 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Tunable Convolutions with Parametric Multi-Loss Optimization
Apr 03, 2023
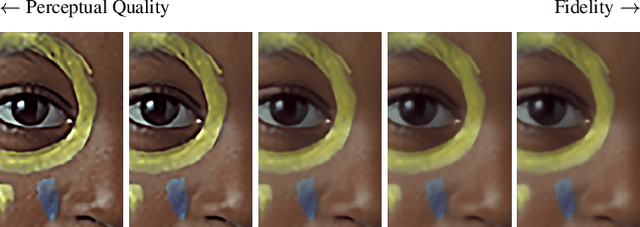
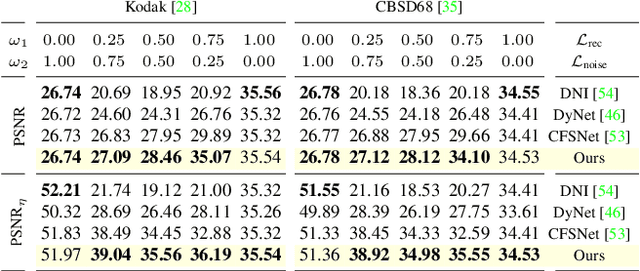
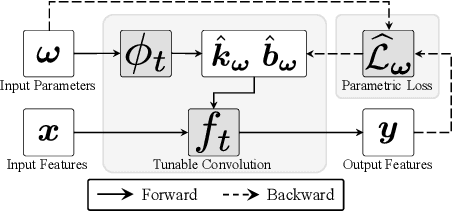
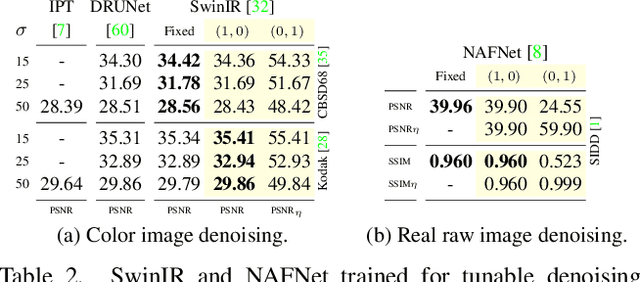
Behavior of neural networks is irremediably determined by the specific loss and data used during training. However it is often desirable to tune the model at inference time based on external factors such as preferences of the user or dynamic characteristics of the data. This is especially important to balance the perception-distortion trade-off of ill-posed image-to-image translation tasks. In this work, we propose to optimize a parametric tunable convolutional layer, which includes a number of different kernels, using a parametric multi-loss, which includes an equal number of objectives. Our key insight is to use a shared set of parameters to dynamically interpolate both the objectives and the kernels. During training, these parameters are sampled at random to explicitly optimize all possible combinations of objectives and consequently disentangle their effect into the corresponding kernels. During inference, these parameters become interactive inputs of the model hence enabling reliable and consistent control over the model behavior. Extensive experimental results demonstrate that our tunable convolutions effectively work as a drop-in replacement for traditional convolutions in existing neural networks at virtually no extra computational cost, outperforming state-of-the-art control strategies in a wide range of applications; including image denoising, deblurring, super-resolution, and style transfer.
ZstGAN: An Adversarial Approach for Unsupervised Zero-Shot Image-to-Image Translation
Jun 01, 2019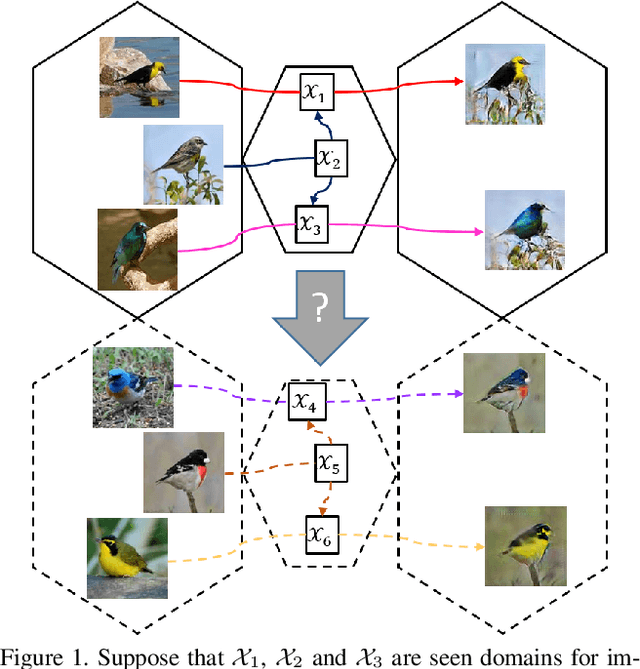
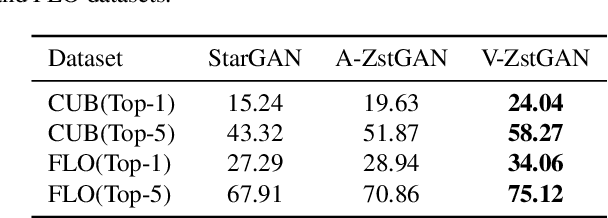
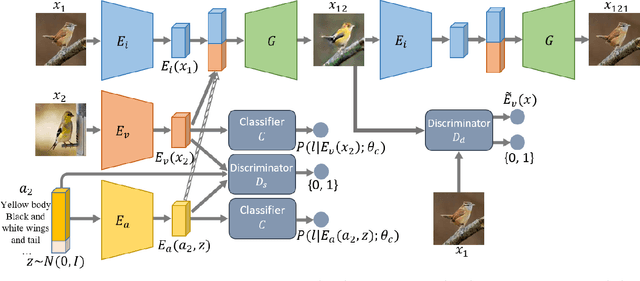
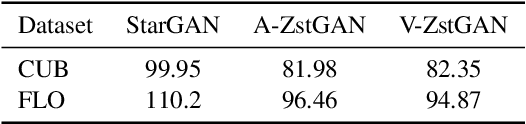
Image-to-image translation models have shown remarkable ability on transferring images among different domains. Most of existing work follows the setting that the source domain and target domain keep the same at training and inference phases, which cannot be generalized to the scenarios for translating an image from an unseen domain to an another unseen domain. In this work, we propose the Unsupervised Zero-Shot Image-to-image Translation (UZSIT) problem, which aims to learn a model that can transfer translation knowledge from seen domains to unseen domains. Accordingly, we propose a framework called ZstGAN: By introducing an adversarial training scheme, ZstGAN learns to model each domain with domain-specific feature distribution that is semantically consistent on vision and attribute modalities. Then the domain-invariant features are disentangled with an shared encoder for image generation. We carry out extensive experiments on CUB and FLO datasets, and the results demonstrate the effectiveness of proposed method on UZSIT task. Moreover, ZstGAN shows significant accuracy improvements over state-of-the-art zero-shot learning methods on CUB and FLO.
ReMix: Towards Image-to-Image Translation with Limited Data
Mar 31, 2021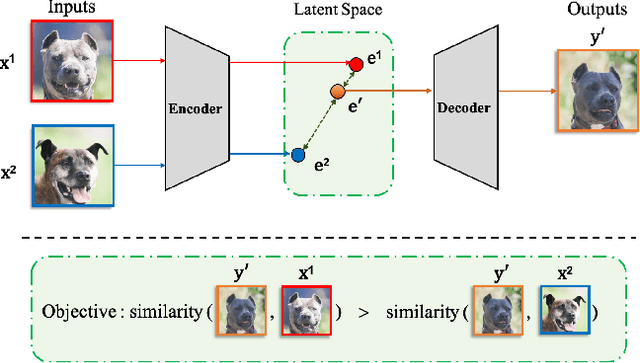
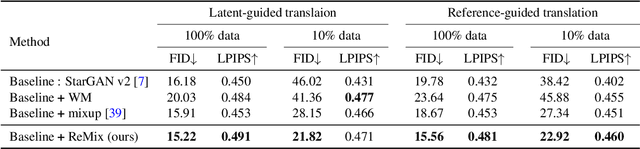
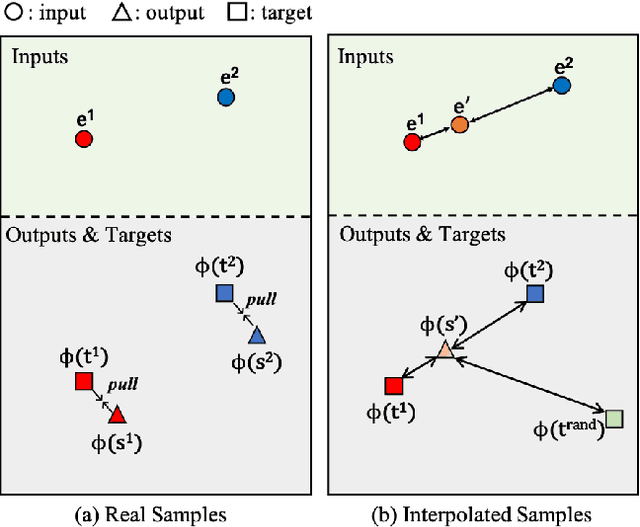
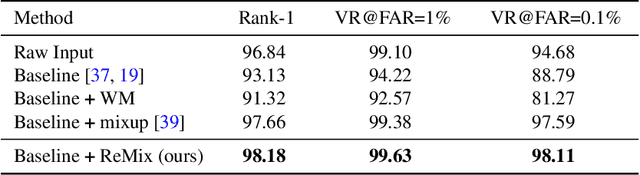
Image-to-image (I2I) translation methods based on generative adversarial networks (GANs) typically suffer from overfitting when limited training data is available. In this work, we propose a data augmentation method (ReMix) to tackle this issue. We interpolate training samples at the feature level and propose a novel content loss based on the perceptual relations among samples. The generator learns to translate the in-between samples rather than memorizing the training set, and thereby forces the discriminator to generalize. The proposed approach effectively reduces the ambiguity of generation and renders content-preserving results. The ReMix method can be easily incorporated into existing GAN models with minor modifications. Experimental results on numerous tasks demonstrate that GAN models equipped with the ReMix method achieve significant improvements.
Reversible GANs for Memory-efficient Image-to-Image Translation
Feb 07, 2019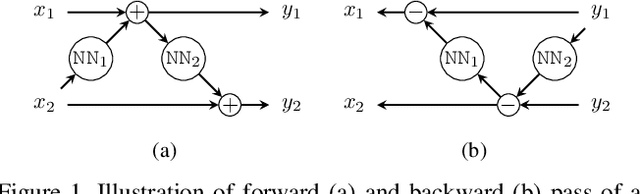
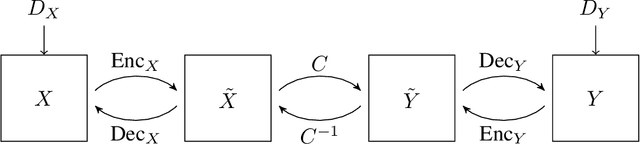

The Pix2pix and CycleGAN losses have vastly improved the qualitative and quantitative visual quality of results in image-to-image translation tasks. We extend this framework by exploring approximately invertible architectures which are well suited to these losses. These architectures are approximately invertible by design and thus partially satisfy cycle-consistency before training even begins. Furthermore, since invertible architectures have constant memory complexity in depth, these models can be built arbitrarily deep. We are able to demonstrate superior quantitative output on the Cityscapes and Maps datasets at near constant memory budget.
GANtruth - an unpaired image-to-image translation method for driving scenarios
Nov 26, 2018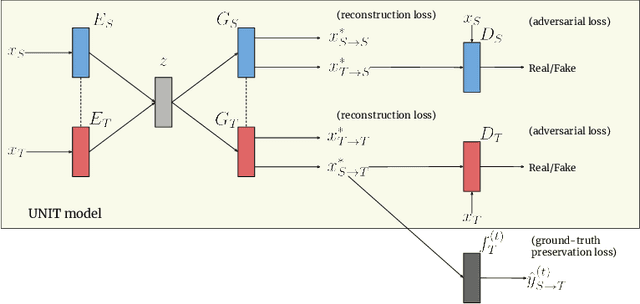
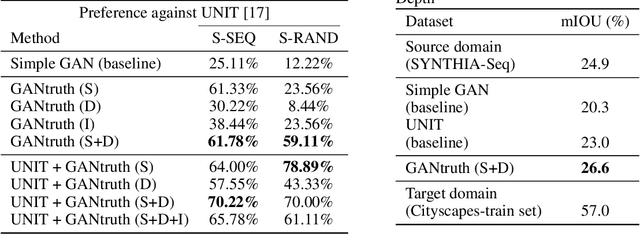


Synthetic image translation has significant potentials in autonomous transportation systems. That is due to the expense of data collection and annotation as well as the unmanageable diversity of real-words situations. The main issue with unpaired image-to-image translation is the ill-posed nature of the problem. In this work, we propose a novel method for constraining the output space of unpaired image-to-image translation. We make the assumption that the environment of the source domain is known (e.g. synthetically generated), and we propose to explicitly enforce preservation of the ground-truth labels on the translated images. We experiment on preserving ground-truth information such as semantic segmentation, disparity, and instance segmentation. We show significant evidence that our method achieves improved performance over the state-of-the-art model of UNIT for translating images from SYNTHIA to Cityscapes. The generated images are perceived as more realistic in human surveys and outperforms UNIT when used in a domain adaptation scenario for semantic segmentation.
Lipschitz Regularized CycleGAN for Improving Semantic Robustness in Unpaired Image-to-image Translation
Dec 09, 2020
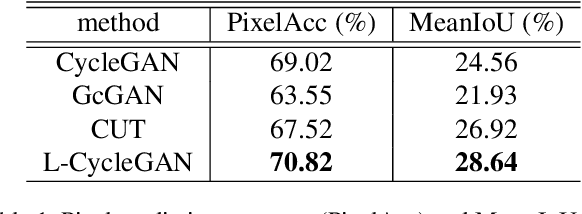

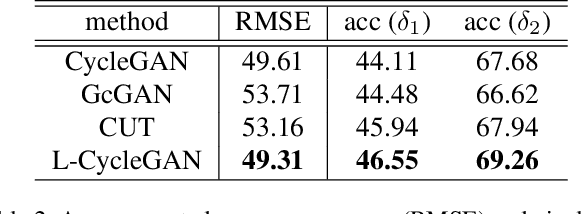
For unpaired image-to-image translation tasks, GAN-based approaches are susceptible to semantic flipping, i.e., contents are not preserved consistently. We argue that this is due to (1) the difference in semantic statistics between source and target domains and (2) the learned generators being non-robust. In this paper, we proposed a novel approach, Lipschitz regularized CycleGAN, for improving semantic robustness and thus alleviating the semantic flipping issue. During training, we add a gradient penalty loss to the generators, which encourages semantically consistent transformations. We evaluate our approach on multiple common datasets and compare with several existing GAN-based methods. Both quantitative and visual results suggest the effectiveness and advantage of our approach in producing robust transformations with fewer semantic flipping.
Unsupervised Detection of Cancerous Regions in Histology Imagery using Image-to-Image Translation
Apr 28, 2021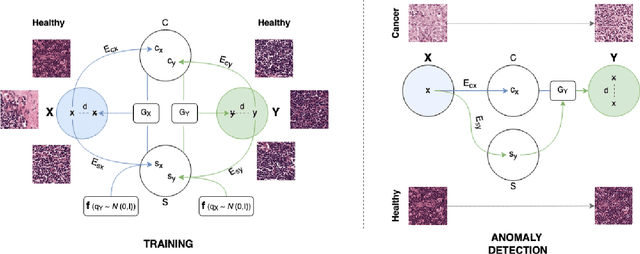
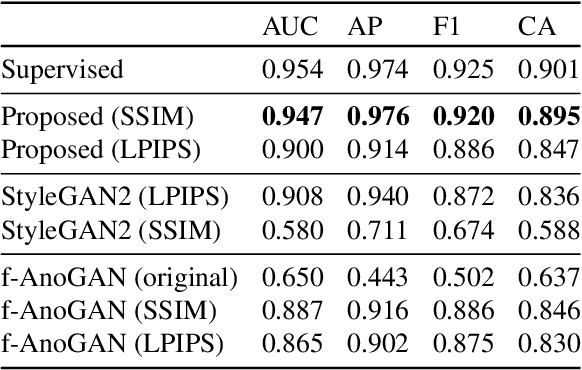
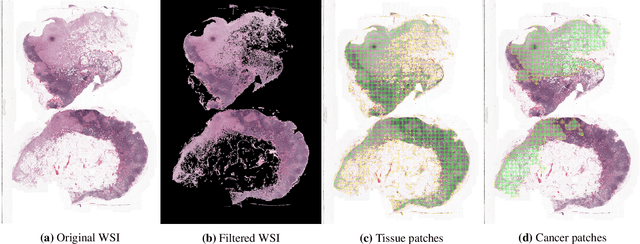

Detection of visual anomalies refers to the problem of finding patterns in different imaging data that do not conform to the expected visual appearance and is a widely studied problem in different domains. Due to the nature of anomaly occurrences and underlying generating processes, it is hard to characterize them and obtain labeled data. Obtaining labeled data is especially difficult in biomedical applications, where only trained domain experts can provide labels, which often come in large diversity and complexity. Recently presented approaches for unsupervised detection of visual anomalies approaches omit the need for labeled data and demonstrate promising results in domains, where anomalous samples significantly deviate from the normal appearance. Despite promising results, the performance of such approaches still lags behind supervised approaches and does not provide a one-fits-all solution. In this work, we present an image-to-image translation-based framework that significantly surpasses the performance of existing unsupervised methods and approaches the performance of supervised methods in a challenging domain of cancerous region detection in histology imagery.
Boosting segmentation with weak supervision from image-to-image translation
Apr 04, 2019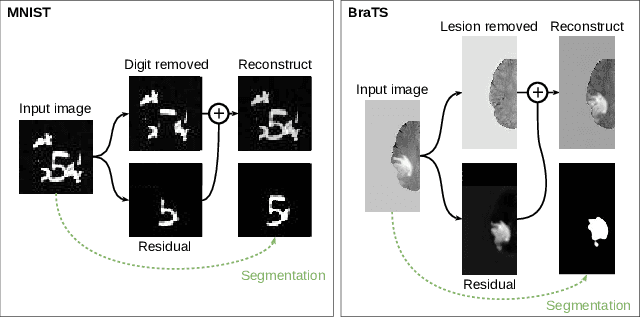

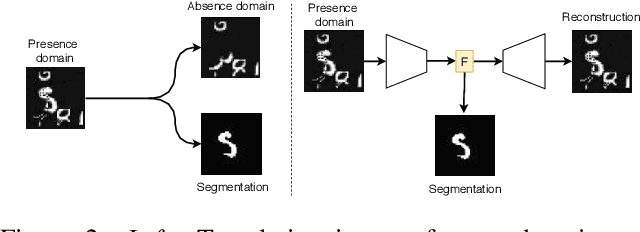
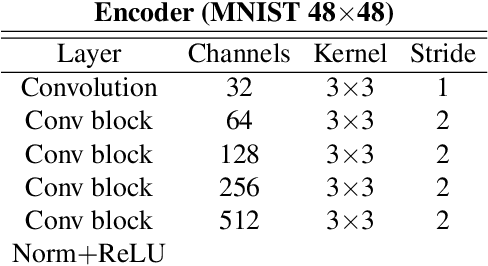
In many cases, especially with medical images, it is prohibitively challenging to produce a sufficiently large training sample of pixel-level annotations to train deep neural networks for semantic image segmentation. On the other hand, some information is often known about the contents of images. We leverage information on whether an image presents the segmentation target or whether it is absent from the image to improve segmentation performance by augmenting the amount of data usable for model training. Specifically, we propose a semi-supervised framework that employs image-to-image translation between weak labels (e.g., presence vs. absence of cancer), in addition to fully supervised segmentation on some examples. We conjecture that this translation objective is well aligned with the segmentation objective as both require the same disentangling of image variations. Building on prior image-to-image translation work, we re-use the encoder and decoders for translating in either direction between two domains, employing a strategy of selectively decoding domain-specific variations. For presence vs. absence domains, the encoder produces variations that are common to both and those unique to the presence domain. Furthermore, we successfully re-use one of the decoders used in translation for segmentation. We validate the proposed method on synthetic tasks of varying difficulty as well as on the real task of brain tumor segmentation in magnetic resonance images, where we show significant improvements over standard semi-supervised training with autoencoding.
One-Shot Image-to-Image Translation via Part-Global Learning with a Multi-adversarial Framework
May 12, 2019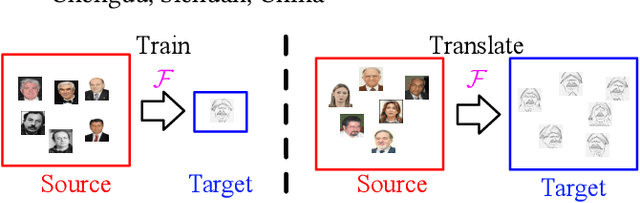
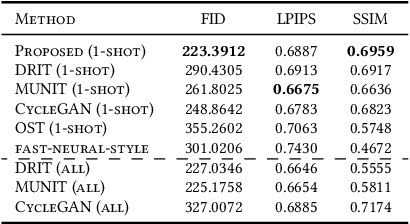
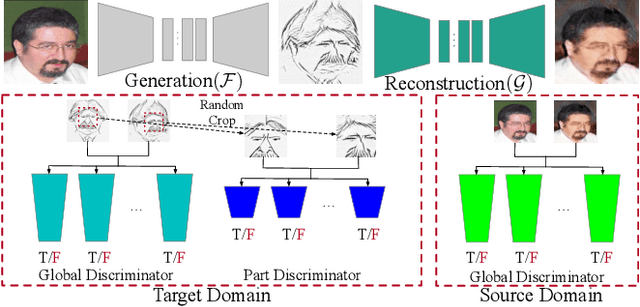
It is well known that humans can learn and recognize objects effectively from several limited image samples. However, learning from just a few images is still a tremendous challenge for existing main-stream deep neural networks. Inspired by analogical reasoning in the human mind, a feasible strategy is to translate the abundant images of a rich source domain to enrich the relevant yet different target domain with insufficient image data. To achieve this goal, we propose a novel, effective multi-adversarial framework (MA) based on part-global learning, which accomplishes one-shot cross-domain image-to-image translation. In specific, we first devise a part-global adversarial training scheme to provide an efficient way for feature extraction and prevent discriminators being over-fitted. Then, a multi-adversarial mechanism is employed to enhance the image-to-image translation ability to unearth the high-level semantic representation. Moreover, a balanced adversarial loss function is presented, which aims to balance the training data and stabilize the training process. Extensive experiments demonstrate that the proposed approach can obtain impressive results on various datasets between two extremely imbalanced image domains and outperform state-of-the-art methods on one-shot image-to-image translation.
Mutually improved endoscopic image synthesis and landmark detection in unpaired image-to-image translation
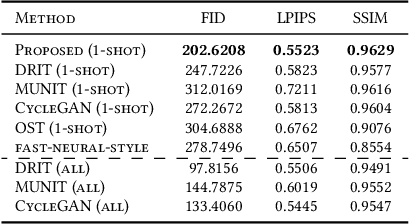
Jul 14, 2021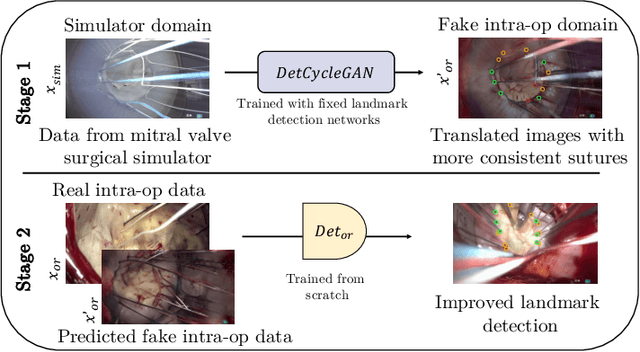
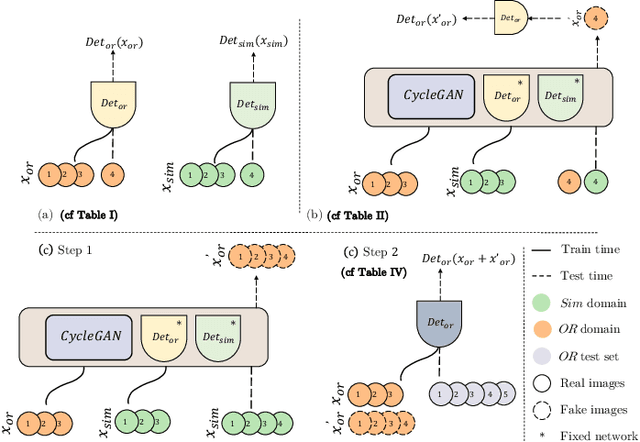
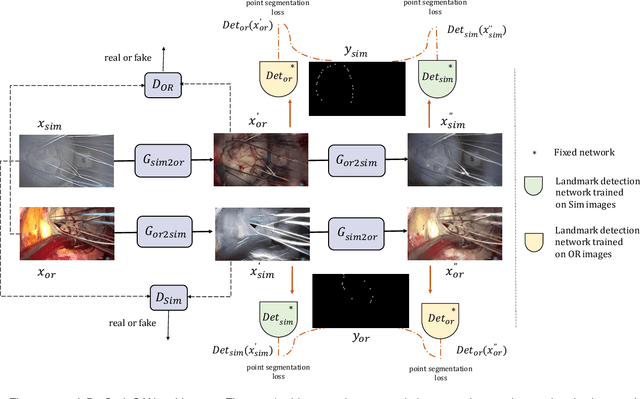
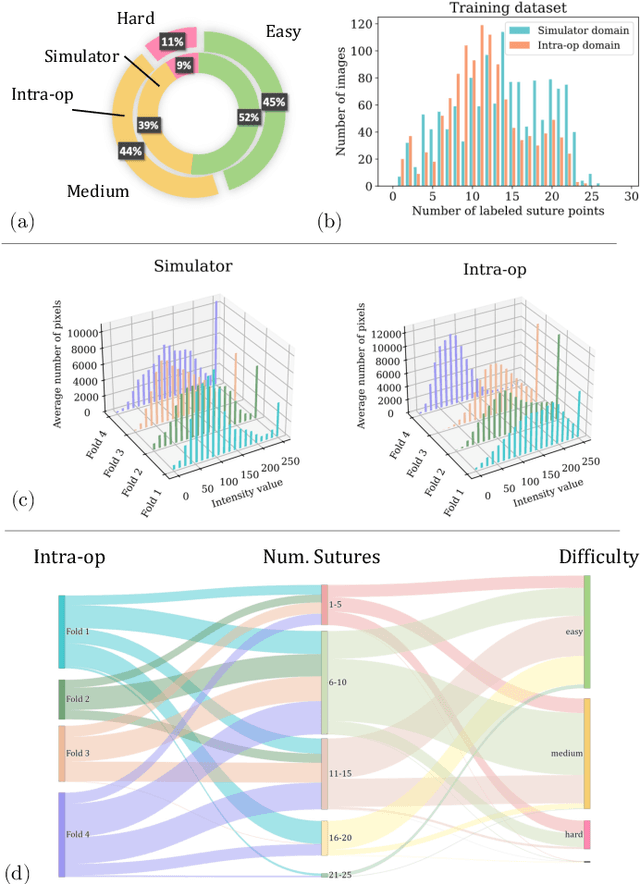
The CycleGAN framework allows for unsupervised image-to-image translation of unpaired data. In a scenario of surgical training on a physical surgical simulator, this method can be used to transform endoscopic images of phantoms into images which more closely resemble the intra-operative appearance of the same surgical target structure. This can be viewed as a novel augmented reality approach, which we coined Hyperrealism in previous work. In this use case, it is of paramount importance to display objects like needles, sutures or instruments consistent in both domains while altering the style to a more tissue-like appearance. Segmentation of these objects would allow for a direct transfer, however, contouring of these, partly tiny and thin foreground objects is cumbersome and perhaps inaccurate. Instead, we propose to use landmark detection on the points when sutures pass into the tissue. This objective is directly incorporated into a CycleGAN framework by treating the performance of pre-trained detector models as an additional optimization goal. We show that a task defined on these sparse landmark labels improves consistency of synthesis by the generator network in both domains. Comparing a baseline CycleGAN architecture to our proposed extension (DetCycleGAN), mean precision (PPV) improved by +61.32, mean sensitivity (TPR) by +37.91, and mean F1 score by +0.4743. Furthermore, it could be shown that by dataset fusion, generated intra-operative images can be leveraged as additional training data for the detection network itself. The data is released within the scope of the AdaptOR MICCAI Challenge 2021 at https://adaptor2021.github.io/, and code at https://github.com/Cardio-AI/detcyclegan_pytorch.