the domain-specific features of each image by using the output of its second-to-last layer. Such features, together with the domain-independent features extracted by another encoder (shared across different domains), are used to generate an image in the target domain. Extensive experiments on multiple hair color translation, multiple identity translation, multiple season translation and conditional edges-to-shoes/handbags demonstrate the effectiveness of our method. In addition, we can transfer the domain-specific feature extractor obtained on the Facescrub dataset with domain supervision information to unseen domains, such as faces in the CelebA dataset. We also succeed in achieving conditional translation with any two images in CelebA, while previous models like StarGAN cannot handle this task.
Unsupervised Cardiac Segmentation Utilizing Synthesized Images from Anatomical Labels
Jan 15, 2023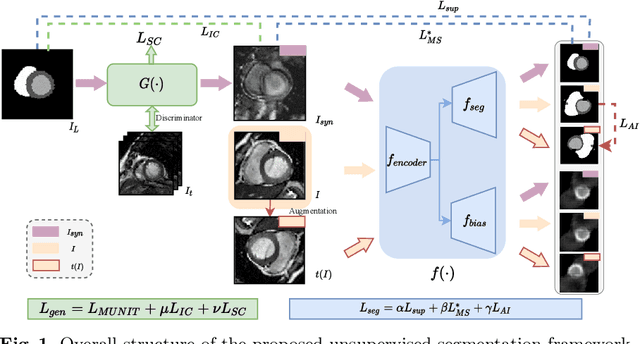
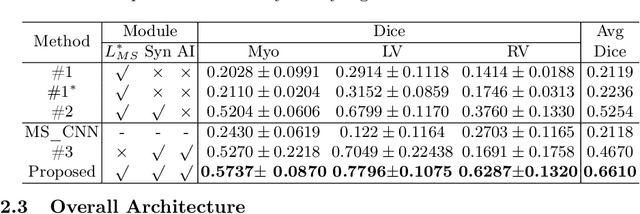


Cardiac segmentation is in great demand for clinical practice. Due to the enormous labor of manual delineation, unsupervised segmentation is desired. The ill-posed optimization problem of this task is inherently challenging, requiring well-designed constraints. In this work, we propose an unsupervised framework for multi-class segmentation with both intensity and shape constraints. Firstly, we extend a conventional non-convex energy function as an intensity constraint and implement it with U-Net. For shape constraint, synthetic images are generated from anatomical labels via image-to-image translation, as shape supervision for the segmentation network. Moreover, augmentation invariance is applied to facilitate the segmentation network to learn the latent features in terms of shape. We evaluated the proposed framework using the public datasets from MICCAI2019 MSCMR Challenge and achieved promising results on cardiac MRIs with Dice scores of 0.5737, 0.7796, and 0.6287 in Myo, LV, and RV, respectively.
Projection image-to-image translation in hybrid X-ray/MR imaging
Apr 11, 2018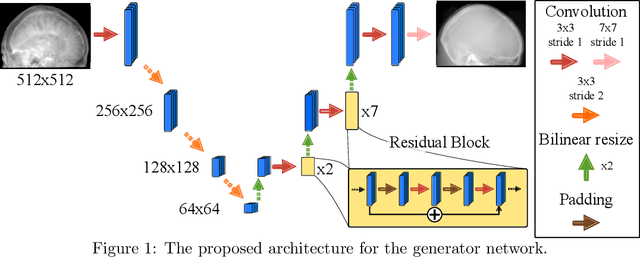
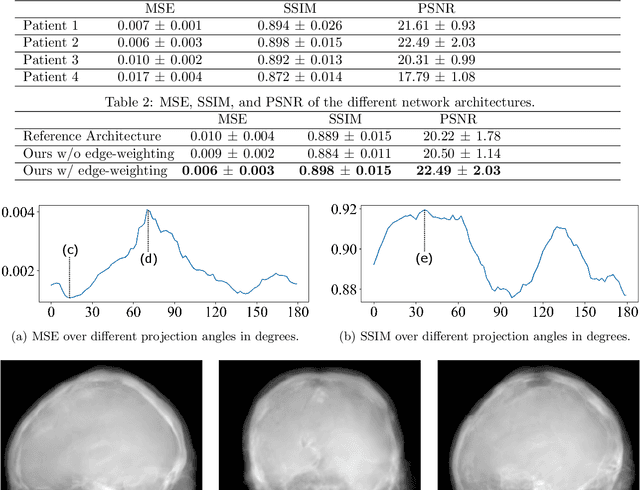
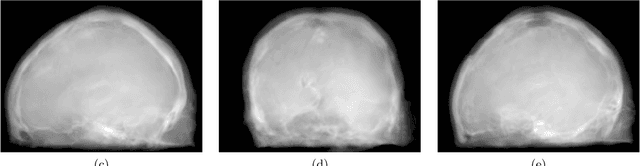
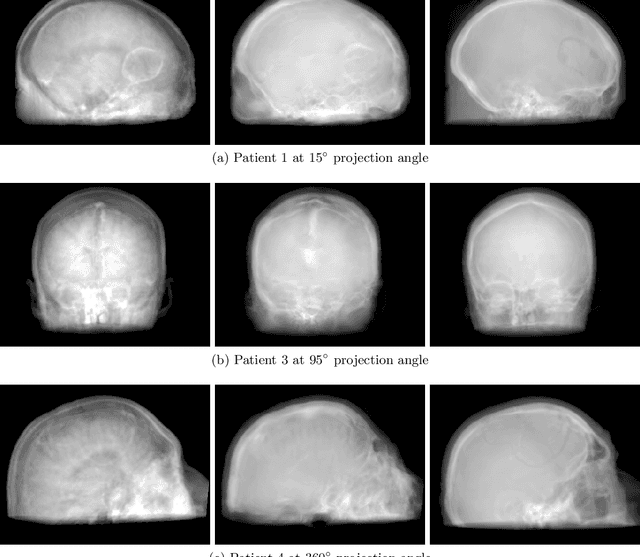
The potential benefit of hybrid X-ray and MR imaging in the interventional environment is enormous. However, a vast amount of existing image enhancement methods requires the image information to be present in the same domain. To unlock this potential, we present a solution to image-to-image translation from MR projections to corresponding X-ray projection images. The approach is based on a state-of-the-art image generator network that is modified to fit the specific application. Furthermore, we propose the inclusion of a gradient map to the perceptual loss to emphasize high frequency details. The proposed approach is capable of creating X-ray projection images with natural appearance. Additionally, our extensions show clear improvement compared to the baseline method.
Multi-Modality Image Inpainting using Generative Adversarial Networks
Jun 22, 2022



Deep learning techniques, especially Generative Adversarial Networks (GANs) have significantly improved image inpainting and image-to-image translation tasks over the past few years. To the best of our knowledge, the problem of combining the image inpainting task with the multi-modality image-to-image translation remains intact. In this paper, we propose a model to address this problem. The model will be evaluated on combined night-to-day image translation and inpainting, along with promising qualitative and quantitative results.
Face Attribute Editing with Disentangled Latent Vectors
Jan 11, 2023
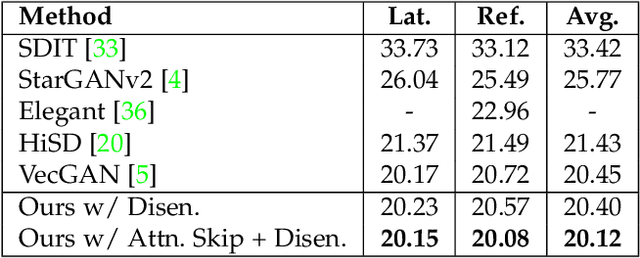
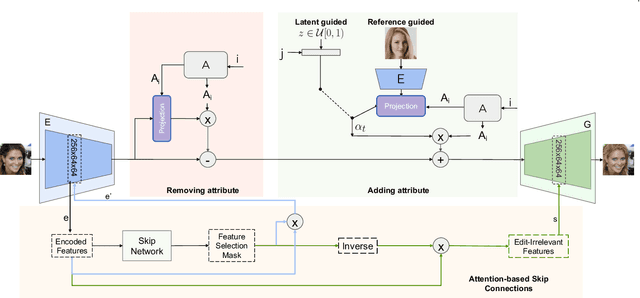
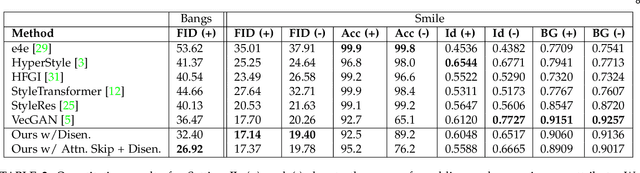
We propose an image-to-image translation framework for facial attribute editing with disentangled interpretable latent directions. Facial attribute editing task faces the challenges of targeted attribute editing with controllable strength and disentanglement in the representations of attributes to preserve the other attributes during edits. For this goal, inspired by the latent space factorization works of fixed pretrained GANs, we design the attribute editing by latent space factorization, and for each attribute, we learn a linear direction that is orthogonal to the others. We train these directions with orthogonality constraints and disentanglement losses. To project images to semantically organized latent spaces, we set an encoder-decoder architecture with attention-based skip connections. We extensively compare with previous image translation algorithms and editing with pretrained GAN works. Our extensive experiments show that our method significantly improves over the state-of-the-arts. Project page: https://yusufdalva.github.io/vecgan
Domain Bridge for Unpaired Image-to-Image Translation and Unsupervised Domain Adaptation
Oct 23, 2019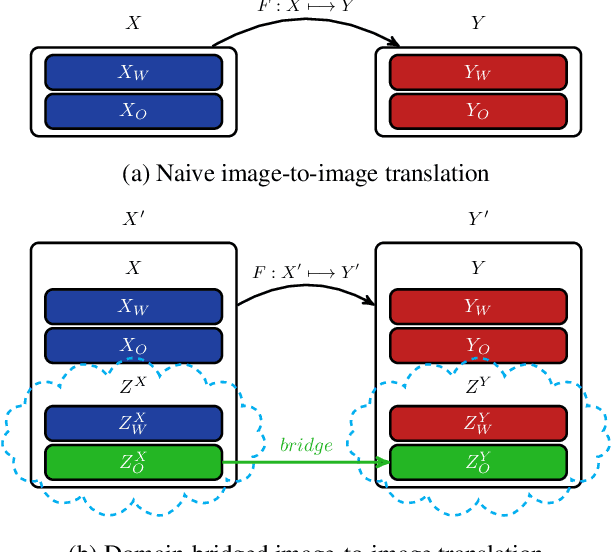
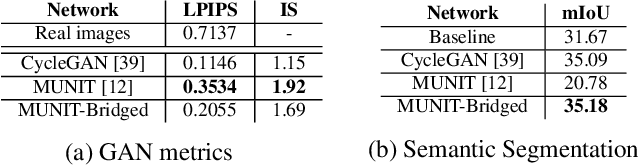
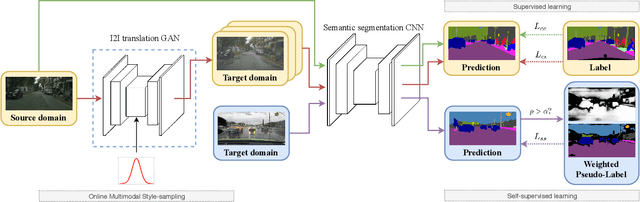

Image-to-image translation architectures may have limited effectiveness in some circumstances. For example, while generating rainy scenarios, they may fail to model typical traits of rain as water drops, and this ultimately impacts the synthetic images realism. With our method, called domain bridge, web-crawled data are exploited to reduce the domain gap, leading to the inclusion of previously ignored elements in the generated images. We make use of a network for clear to rain translation trained with the domain bridge to extend our work to Unsupervised Domain Adaptation (UDA). In that context, we introduce an online multimodal style-sampling strategy, where image translation multimodality is exploited at training time to improve performances. Finally, a novel approach for self-supervised learning is presented, and used to further align the domains. With our contributions, we simultaneously increase the realism of the generated images, while reaching on par performances w.r.t. the UDA state-of-the-art, with a simpler approach.
Describe What to Change: A Text-guided Unsupervised Image-to-Image Translation Approach
Aug 10, 2020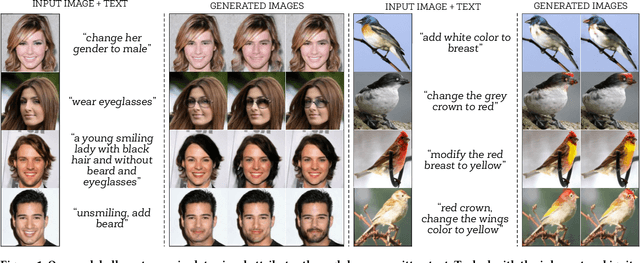
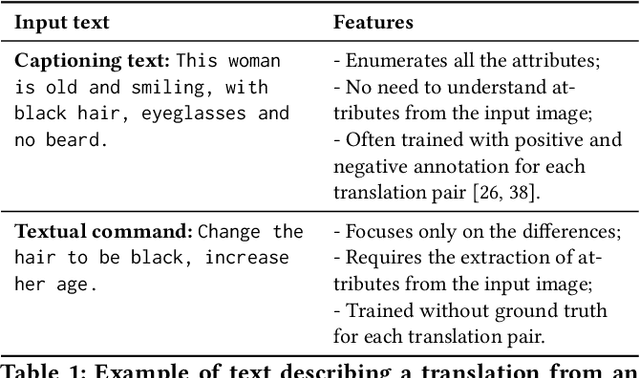
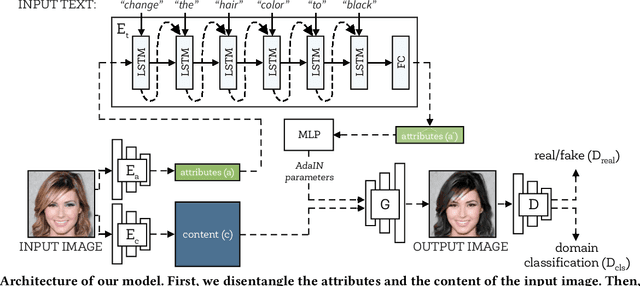

Manipulating visual attributes of images through human-written text is a very challenging task. On the one hand, models have to learn the manipulation without the ground truth of the desired output. On the other hand, models have to deal with the inherent ambiguity of natural language. Previous research usually requires either the user to describe all the characteristics of the desired image or to use richly-annotated image captioning datasets. In this work, we propose a novel unsupervised approach, based on image-to-image translation, that alters the attributes of a given image through a command-like sentence such as "change the hair color to black". Contrarily to state-of-the-art approaches, our model does not require a human-annotated dataset nor a textual description of all the attributes of the desired image, but only those that have to be modified. Our proposed model disentangles the image content from the visual attributes, and it learns to modify the latter using the textual description, before generating a new image from the content and the modified attribute representation. Because text might be inherently ambiguous (blond hair may refer to different shadows of blond, e.g. golden, icy, sandy), our method generates multiple stochastic versions of the same translation. Experiments show that the proposed model achieves promising performances on two large-scale public datasets: CelebA and CUB. We believe our approach will pave the way to new avenues of research combining textual and speech commands with visual attributes.
Unsupervised Image-to-Image Translation with Generative Adversarial Networks
Jan 10, 2017
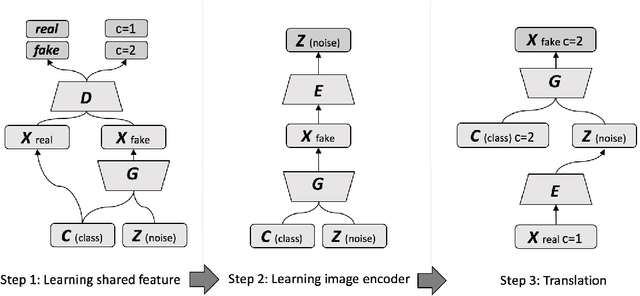

It's useful to automatically transform an image from its original form to some synthetic form (style, partial contents, etc.), while keeping the original structure or semantics. We define this requirement as the "image-to-image translation" problem, and propose a general approach to achieve it, based on deep convolutional and conditional generative adversarial networks (GANs), which has gained a phenomenal success to learn mapping images from noise input since 2014. In this work, we develop a two step (unsupervised) learning method to translate images between different domains by using unlabeled images without specifying any correspondence between them, so that to avoid the cost of acquiring labeled data. Compared with prior works, we demonstrated the capacity of generality in our model, by which variance of translations can be conduct by a single type of model. Such capability is desirable in applications like bidirectional translation
DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model
Feb 14, 2023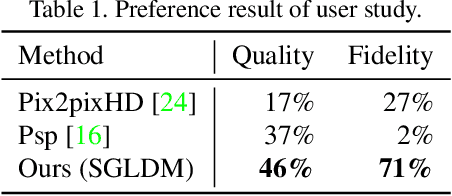

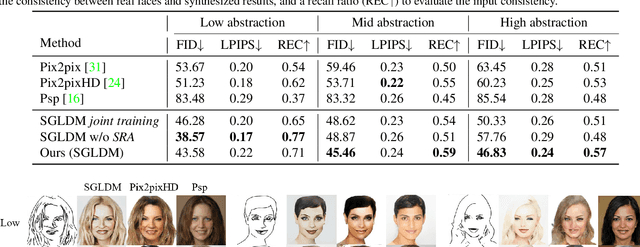
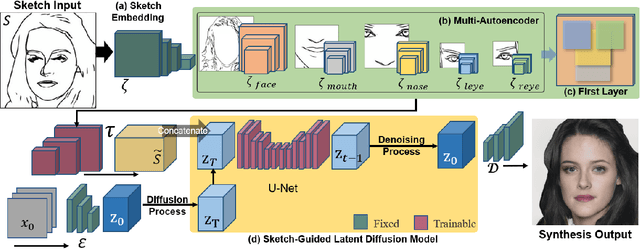
Synthesizing face images from monochrome sketches is one of the most fundamental tasks in the field of image-to-image translation. However, it is still challenging to (1)~make models learn the high-dimensional face features such as geometry and color, and (2)~take into account the characteristics of input sketches. Existing methods often use sketches as indirect inputs (or as auxiliary inputs) to guide the models, resulting in the loss of sketch features or the alteration of geometry information. In this paper, we introduce a Sketch-Guided Latent Diffusion Model (SGLDM), an LDM-based network architect trained on the paired sketch-face dataset. We apply a Multi-Auto-Encoder (AE) to encode the different input sketches from different regions of a face from pixel space to a feature map in latent space, which enables us to reduce the dimension of the sketch input while preserving the geometry-related information of local face details. We build a sketch-face paired dataset based on the existing method that extracts the edge map from an image. We then introduce a Stochastic Region Abstraction (SRA), an approach to augment our dataset to improve the robustness of SGLDM to handle sketch input with arbitrary abstraction. The evaluation study shows that SGLDM can synthesize high-quality face images with different expressions, facial accessories, and hairstyles from various sketches with different abstraction levels.