 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Learning Spatial Pyramid Attentive Pooling in Image Synthesis and Image-to-Image Translation
Jan 18, 2019
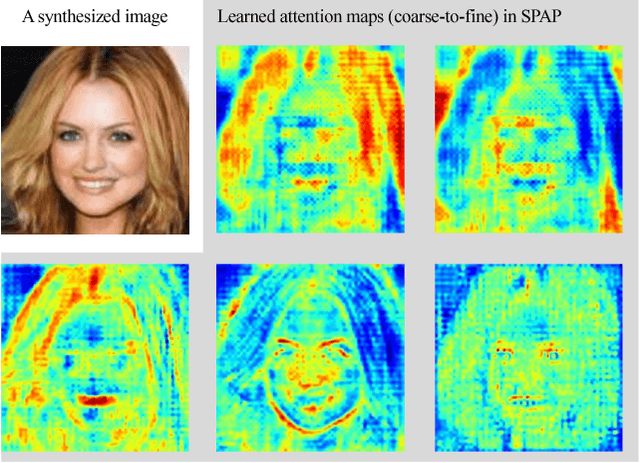
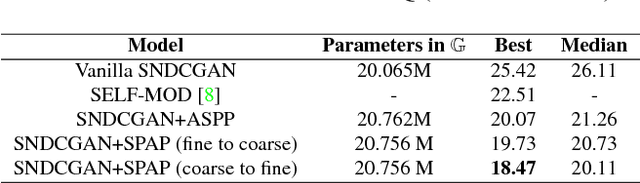
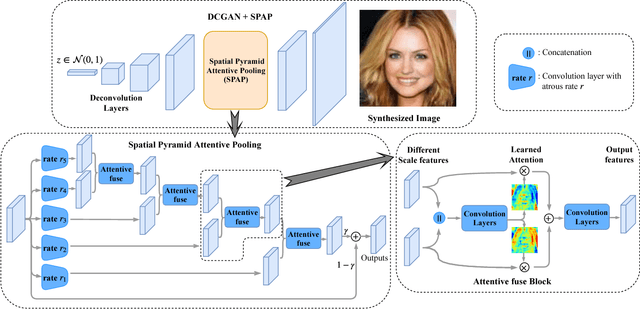
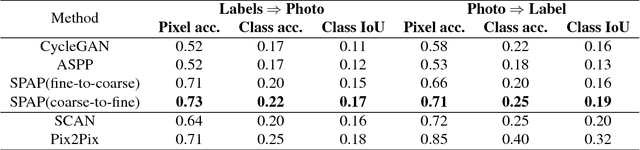
Image synthesis and image-to-image translation are two important generative learning tasks. Remarkable progress has been made by learning Generative Adversarial Networks (GANs)~\cite{goodfellow2014generative} and cycle-consistent GANs (CycleGANs)~\cite{zhu2017unpaired} respectively. This paper presents a method of learning Spatial Pyramid Attentive Pooling (SPAP) which is a novel architectural unit and can be easily integrated into both generators and discriminators in GANs and CycleGANs. The proposed SPAP integrates Atrous spatial pyramid~\cite{chen2018deeplab}, a proposed cascade attention mechanism and residual connections~\cite{he2016deep}. It leverages the advantages of the three components to facilitate effective end-to-end generative learning: (i) the capability of fusing multi-scale information by ASPP; (ii) the capability of capturing relative importance between both spatial locations (especially multi-scale context) or feature channels by attention; (iii) the capability of preserving information and enhancing optimization feasibility by residual connections. Coarse-to-fine and fine-to-coarse SPAP are studied and intriguing attention maps are observed in both tasks. In experiments, the proposed SPAP is tested in GANs on the Celeba-HQ-128 dataset~\cite{karras2017progressive}, and tested in CycleGANs on the Image-to-Image translation datasets including the Cityscape dataset~\cite{cordts2016cityscapes}, Facade and Aerial Maps dataset~\cite{zhu2017unpaired}, both obtaining better performance.
Crossing-Domain Generative Adversarial Networks for Unsupervised Multi-Domain Image-to-Image Translation
Aug 27, 2020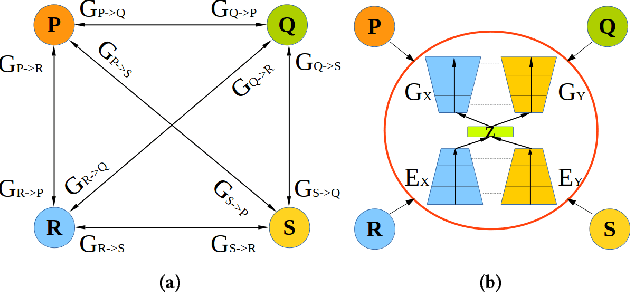
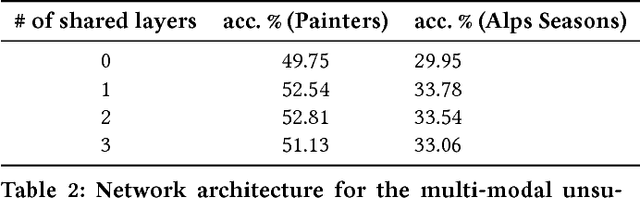
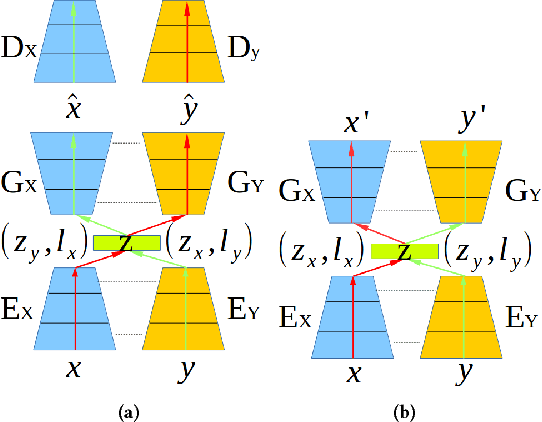
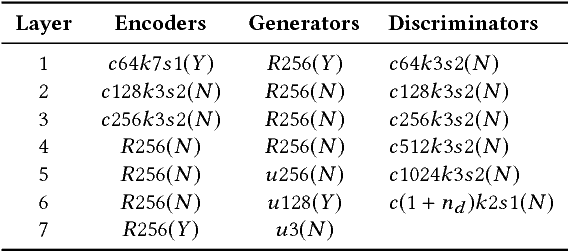
State-of-the-art techniques in Generative Adversarial Networks (GANs) have shown remarkable success in image-to-image translation from peer domain X to domain Y using paired image data. However, obtaining abundant paired data is a non-trivial and expensive process in the majority of applications. When there is a need to translate images across n domains, if the training is performed between every two domains, the complexity of the training will increase quadratically. Moreover, training with data from two domains only at a time cannot benefit from data of other domains, which prevents the extraction of more useful features and hinders the progress of this research area. In this work, we propose a general framework for unsupervised image-to-image translation across multiple domains, which can translate images from domain X to any a domain without requiring direct training between the two domains involved in image translation. A byproduct of the framework is the reduction of computing time and computing resources, since it needs less time than training the domains in pairs as is done in state-of-the-art works. Our proposed framework consists of a pair of encoders along with a pair of GANs which learns high-level features across different domains to generate diverse and realistic samples from. Our framework shows competing results on many image-to-image tasks compared with state-of-the-art techniques.
Translating Simulation Images to X-ray Images via Multi-Scale Semantic Matching
Apr 16, 2023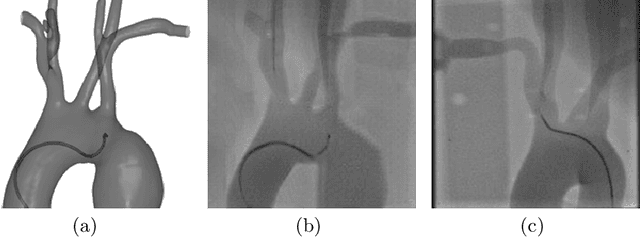
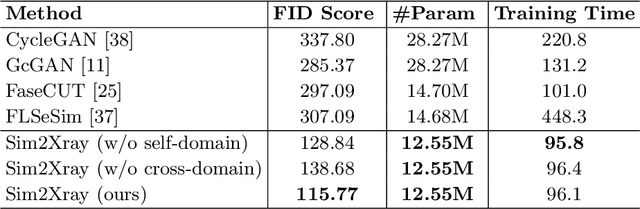
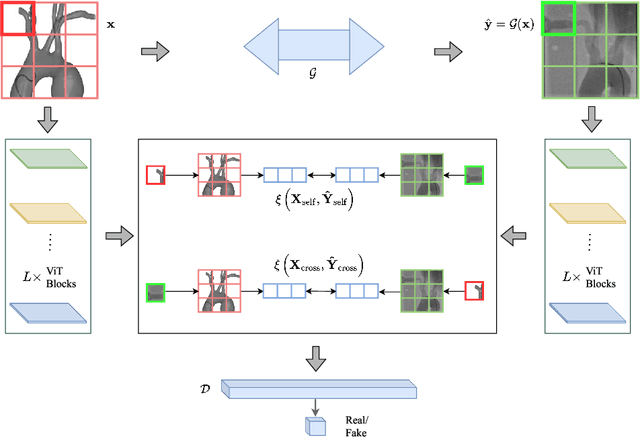
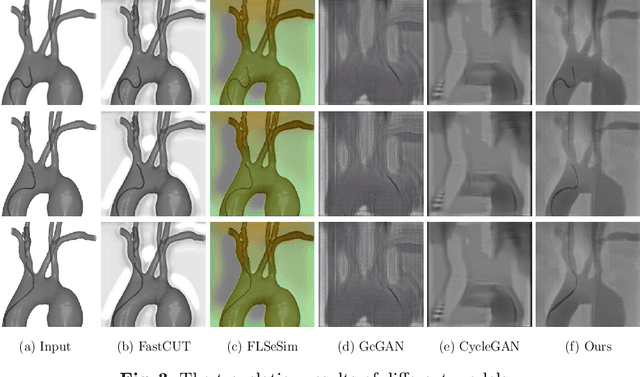
Endovascular intervention training is increasingly being conducted in virtual simulators. However, transferring the experience from endovascular simulators to the real world remains an open problem. The key challenge is the virtual environments are usually not realistically simulated, especially the simulation images. In this paper, we propose a new method to translate simulation images from an endovascular simulator to X-ray images. Previous image-to-image translation methods often focus on visual effects and neglect structure information, which is critical for medical images. To address this gap, we propose a new method that utilizes multi-scale semantic matching. We apply self-domain semantic matching to ensure that the input image and the generated image have the same positional semantic relationships. We further apply cross-domain matching to eliminate the effects of different styles. The intensive experiment shows that our method generates realistic X-ray images and outperforms other state-of-the-art approaches by a large margin. We also collect a new large-scale dataset to serve as the new benchmark for this task. Our source code and dataset will be made publicly available.
Unpaired Image-to-Image Translation via Latent Energy Transport
Dec 01, 2020
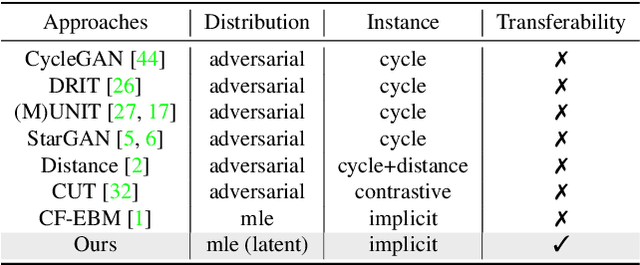
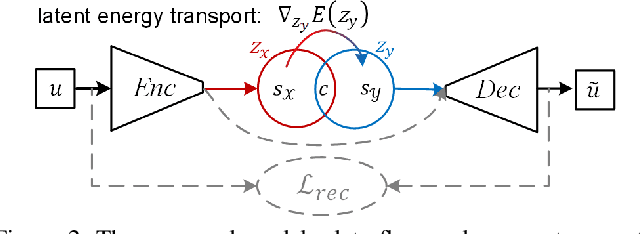

Image-to-image translation aims to preserve source contents while translating to discriminative target styles between two visual domains. Most works apply adversarial learning in the ambient image space, which could be computationally expensive and challenging to train. In this paper, we propose to deploy an energy-based model (EBM) in the latent space of a pretrained autoencoder for this task. The pretrained autoencoder serves as both a latent code extractor and an image reconstruction worker. Our model is based on the assumption that two domains share the same latent space, where latent representation is implicitly decomposed as a content code and a domain-specific style code. Instead of explicitly extracting the two codes and applying adaptive instance normalization to combine them, our latent EBM can implicitly learn to transport the source style code to the target style code while preserving the content code, which is an advantage over existing image translation methods. This simplified solution also brings us far more efficiency in the one-sided unpaired image translation setting. Qualitative and quantitative comparisons demonstrate superior translation quality and faithfulness for content preservation. To the best of our knowledge, our model is the first to be applicable to 1024$\times$1024-resolution unpaired image translation.
Zero-Shot Contrastive Loss for Text-Guided Diffusion Image Style Transfer
Mar 15, 2023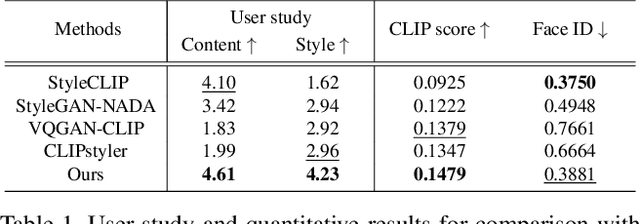
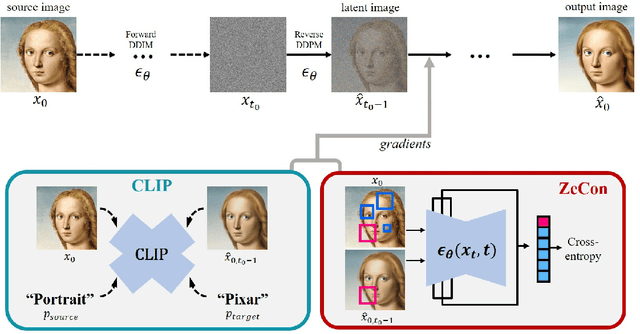
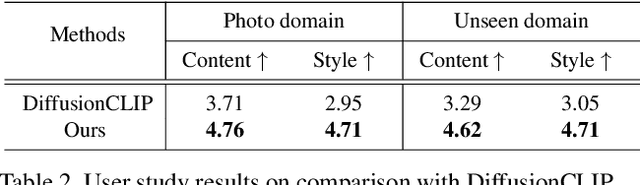
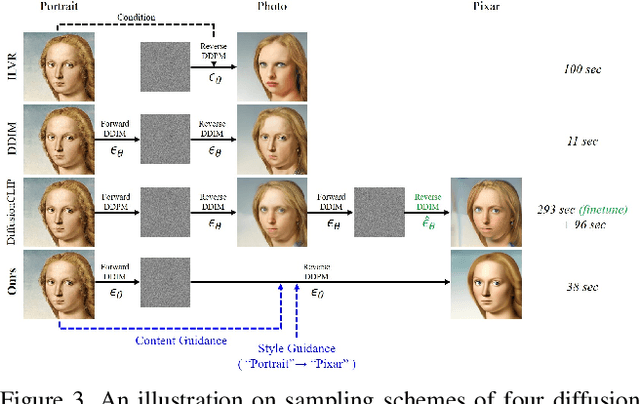
Diffusion models have shown great promise in text-guided image style transfer, but there is a trade-off between style transformation and content preservation due to their stochastic nature. Existing methods require computationally expensive fine-tuning of diffusion models or additional neural network. To address this, here we propose a zero-shot contrastive loss for diffusion models that doesn't require additional fine-tuning or auxiliary networks. By leveraging patch-wise contrastive loss between generated samples and original image embeddings in the pre-trained diffusion model, our method can generate images with the same semantic content as the source image in a zero-shot manner. Our approach outperforms existing methods while preserving content and requiring no additional training, not only for image style transfer but also for image-to-image translation and manipulation. Our experimental results validate the effectiveness of our proposed method.
Biphasic Learning of GANs for High-Resolution Image-to-Image Translation
Apr 14, 2019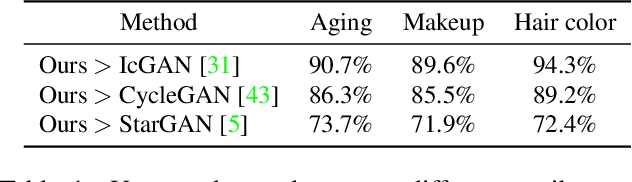
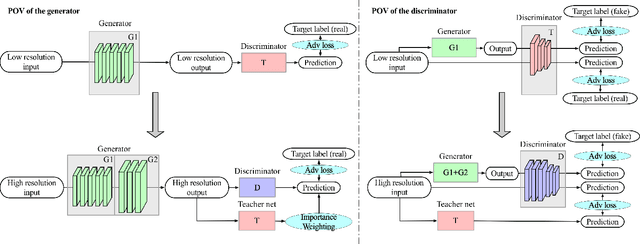
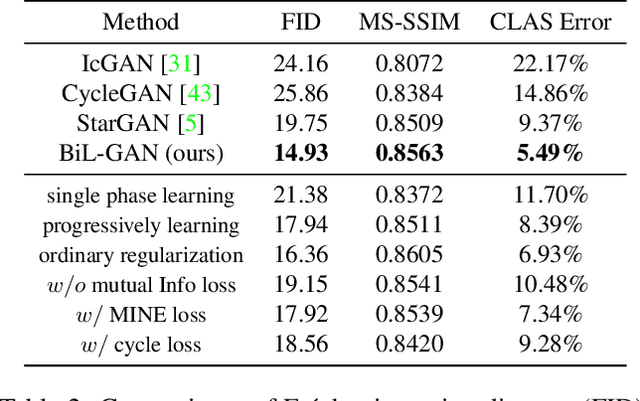

Despite that the performance of image-to-image translation has been significantly improved by recent progress in generative models, current methods still suffer from severe degradation in training stability and sample quality when applied to the high-resolution situation. In this work, we present a novel training framework for GANs, namely biphasic learning, to achieve image-to-image translation in multiple visual domains at $1024^2$ resolution. Our core idea is to design an adjustable objective function that varies across training phases. Within the biphasic learning framework, we propose a novel inherited adversarial loss to achieve the enhancement of model capacity and stabilize the training phase transition. Furthermore, we introduce a perceptual-level consistency loss through mutual information estimation and maximization. To verify the superiority of the proposed method, we apply it to a wide range of face-related synthesis tasks and conduct experiments on multiple large-scale datasets. Through comprehensive quantitative analyses, we demonstrate that our method significantly outperforms existing methods.
GMM-UNIT: Unsupervised Multi-Domain and Multi-Modal Image-to-Image Translation via Attribute Gaussian Mixture Modeling
Mar 21, 2020

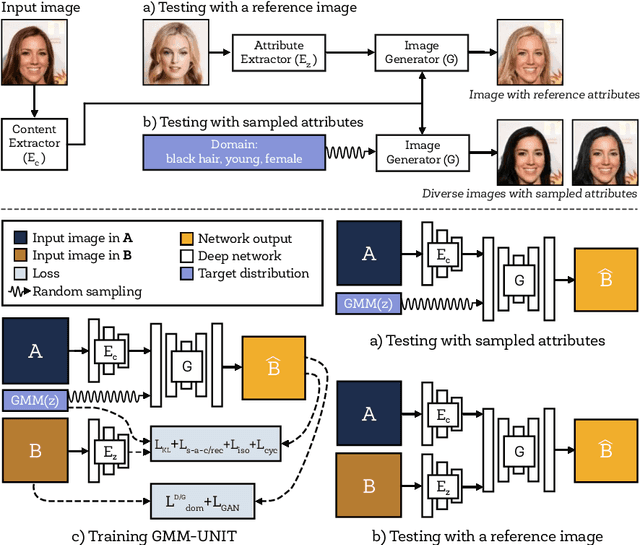

Unsupervised image-to-image translation (UNIT) aims at learning a mapping between several visual domains by using unpaired training images. Recent studies have shown remarkable success for multiple domains but they suffer from two main limitations: they are either built from several two-domain mappings that are required to be learned independently, or they generate low-diversity results, a problem known as mode collapse. To overcome these limitations, we propose a method named GMM-UNIT, which is based on a content-attribute disentangled representation where the attribute space is fitted with a GMM. Each GMM component represents a domain, and this simple assumption has two prominent advantages. First, it can be easily extended to most multi-domain and multi-modal image-to-image translation tasks. Second, the continuous domain encoding allows for interpolation between domains and for extrapolation to unseen domains and translations. Additionally, we show how GMM-UNIT can be constrained down to different methods in the literature, meaning that GMM-UNIT is a unifying framework for unsupervised image-to-image translation.
Toward Multimodal Image-to-Image Translation
Oct 24, 2018

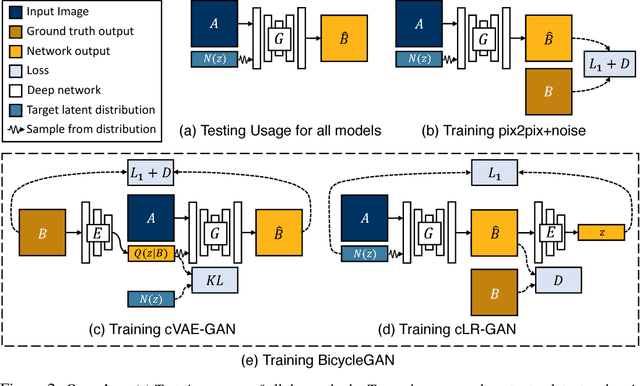
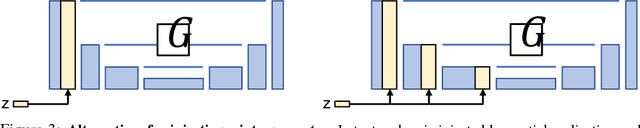
Many image-to-image translation problems are ambiguous, as a single input image may correspond to multiple possible outputs. In this work, we aim to model a \emph{distribution} of possible outputs in a conditional generative modeling setting. The ambiguity of the mapping is distilled in a low-dimensional latent vector, which can be randomly sampled at test time. A generator learns to map the given input, combined with this latent code, to the output. We explicitly encourage the connection between output and the latent code to be invertible. This helps prevent a many-to-one mapping from the latent code to the output during training, also known as the problem of mode collapse, and produces more diverse results. We explore several variants of this approach by employing different training objectives, network architectures, and methods of injecting the latent code. Our proposed method encourages bijective consistency between the latent encoding and output modes. We present a systematic comparison of our method and other variants on both perceptual realism and diversity.
An Efficient Image-to-Image Translation HourGlass-based Architecture for Object Pushing Policy Learning
Aug 02, 2021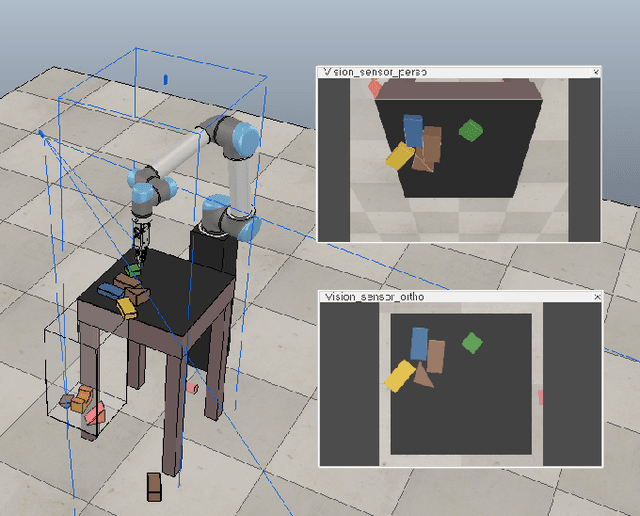
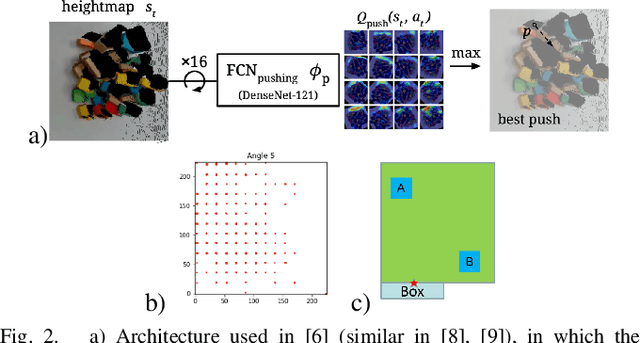
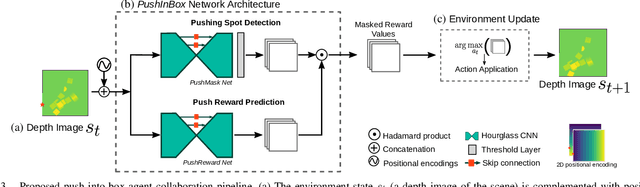
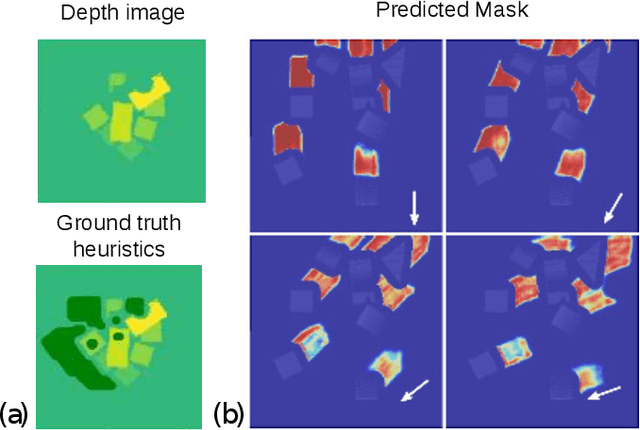
Humans effortlessly solve pushing tasks in everyday life but unlocking these capabilities remains a challenge in robotics because physics models of these tasks are often inaccurate or unattainable. State-of-the-art data-driven approaches learn to compensate for these inaccuracies or replace the approximated physics models altogether. Nevertheless, approaches like Deep Q-Networks (DQNs) suffer from local optima in large state-action spaces. Furthermore, they rely on well-chosen deep learning architectures and learning paradigms. In this paper, we propose to frame the learning of pushing policies (where to push and how) by DQNs as an image-to-image translation problem and exploit an Hourglass-based architecture. We present an architecture combining a predictor of which pushes lead to changes in the environment with a state-action value predictor dedicated to the pushing task. Moreover, we investigate positional information encoding to learn position-dependent policy behaviors. We demonstrate in simulation experiments with a UR5 robot arm that our overall architecture helps the DQN learn faster and achieve higher performance in a pushing task involving objects with unknown dynamics.