 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Augmenting Ego-Vehicle for Traffic Near-Miss and Accident Classification Dataset using Manipulating Conditional Style Translation
Jan 06, 2023
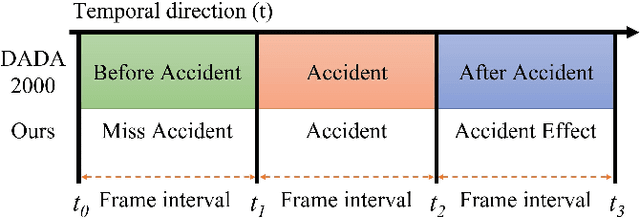
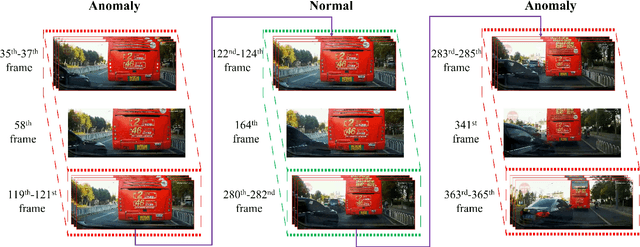

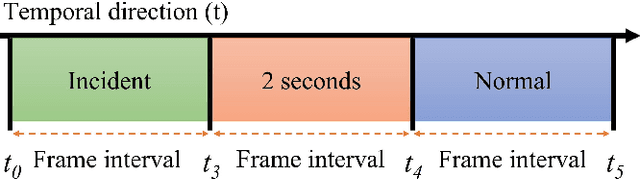
To develop the advanced self-driving systems, many researchers are focusing to alert all possible traffic risk cases from closed-circuit television (CCTV) and dashboard-mounted cameras. Most of these methods focused on identifying frame-by-frame in which an anomaly has occurred, but they are unrealized, which road traffic participant can cause ego-vehicle leading into collision because of available annotation dataset only to detect anomaly on traffic video. Near-miss is one type of accident and can be defined as a narrowly avoided accident. However, there is no difference between accident and near-miss at the time before the accident happened, so our contribution is to redefine the accident definition and re-annotate the accident inconsistency on DADA-2000 dataset together with near-miss. By extending the start and end time of accident duration, our annotation can precisely cover all ego-motions during an incident and consistently classify all possible traffic risk accidents including near-miss to give more critical information for real-world driving assistance systems. The proposed method integrates two different components: conditional style translation (CST) and separable 3-dimensional convolutional neural network (S3D). CST architecture is derived by unsupervised image-to-image translation networks (UNIT) used for augmenting the re-annotation DADA-2000 dataset to increase the number of traffic risk accident videos and to generalize the performance of video classification model on different types of conditions while S3D is useful for video classification to prove dataset re-annotation consistency. In evaluation, the proposed method achieved a significant improvement result by 10.25% positive margin from the baseline model for accuracy on cross-validation analysis.
* 8 pages, conference
A Novel BiLevel Paradigm for Image-to-Image Translation
Apr 18, 2019
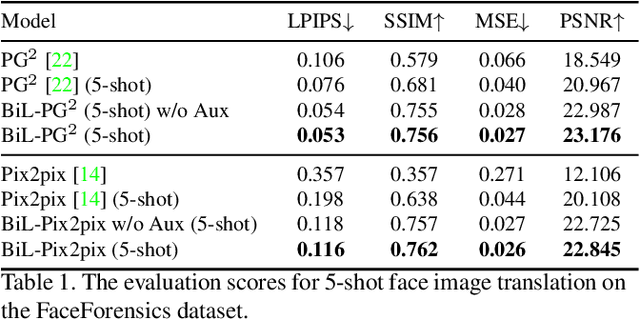
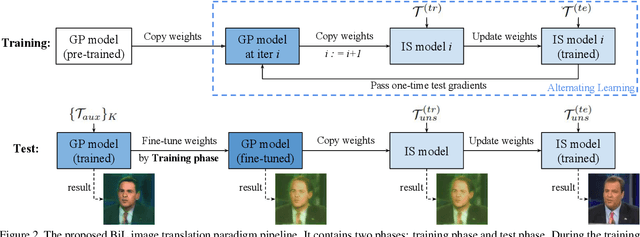
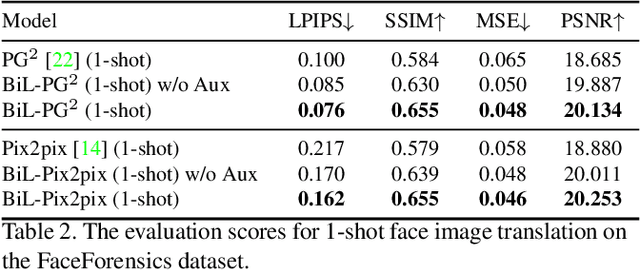
Image-to-image (I2I) translation is a pixel-level mapping that requires a large number of paired training data and often suffers from the problems of high diversity and strong category bias in image scenes. In order to tackle these problems, we propose a novel BiLevel (BiL) learning paradigm that alternates the learning of two models, respectively at an instance-specific (IS) and a general-purpose (GP) level. In each scene, the IS model learns to maintain the specific scene attributes. It is initialized by the GP model that learns from all the scenes to obtain the generalizable translation knowledge. This GP initialization gives the IS model an efficient starting point, thus enabling its fast adaptation to the new scene with scarce training data. We conduct extensive I2I translation experiments on human face and street view datasets. Quantitative results validate that our approach can significantly boost the performance of classical I2I translation models, such as PG2 and Pix2Pix. Our visualization results show both higher image quality and more appropriate instance-specific details, e.g., the translated image of a person looks more like that person in terms of identity.
ObjCAViT: Improving Monocular Depth Estimation Using Natural Language Models And Image-Object Cross-Attention
Nov 30, 2022
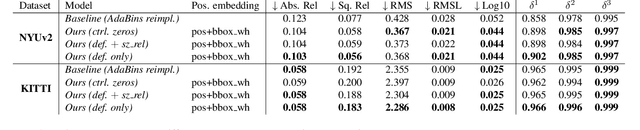
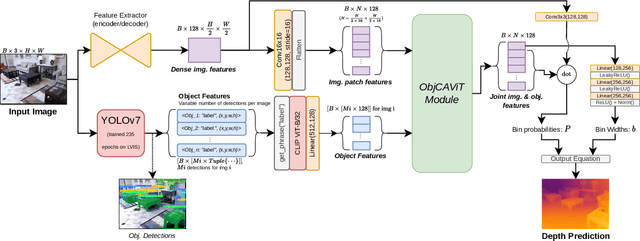
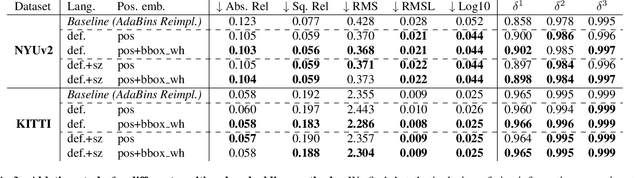
While monocular depth estimation (MDE) is an important problem in computer vision, it is difficult due to the ambiguity that results from the compression of a 3D scene into only 2 dimensions. It is common practice in the field to treat it as simple image-to-image translation, without consideration for the semantics of the scene and the objects within it. In contrast, humans and animals have been shown to use higher-level information to solve MDE: prior knowledge of the nature of the objects in the scene, their positions and likely configurations relative to one another, and their apparent sizes have all been shown to help resolve this ambiguity. In this paper, we present a novel method to enhance MDE performance by encouraging use of known-useful information about the semantics of objects and inter-object relationships within a scene. Our novel ObjCAViT module sources world-knowledge from language models and learns inter-object relationships in the context of the MDE problem using transformer attention, incorporating apparent size information. Our method produces highly accurate depth maps, and we obtain competitive results on the NYUv2 and KITTI datasets. Our ablation experiments show that the use of language and cross-attention within the ObjCAViT module increases performance. Code is released at https://github.com/DylanAuty/ObjCAViT.
Mix and match networks: multi-domain alignment for unpaired image-to-image translation
Mar 08, 2019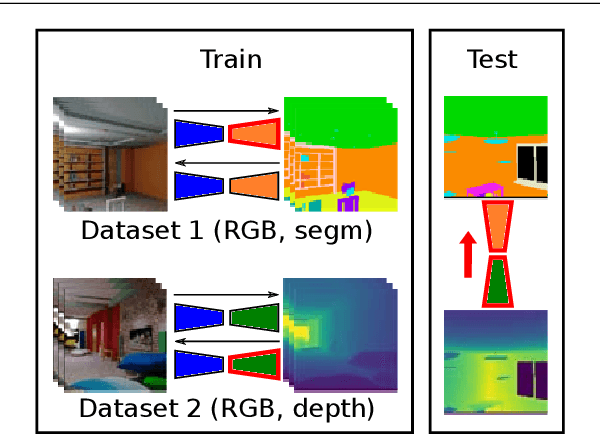
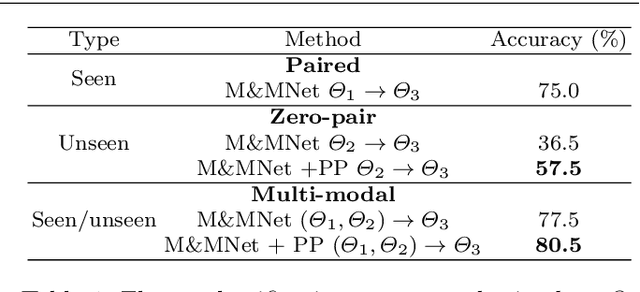

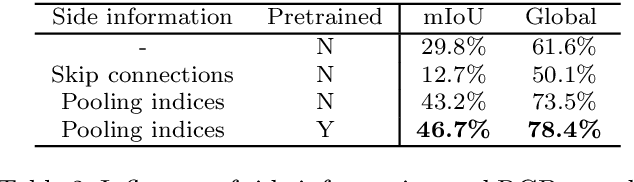
This paper addresses the problem of inferring unseen cross-domain and cross-modal image-to-image translations between multiple domains and modalities. We assume that only some of the pairwise translations have been seen (i.e. trained) and infer the remaining unseen translations (where training pairs are not available). We propose mix and match networks, an approach where multiple encoders and decoders are aligned in such a way that the desired translation can be obtained by simply cascading the source encoder and the target decoder, even when they have not interacted during the training stage (i.e. unseen). The main challenge lies in the alignment of the latent representations at the bottlenecks of encoder-decoder pairs. We propose an architecture with several tools to encourage alignment, including autoencoders and robust side information and latent consistency losses. We show the benefits of our approach in terms of effectiveness and scalability compared with other pairwise image-to-image translation approaches. We also propose zero-pair cross-modal image translation, a challenging setting where the objective is inferring semantic segmentation from depth (and vice-versa) without explicit segmentation-depth pairs, and only from two (disjoint) segmentation-RGB and depth-segmentation training sets. We observe that certain part of the shared information between unseen domains might not be reachable, so we further propose a variant that leverages pseudo-pairs to exploit all shared information.
Extremely Weak Supervised Image-to-Image Translation for Semantic Segmentation
Sep 18, 2019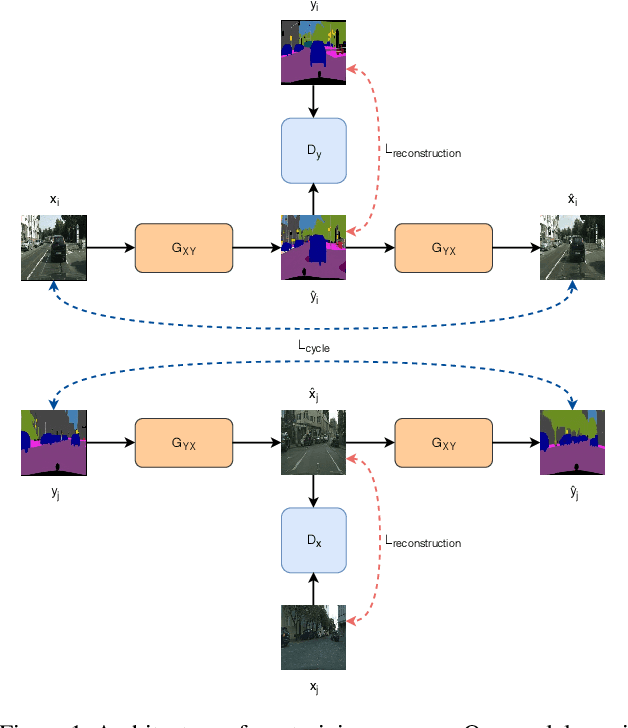
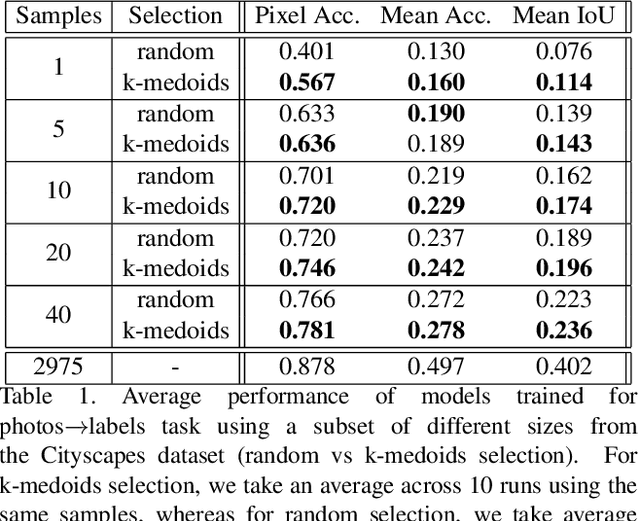
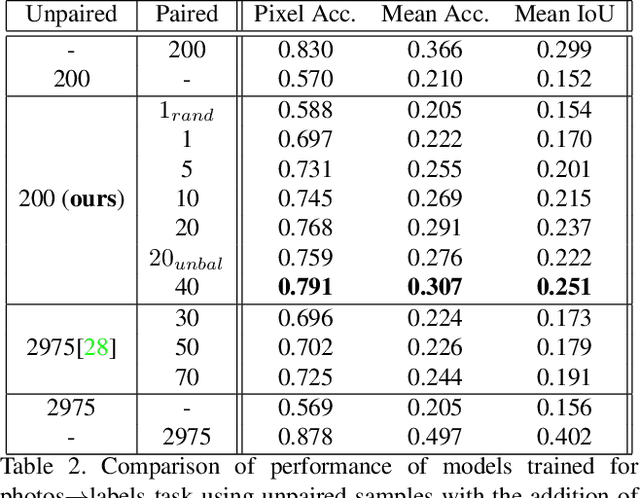

Recent advances in generative models and adversarial training have led to a flourishing image-to-image (I2I) translation literature. The current I2I translation approaches require training images from the two domains that are either all paired (supervised) or all unpaired (unsupervised). In practice, obtaining paired training data in sufficient quantities is often very costly and cumbersome. Therefore solutions that employ unpaired data, while less accurate, are largely preferred. In this paper, we aim to bridge the gap between supervised and unsupervised I2I translation, with application to semantic image segmentation. We build upon pix2pix and CycleGAN, state-of-the-art seminal I2I translation techniques. We propose a method to select (very few) paired training samples and achieve significant improvements in both supervised and unsupervised I2I translation settings over random selection. Further, we boost the performance by incorporating both (selected) paired and unpaired samples in the training process. Our experiments show that an extremely weak supervised I2I translation solution using only one paired training sample can achieve a quantitative performance much better than the unsupervised CycleGAN model, and comparable to that of the supervised pix2pix model trained on thousands of pairs.
What's in a Decade? Transforming Faces Through Time
Oct 17, 2022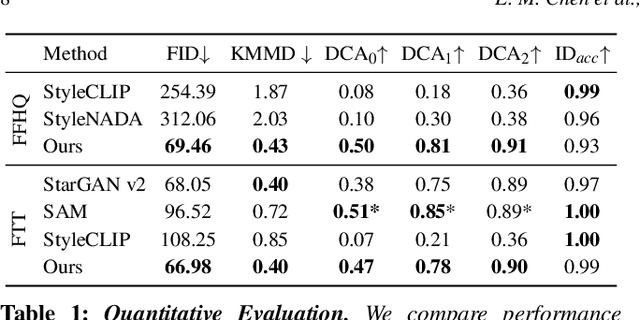

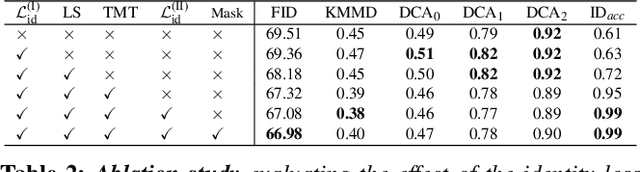
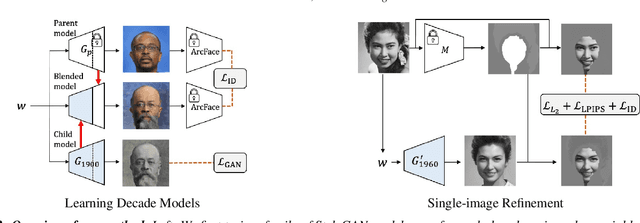
How can one visually characterize people in a decade? In this work, we assemble the Faces Through Time dataset, which contains over a thousand portrait images from each decade, spanning the 1880s to the present day. Using our new dataset, we present a framework for resynthesizing portrait images across time, imagining how a portrait taken during a particular decade might have looked like, had it been taken in other decades. Our framework optimizes a family of per-decade generators that reveal subtle changes that differentiate decade--such as different hairstyles or makeup--while maintaining the identity of the input portrait. Experiments show that our method is more effective in resynthesizing portraits across time compared to state-of-the-art image-to-image translation methods, as well as attribute-based and language-guided portrait editing models. Our code and data will be available at https://facesthroughtime.github.io
Computational Choreography using Human Motion Synthesis
Oct 09, 2022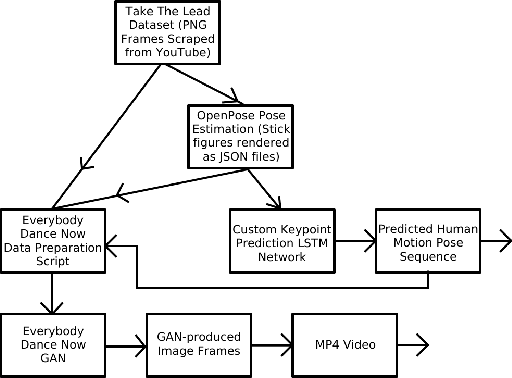
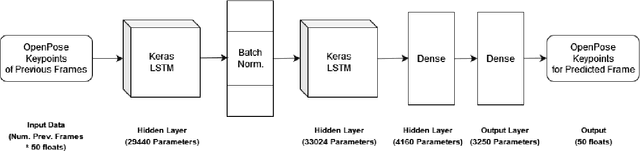
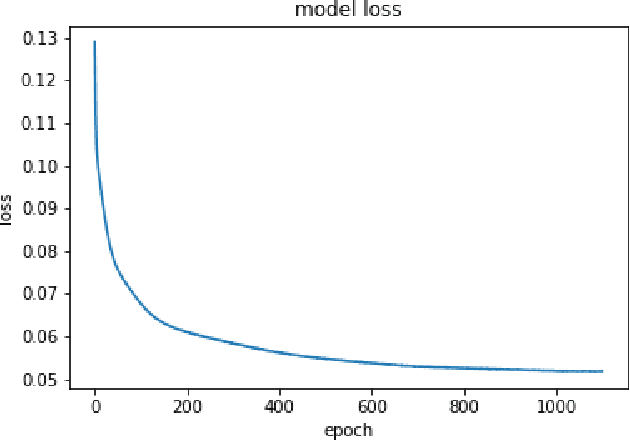
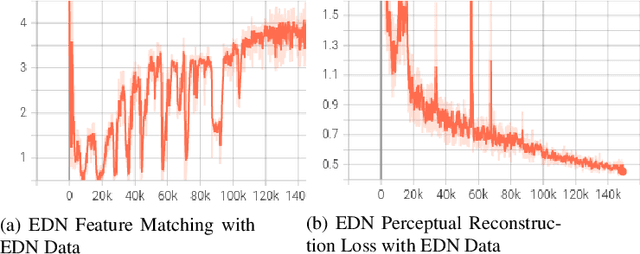
Should deep learning models be trained to analyze human performance art? To help answer this question, we explore an application of deep neural networks to synthesize artistic human motion. Problem tasks in human motion synthesis can include predicting the motions of humans in-the-wild, as well as generating new sequences of motions based on said predictions. We will discuss the potential of a less traditional application, where learning models are applied to predicting dance movements. There have been notable, recent efforts to analyze dance movements in a computational light, such as the Everybody Dance Now (EDN) learning model and a recent Cal Poly master's thesis, Take The Lead (TTL). We have effectively combined these two works along with our own deep neural network to produce a new system for dance motion prediction, image-to-image translation, and video generation.
Review Neural Networks about Image Transformation Based on IGC Learning Framework with Annotated Information
Jun 21, 2022
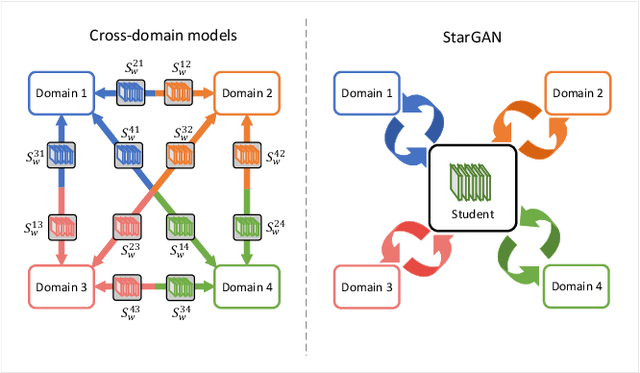


Image transformation, a class of vision and graphics problems whose goal is to learn the mapping between an input image and an output image, develops rapidly in the context of deep neural networks. In Computer Vision (CV), many problems can be regarded as the image transformation task, e.g., semantic segmentation and style transfer. These works have different topics and motivations, making the image transformation task flourishing. Some surveys only review the research on style transfer or image-to-image translation, all of which are just a branch of image transformation. However, none of the surveys summarize those works together in a unified framework to our best knowledge. This paper proposes a novel learning framework including Independent learning, Guided learning, and Cooperative learning, called the IGC learning framework. The image transformation we discuss mainly involves the general image-to-image translation and style transfer about deep neural networks. From the perspective of this framework, we review those subtasks and give a unified interpretation of various scenarios. We categorize related subtasks about the image transformation according to similar development trends. Furthermore, experiments have been performed to verify the effectiveness of IGC learning. Finally, new research directions and open problems are discussed for future research.
SAR-to-Optical Image Translation via Thermodynamics-inspired Network
May 23, 2023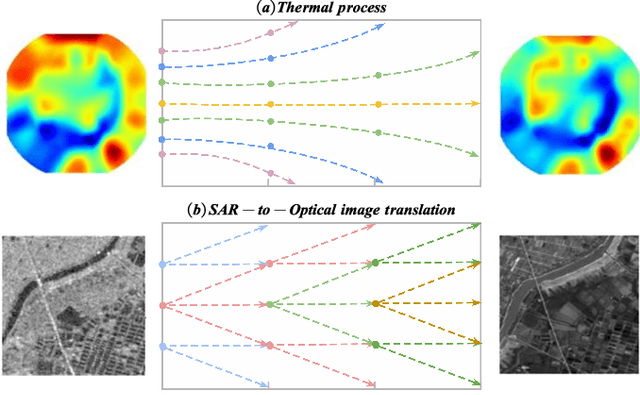
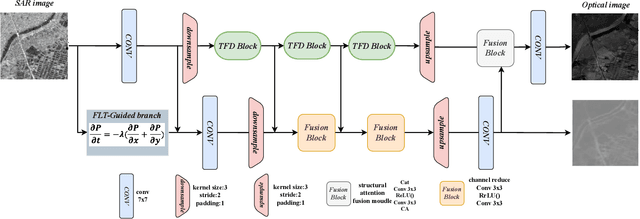
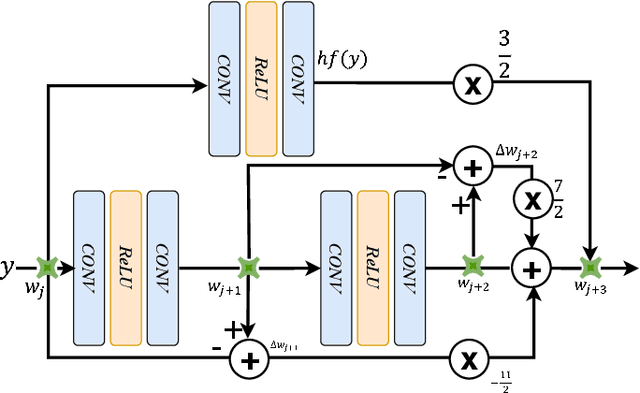
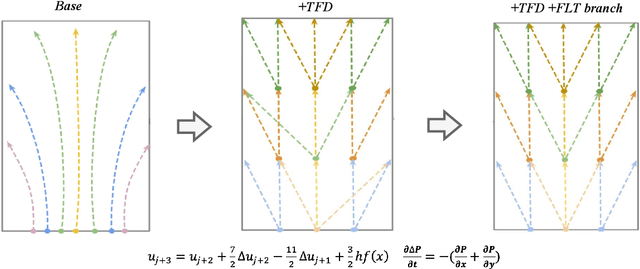
Synthetic aperture radar (SAR) is prevalent in the remote sensing field but is difficult to interpret in human visual perception. Recently, SAR-to-optical (S2O) image conversion methods have provided a prospective solution for interpretation. However, since there is a huge domain difference between optical and SAR images, they suffer from low image quality and geometric distortion in the produced optical images. Motivated by the analogy between pixels during the S2O image translation and molecules in a heat field, Thermodynamics-inspired Network for SAR-to-Optical Image Translation (S2O-TDN) is proposed in this paper. Specifically, we design a Third-order Finite Difference (TFD) residual structure in light of the TFD equation of thermodynamics, which allows us to efficiently extract inter-domain invariant features and facilitate the learning of the nonlinear translation mapping. In addition, we exploit the first law of thermodynamics (FLT) to devise an FLT-guided branch that promotes the state transition of the feature values from the unstable diffusion state to the stable one, aiming to regularize the feature diffusion and preserve image structures during S2O image translation. S2O-TDN follows an explicit design principle derived from thermodynamic theory and enjoys the advantage of explainability. Experiments on the public SEN1-2 dataset show the advantages of the proposed S2O-TDN over the current methods with more delicate textures and higher quantitative results.
Synthetic-to-real Composite Semantic Segmentation in Additive Manufacturing
Oct 14, 2022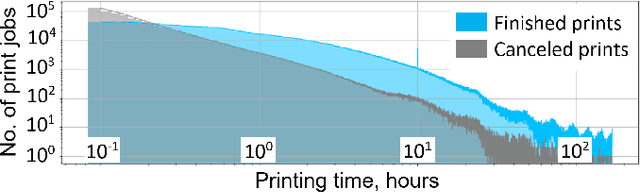
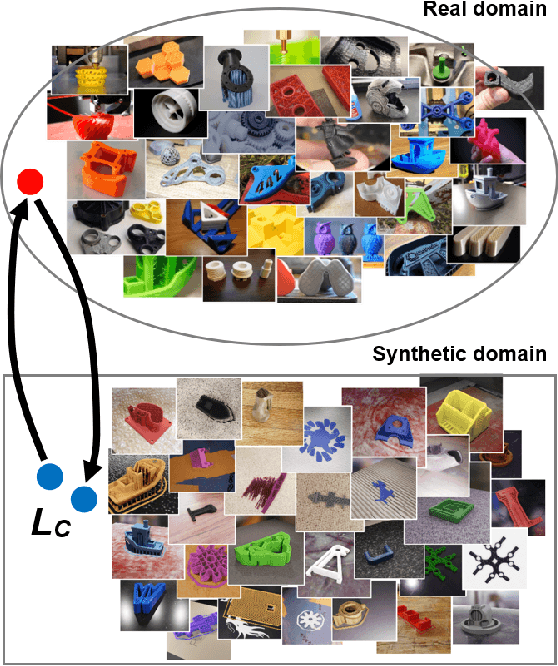


The application of computer vision and machine learning methods in the field of additive manufacturing (AM) for semantic segmentation of the structural elements of 3-D printed products will improve real-time failure analysis systems and can potentially reduce the number of defects by enabling in situ corrections. This work demonstrates the possibilities of using physics-based rendering for labeled image dataset generation, as well as image-to-image translation capabilities to improve the accuracy of real image segmentation for AM systems. Multi-class semantic segmentation experiments were carried out based on the U-Net model and cycle generative adversarial network. The test results demonstrated the capacity of detecting such structural elements of 3-D printed parts as a top layer, infill, shell, and support. A basis for further segmentation system enhancement by utilizing image-to-image style transfer and domain adaptation technologies was also developed. The results indicate that using style transfer as a precursor to domain adaptation can significantly improve real 3-D printing image segmentation in situations where a model trained on synthetic data is the only tool available. The mean intersection over union (mIoU) scores for synthetic test datasets included 94.90% for the entire 3-D printed part, 73.33% for the top layer, 78.93% for the infill, 55.31% for the shell, and 69.45% for supports.