 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Multimodal Image-to-Image Translation via Mutual Information Estimation and Maximization
Sep 01, 2020
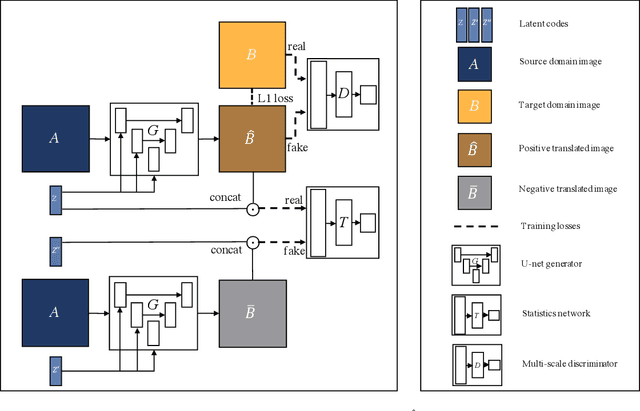
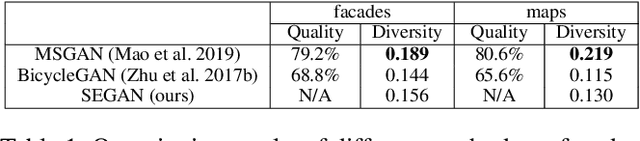

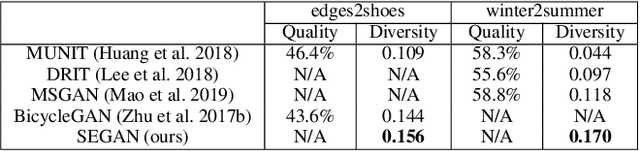
In this paper, we present a novel framework that can achieve multimodal image-to-image translation by simply encouraging the statistical dependence between the latent code and the output image in conditional generative adversarial networks. In addition, by incorporating a U-net generator into our framework, our method only needs to learn a one-sided translation model from the source image domain to the target image domain for both supervised and unsupervised multimodal image-to-image translation. Furthermore, our method also achieves disentanglement between the source domain content and the target domain style for free. We conduct experiments under supervised and unsupervised settings on various benchmark image-to-image translation datasets compared with the state-of-the-art methods, showing the effectiveness and simplicity of our method to achieve multimodal and high-quality results.
Image to Image Translation : Generating maps from satellite images
May 19, 2021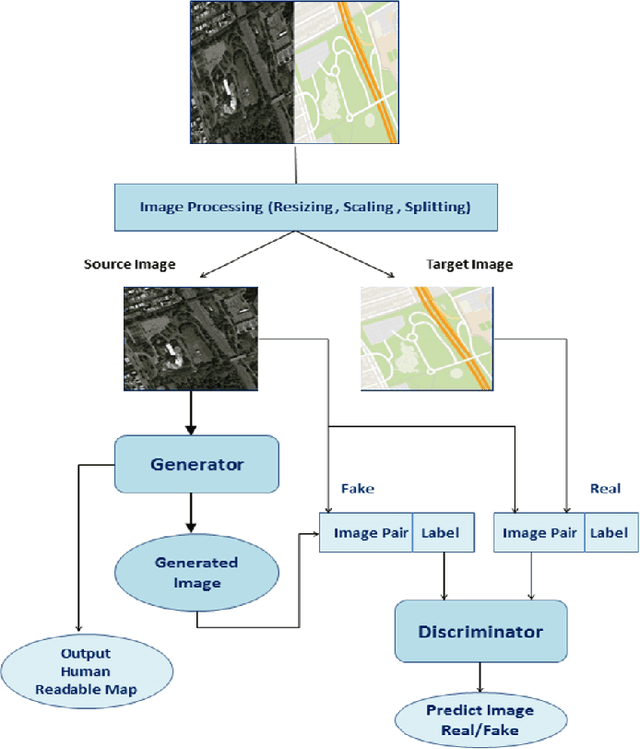
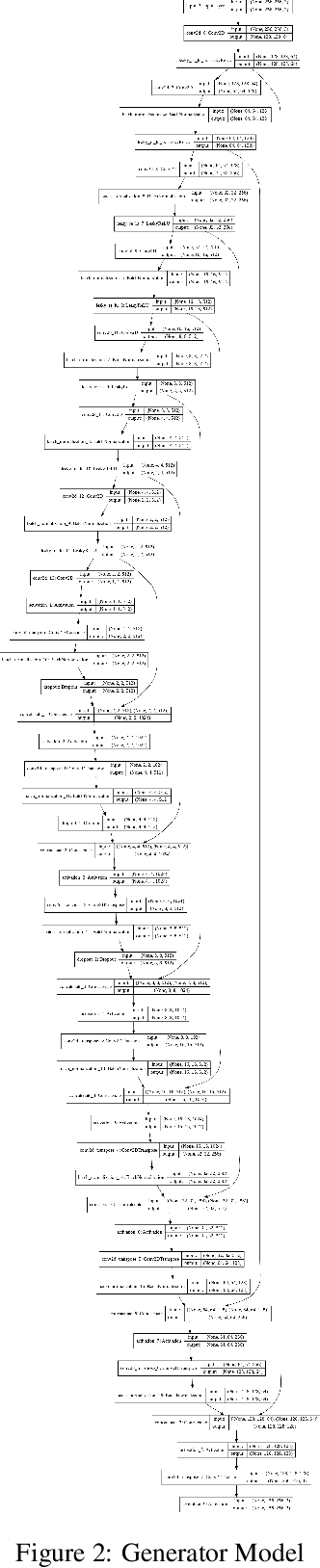
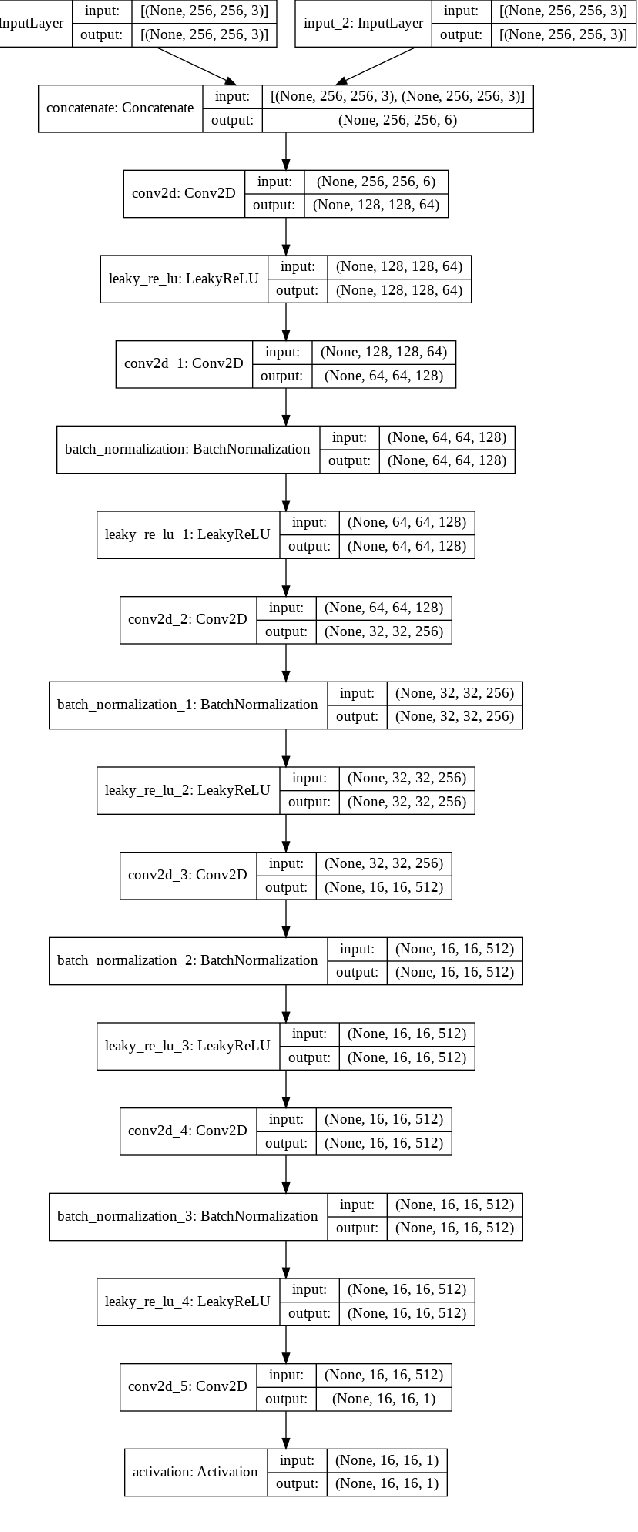
Generation of maps from satellite images is conventionally done by a range of tools. Maps became an important part of life whose conversion from satellite images may be a bit expensive but Generative models can pander to this challenge. These models aims at finding the patterns between the input and output image. Image to image translation is employed to convert satellite image to corresponding map. Different techniques for image to image translations like Generative adversarial network, Conditional adversarial networks and Co-Variational Auto encoders are used to generate the corresponding human-readable maps for that region, which takes a satellite image at a given zoom level as its input. We are training our model on Conditional Generative Adversarial Network which comprises of Generator model which which generates fake images while the discriminator tries to classify the image as real or fake and both these models are trained synchronously in adversarial manner where both try to fool each other and result in enhancing model performance.
Toward Zero-Shot Unsupervised Image-to-Image Translation
Jul 28, 2020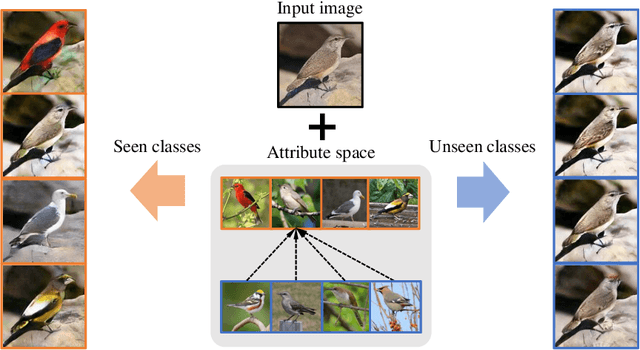
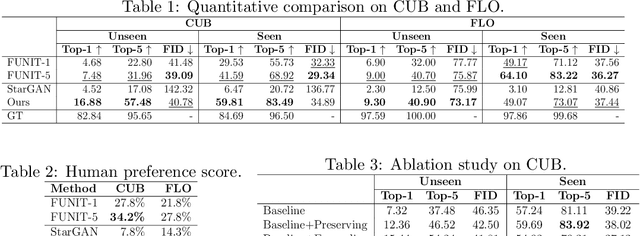
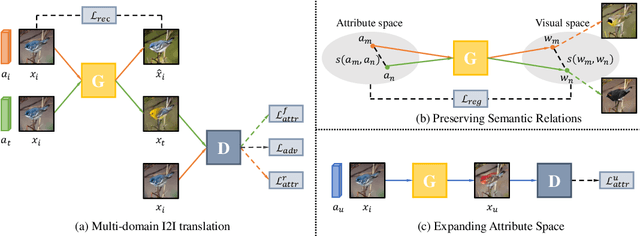

Recent studies have shown remarkable success in unsupervised image-to-image translation. However, if there has no access to enough images in target classes, learning a mapping from source classes to the target classes always suffers from mode collapse, which limits the application of the existing methods. In this work, we propose a zero-shot unsupervised image-to-image translation framework to address this limitation, by associating categories with their side information like attributes. To generalize the translator to previous unseen classes, we introduce two strategies for exploiting the space spanned by the semantic attributes. Specifically, we propose to preserve semantic relations to the visual space and expand attribute space by utilizing attribute vectors of unseen classes, thus encourage the translator to explore the modes of unseen classes. Quantitative and qualitative results on different datasets demonstrate the effectiveness of our proposed approach. Moreover, we demonstrate that our framework can be applied to many tasks, such as zero-shot classification and fashion design.
Separating Content and Style for Unsupervised Image-to-Image Translation
Oct 27, 2021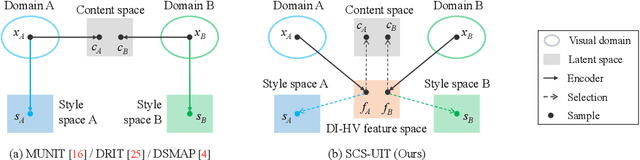
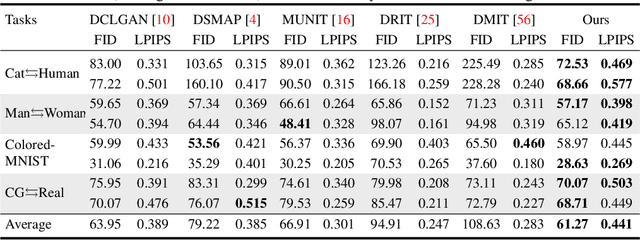
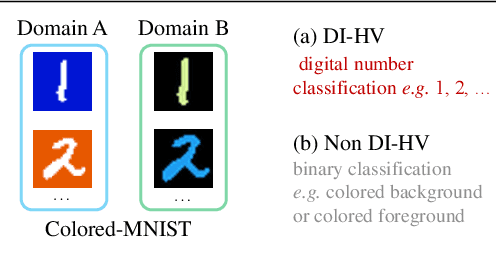
Unsupervised image-to-image translation aims to learn the mapping between two visual domains with unpaired samples. Existing works focus on disentangling domain-invariant content code and domain-specific style code individually for multimodal purposes. However, less attention has been paid to interpreting and manipulating the translated image. In this paper, we propose to separate the content code and style code simultaneously in a unified framework. Based on the correlation between the latent features and the high-level domain-invariant tasks, the proposed framework demonstrates superior performance in multimodal translation, interpretability and manipulation of the translated image. Experimental results show that the proposed approach outperforms the existing unsupervised image translation methods in terms of visual quality and diversity.
Federated CycleGAN for Privacy-Preserving Image-to-Image Translation
Jun 17, 2021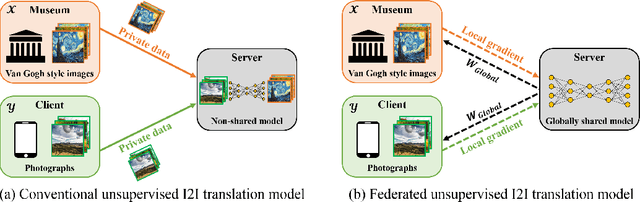
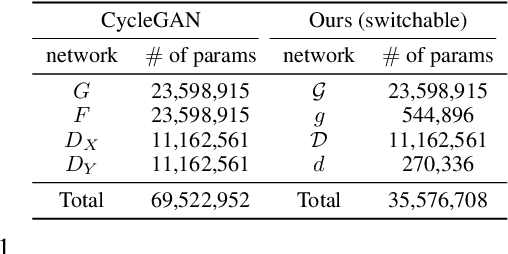
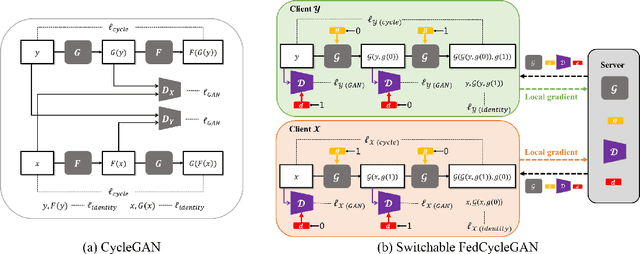
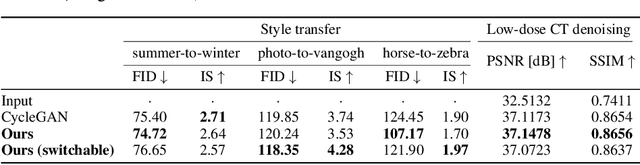
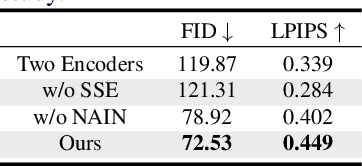
Unsupervised image-to-image translation methods such as CycleGAN learn to convert images from one domain to another using unpaired training data sets from different domains. Unfortunately, these approaches still require centrally collected unpaired records, potentially violating privacy and security issues. Although the recent federated learning (FL) allows a neural network to be trained without data exchange, the basic assumption of the FL is that all clients have their own training data from a similar domain, which is different from our image-to-image translation scenario in which each client has images from its unique domain and the goal is to learn image translation between different domains without accessing the target domain data. To address this, here we propose a novel federated CycleGAN architecture that can learn image translation in an unsupervised manner while maintaining the data privacy. Specifically, our approach arises from a novel observation that CycleGAN loss can be decomposed into the sum of client specific local objectives that can be evaluated using only their data. This local objective decomposition allows multiple clients to participate in federated CycleGAN training without sacrificing performance. Furthermore, our method employs novel switchable generator and discriminator architecture using Adaptive Instance Normalization (AdaIN) that significantly reduces the band-width requirement of the federated learning. Our experimental results on various unsupervised image translation tasks show that our federated CycleGAN provides comparable performance compared to the non-federated counterpart.
Instance-wise Hard Negative Example Generation for Contrastive Learning in Unpaired Image-to-Image Translation
Aug 11, 2021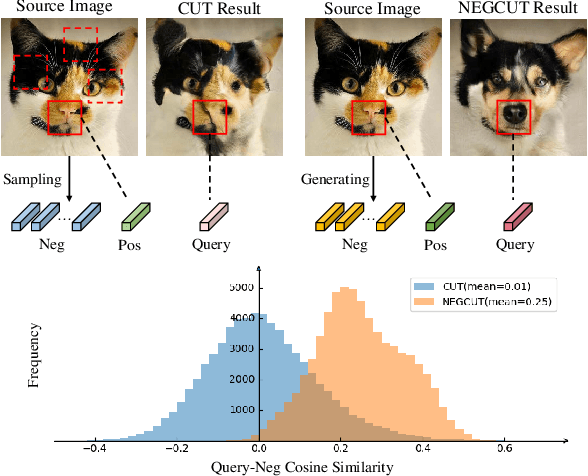
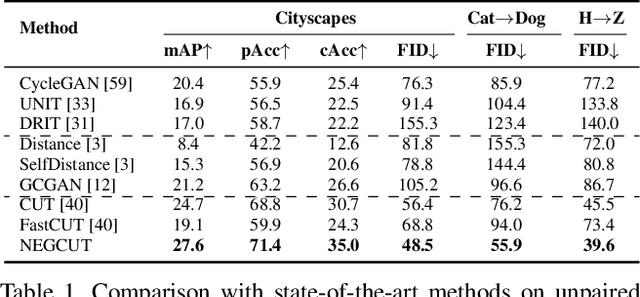
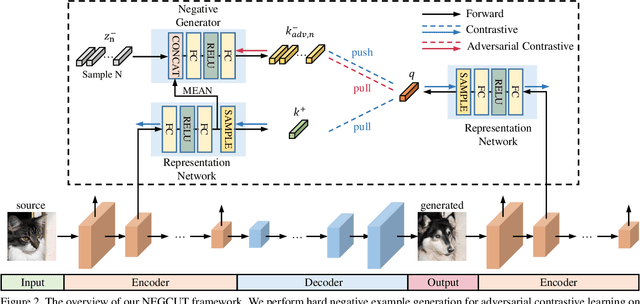
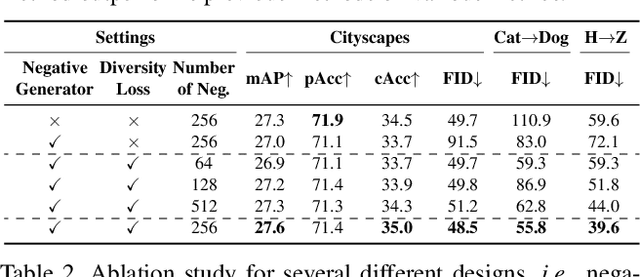
Contrastive learning shows great potential in unpaired image-to-image translation, but sometimes the translated results are in poor quality and the contents are not preserved consistently. In this paper, we uncover that the negative examples play a critical role in the performance of contrastive learning for image translation. The negative examples in previous methods are randomly sampled from the patches of different positions in the source image, which are not effective to push the positive examples close to the query examples. To address this issue, we present instance-wise hard Negative Example Generation for Contrastive learning in Unpaired image-to-image Translation (NEGCUT). Specifically, we train a generator to produce negative examples online. The generator is novel from two perspectives: 1) it is instance-wise which means that the generated examples are based on the input image, and 2) it can generate hard negative examples since it is trained with an adversarial loss. With the generator, the performance of unpaired image-to-image translation is significantly improved. Experiments on three benchmark datasets demonstrate that the proposed NEGCUT framework achieves state-of-the-art performance compared to previous methods.