 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model
Feb 14, 2023
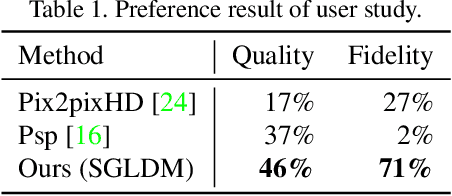

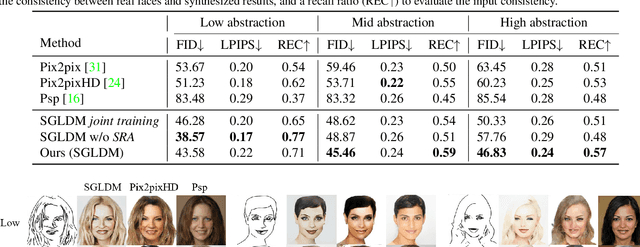
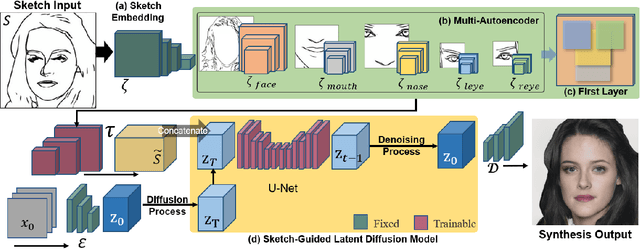
Synthesizing face images from monochrome sketches is one of the most fundamental tasks in the field of image-to-image translation. However, it is still challenging to (1)~make models learn the high-dimensional face features such as geometry and color, and (2)~take into account the characteristics of input sketches. Existing methods often use sketches as indirect inputs (or as auxiliary inputs) to guide the models, resulting in the loss of sketch features or the alteration of geometry information. In this paper, we introduce a Sketch-Guided Latent Diffusion Model (SGLDM), an LDM-based network architect trained on the paired sketch-face dataset. We apply a Multi-Auto-Encoder (AE) to encode the different input sketches from different regions of a face from pixel space to a feature map in latent space, which enables us to reduce the dimension of the sketch input while preserving the geometry-related information of local face details. We build a sketch-face paired dataset based on the existing method that extracts the edge map from an image. We then introduce a Stochastic Region Abstraction (SRA), an approach to augment our dataset to improve the robustness of SGLDM to handle sketch input with arbitrary abstraction. The evaluation study shows that SGLDM can synthesize high-quality face images with different expressions, facial accessories, and hairstyles from various sketches with different abstraction levels.
XOGAN: One-to-Many Unsupervised Image-to-Image Translation
May 18, 2018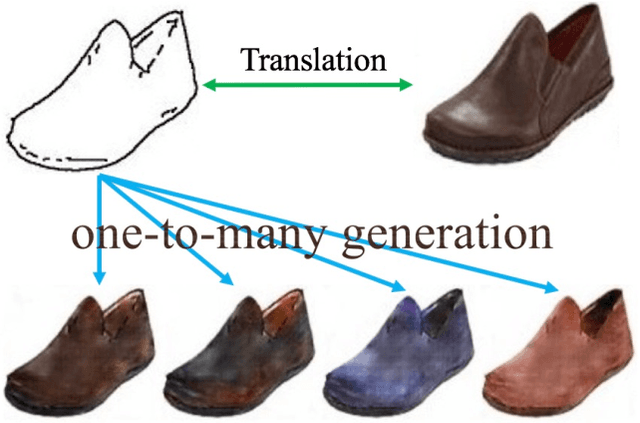
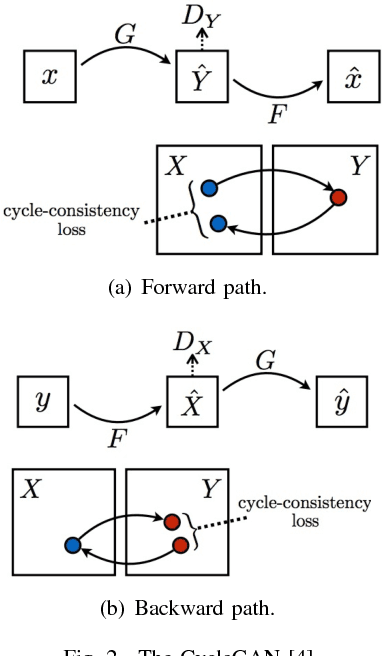
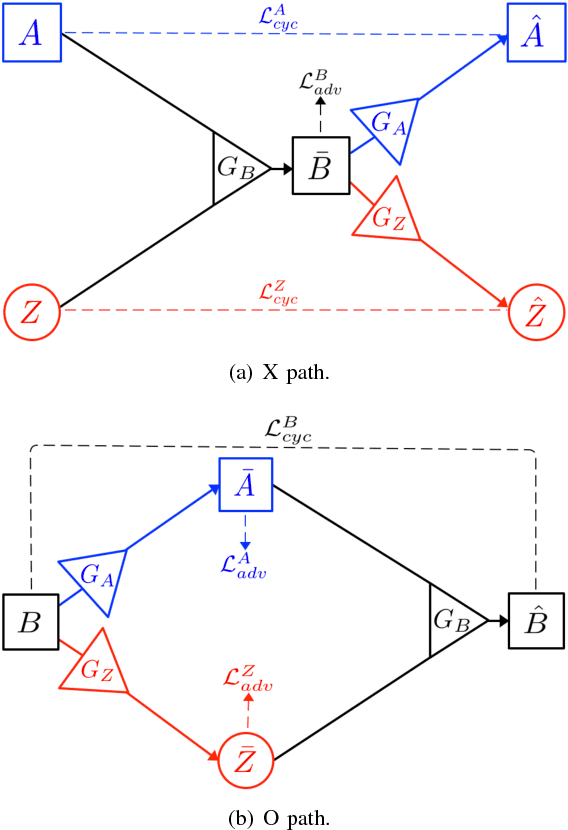
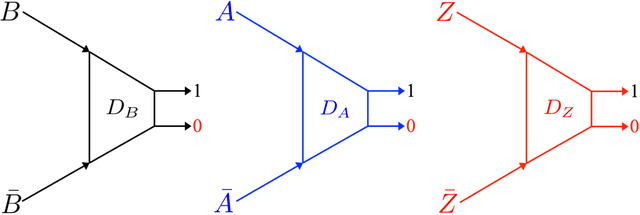
Unsupervised image-to-image translation aims at learning the relationship between samples from two image domains without supervised pair information. The relationship between two domain images can be one-to-one, one-to-many or many-to-many. In this paper, we study the one-to-many unsupervised image translation problem in which an input sample from one domain can correspond to multiple samples in the other domain. To learn the complex relationship between the two domains, we introduce an additional variable to control the variations in our one-to-many mapping. A generative model with an XO-structure, called the XOGAN, is proposed to learn the cross domain relationship among the two domains and the ad- ditional variables. Not only can we learn to translate between the two image domains, we can also handle the translated images with additional variations. Experiments are performed on unpaired image generation tasks, including edges-to-objects translation and facial image translation. We show that the proposed XOGAN model can generate plausible images and control variations, such as color and texture, of the generated images. Moreover, while state-of-the-art unpaired image generation algorithms tend to generate images with monotonous colors, XOGAN can generate more diverse results.
Structurally aware bidirectional unpaired image to image translation between CT and MR
Jun 05, 2020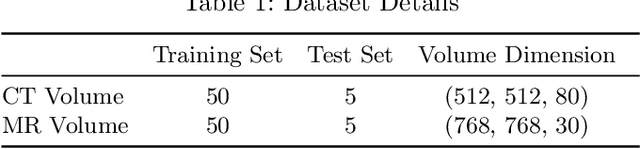
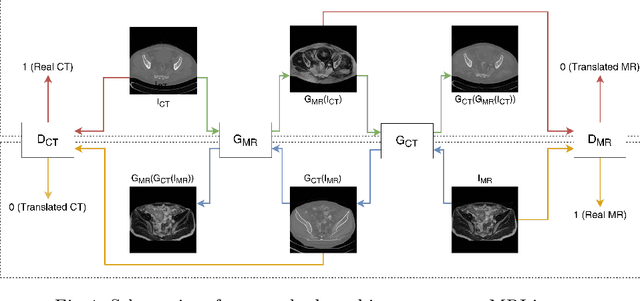
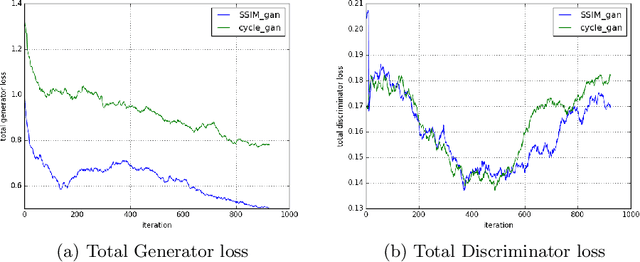
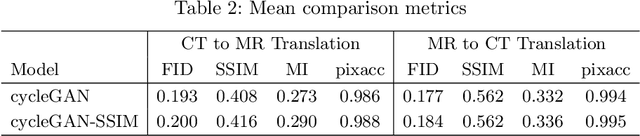
Magnetic Resonance (MR) Imaging and Computed Tomography (CT) are the primary diagnostic imaging modalities quite frequently used for surgical planning and analysis. A general problem with medical imaging is that the acquisition process is quite expensive and time-consuming. Deep learning techniques like generative adversarial networks (GANs) can help us to leverage the possibility of an image to image translation between multiple imaging modalities, which in turn helps in saving time and cost. These techniques will help to conduct surgical planning under CT with the feedback of MRI information. While previous studies have shown paired and unpaired image synthesis from MR to CT, image synthesis from CT to MR still remains a challenge, since it involves the addition of extra tissue information. In this manuscript, we have implemented two different variations of Generative Adversarial Networks exploiting the cycling consistency and structural similarity between both CT and MR image modalities on a pelvis dataset, thus facilitating a bidirectional exchange of content and style between these image modalities. The proposed GANs translate the input medical images by different mechanisms, and hence generated images not only appears realistic but also performs well across various comparison metrics, and these images have also been cross verified with a radiologist. The radiologist verification has shown that slight variations in generated MR and CT images may not be exactly the same as their true counterpart but it can be used for medical purposes.
Learning Fixed Points in Generative Adversarial Networks: From Image-to-Image Translation to Disease Detection and Localization
Aug 29, 2019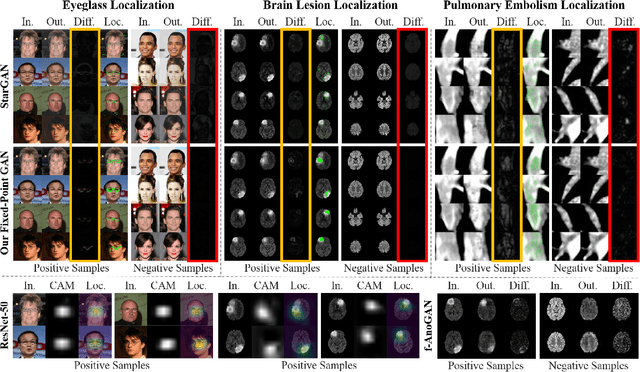

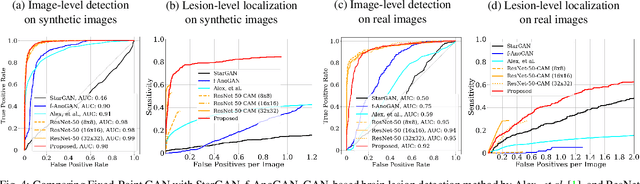
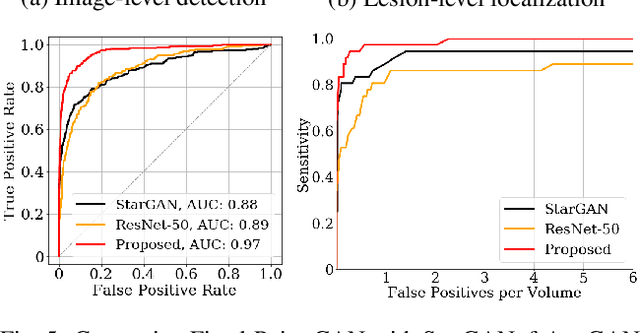
Generative adversarial networks (GANs) have ushered in a revolution in image-to-image translation. The development and proliferation of GANs raises an interesting question: can we train a GAN to remove an object, if present, from an image while otherwise preserving the image? Specifically, can a GAN "virtually heal" anyone by turning his medical image, with an unknown health status (diseased or healthy), into a healthy one, so that diseased regions could be revealed by subtracting those two images? Such a task requires a GAN to identify a minimal subset of target pixels for domain translation, an ability that we call fixed-point translation, which no GAN is equipped with yet. Therefore, we propose a new GAN, called Fixed-Point GAN, trained by (1) supervising same-domain translation through a conditional identity loss, and (2) regularizing cross-domain translation through revised adversarial, domain classification, and cycle consistency loss. Based on fixed-point translation, we further derive a novel framework for disease detection and localization using only image-level annotation. Qualitative and quantitative evaluations demonstrate that the proposed method outperforms the state of the art in multi-domain image-to-image translation and that it surpasses predominant weakly-supervised localization methods in both disease detection and localization. Implementation is available at https://github.com/jlianglab/Fixed-Point-GAN.
Unsupervised Multi-Modal Medical Image Registration via Discriminator-Free Image-to-Image Translation
Apr 28, 2022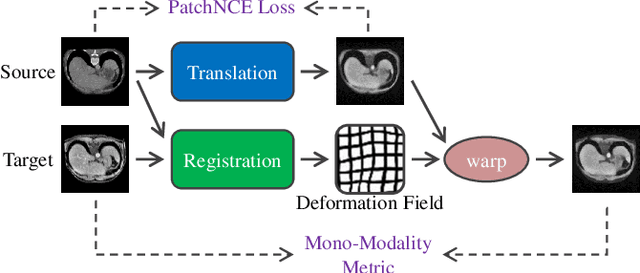
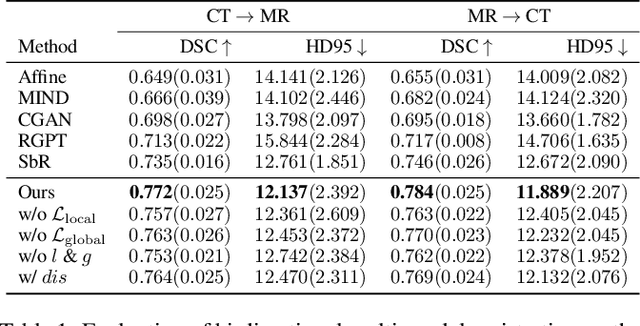
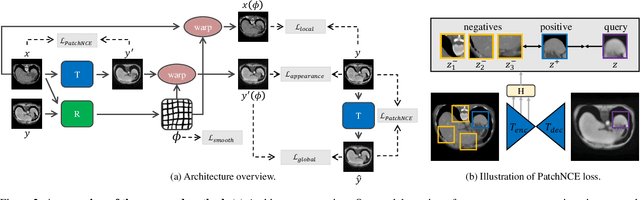
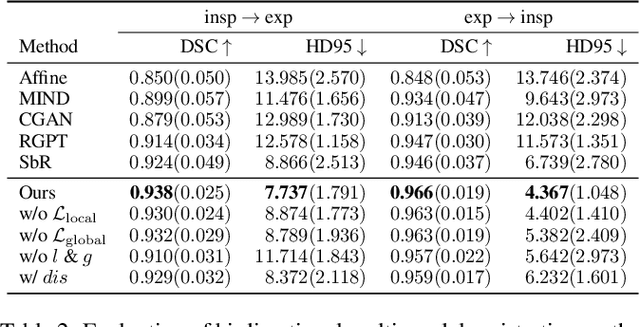
In clinical practice, well-aligned multi-modal images, such as Magnetic Resonance (MR) and Computed Tomography (CT), together can provide complementary information for image-guided therapies. Multi-modal image registration is essential for the accurate alignment of these multi-modal images. However, it remains a very challenging task due to complicated and unknown spatial correspondence between different modalities. In this paper, we propose a novel translation-based unsupervised deformable image registration approach to convert the multi-modal registration problem to a mono-modal one. Specifically, our approach incorporates a discriminator-free translation network to facilitate the training of the registration network and a patchwise contrastive loss to encourage the translation network to preserve object shapes. Furthermore, we propose to replace an adversarial loss, that is widely used in previous multi-modal image registration methods, with a pixel loss in order to integrate the output of translation into the target modality. This leads to an unsupervised method requiring no ground-truth deformation or pairs of aligned images for training. We evaluate four variants of our approach on the public Learn2Reg 2021 datasets \cite{hering2021learn2reg}. The experimental results demonstrate that the proposed architecture achieves state-of-the-art performance. Our code is available at https://github.com/heyblackC/DFMIR.
Multi-Mapping Image-to-Image Translation with Central Biasing Normalization
Oct 11, 2018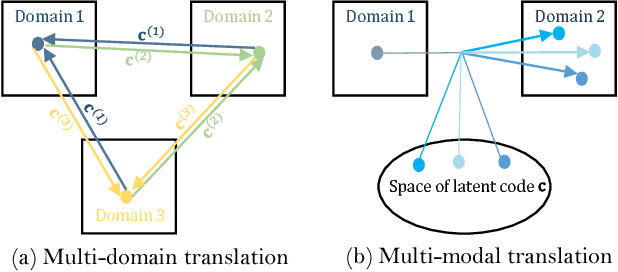
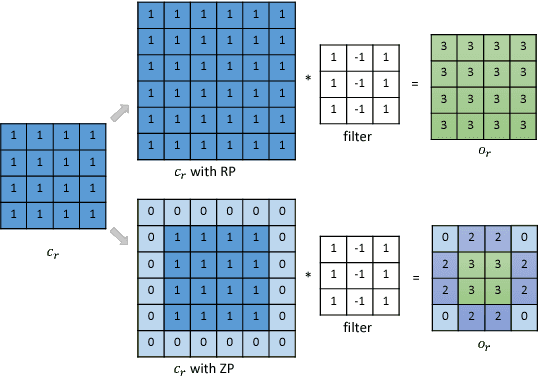
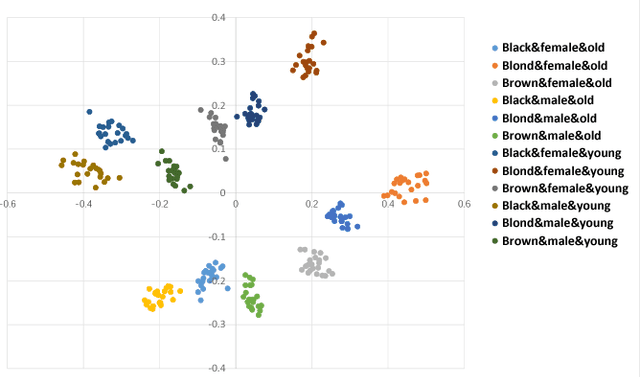

Image-to-image translation is a class of image processing and vision problems that translates an image to a different style or domain. To improve the capacity and performance of one-to-one translation models, multi-mapping image translation have been attempting to extend them for multiple mappings by injecting latent code. Through the analysis of the existing latent code injection models, we find that latent code can determine the target mapping of a generator by controlling the output statistical properties, especially the mean value. However, we find that in some cases the normalization will reduce the consistency of same mapping or the diversity of different mappings. After mathematical analysis, we find the reason behind that is that the distributions of same mapping become inconsistent after batch normalization, and that the effects of latent code are eliminated after instance normalization. To solve these problems, we propose consistency within diversity design criteria for multi-mapping networks. Based on the design criteria, we propose central biasing normalization (CBN) to replace existing latent code injection. CBN can be easily integrated into existing multi-mapping models, significantly reducing model parameters. Experiments show that the results of our method is more stable and diverse than that of existing models. https://github.com/Xiaoming-Yu/cbn .
Unsupervised Image-to-Image Translation via Pre-trained StyleGAN2 Network
Oct 27, 2020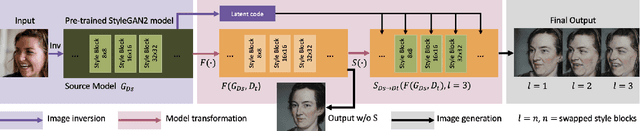



Image-to-Image (I2I) translation is a heated topic in academia, and it also has been applied in real-world industry for tasks like image synthesis, super-resolution, and colorization. However, traditional I2I translation methods train data in two or more domains together. This requires lots of computation resources. Moreover, the results are of lower quality, and they contain many more artifacts. The training process could be unstable when the data in different domains are not balanced, and modal collapse is more likely to happen. We proposed a new I2I translation method that generates a new model in the target domain via a series of model transformations on a pre-trained StyleGAN2 model in the source domain. After that, we proposed an inversion method to achieve the conversion between an image and its latent vector. By feeding the latent vector into the generated model, we can perform I2I translation between the source domain and target domain. Both qualitative and quantitative evaluations were conducted to prove that the proposed method can achieve outstanding performance in terms of image quality, diversity and semantic similarity to the input and reference images compared to state-of-the-art works.
Unsupervised Image-to-Image Translation with Stacked Cycle-Consistent Adversarial Networks
Jul 28, 2018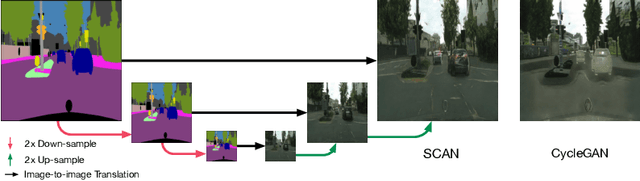
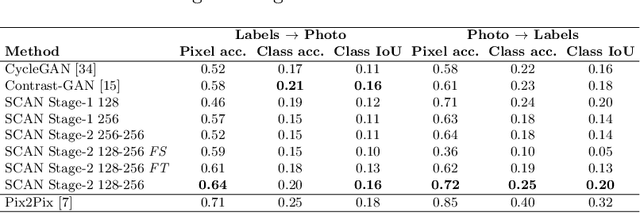
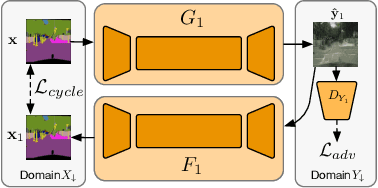
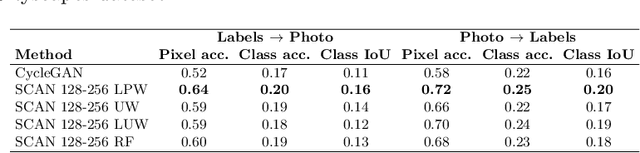
Recent studies on unsupervised image-to-image translation have made a remarkable progress by training a pair of generative adversarial networks with a cycle-consistent loss. However, such unsupervised methods may generate inferior results when the image resolution is high or the two image domains are of significant appearance differences, such as the translations between semantic layouts and natural images in the Cityscapes dataset. In this paper, we propose novel Stacked Cycle-Consistent Adversarial Networks (SCANs) by decomposing a single translation into multi-stage transformations, which not only boost the image translation quality but also enable higher resolution image-to-image translations in a coarse-to-fine manner. Moreover, to properly exploit the information from the previous stage, an adaptive fusion block is devised to learn a dynamic integration of the current stage's output and the previous stage's output. Experiments on multiple datasets demonstrate that our proposed approach can improve the translation quality compared with previous single-stage unsupervised methods.
Towards Realistic Underwater Dataset Generation and Color Restoration
Dec 16, 2022
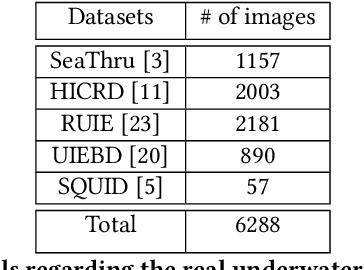

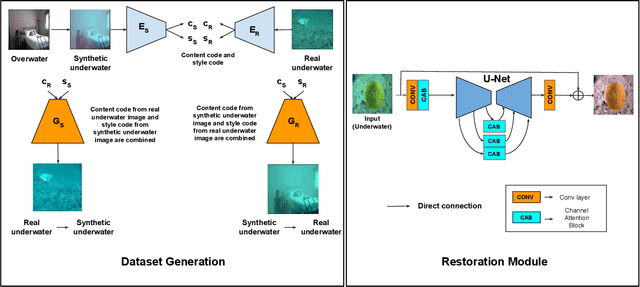
Recovery of true color from underwater images is an ill-posed problem. This is because the wide-band attenuation coefficients for the RGB color channels depend on object range, reflectance, etc. which are difficult to model. Also, there is backscattering due to suspended particles in water. Thus, most existing deep-learning based color restoration methods, which are trained on synthetic underwater datasets, do not perform well on real underwater data. This can be attributed to the fact that synthetic data cannot accurately represent real conditions. To address this issue, we use an image to image translation network to bridge the gap between the synthetic and real domains by translating images from synthetic underwater domain to real underwater domain. Using this multimodal domain adaptation technique, we create a dataset that can capture a diverse array of underwater conditions. We then train a simple but effective CNN based network on our domain adapted dataset to perform color restoration. Code and pre-trained models can be accessed at https://github.com/nehamjain10/TRUDGCR