 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Delta Denoising Score
Apr 14, 2023
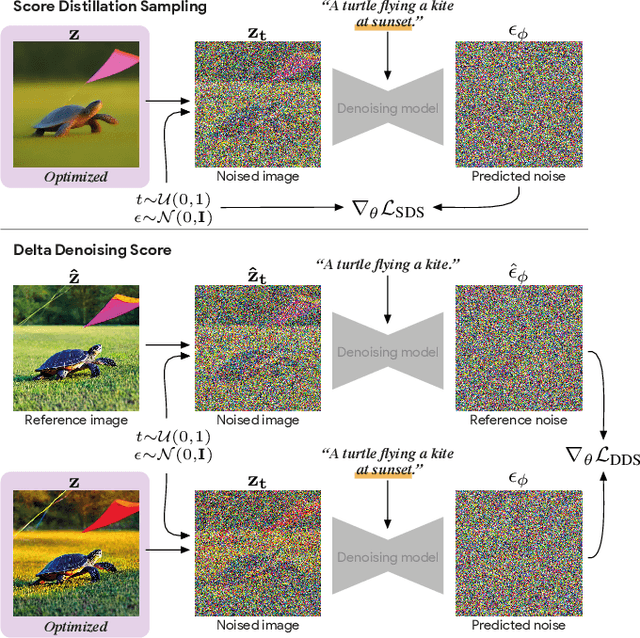
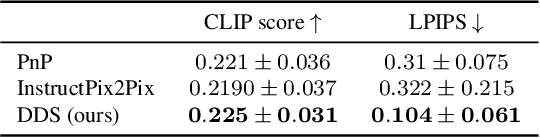


We introduce Delta Denoising Score (DDS), a novel scoring function for text-based image editing that guides minimal modifications of an input image towards the content described in a target prompt. DDS leverages the rich generative prior of text-to-image diffusion models and can be used as a loss term in an optimization problem to steer an image towards a desired direction dictated by a text. DDS utilizes the Score Distillation Sampling (SDS) mechanism for the purpose of image editing. We show that using only SDS often produces non-detailed and blurry outputs due to noisy gradients. To address this issue, DDS uses a prompt that matches the input image to identify and remove undesired erroneous directions of SDS. Our key premise is that SDS should be zero when calculated on pairs of matched prompts and images, meaning that if the score is non-zero, its gradients can be attributed to the erroneous component of SDS. Our analysis demonstrates the competence of DDS for text based image-to-image translation. We further show that DDS can be used to train an effective zero-shot image translation model. Experimental results indicate that DDS outperforms existing methods in terms of stability and quality, highlighting its potential for real-world applications in text-based image editing.
AttentionGAN: Unpaired Image-to-Image Translation using Attention-Guided Generative Adversarial Networks
Dec 28, 2019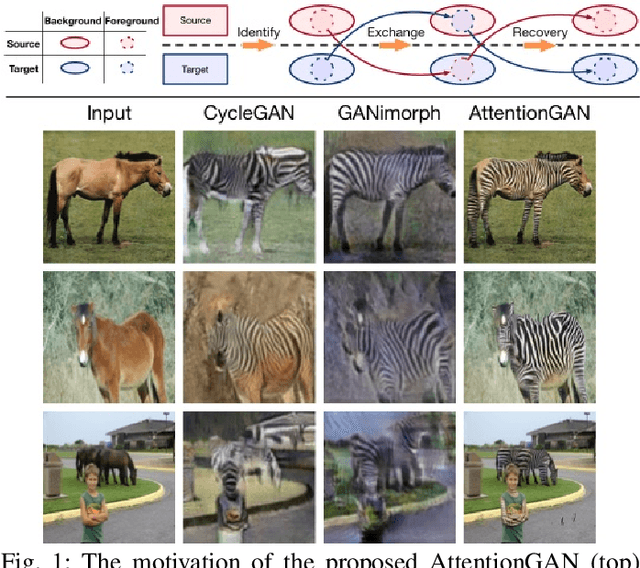



State-of-the-art methods in the unpaired image-to-image translation are capable of learning a mapping from a source domain to a target domain with unpaired image data. Though the existing methods have achieved promising results, they still produce unsatisfied artifacts, being able to convert low-level information while limited in transforming high-level semantics of input images. One possible reason is that generators do not have the ability to perceive the most discriminative semantic parts between the source and target domains, thus making the generated images low quality. In this paper, we propose a new Attention-Guided Generative Adversarial Networks (AttentionGAN) for the unpaired image-to-image translation task. AttentionGAN can identify the most discriminative semantic objects and minimize changes of unwanted parts for semantic manipulation problems without using extra data and models. The attention-guided generators in AttentionGAN are able to produce attention masks via a built-in attention mechanism, and then fuse the generation output with the attention masks to obtain high-quality target images. Accordingly, we also design a novel attention-guided discriminator which only considers attended regions. Extensive experiments are conducted on several generative tasks, demonstrating that the proposed model is effective to generate sharper and more realistic images compared with existing competitive models. The source code for the proposed AttentionGAN is available at https://github.com/Ha0Tang/AttentionGAN.
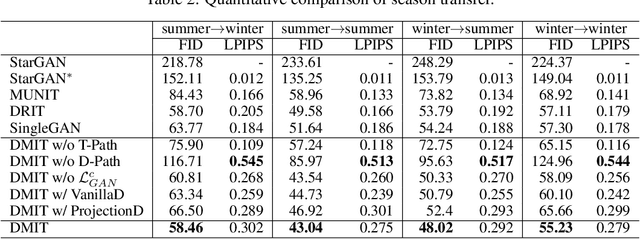
Less is More: Unified Model for Unsupervised Multi-Domain Image-to-Image Translation
May 28, 2018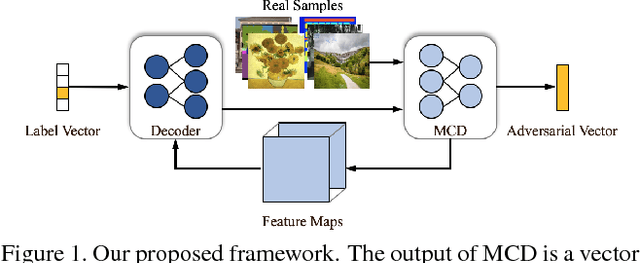
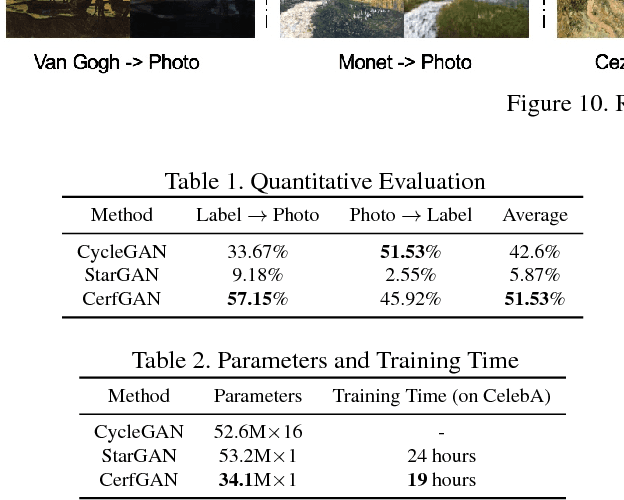
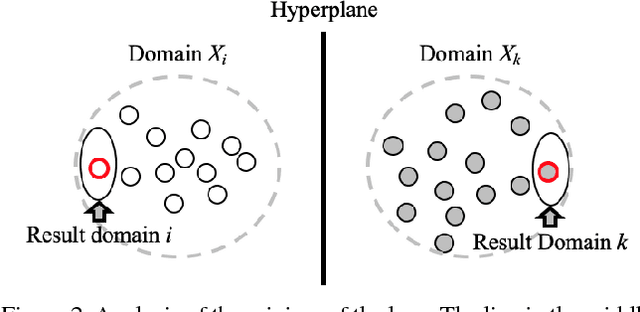
In this paper, we aim at solving the multi-domain image-to-image translation problem by a single GAN-based model in an unsupervised manner. In the field of image-to-image translation, most previous works mainly focus on adopting a generative adversarial network, which contains three parts, i.e., encoder, decoder and discriminator. These three parts are trained to give the encoder and the decoder together as a translator. However, the discriminator that occupies a lot of parameters is abandoned after the training process, which is wasteful of computation and memory. To handle this problem, we integrate the discriminator and the encoder of the traditional framework into a single network, where the decoder in our framework translates the information encoded by the discriminator to the target image. As a result, our framework only contains two parts, i.e., decoder and discriminator, which effectively reduces the number of the parameters of the network and achieves more effective training. Then, we expand the traditional binary-class discriminator to the multi-classes discriminator, which solves the multi-domain image-to-image translation problem in traditional settings. At last, we propose the label encoder to transform the label vector to high-dimension representation automatically rather than designing a one-hot vector manually. We performed extensive experiments on many image-to-image translation tasks including style transfer, season transfer, face hallucination, etc. A unified model was trained to translate images sampled from 14 considerable different domains and the comparisons to several recently-proposed approaches demonstrate the superiority and novelty of our framework.
Mutually improved endoscopic image synthesis and landmark detection in unpaired image-to-image translation
Jul 14, 2021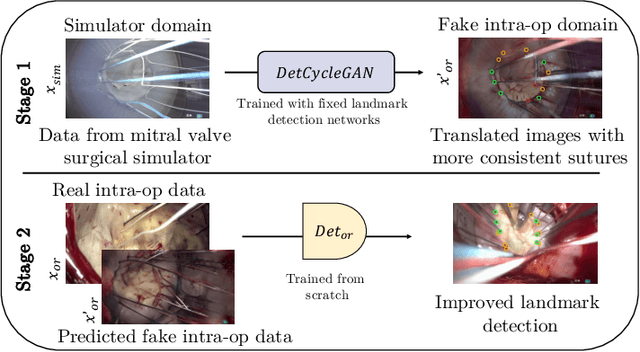
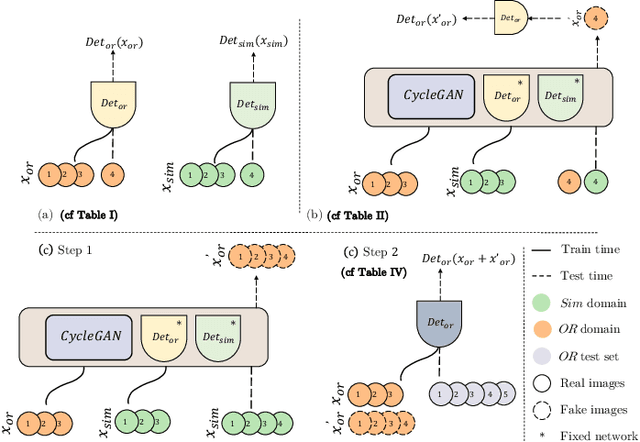
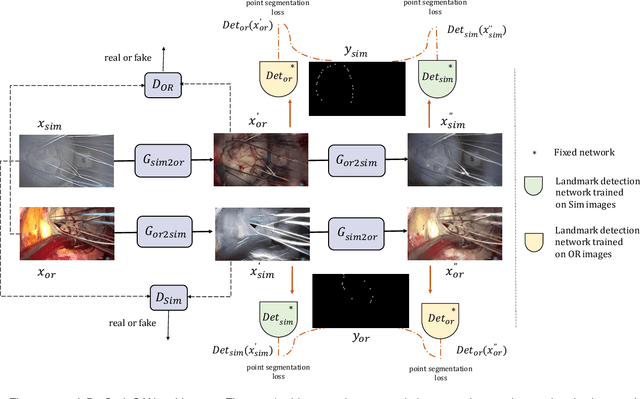
The CycleGAN framework allows for unsupervised image-to-image translation of unpaired data. In a scenario of surgical training on a physical surgical simulator, this method can be used to transform endoscopic images of phantoms into images which more closely resemble the intra-operative appearance of the same surgical target structure. This can be viewed as a novel augmented reality approach, which we coined Hyperrealism in previous work. In this use case, it is of paramount importance to display objects like needles, sutures or instruments consistent in both domains while altering the style to a more tissue-like appearance. Segmentation of these objects would allow for a direct transfer, however, contouring of these, partly tiny and thin foreground objects is cumbersome and perhaps inaccurate. Instead, we propose to use landmark detection on the points when sutures pass into the tissue. This objective is directly incorporated into a CycleGAN framework by treating the performance of pre-trained detector models as an additional optimization goal. We show that a task defined on these sparse landmark labels improves consistency of synthesis by the generator network in both domains. Comparing a baseline CycleGAN architecture to our proposed extension (DetCycleGAN), mean precision (PPV) improved by +61.32, mean sensitivity (TPR) by +37.91, and mean F1 score by +0.4743. Furthermore, it could be shown that by dataset fusion, generated intra-operative images can be leveraged as additional training data for the detection network itself. The data is released within the scope of the AdaptOR MICCAI Challenge 2021 at https://adaptor2021.github.io/, and code at https://github.com/Cardio-AI/detcyclegan_pytorch.
Tunable Convolutions with Parametric Multi-Loss Optimization
Apr 03, 2023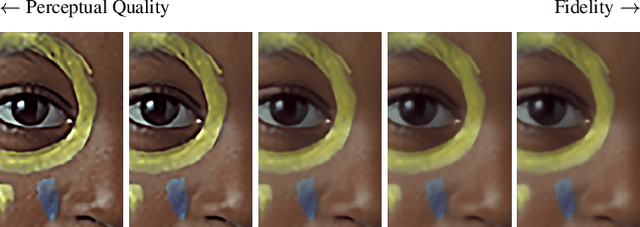
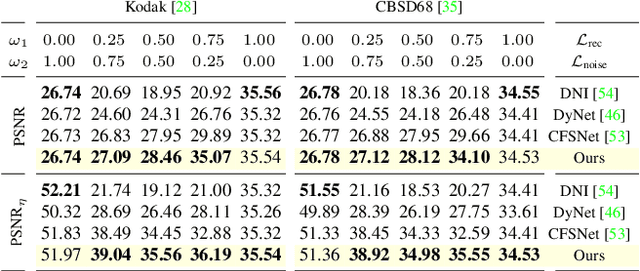
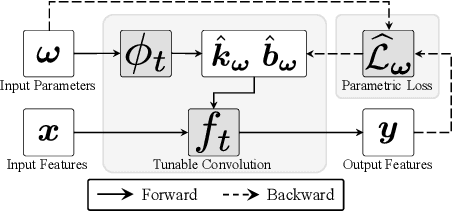
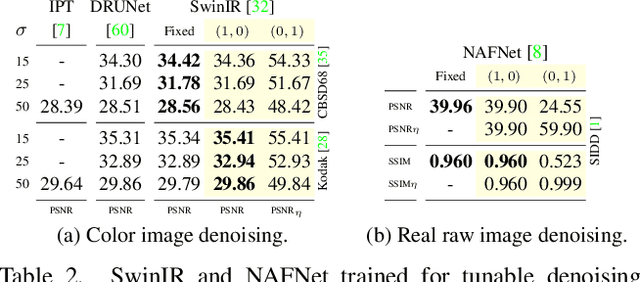
Behavior of neural networks is irremediably determined by the specific loss and data used during training. However it is often desirable to tune the model at inference time based on external factors such as preferences of the user or dynamic characteristics of the data. This is especially important to balance the perception-distortion trade-off of ill-posed image-to-image translation tasks. In this work, we propose to optimize a parametric tunable convolutional layer, which includes a number of different kernels, using a parametric multi-loss, which includes an equal number of objectives. Our key insight is to use a shared set of parameters to dynamically interpolate both the objectives and the kernels. During training, these parameters are sampled at random to explicitly optimize all possible combinations of objectives and consequently disentangle their effect into the corresponding kernels. During inference, these parameters become interactive inputs of the model hence enabling reliable and consistent control over the model behavior. Extensive experimental results demonstrate that our tunable convolutions effectively work as a drop-in replacement for traditional convolutions in existing neural networks at virtually no extra computational cost, outperforming state-of-the-art control strategies in a wide range of applications; including image denoising, deblurring, super-resolution, and style transfer.
Multi-mapping Image-to-Image Translation via Learning Disentanglement
Sep 17, 2019
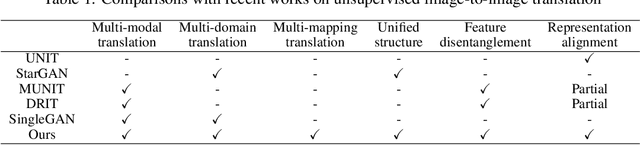

Recent advances of image-to-image translation focus on learning the one-to-many mapping from two aspects: multi-modal translation and multi-domain translation. However, the existing methods only consider one of the two perspectives, which makes them unable to solve each other's problem. To address this issue, we propose a novel unified model, which bridges these two objectives. First, we disentangle the input images into the latent representations by an encoder-decoder architecture with a conditional adversarial training in the feature space. Then, we encourage the generator to learn multi-mappings by a random cross-domain translation. As a result, we can manipulate different parts of the latent representations to perform multi-modal and multi-domain translations simultaneously. Experiments demonstrate that our method outperforms state-of-the-art methods.
An Optimized Architecture for Unpaired Image-to-Image Translation
Feb 13, 2018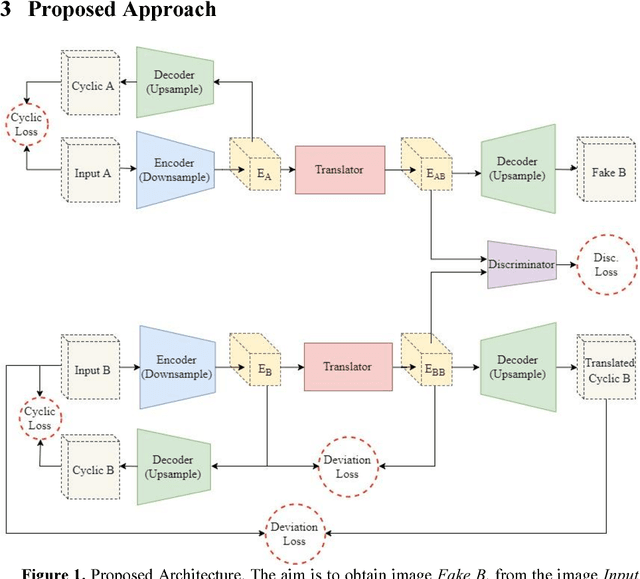

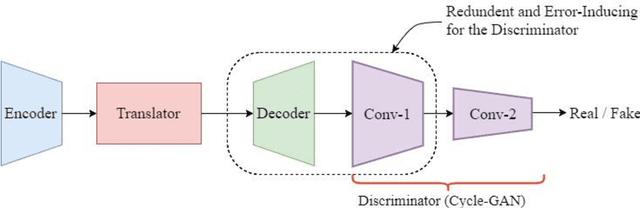
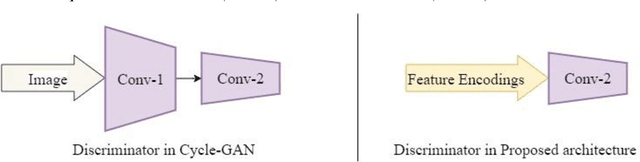
Unpaired Image-to-Image translation aims to convert the image from one domain (input domain A) to another domain (target domain B), without providing paired examples for the training. The state-of-the-art, Cycle-GAN demonstrated the power of Generative Adversarial Networks with Cycle-Consistency Loss. While its results are promising, there is scope for optimization in the training process. This paper introduces a new neural network architecture, which only learns the translation from domain A to B and eliminates the need for reverse mapping (B to A), by introducing a new Deviation-loss term. Furthermore, few other improvements to the Cycle-GAN are found and utilized in this new architecture, contributing to significantly lesser training duration.
Harmonic Unpaired Image-to-image Translation
Feb 26, 2019
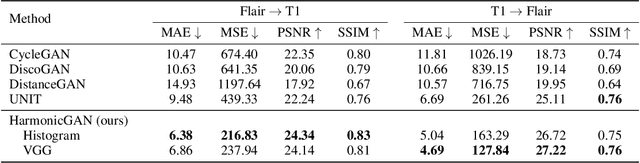
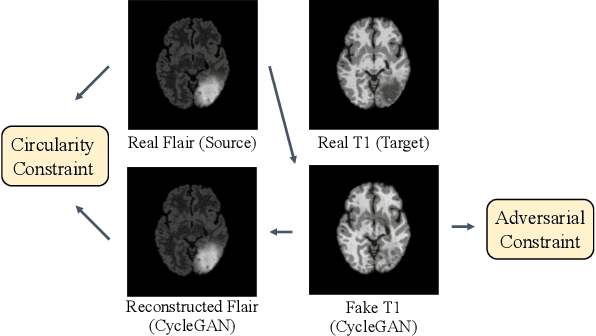
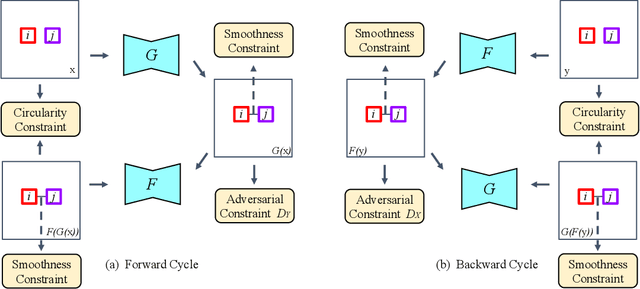
The recent direction of unpaired image-to-image translation is on one hand very exciting as it alleviates the big burden in obtaining label-intensive pixel-to-pixel supervision, but it is on the other hand not fully satisfactory due to the presence of artifacts and degenerated transformations. In this paper, we take a manifold view of the problem by introducing a smoothness term over the sample graph to attain harmonic functions to enforce consistent mappings during the translation. We develop HarmonicGAN to learn bi-directional translations between the source and the target domains. With the help of similarity-consistency, the inherent self-consistency property of samples can be maintained. Distance metrics defined on two types of features including histogram and CNN are exploited. Under an identical problem setting as CycleGAN, without additional manual inputs and only at a small training-time cost, HarmonicGAN demonstrates a significant qualitative and quantitative improvement over the state of the art, as well as improved interpretability. We show experimental results in a number of applications including medical imaging, object transfiguration, and semantic labeling. We outperform the competing methods in all tasks, and for a medical imaging task in particular our method turns CycleGAN from a failure to a success, halving the mean-squared error, and generating images that radiologists prefer over competing methods in 95% of cases.