 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Informative Sample Mining Network for Multi-Domain Image-to-Image Translation
Jan 05, 2020
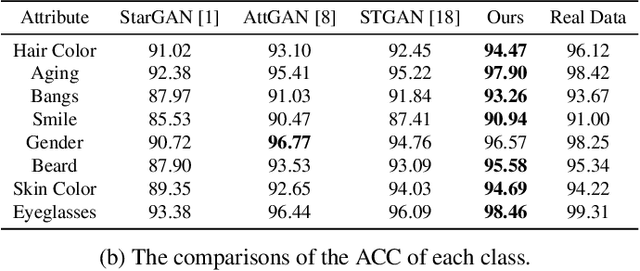
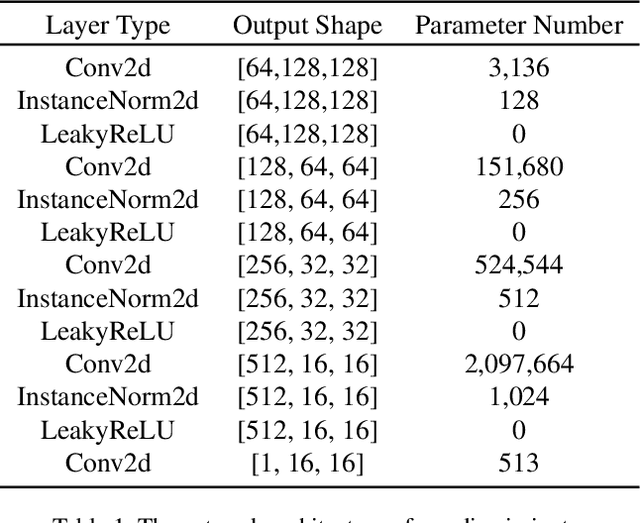

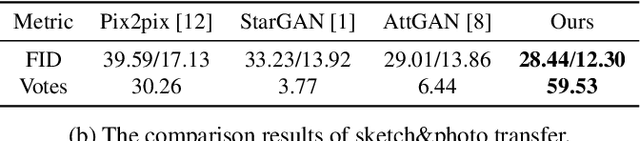
The performance of multi-domain image-to-image translation has been significantly improved by recent progress in deep generative models. Existing approaches can use a unified model to achieve translations between all the visual domains. However, their outcomes are far from satisfying when there are large domain variations. In this paper, we reveal that improving the strategy of sample selection is an effective solution. To select informative samples, we dynamically estimate sample importance during the training of Generative Adversarial Networks, presenting Informative Sample Mining Network. We theoretically analyze the relationship between the sample importance and the prediction of the global optimal discriminator. Then a practical importance estimation function based on general discriminators is derived. In addition, we propose a novel multi-stage sample training scheme to reduce sample hardness while preserving sample informativeness. Extensive experiments on a wide range of specific image-to-image translation tasks are conducted, and the results demonstrate our superiority over current state-of-the-art methods.
High-resolution semantically-consistent image-to-image translation
Sep 13, 2022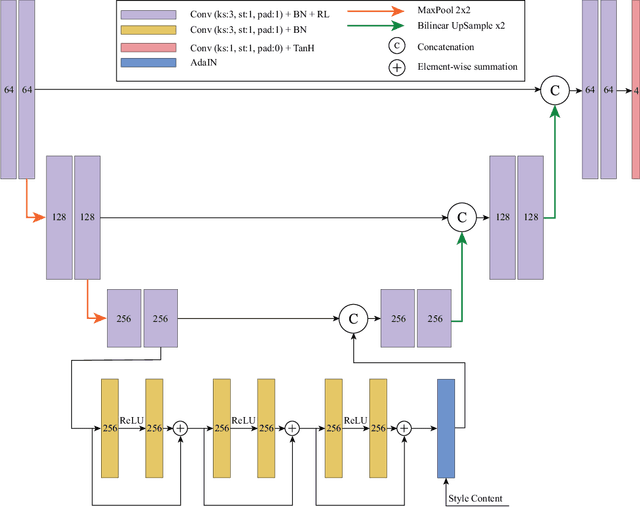
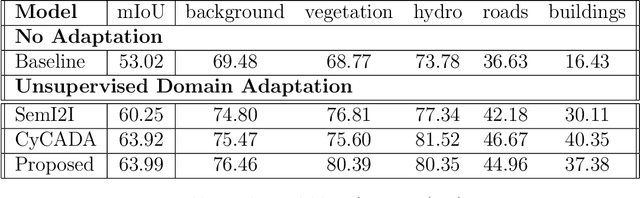
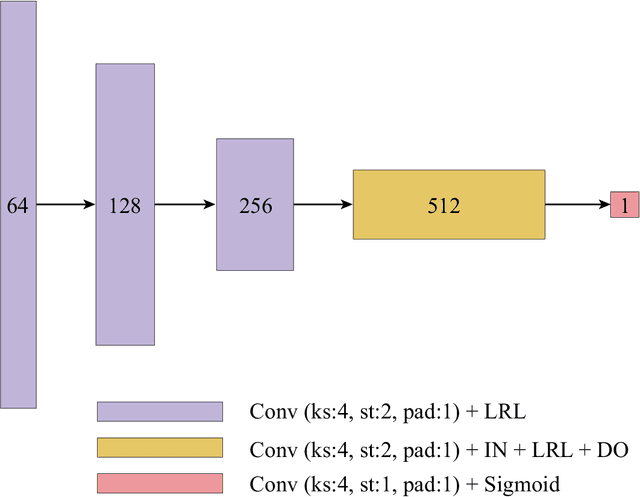
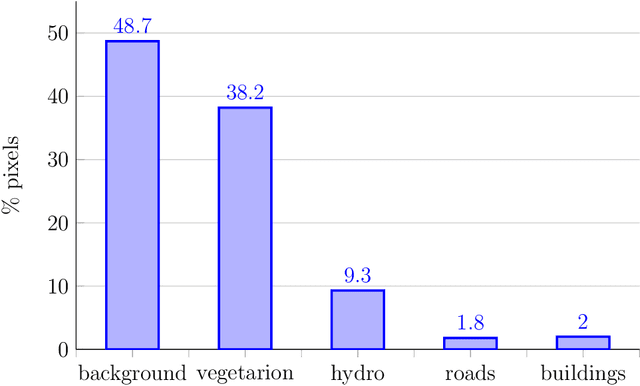
Deep learning has become one of remote sensing scientists' most efficient computer vision tools in recent years. However, the lack of training labels for the remote sensing datasets means that scientists need to solve the domain adaptation problem to narrow the discrepancy between satellite image datasets. As a result, image segmentation models that are then trained, could better generalize and use an existing set of labels instead of requiring new ones. This work proposes an unsupervised domain adaptation model that preserves semantic consistency and per-pixel quality for the images during the style-transferring phase. This paper's major contribution is proposing the improved architecture of the SemI2I model, which significantly boosts the proposed model's performance and makes it competitive with the state-of-the-art CyCADA model. A second contribution is testing the CyCADA model on the remote sensing multi-band datasets such as WorldView-2 and SPOT-6. The proposed model preserves semantic consistency and per-pixel quality for the images during the style-transferring phase. Thus, the semantic segmentation model, trained on the adapted images, shows substantial performance gain compared to the SemI2I model and reaches similar results as the state-of-the-art CyCADA model. The future development of the proposed method could include ecological domain transfer, {\em a priori} evaluation of dataset quality in terms of data distribution, or exploration of the inner architecture of the domain adaptation model.
One-to-one Mapping for Unpaired Image-to-image Translation
Oct 12, 2019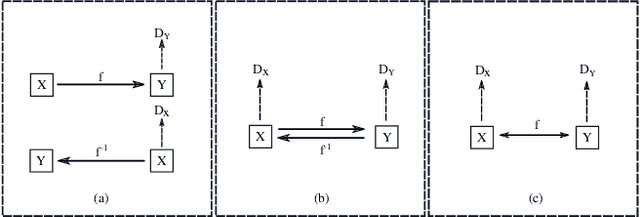



Recently image-to-image translation has attracted significant interests in the literature, starting from the successful use of the generative adversarial network (GAN), to the introduction of cyclic constraint, to extensions to multiple domains. However, in existing approaches, there is no guarantee that the mapping between two image domains is unique or one-to-one. Here we propose a self-inverse network learning approach for unpaired image-to-image translation. Building on top of CycleGAN, we learn a self-inverse function by simply augmenting the training samples by swapping inputs and outputs during training and with separated cycle consistency loss for each mapping direction. The outcome of such learning is a proven one-to-one mapping function. Our extensive experiments on a variety of datasets, including cross-modal medical image synthesis, object transfiguration, and semantic labeling, consistently demonstrate clear improvement over the CycleGAN method both qualitatively and quantitatively. Especially our proposed method reaches the state-of-the-art result on the cityscapes benchmark dataset for the label to photo unpaired directional image translation.
Unsupervised Multi-Domain Multimodal Image-to-Image Translation with Explicit Domain-Constrained Disentanglement
Nov 02, 2019
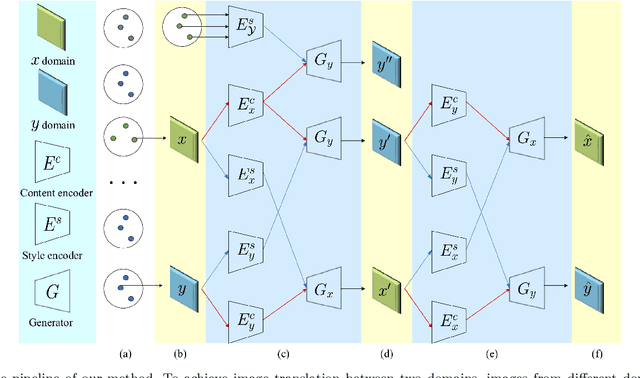
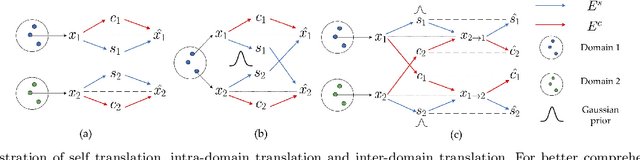
Image-to-image translation has drawn great attention during the past few years. It aims to translate an image in one domain to a given reference image in another domain. Due to its effectiveness and efficiency, many applications can be formulated as image-to-image translation problems. However, three main challenges remain in image-to-image translation: 1) the lack of large amounts of aligned training pairs for different tasks; 2) the ambiguity of multiple possible outputs from a single input image; and 3) the lack of simultaneous training of multiple datasets from different domains within a single network. We also found in experiments that the implicit disentanglement of content and style could lead to unexpect results. In this paper, we propose a unified framework for learning to generate diverse outputs using unpaired training data and allow simultaneous training of multiple datasets from different domains via a single network. Furthermore, we also investigate how to better extract domain supervision information so as to learn better disentangled representations and achieve better image translation. Experiments show that the proposed method outperforms or is comparable with the state-of-the-art methods.
Critical heat flux diagnosis using conditional generative adversarial networks
May 04, 2023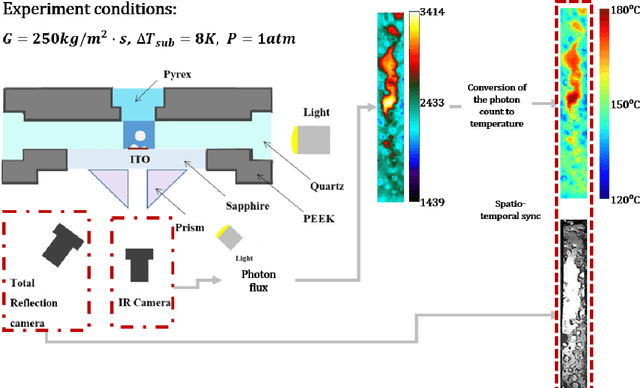
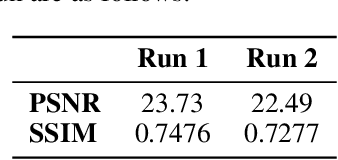

The critical heat flux (CHF) is an essential safety boundary in boiling heat transfer processes employed in high heat flux thermal-hydraulic systems. Identifying CHF is vital for preventing equipment damage and ensuring overall system safety, yet it is challenging due to the complexity of the phenomena. For an in-depth understanding of the complicated phenomena, various methodologies have been devised, but the acquisition of high-resolution data is limited by the substantial resource consumption required. This study presents a data-driven, image-to-image translation method for reconstructing thermal data of a boiling system at CHF using conditional generative adversarial networks (cGANs). The supervised learning process relies on paired images, which include total reflection visualizations and infrared thermometry measurements obtained from flow boiling experiments. Our proposed approach has the potential to not only provide evidence connecting phase interface dynamics with thermal distribution but also to simplify the laborious and time-consuming experimental setup and data-reduction procedures associated with infrared thermal imaging, thereby providing an effective solution for CHF diagnosis.
Neural Style Transfer and Unpaired Image-to-Image Translation to deal with the Domain Shift Problem on Spheroid Segmentation
Dec 16, 2021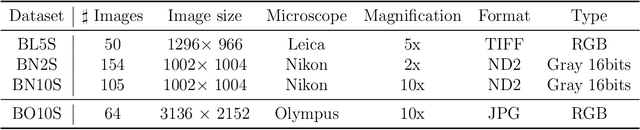
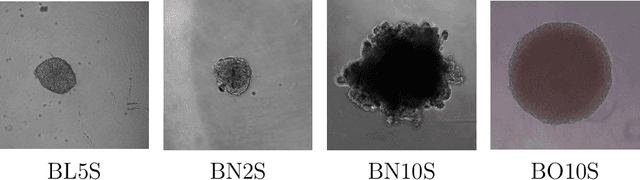

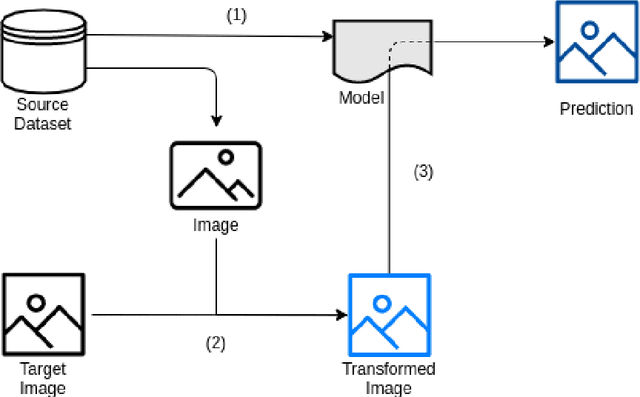
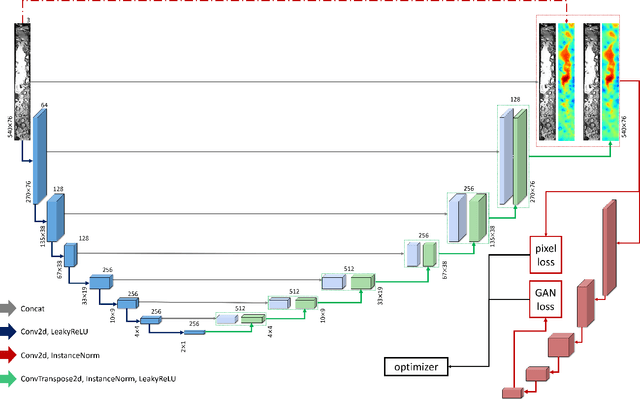
Background and objectives. Domain shift is a generalisation problem of machine learning models that occurs when the data distribution of the training set is different to the data distribution encountered by the model when it is deployed. This is common in the context of biomedical image segmentation due to the variance of experimental conditions, equipment, and capturing settings. In this work, we address this challenge by studying both neural style transfer algorithms and unpaired image-to-image translation methods in the context of the segmentation of tumour spheroids. Methods. We have illustrated the domain shift problem in the context of spheroid segmentation with 4 deep learning segmentation models that achieved an IoU over 97% when tested with images following the training distribution, but whose performance decreased up to an 84\% when applied to images captured under different conditions. In order to deal with this problem, we have explored 3 style transfer algorithms (NST, deep image analogy, and STROTSS), and 6 unpaired image-to-image translations algorithms (CycleGAN, DualGAN, ForkGAN, GANILLA, CUT, and FastCUT). These algorithms have been integrated into a high-level API that facilitates their application to other contexts where the domain-shift problem occurs. Results. We have considerably improved the performance of the 4 segmentation models when applied to images captured under different conditions by using both style transfer and image-to-image translation algorithms. In particular, there are 2 style transfer algorithms (NST and deep image analogy) and 1 unpaired image-to-image translations algorithm (CycleGAN) that improve the IoU of the models in a range from 0.24 to 76.07. Therefore, reaching a similar performance to the one obtained with the models are applied to images following the training distribution.
Multi-Channel Attention Selection GANs for Guided Image-to-Image Translation
Feb 03, 2020

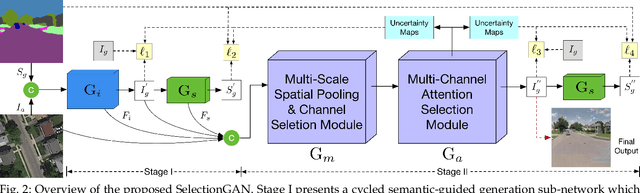
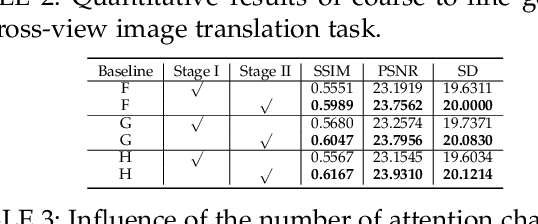
We propose a novel model named Multi-Channel Attention Selection Generative Adversarial Network (SelectionGAN) for guided image-to-image translation, where we translate an input image into another while respecting an external semantic guidance. The proposed SelectionGAN explicitly utilizes the semantic guidance information and consists of two stages. In the first stage, the input image and the conditional semantic guidance are fed into a cycled semantic-guided generation network to produce initial coarse results. In the second stage, we refine the initial results by using the proposed multi-scale spatial pooling \& channel selection module and the multi-channel attention selection module. Moreover, uncertainty maps automatically learned from attention maps are used to guide the pixel loss for better network optimization. Exhaustive experiments on four challenging guided image-to-image translation tasks (face, hand, body and street view) demonstrate that our SelectionGAN is able to generate significantly better results than the state-of-the-art methods. Meanwhile, the proposed framework and modules are unified solutions and can be applied to solve other generation tasks, such as semantic image synthesis. The code is available at https://github.com/Ha0Tang/SelectionGAN.
Multi-Domain Image-to-Image Translation with Adaptive Inference Graph
Jan 11, 2021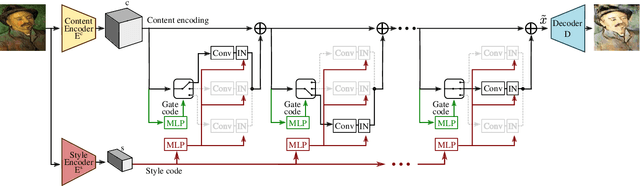



In this work, we address the problem of multi-domain image-to-image translation with particular attention paid to computational cost. In particular, current state of the art models require a large and deep model in order to handle the visual diversity of multiple domains. In a context of limited computational resources, increasing the network size may not be possible. Therefore, we propose to increase the network capacity by using an adaptive graph structure. At inference time, the network estimates its own graph by selecting specific sub-networks. Sub-network selection is implemented using Gumbel-Softmax in order to allow end-to-end training. This approach leads to an adjustable increase in number of parameters while preserving an almost constant computational cost. Our evaluation on two publicly available datasets of facial and painting images shows that our adaptive strategy generates better images with fewer artifacts than literature methods
Learning image-to-image translation using paired and unpaired training samples
May 08, 2018
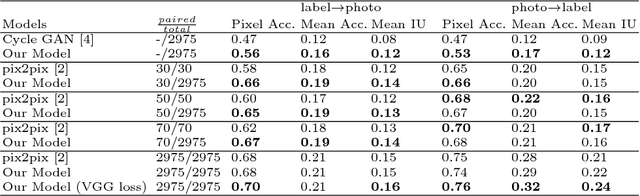
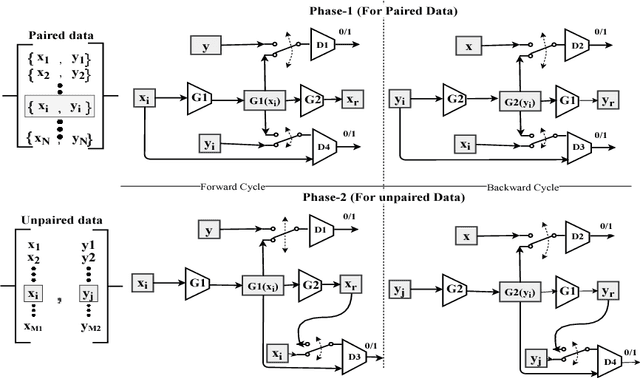

Image-to-image translation is a general name for a task where an image from one domain is converted to a corresponding image in another domain, given sufficient training data. Traditionally different approaches have been proposed depending on whether aligned image pairs or two sets of (unaligned) examples from both domains are available for training. While paired training samples might be difficult to obtain, the unpaired setup leads to a highly under-constrained problem and inferior results. In this paper, we propose a new general purpose image-to-image translation model that is able to utilize both paired and unpaired training data simultaneously. We compare our method with two strong baselines and obtain both qualitatively and quantitatively improved results. Our model outperforms the baselines also in the case of purely paired and unpaired training data. To our knowledge, this is the first work to consider such hybrid setup in image-to-image translation.
Learning Unsupervised Cross-domain Image-to-Image Translation Using a Shared Discriminator
Feb 09, 2021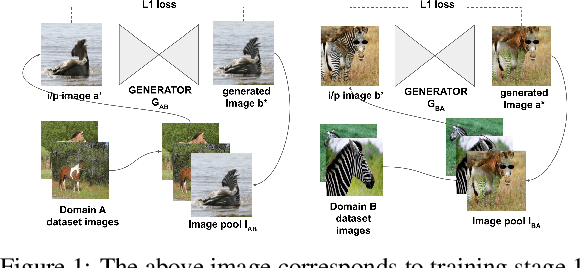

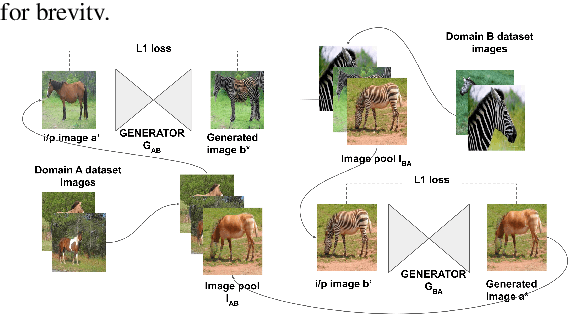
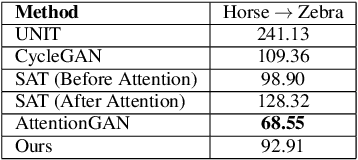
Unsupervised image-to-image translation is used to transform images from a source domain to generate images in a target domain without using source-target image pairs. Promising results have been obtained for this problem in an adversarial setting using two independent GANs and attention mechanisms. We propose a new method that uses a single shared discriminator between the two GANs, which improves the overall efficacy. We assess the qualitative and quantitative results on image transfiguration, a cross-domain translation task, in a setting where the target domain shares similar semantics to the source domain. Our results indicate that even without adding attention mechanisms, our method performs at par with attention-based methods and generates images of comparable quality.