 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
DeepHist: Differentiable Joint and Color Histogram Layers for Image-to-Image Translation
May 06, 2020
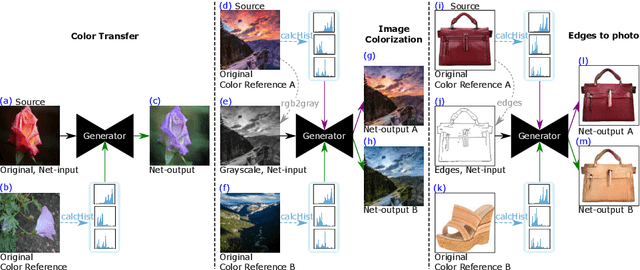
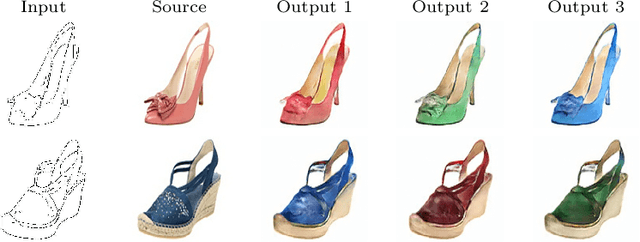

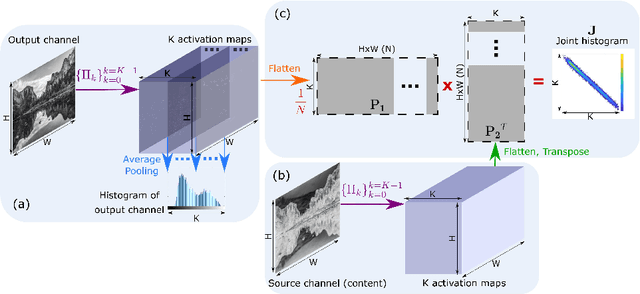
We present the DeepHist - a novel Deep Learning framework for augmenting a network by histogram layers and demonstrate its strength by addressing image-to-image translation problems. Specifically, given an input image and a reference color distribution we aim to generate an output image with the structural appearance (content) of the input (source) yet with the colors of the reference. The key idea is a new technique for a differentiable construction of joint and color histograms of the output images. We further define a color distribution loss based on the Earth Mover's Distance between the output's and the reference's color histograms and a Mutual Information loss based on the joint histograms of the source and the output images. Promising results are shown for the tasks of color transfer, image colorization and edges $\rightarrow$ photo, where the color distribution of the output image is controlled. Comparison to Pix2Pix and CyclyGANs are shown.
Bridging the Gap between Label- and Reference-based Synthesis in Multi-attribute Image-to-Image Translation
Oct 11, 2021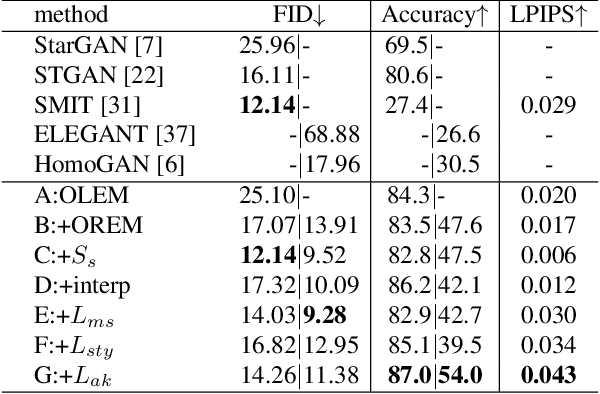
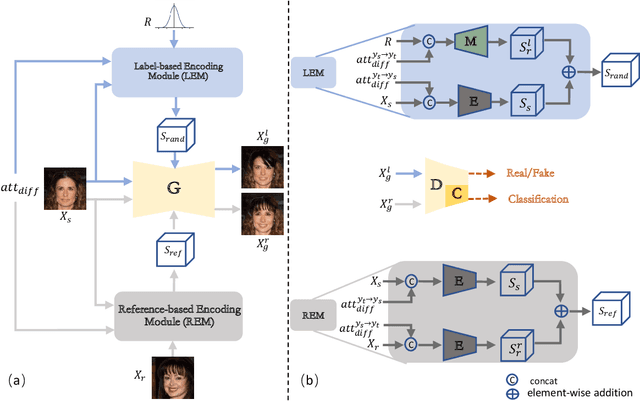


The image-to-image translation (I2IT) model takes a target label or a reference image as the input, and changes a source into the specified target domain. The two types of synthesis, either label- or reference-based, have substantial differences. Particularly, the label-based synthesis reflects the common characteristics of the target domain, and the reference-based shows the specific style similar to the reference. This paper intends to bridge the gap between them in the task of multi-attribute I2IT. We design the label- and reference-based encoding modules (LEM and REM) to compare the domain differences. They first transfer the source image and target label (or reference) into a common embedding space, by providing the opposite directions through the attribute difference vector. Then the two embeddings are simply fused together to form the latent code S_rand (or S_ref), reflecting the domain style differences, which is injected into each layer of the generator by SPADE. To link LEM and REM, so that two types of results benefit each other, we encourage the two latent codes to be close, and set up the cycle consistency between the forward and backward translations on them. Moreover, the interpolation between the S_rand and S_ref is also used to synthesize an extra image. Experiments show that label- and reference-based synthesis are indeed mutually promoted, so that we can have the diverse results from LEM, and high quality results with the similar style of the reference.
Anime-to-Real Clothing: Cosplay Costume Generation via Image-to-Image Translation
Aug 26, 2020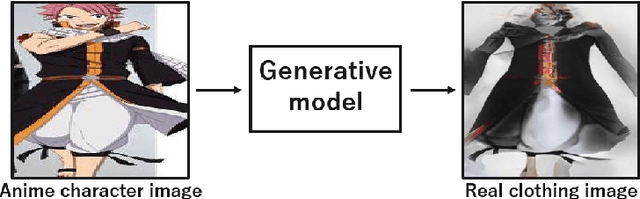


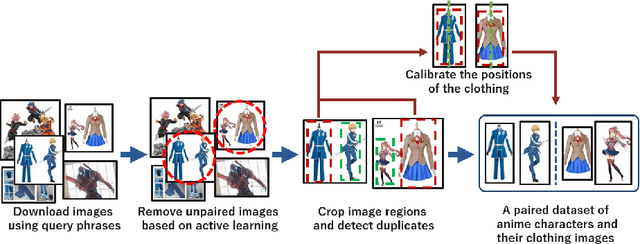
Cosplay has grown from its origins at fan conventions into a billion-dollar global dress phenomenon. To facilitate imagination and reinterpretation from animated images to real garments, this paper presents an automatic costume image generation method based on image-to-image translation. Cosplay items can be significantly diverse in their styles and shapes, and conventional methods cannot be directly applied to the wide variation in clothing images that are the focus of this study. To solve this problem, our method starts by collecting and preprocessing web images to prepare a cleaned, paired dataset of the anime and real domains. Then, we present a novel architecture for generative adversarial networks (GANs) to facilitate high-quality cosplay image generation. Our GAN consists of several effective techniques to fill the gap between the two domains and improve both the global and local consistency of generated images. Experiments demonstrated that, with two types of evaluation metrics, the proposed GAN achieves better performance than existing methods. We also showed that the images generated by the proposed method are more realistic than those generated by the conventional methods. Our codes and pretrained model are available on the web.
Cross-modal Face- and Voice-style Transfer
Mar 01, 2023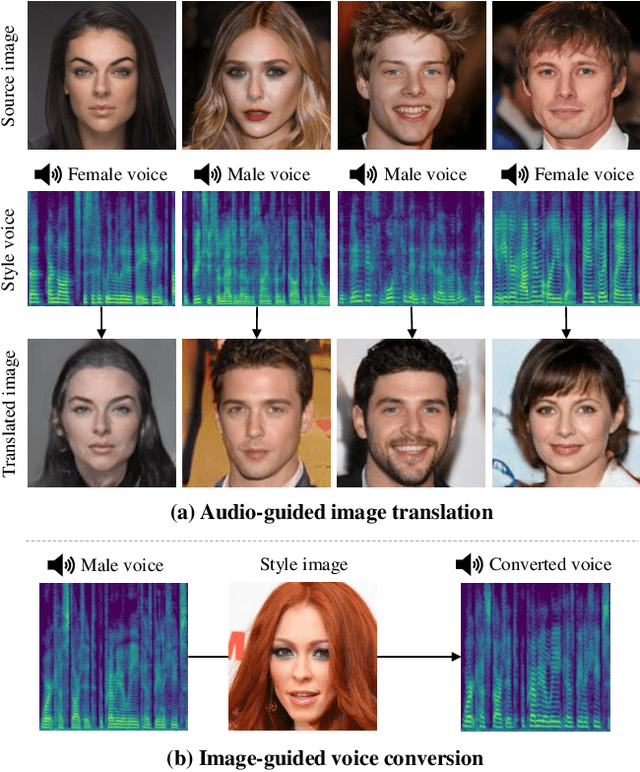

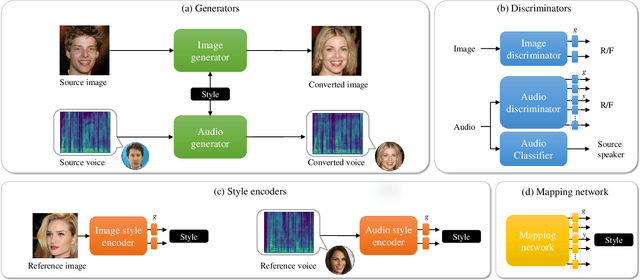
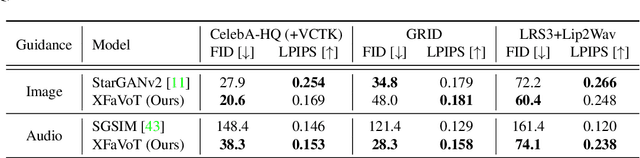
Image-to-image translation and voice conversion enable the generation of a new facial image and voice while maintaining some of the semantics such as a pose in an image and linguistic content in audio, respectively. They can aid in the content-creation process in many applications. However, as they are limited to the conversion within each modality, matching the impression of the generated face and voice remains an open question. We propose a cross-modal style transfer framework called XFaVoT that jointly learns four tasks: image translation and voice conversion tasks with audio or image guidance, which enables the generation of ``face that matches given voice" and ``voice that matches given face", and intra-modality translation tasks with a single framework. Experimental results on multiple datasets show that XFaVoT achieves cross-modal style translation of image and voice, outperforming baselines in terms of quality, diversity, and face-voice correspondence.
Unsupervised Multi-Modal Image Registration via Geometry Preserving Image-to-Image Translation
Mar 18, 2020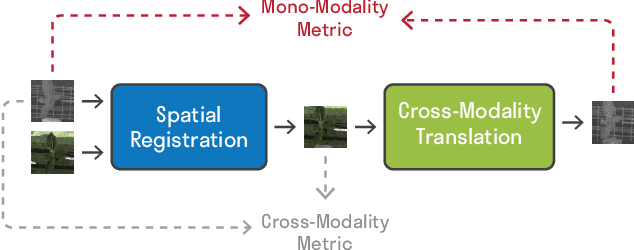
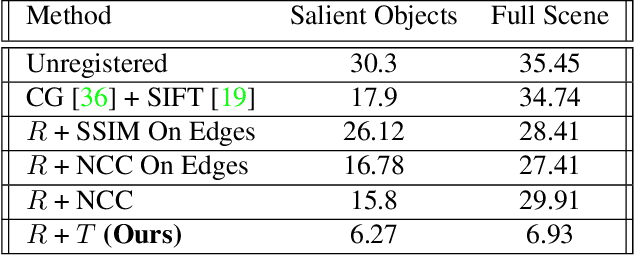
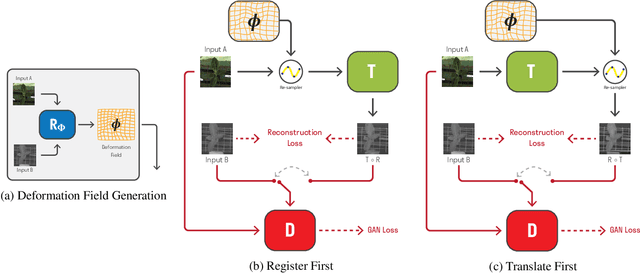
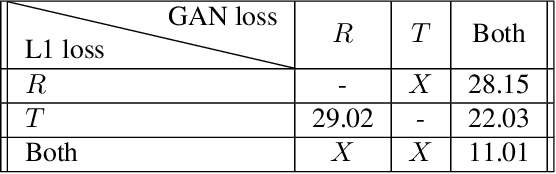
Many applications, such as autonomous driving, heavily rely on multi-modal data where spatial alignment between the modalities is required. Most multi-modal registration methods struggle computing the spatial correspondence between the images using prevalent cross-modality similarity measures. In this work, we bypass the difficulties of developing cross-modality similarity measures, by training an image-to-image translation network on the two input modalities. This learned translation allows training the registration network using simple and reliable mono-modality metrics. We perform multi-modal registration using two networks - a spatial transformation network and a translation network. We show that by encouraging our translation network to be geometry preserving, we manage to train an accurate spatial transformation network. Compared to state-of-the-art multi-modal methods our presented method is unsupervised, requiring no pairs of aligned modalities for training, and can be adapted to any pair of modalities. We evaluate our method quantitatively and qualitatively on commercial datasets, showing that it performs well on several modalities and achieves accurate alignment.
LSC-GAN: Latent Style Code Modeling for Continuous Image-to-image Translation
Oct 11, 2021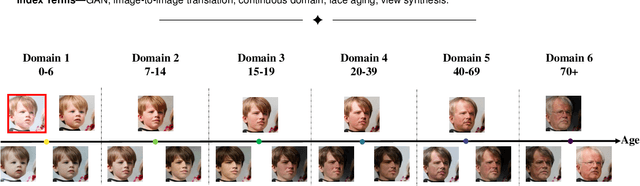

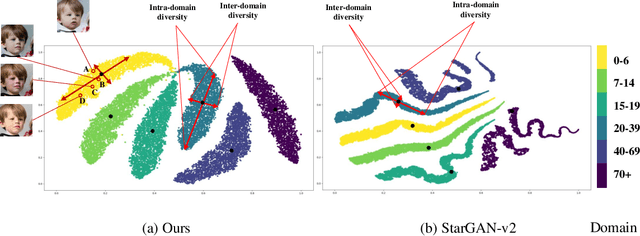
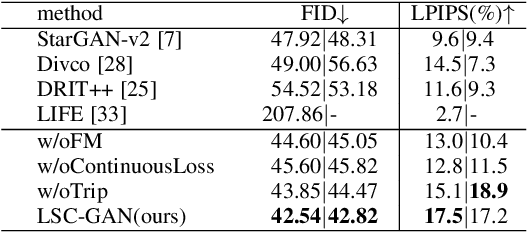
Image-to-image (I2I) translation is usually carried out among discrete domains. However, image domains, often corresponding to a physical value, are usually continuous. In other words, images gradually change with the value, and there exists no obvious gap between different domains. This paper intends to build the model for I2I translation among continuous varying domains. We first divide the whole domain coverage into discrete intervals, and explicitly model the latent style code for the center of each interval. To deal with continuous translation, we design the editing modules, changing the latent style code along two directions. These editing modules help to constrain the codes for domain centers during training, so that the model can better understand the relation among them. To have diverse results, the latent style code is further diversified with either the random noise or features from the reference image, giving the individual style code to the decoder for label-based or reference-based synthesis. Extensive experiments on age and viewing angle translation show that the proposed method can achieve high-quality results, and it is also flexible for users.
InstaGAN: Instance-aware Image-to-Image Translation
Jan 02, 2019
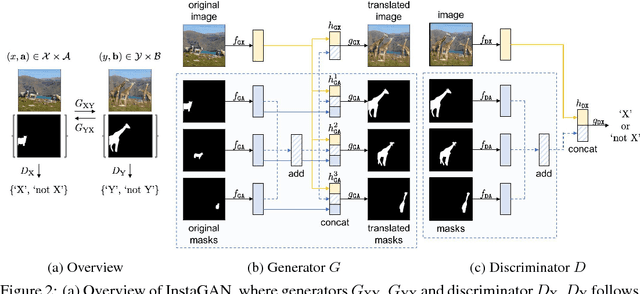
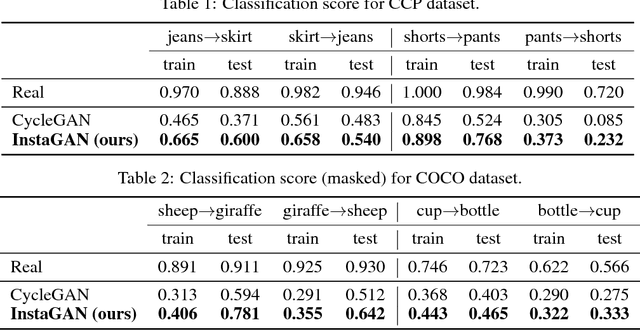
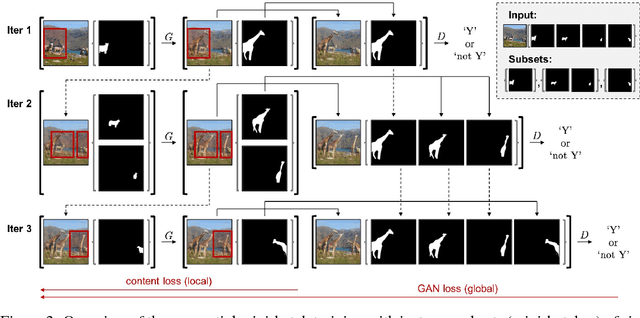
Unsupervised image-to-image translation has gained considerable attention due to the recent impressive progress based on generative adversarial networks (GANs). However, previous methods often fail in challenging cases, in particular, when an image has multiple target instances and a translation task involves significant changes in shape, e.g., translating pants to skirts in fashion images. To tackle the issues, we propose a novel method, coined instance-aware GAN (InstaGAN), that incorporates the instance information (e.g., object segmentation masks) and improves multi-instance transfiguration. The proposed method translates both an image and the corresponding set of instance attributes while maintaining the permutation invariance property of the instances. To this end, we introduce a context preserving loss that encourages the network to learn the identity function outside of target instances. We also propose a sequential mini-batch inference/training technique that handles multiple instances with a limited GPU memory and enhances the network to generalize better for multiple instances. Our comparative evaluation demonstrates the effectiveness of the proposed method on different image datasets, in particular, in the aforementioned challenging cases. Code and results are available in https://github.com/sangwoomo/instagan
Generating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation
Jul 05, 2019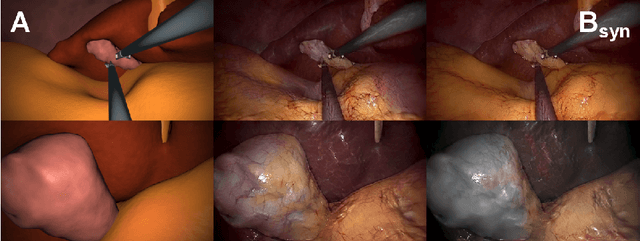
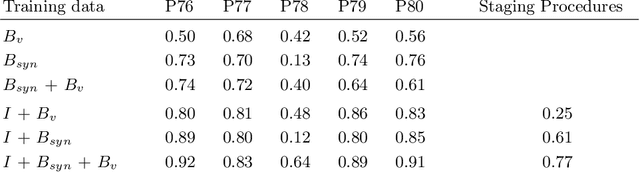
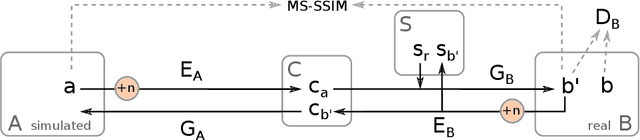
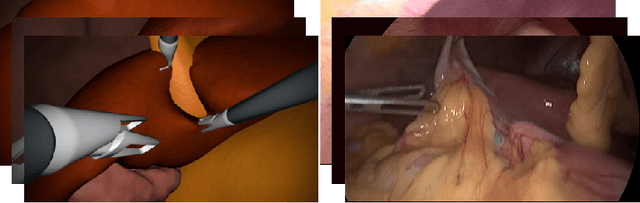
In the medical domain, the lack of large training data sets and benchmarks is often a limiting factor for training deep neural networks. In contrast to expensive manual labeling, computer simulations can generate large and fully labeled data sets with a minimum of manual effort. However, models that are trained on simulated data usually do not translate well to real scenarios. To bridge the domain gap between simulated and real laparoscopic images, we exploit recent advances in unpaired image-to-image translation. We extent an image-to-image translation method to generate a diverse multitude of realistically looking synthetic images based on images from a simple laparoscopy simulation. By incorporating means to ensure that the image content is preserved during the translation process, we ensure that the labels given for the simulated images remain valid for their realistically looking translations. This way, we are able to generate a large, fully labeled synthetic data set of laparoscopic images with realistic appearance. We show that this data set can be used to train models for the task of liver segmentation of laparoscopic images. We achieve average dice scores of up to 0.89 in some patients without manually labeling a single laparoscopic image and show that using our synthetic data to pre-train models can greatly improve their performance. The synthetic data set will be made publicly available, fully labeled with segmentation maps, depth maps, normal maps, and positions of tools and camera (http://opencas.dkfz.de/image2image).
Semi-supervised Hand Appearance Recovery via Structure Disentanglement and Dual Adversarial Discrimination
Mar 11, 2023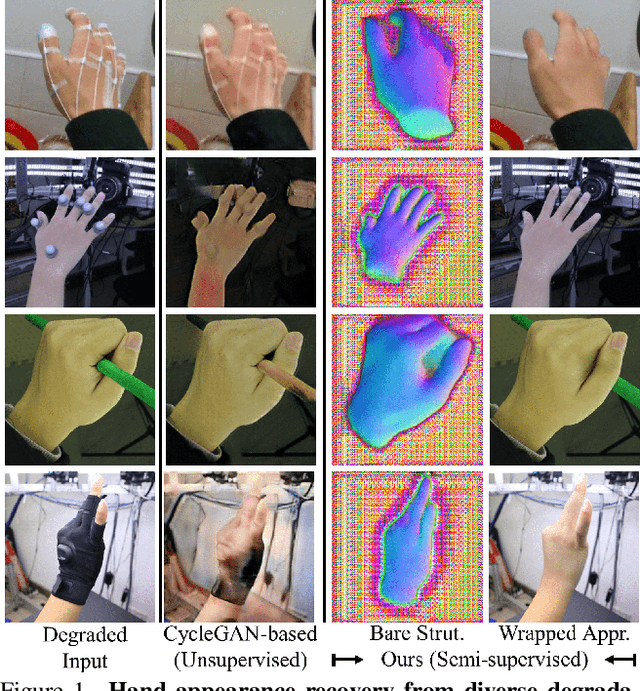
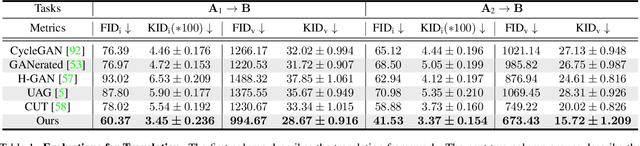

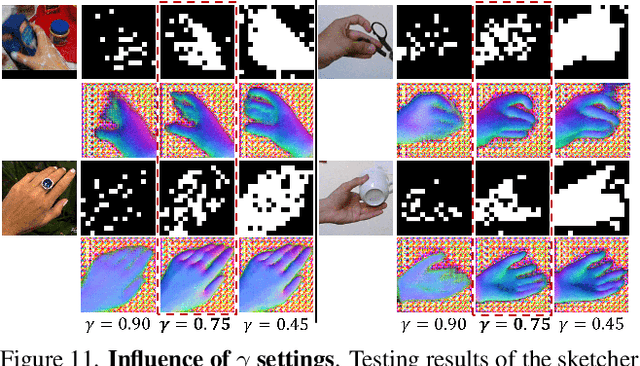
Enormous hand images with reliable annotations are collected through marker-based MoCap. Unfortunately, degradations caused by markers limit their application in hand appearance reconstruction. A clear appearance recovery insight is an image-to-image translation trained with unpaired data. However, most frameworks fail because there exists structure inconsistency from a degraded hand to a bare one. The core of our approach is to first disentangle the bare hand structure from those degraded images and then wrap the appearance to this structure with a dual adversarial discrimination (DAD) scheme. Both modules take full advantage of the semi-supervised learning paradigm: The structure disentanglement benefits from the modeling ability of ViT, and the translator is enhanced by the dual discrimination on both translation processes and translation results. Comprehensive evaluations have been conducted to prove that our framework can robustly recover photo-realistic hand appearance from diverse marker-contained and even object-occluded datasets. It provides a novel avenue to acquire bare hand appearance data for other downstream learning problems.The codes will be publicly available at https://www.yangangwang.com
Generative Adversarial Network with Multi-Branch Discriminator for Cross-Species Image-to-Image Translation
Jan 24, 2019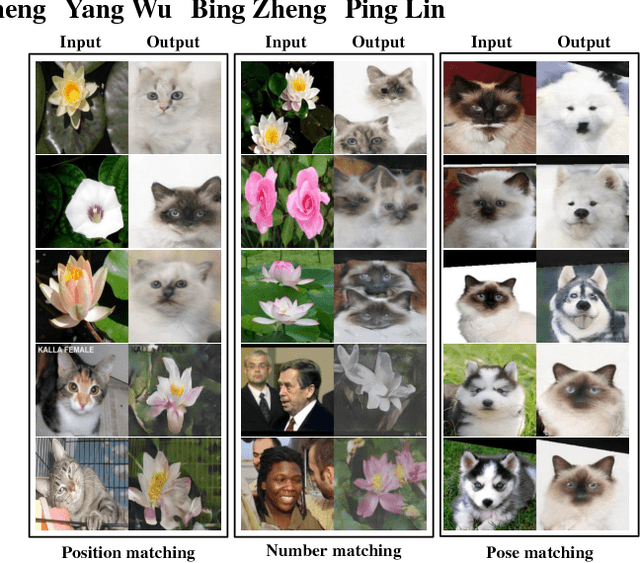
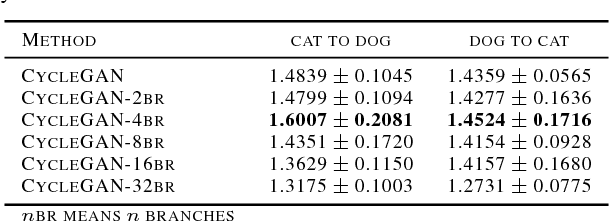
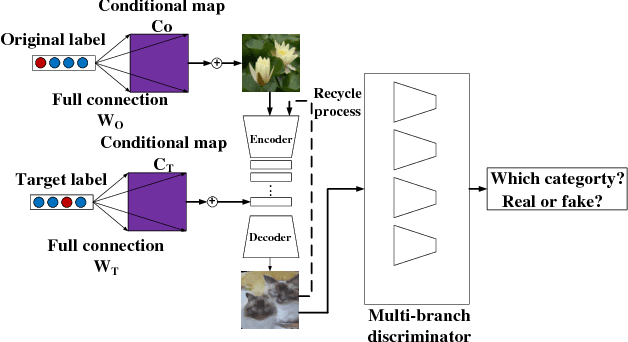

Current approaches have made great progress on image-to-image translation tasks benefiting from the success of image synthesis methods especially generative adversarial networks (GANs). However, existing methods are limited to handling translation tasks between two species while keeping the content matching on the semantic level. A more challenging task would be the translation among more than two species. To explore this new area, we propose a simple yet effective structure of a multi-branch discriminator for enhancing an arbitrary generative adversarial architecture (GAN), named GAN-MBD. It takes advantage of the boosting strategy to break a common discriminator into several smaller ones with fewer parameters, which can enhance the generation and synthesis abilities of GANs efficiently and effectively. Comprehensive experiments show that the proposed multi-branch discriminator can dramatically improve the performance of popular GANs on cross-species image-to-image translation tasks while reducing the number of parameters for computation. The code and some datasets are attached as supplementary materials for reference.