 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Image-to-image Translation as a Unique Source of Knowledge
Dec 09, 2021
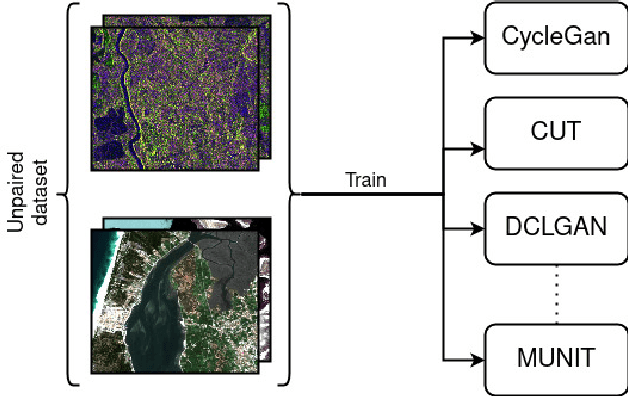
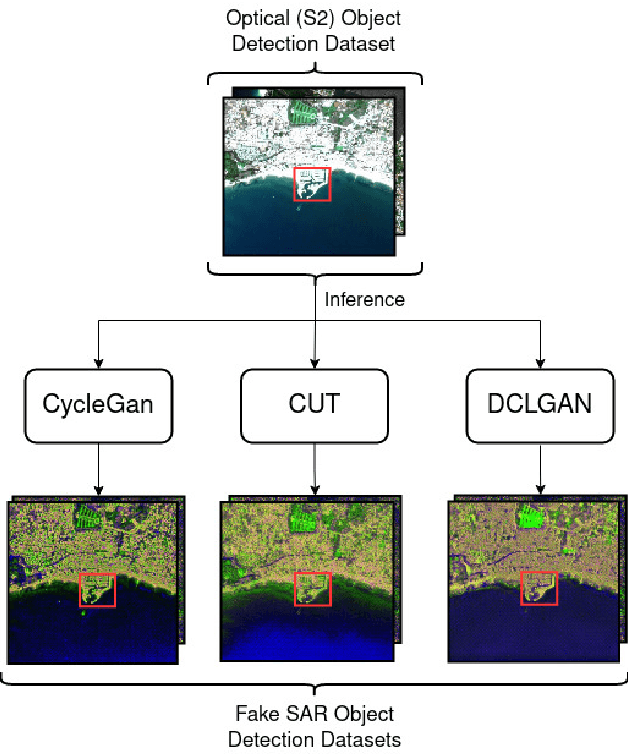
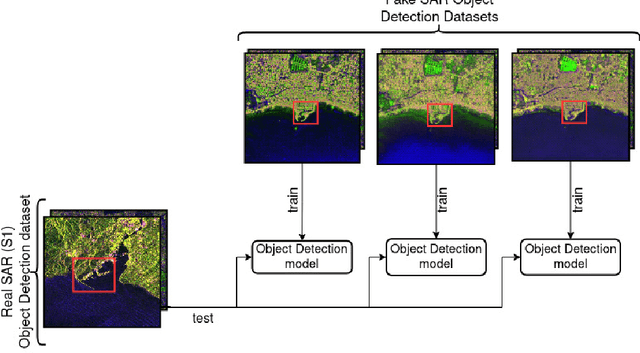
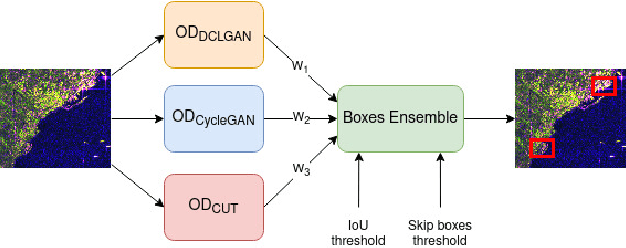
Image-to-image (I2I) translation is an established way of translating data from one domain to another but the usability of the translated images in the target domain when working with such dissimilar domains as the SAR/optical satellite imagery ones and how much of the origin domain is translated to the target domain is still not clear enough. This article address this by performing translations of labelled datasets from the optical domain to the SAR domain with different I2I algorithms from the state-of-the-art, learning from transferred features in the destination domain and evaluating later how much from the original dataset was transferred. Added to this, stacking is proposed as a way of combining the knowledge learned from the different I2I translations and evaluated against single models.
Implicit Pairs for Boosting Unpaired Image-to-Image Translation
Apr 15, 2019
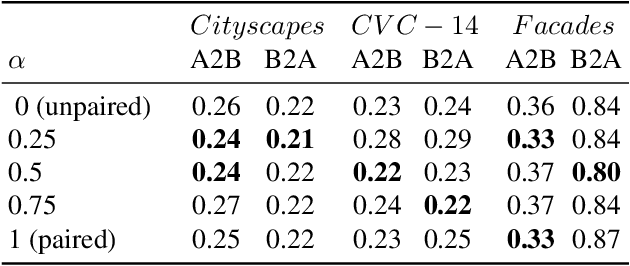
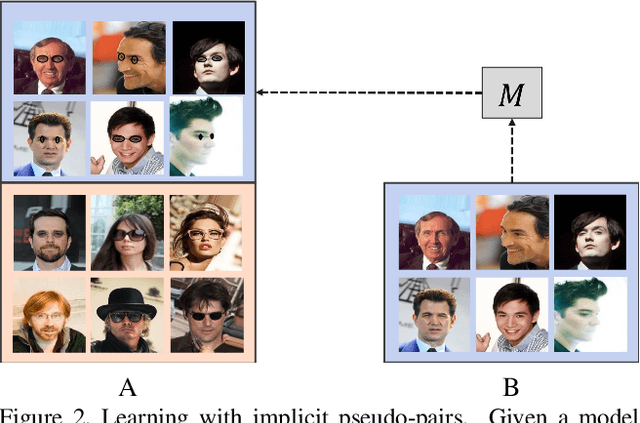
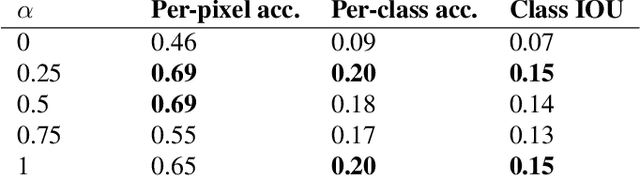
In image-to-image translation the goal is to learn a mapping from one image domain to another. Supervised approaches learn the mapping from paired samples. However, collecting large sets of image pairs is often prohibitively expensive or infeasible. In our work, we show that even training on the pairs implicitly, boosts the performance of unsupervised techniques by over 14% across several measurements. We illustrate that the injection of implicit pairs into unpaired sets strengthens the mapping between the two domains and improves the compatibility of their distributions. Furthermore, we show that for this purpose the implicit pairs can be pseudo-pairs, i.e., paired samples which only approximate a real pair. We demonstrate the effect of the approximated implicit samples on image-to-image translation problems, where such pseudo-pairs can be synthesized in one direction, but not in the other. We further show that pseudo-pairs are significantly more effective as implicit pairs in an unpaired setting, than directly using them explicitly in a paired setting.
Adaptive Gradient Balancing for UndersampledMRI Reconstruction and Image-to-Image Translation
Apr 05, 2021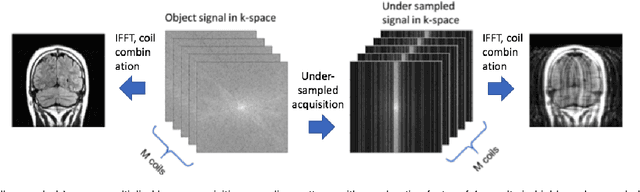
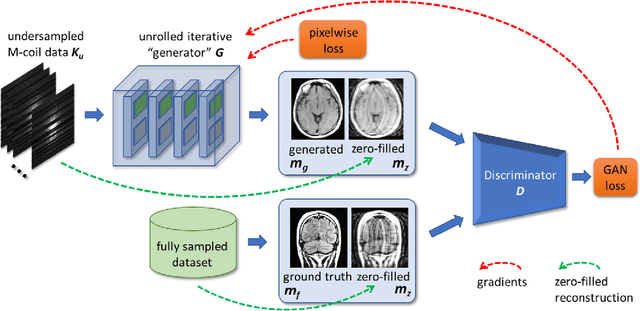
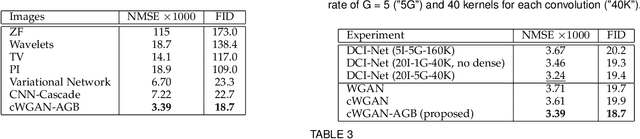
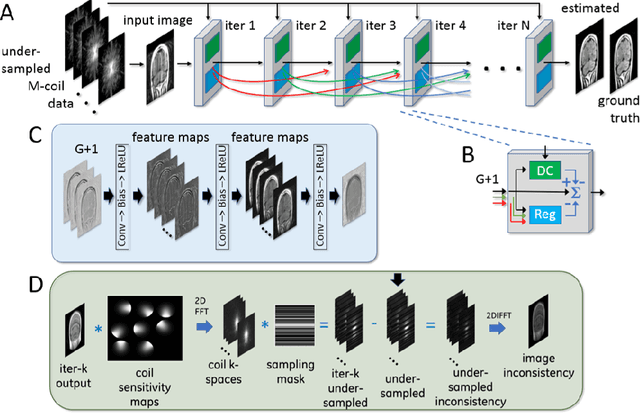
Recent accelerated MRI reconstruction models have used Deep Neural Networks (DNNs) to reconstruct relatively high-quality images from highly undersampled k-space data, enabling much faster MRI scanning. However, these techniques sometimes struggle to reconstruct sharp images that preserve fine detail while maintaining a natural appearance. In this work, we enhance the image quality by using a Conditional Wasserstein Generative Adversarial Network combined with a novel Adaptive Gradient Balancing (AGB) technique that automates the process of combining the adversarial and pixel-wise terms and streamlines hyperparameter tuning. In addition, we introduce a Densely Connected Iterative Network, which is an undersampled MRI reconstruction network that utilizes dense connections. In MRI, our method minimizes artifacts, while maintaining a high-quality reconstruction that produces sharper images than other techniques. To demonstrate the general nature of our method, it is further evaluated on a battery of image-to-image translation experiments, demonstrating an ability to recover from sub-optimal weighting in multi-term adversarial training.
Single Image LDR to HDR Conversion using Conditional Diffusion
Jul 06, 2023
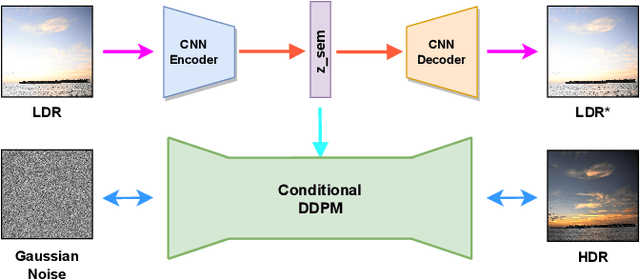

Digital imaging aims to replicate realistic scenes, but Low Dynamic Range (LDR) cameras cannot represent the wide dynamic range of real scenes, resulting in under-/overexposed images. This paper presents a deep learning-based approach for recovering intricate details from shadows and highlights while reconstructing High Dynamic Range (HDR) images. We formulate the problem as an image-to-image (I2I) translation task and propose a conditional Denoising Diffusion Probabilistic Model (DDPM) based framework using classifier-free guidance. We incorporate a deep CNN-based autoencoder in our proposed framework to enhance the quality of the latent representation of the input LDR image used for conditioning. Moreover, we introduce a new loss function for LDR-HDR translation tasks, termed Exposure Loss. This loss helps direct gradients in the opposite direction of the saturation, further improving the results' quality. By conducting comprehensive quantitative and qualitative experiments, we have effectively demonstrated the proficiency of our proposed method. The results indicate that a simple conditional diffusion-based method can replace the complex camera pipeline-based architectures.
Quality-aware Unpaired Image-to-Image Translation
Mar 15, 2019

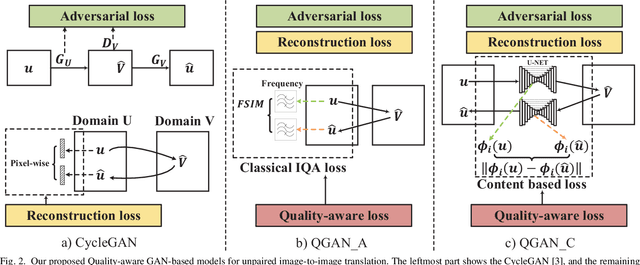
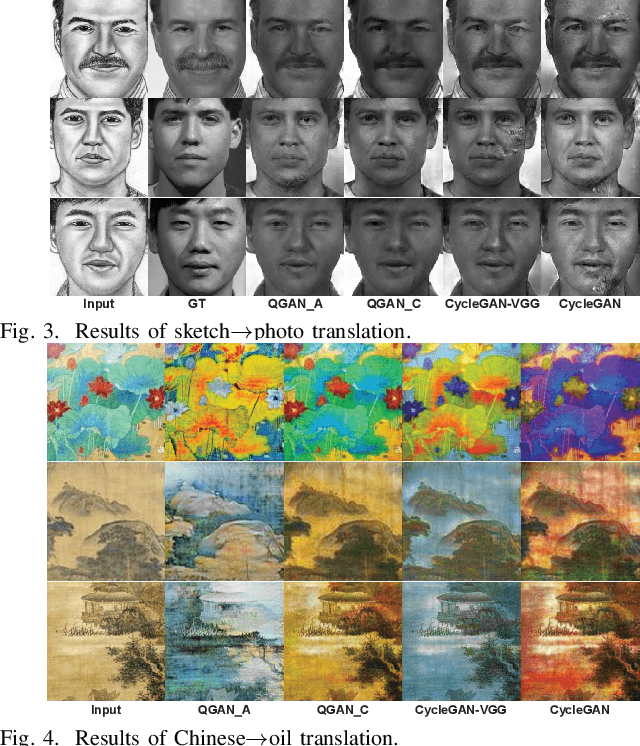
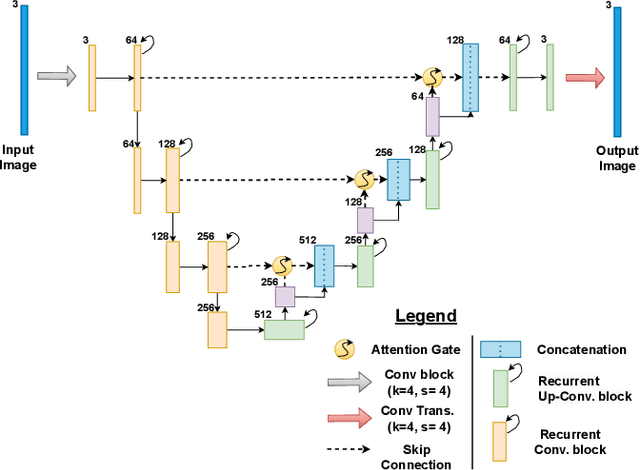
Generative Adversarial Networks (GANs) have been widely used for the image-to-image translation task. While these models rely heavily on the labeled image pairs, recently some GAN variants have been proposed to tackle the unpaired image translation task. These models exploited supervision at the domain level with a reconstruction process for unpaired image translation. On the other hand, parallel works have shown that leveraging perceptual loss functions based on high level deep features could enhance the generated image quality. Nevertheless, as these GAN-based models either depended on the pretrained deep network structure or relied on the labeled image pairs, they could not be directly applied to the unpaired image translation task. Moreover, despite the improvement of the introduced perceptual losses from deep neural networks, few researchers have explored the possibility of improving the generated image quality from classical image quality measures. To tackle the above two challenges, in this paper, we propose a unified quality-aware GAN-based framework for unpaired image-to-image translation, where a quality-aware loss is explicitly incorporated by comparing each source image and the reconstructed image at the domain level. Specifically, we design two detailed implementations of the quality loss. The first method is based on a classical image quality assessment measure by defining a classical quality-aware loss. The second method proposes an adaptive deep network based loss. Finally, extensive experimental results on many real-world datasets clearly show the quality improvement of our proposed framework, and the superiority of leveraging classical image quality measures for unpaired image translation compared to the deep network based model.
Zero-Pair Image to Image Translation using Domain Conditional Normalization
Nov 11, 2020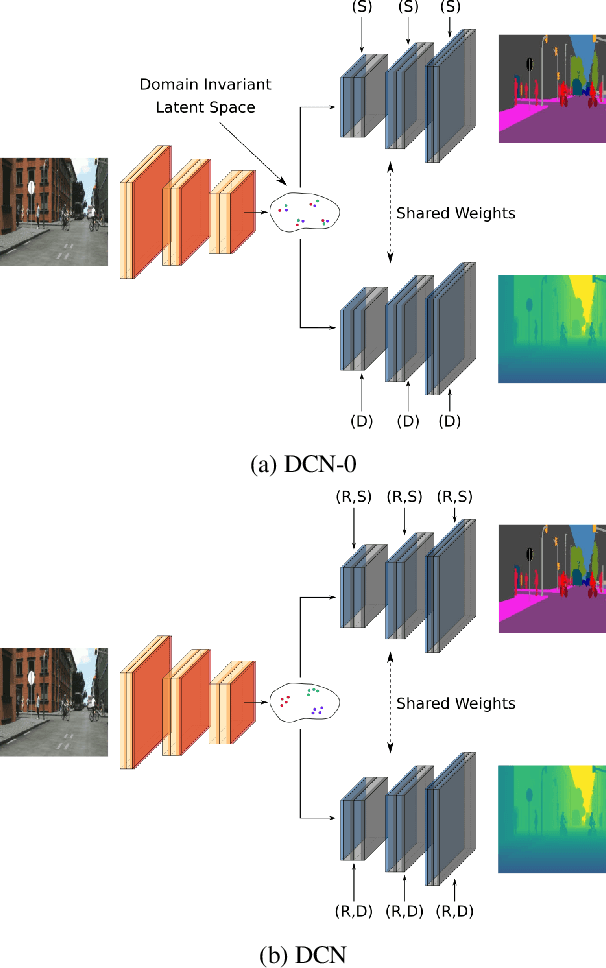
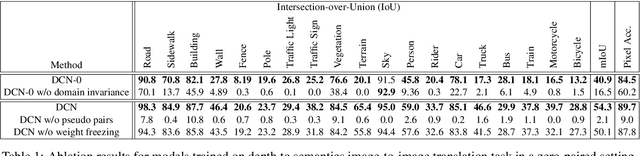
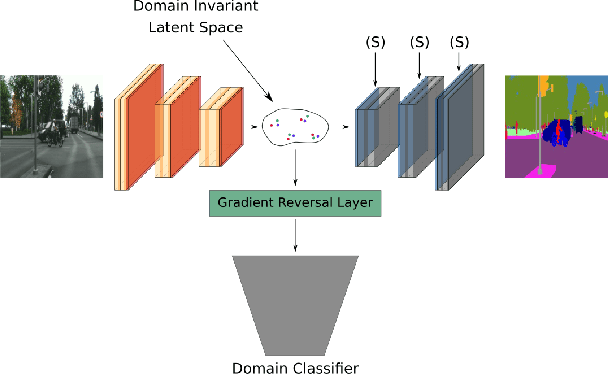

In this paper, we propose an approach based on domain conditional normalization (DCN) for zero-pair image-to-image translation, i.e., translating between two domains which have no paired training data available but each have paired training data with a third domain. We employ a single generator which has an encoder-decoder structure and analyze different implementations of domain conditional normalization to obtain the desired target domain output. The validation benchmark uses RGB-depth pairs and RGB-semantic pairs for training and compares performance for the depth-semantic translation task. The proposed approaches improve in qualitative and quantitative terms over the compared methods, while using much fewer parameters. Code available at https://github.com/samarthshukla/dcn
One-to-one Mapping for Unpaired Image-to-image Translation
Sep 16, 2019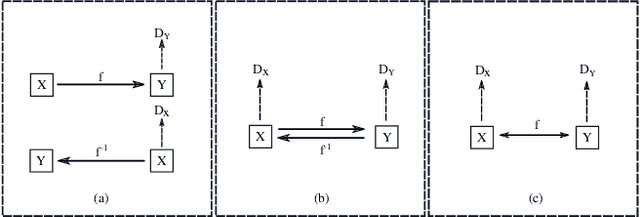



Recently image-to-image translation has attracted significant interests in the literature, starting from the successful use of the generative adversarial network (GAN), to the introduction of cyclic constraint, to extensions to multiple domains. However, in existing approaches, there is no guarantee that the mapping between two image domains is unique or one-to-one. Here we propose a self-inverse network learning approach for unpaired image-to-image translation. Building on top of CycleGAN, we learn a self-inverse function by simply augmenting the training samples by switching inputs and outputs during training. The outcome of such learning is a proven one-to-one mapping function. Our extensive experiments on a variety of detests, including cross-modal medical image synthesis, object transfiguration, and semantic labeling, consistently demonstrate clear improvement over the CycleGAN method both qualitatively and quantitatively. Especially our proposed method reaches the state-of-the-art result on the label to photo direction of the cityscapes benchmark dataset.
Powers of layers for image-to-image translation
Aug 13, 2020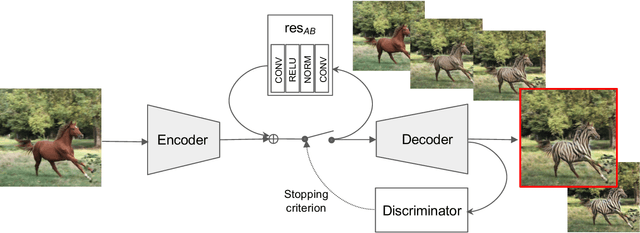
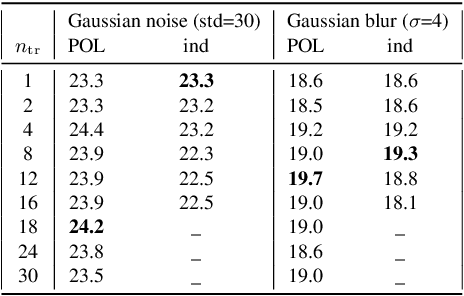
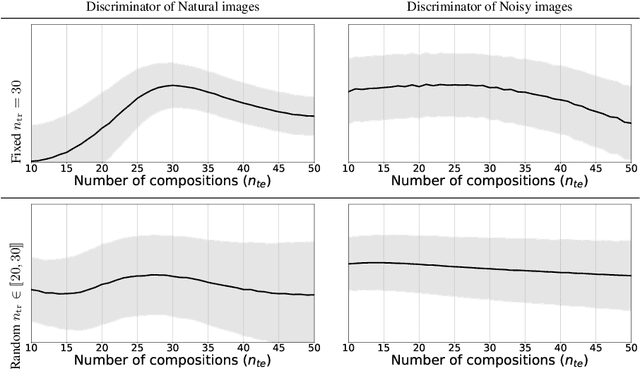
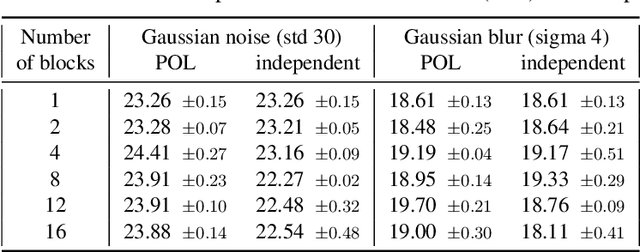
We propose a simple architecture to address unpaired image-to-image translation tasks: style or class transfer, denoising, deblurring, deblocking, etc. We start from an image autoencoder architecture with fixed weights. For each task we learn a residual block operating in the latent space, which is iteratively called until the target domain is reached. A specific training schedule is required to alleviate the exponentiation effect of the iterations. At test time, it offers several advantages: the number of weight parameters is limited and the compositional design allows one to modulate the strength of the transformation with the number of iterations. This is useful, for instance, when the type or amount of noise to suppress is not known in advance. Experimentally, we provide proofs of concepts showing the interest of our method for many transformations. The performance of our model is comparable or better than CycleGAN with significantly fewer parameters.
Image-to-Image Translation with Text Guidance
Feb 12, 2020
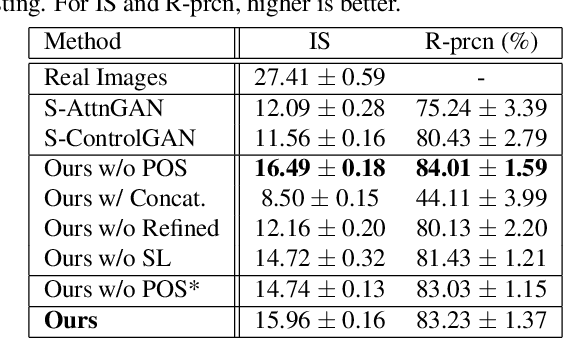
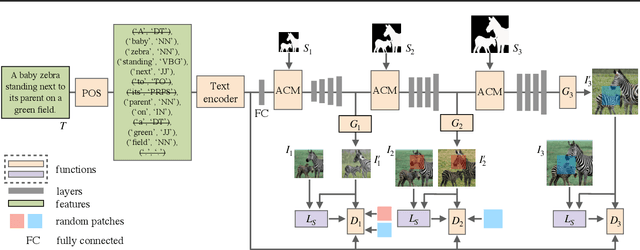

The goal of this paper is to embed controllable factors, i.e., natural language descriptions, into image-to-image translation with generative adversarial networks, which allows text descriptions to determine the visual attributes of synthetic images. We propose four key components: (1) the implementation of part-of-speech tagging to filter out non-semantic words in the given description, (2) the adoption of an affine combination module to effectively fuse different modality text and image features, (3) a novel refined multi-stage architecture to strengthen the differential ability of discriminators and the rectification ability of generators, and (4) a new structure loss to further improve discriminators to better distinguish real and synthetic images. Extensive experiments on the COCO dataset demonstrate that our method has a superior performance on both visual realism and semantic consistency with given descriptions.