 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Semantic Relation Preserving Knowledge Distillation for Image-to-Image Translation
Apr 30, 2021
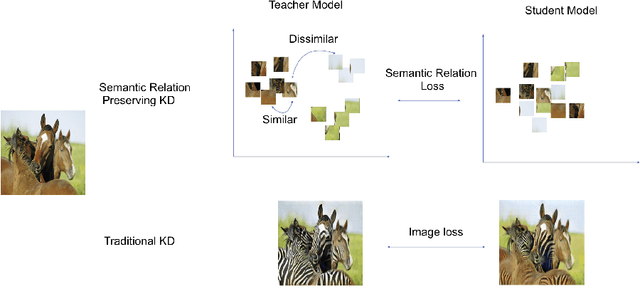
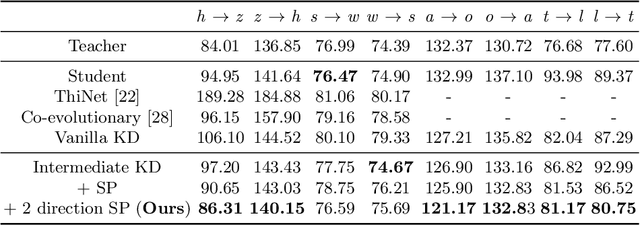
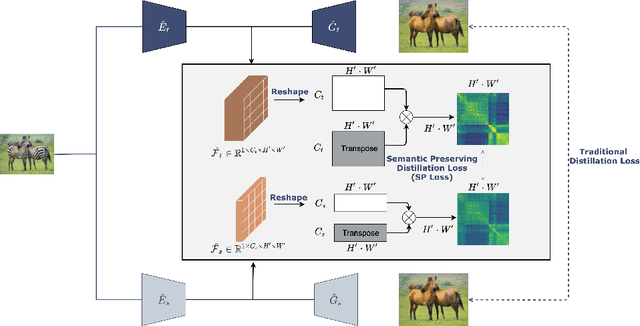
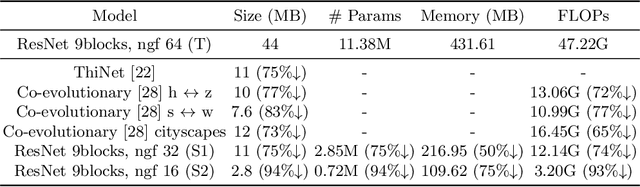
Generative adversarial networks (GANs) have shown significant potential in modeling high dimensional distributions of image data, especially on image-to-image translation tasks. However, due to the complexity of these tasks, state-of-the-art models often contain a tremendous amount of parameters, which results in large model size and long inference time. In this work, we propose a novel method to address this problem by applying knowledge distillation together with distillation of a semantic relation preserving matrix. This matrix, derived from the teacher's feature encoding, helps the student model learn better semantic relations. In contrast to existing compression methods designed for classification tasks, our proposed method adapts well to the image-to-image translation task on GANs. Experiments conducted on 5 different datasets and 3 different pairs of teacher and student models provide strong evidence that our methods achieve impressive results both qualitatively and quantitatively.
Wavelet-based Unsupervised Label-to-Image Translation
May 16, 2023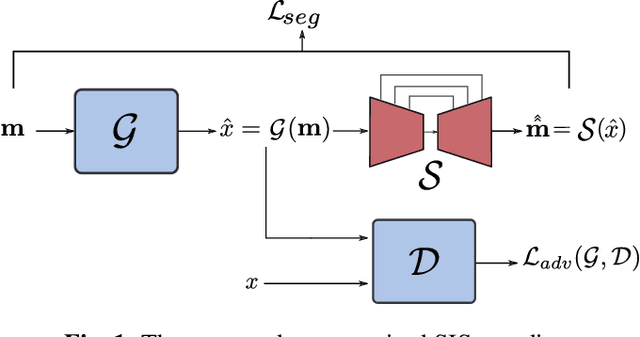
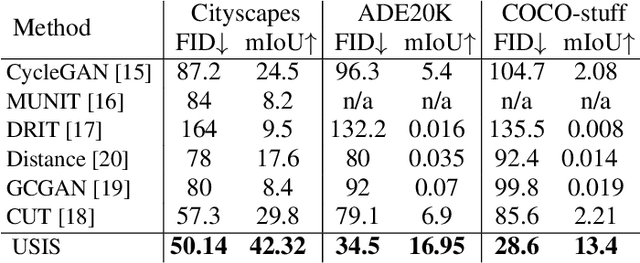

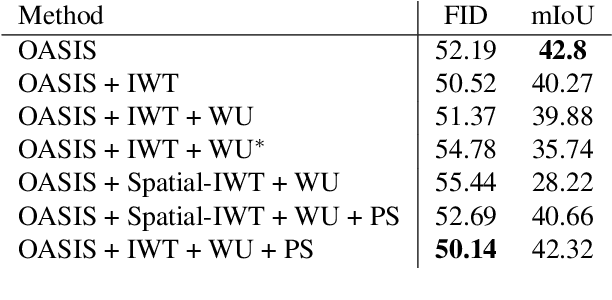
Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a semantic layout is used to generate a photorealistic image. State-of-the-art conditional Generative Adversarial Networks (GANs) need a huge amount of paired data to accomplish this task while generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and learn correspondences in appearance instead of semantic content. Starting from the assumption that a high quality generated image should be segmented back to its semantic layout, we propose a new Unsupervised paradigm for SIS (USIS) that makes use of a self-supervised segmentation loss and whole image wavelet based discrimination. Furthermore, in order to match the high-frequency distribution of real images, a novel generator architecture in the wavelet domain is proposed. We test our methodology on 3 challenging datasets and demonstrate its ability to bridge the performance gap between paired and unpaired models.
EGSDE: Unpaired Image-to-Image Translation via Energy-Guided Stochastic Differential Equations
Jul 14, 2022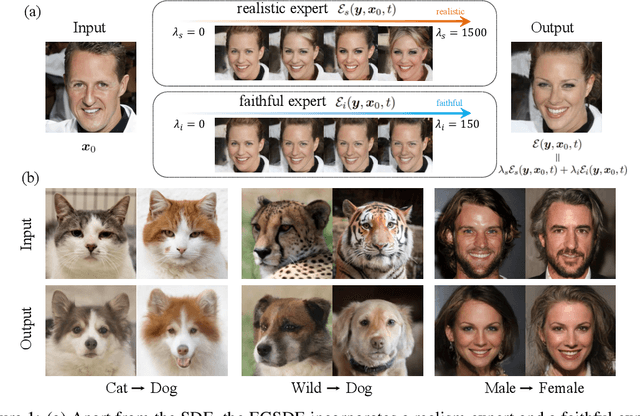
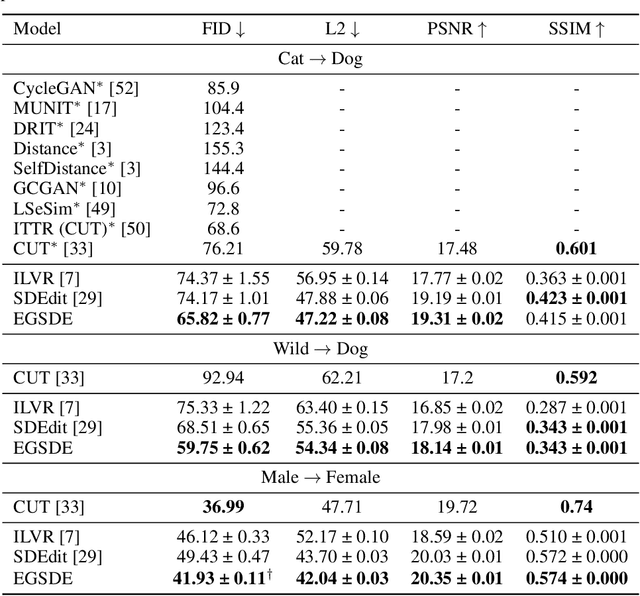
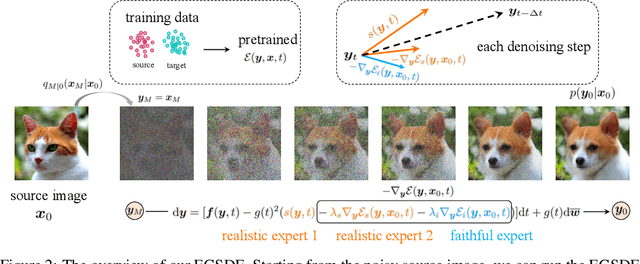

Score-based diffusion generative models (SDGMs) have achieved the SOTA FID results in unpaired image-to-image translation (I2I). However, we notice that existing methods totally ignore the training data in the source domain, leading to sub-optimal solutions for unpaired I2I. To this end, we propose energy-guided stochastic differential equations (EGSDE) that employs an energy function pretrained on both the source and target domains to guide the inference process of a pretrained SDE for realistic and faithful unpaired I2I. Building upon two feature extractors, we carefully design the energy function such that it encourages the transferred image to preserve the domain-independent features and discard domainspecific ones. Further, we provide an alternative explanation of the EGSDE as a product of experts, where each of the three experts (corresponding to the SDE and two feature extractors) solely contributes to faithfulness or realism. Empirically, we compare EGSDE to a large family of baselines on three widely-adopted unpaired I2I tasks under four metrics. EGSDE not only consistently outperforms existing SDGMs-based methods in almost all settings but also achieves the SOTA realism results (e.g., FID of 65.82 in Cat to Dog and FID of 59.75 in Wild to Dog on AFHQ) without harming the faithful performance.
Dense Multitask Learning to Reconfigure Comics
Jul 16, 2023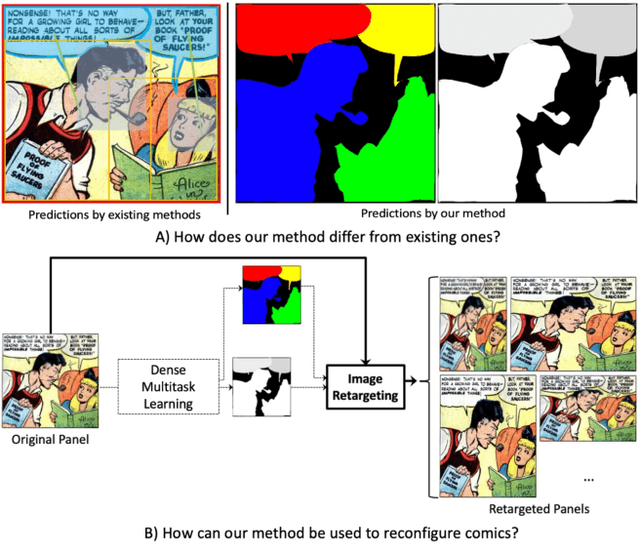

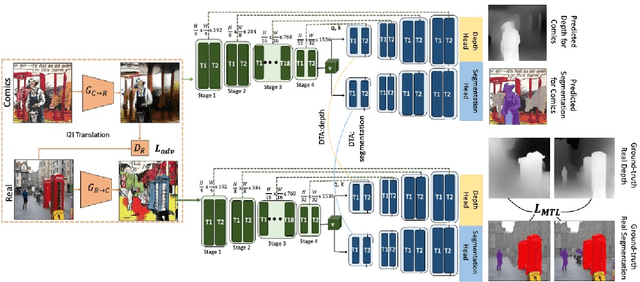
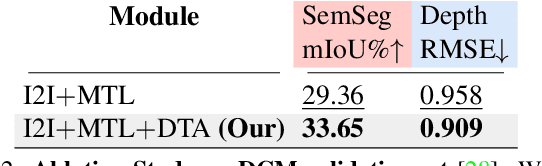
In this paper, we develop a MultiTask Learning (MTL) model to achieve dense predictions for comics panels to, in turn, facilitate the transfer of comics from one publication channel to another by assisting authors in the task of reconfiguring their narratives. Our MTL method can successfully identify the semantic units as well as the embedded notion of 3D in comic panels. This is a significantly challenging problem because comics comprise disparate artistic styles, illustrations, layouts, and object scales that depend on the authors creative process. Typically, dense image-based prediction techniques require a large corpus of data. Finding an automated solution for dense prediction in the comics domain, therefore, becomes more difficult with the lack of ground-truth dense annotations for the comics images. To address these challenges, we develop the following solutions: 1) we leverage a commonly-used strategy known as unsupervised image-to-image translation, which allows us to utilize a large corpus of real-world annotations; 2) we utilize the results of the translations to develop our multitasking approach that is based on a vision transformer backbone and a domain transferable attention module; 3) we study the feasibility of integrating our MTL dense-prediction method with an existing retargeting method, thereby reconfiguring comics.
Efficient High-Resolution Image-to-Image Translation using Multi-Scale Gradient U-Net
May 27, 2021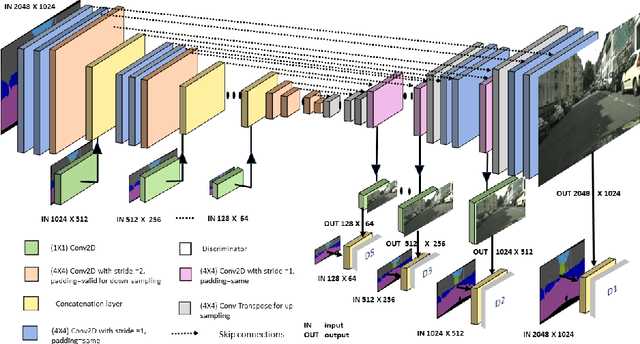
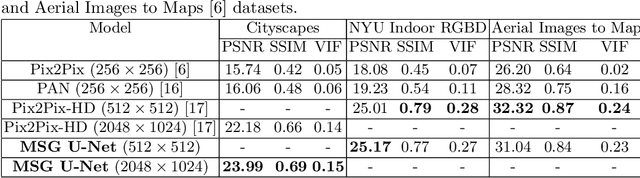
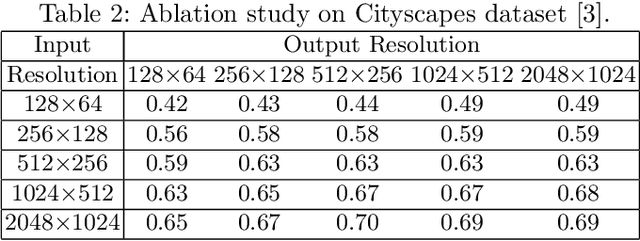
Recently, Conditional Generative Adversarial Network (Conditional GAN) have shown very promising performance in several image-to-image translation applications. However, the uses of these conditional GANs are quite limited to low-resolution images, such as 256X256.The Pix2Pix-HD is a recent attempt to utilize the conditional GAN for high-resolution image synthesis. In this paper, we propose a Multi-Scale Gradient based U-Net (MSG U-Net) model for high-resolution image-to-image translation up to 2048X1024 resolution. The proposed model is trained by allowing the flow of gradients from multiple-discriminators to a single generator at multiple scales. The proposed MSG U-Net architecture leads to photo-realistic high-resolution image-to-image translation. Moreover, the proposed model is computationally efficient as com-pared to the Pix2Pix-HD with an improvement in the inference time nearly by 2.5 times. We provide the code of MSG U-Net model at https://github.com/laxmaniron/MSG-U-Net.
ParGANDA: Making Synthetic Pedestrians A Reality For Object Detection
Jul 21, 2023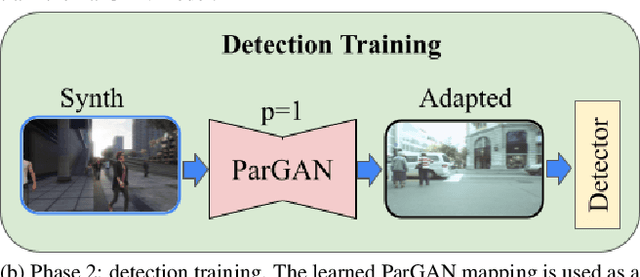



Object detection is the key technique to a number of Computer Vision applications, but it often requires large amounts of annotated data to achieve decent results. Moreover, for pedestrian detection specifically, the collected data might contain some personally identifiable information (PII), which is highly restricted in many countries. This label intensive and privacy concerning task has recently led to an increasing interest in training the detection models using synthetically generated pedestrian datasets collected with a photo-realistic video game engine. The engine is able to generate unlimited amounts of data with precise and consistent annotations, which gives potential for significant gains in the real-world applications. However, the use of synthetic data for training introduces a synthetic-to-real domain shift aggravating the final performance. To close the gap between the real and synthetic data, we propose to use a Generative Adversarial Network (GAN), which performsparameterized unpaired image-to-image translation to generate more realistic images. The key benefit of using the GAN is its intrinsic preference of low-level changes to geometric ones, which means annotations of a given synthetic image remain accurate even after domain translation is performed thus eliminating the need for labeling real data. We extensively experimented with the proposed method using MOTSynth dataset to train and MOT17 and MOT20 detection datasets to test, with experimental results demonstrating the effectiveness of this method. Our approach not only produces visually plausible samples but also does not require any labels of the real domain thus making it applicable to the variety of downstream tasks.
MixerGAN: An MLP-Based Architecture for Unpaired Image-to-Image Translation
May 28, 2021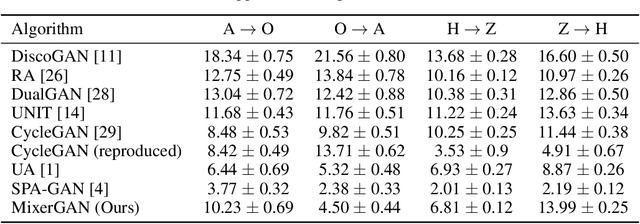

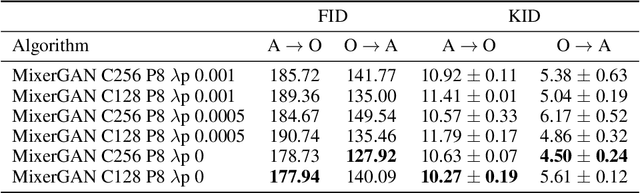
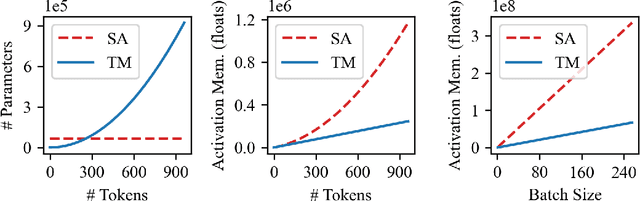
While attention-based transformer networks achieve unparalleled success in nearly all language tasks, the large number of tokens coupled with the quadratic activation memory usage makes them prohibitive for visual tasks. As such, while language-to-language translation has been revolutionized by the transformer model, convolutional networks remain the de facto solution for image-to-image translation. The recently proposed MLP-Mixer architecture alleviates some of the speed and memory issues associated with attention-based networks while still retaining the long-range connections that make transformer models desirable. Leveraging this efficient alternative to self-attention, we propose a new unpaired image-to-image translation model called MixerGAN: a simpler MLP-based architecture that considers long-distance relationships between pixels without the need for expensive attention mechanisms. Quantitative and qualitative analysis shows that MixerGAN achieves competitive results when compared to prior convolutional-based methods.
Multimodal Image-to-Image Translation via Mutual Information Estimation and Maximization
Sep 06, 2020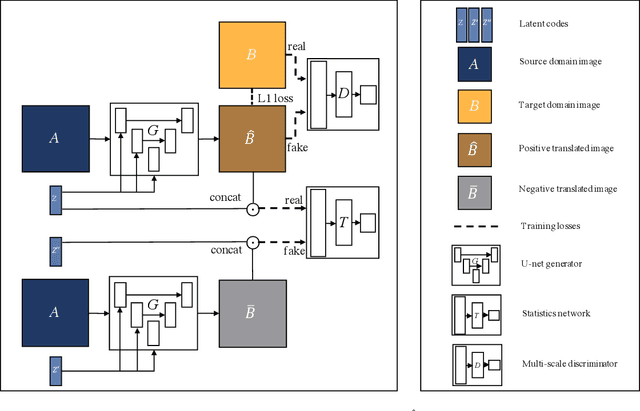
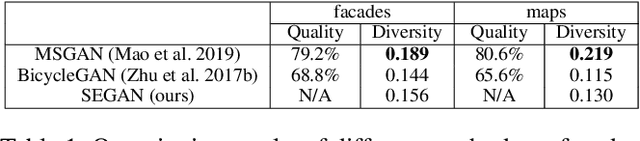

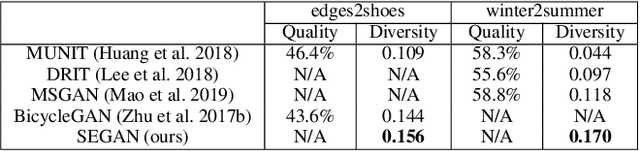
In this paper, we present a novel framework that can achieve multimodal image-to-image translation by simply encouraging the statistical dependence between the latent code and the output image in conditional generative adversarial networks. In addition, by incorporating a U-net generator into our framework, our method only needs to learn a one-sided translation model from the source image domain to the target image domain for both supervised and unsupervised multimodal image-to-image translation. Furthermore, our method also achieves disentanglement between the source domain content and the target domain style for free. We conduct experiments under supervised and unsupervised settings on various benchmark image-to-image translation datasets compared with the state-of-the-art methods, showing the effectiveness and simplicity of our method to achieve multimodal and high-quality results.
Improving Style-Content Disentanglement in Image-to-Image Translation
Jul 09, 2020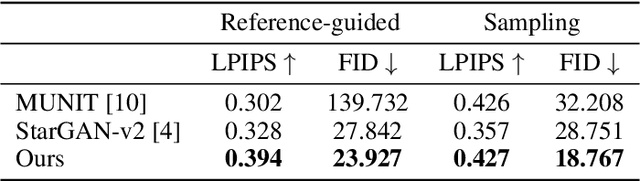

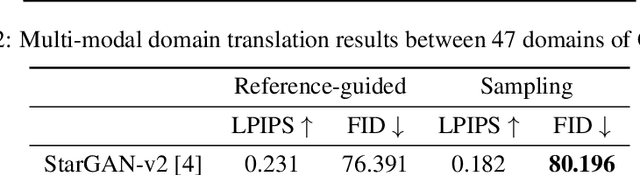

Unsupervised image-to-image translation methods have achieved tremendous success in recent years. However, it can be easily observed that their models contain significant entanglement which often hurts the translation performance. In this work, we propose a principled approach for improving style-content disentanglement in image-to-image translation. By considering the information flow into each of the representations, we introduce an additional loss term which serves as a content-bottleneck. We show that the results of our method are significantly more disentangled than those produced by current methods, while further improving the visual quality and translation diversity.