 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
TraVeLGAN: Image-to-image Translation by Transformation Vector Learning
Feb 25, 2019
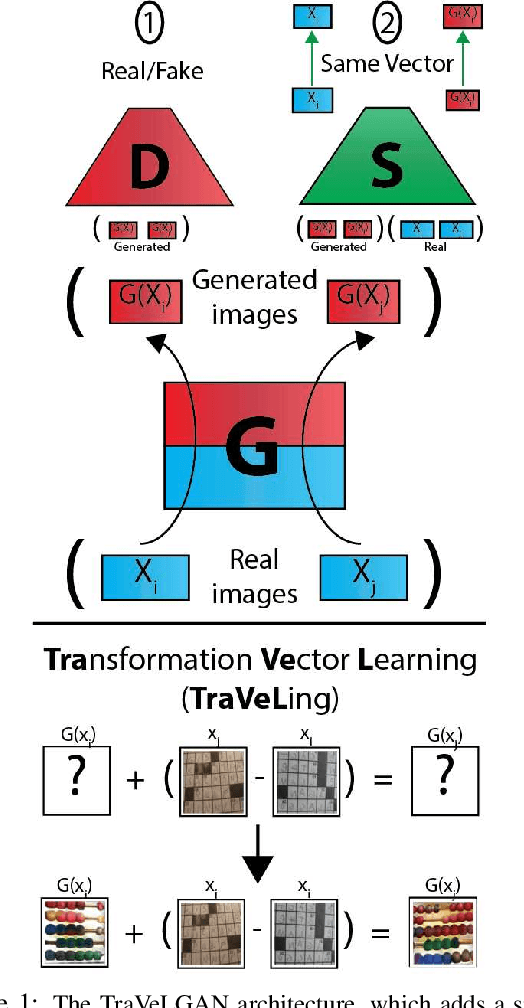
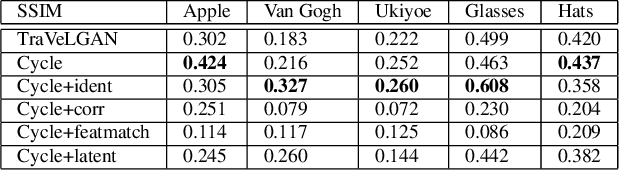

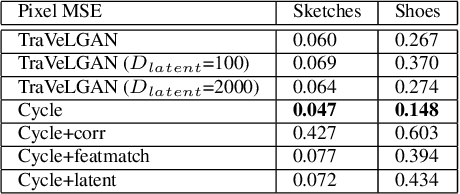
Interest in image-to-image translation has grown substantially in recent years with the success of unsupervised models based on the cycle-consistency assumption. The achievements of these models have been limited to a particular subset of domains where this assumption yields good results, namely homogeneous domains that are characterized by style or texture differences. We tackle the challenging problem of image-to-image translation where the domains are defined by high-level shapes and contexts, as well as including significant clutter and heterogeneity. For this purpose, we introduce a novel GAN based on preserving intra-domain vector transformations in a latent space learned by a siamese network. The traditional GAN system introduced a discriminator network to guide the generator into generating images in the target domain. To this two-network system we add a third: a siamese network that guides the generator so that each original image shares semantics with its generated version. With this new three-network system, we no longer need to constrain the generators with the ubiquitous cycle-consistency restraint. As a result, the generators can learn mappings between more complex domains that differ from each other by large differences - not just style or texture.
Label-Noise Robust Multi-Domain Image-to-Image Translation
May 06, 2019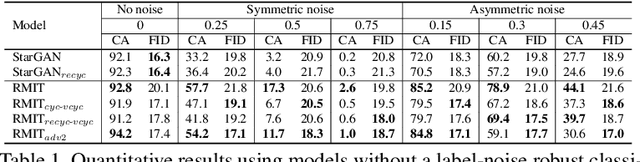
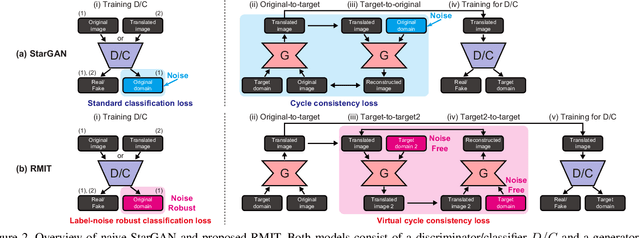


Multi-domain image-to-image translation is a problem where the goal is to learn mappings among multiple domains. This problem is challenging in terms of scalability because it requires the learning of numerous mappings, the number of which increases proportional to the number of domains. However, generative adversarial networks (GANs) have emerged recently as a powerful framework for this problem. In particular, label-conditional extensions (e.g., StarGAN) have become a promising solution owing to their ability to address this problem using only a single unified model. Nonetheless, a limitation is that they rely on the availability of large-scale clean-labeled data, which are often laborious or impractical to collect in a real-world scenario. To overcome this limitation, we propose a novel model called the label-noise robust image-to-image translation model (RMIT) that can learn a clean label conditional generator even when noisy labeled data are only available. In particular, we propose a novel loss called the virtual cycle consistency loss that is able to regularize cyclic reconstruction independently of noisy labeled data, as well as we introduce advanced techniques to boost the performance in practice. Our experimental results demonstrate that RMIT is useful for obtaining label-noise robustness in various settings including synthetic and real-world noise.
Cross-modal tumor segmentation using generative blending augmentation and self training
Apr 04, 2023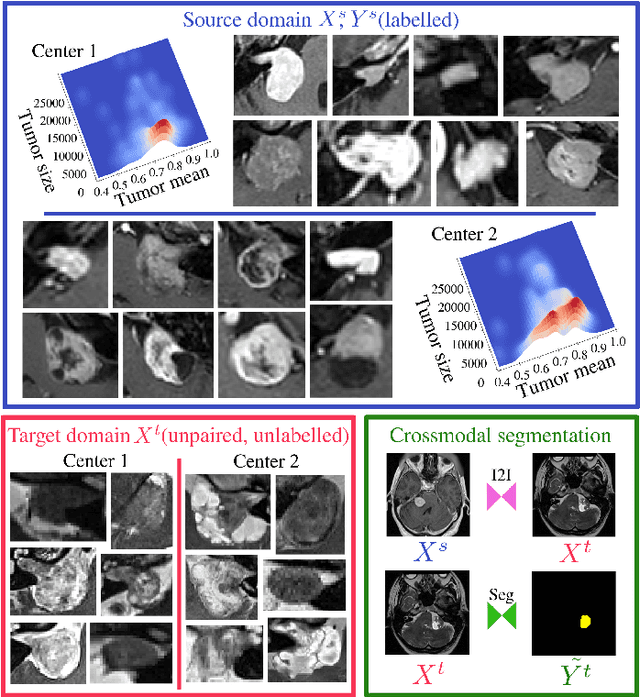
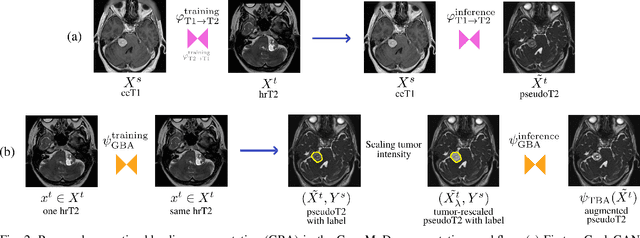
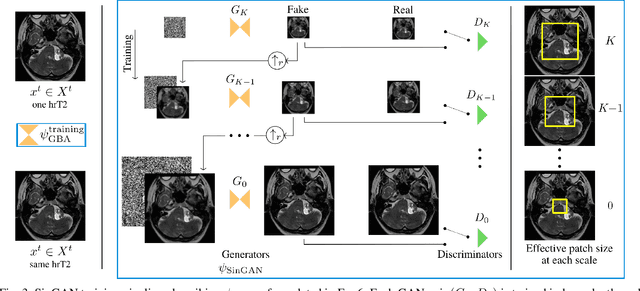
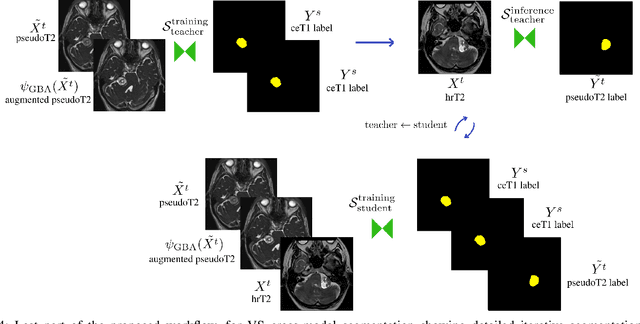
Deep learning for medical imaging is limited by data scarcity and domain shift, which lead to biased training sets that do not accurately represent deployment conditions. A related practical problem is cross-modal segmentation where the objective is to segment unlabelled domains using previously labelled images from other modalites, which is the context of the MICCAI CrossMoDA 2022 challenge on vestibular schwannoma (VS) segmentation. In this context, we propose a VS segmentation method that leverages conventional image-to-image translation and segmentation using iterative self training combined to a dedicated data augmentation technique called Generative Blending Augmentation (GBA). GBA is based on a one-shot 2D SinGAN generative model that allows to realistically diversify target tumor appearances in a downstream segmentation model, improving its generalization power at test time. Our solution ranked first on the VS segmentation task during the validation and test phase of the CrossModa 2022 challenge.
Unsupervised Attention-guided Image to Image Translation
Jun 19, 2018
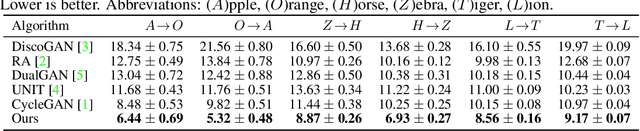
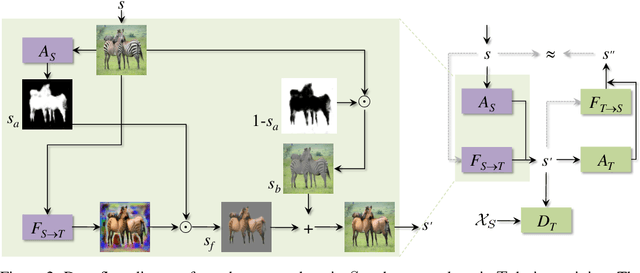

Current unsupervised image-to-image translation techniques struggle to focus their attention on individual objects without altering the background or the way multiple objects interact within a scene. Motivated by the important role of attention in human perception, we tackle this limitation by introducing unsupervised attention mechanisms that are jointly adversarialy trained with the generators and discriminators. We demonstrate qualitatively and quantitatively that our approach is able to attend to relevant regions in the image without requiring supervision, and that by doing so it achieves more realistic mappings compared to recent approaches.
Latent Filter Scaling for Multimodal Unsupervised Image-to-Image Translation
Dec 24, 2018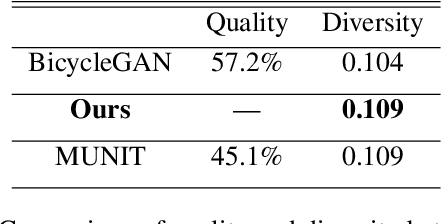
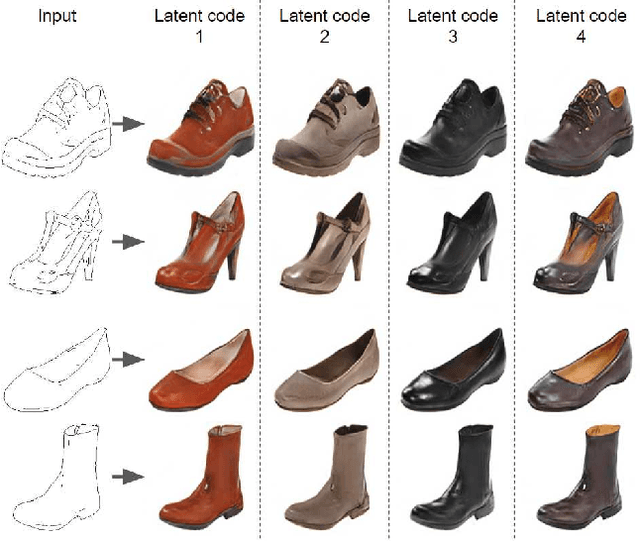


In multimodal unsupervised image-to-image translation tasks, the goal is to translate an image from the source domain to many images in the target domain. We present a simple method that produces higher quality images than current state-of-the-art while maintaining the same amount of multimodal diversity. Previous methods follow the unconditional approach of trying to map the latent code directly to a full-size image. This leads to complicated network architectures with several introduced hyperparameters to tune. By treating the latent code as a modifier of the convolutional filters, we produce multimodal output while maintaining the traditional Generative Adversarial Network (GAN) loss and without additional hyperparameters. The only tuning required by our method controls the tradeoff between variability and quality of generated images. Furthermore, we achieve disentanglement between source domain content and target domain style for free as a by-product of our formulation. We perform qualitative and quantitative experiments showing the advantages of our method compared with the state-of-the art on multiple benchmark image-to-image translation datasets.
Leveraging in-domain supervision for unsupervised image-to-image translation tasks via multi-stream generators
Dec 30, 2021
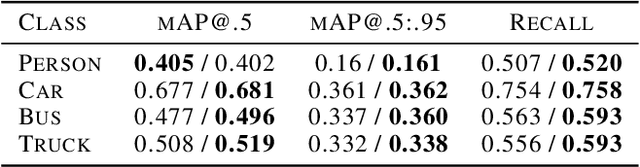


Supervision for image-to-image translation (I2I) tasks is hard to come by, but bears significant effect on the resulting quality. In this paper, we observe that for many Unsupervised I2I (UI2I) scenarios, one domain is more familiar than the other, and offers in-domain prior knowledge, such as semantic segmentation. We argue that for complex scenes, figuring out the semantic structure of the domain is hard, especially with no supervision, but is an important part of a successful I2I operation. We hence introduce two techniques to incorporate this invaluable in-domain prior knowledge for the benefit of translation quality: through a novel Multi-Stream generator architecture, and through a semantic segmentation-based regularization loss term. In essence, we propose splitting the input data according to semantic masks, explicitly guiding the network to different behavior for the different regions of the image. In addition, we propose training a semantic segmentation network along with the translation task, and to leverage this output as a loss term that improves robustness. We validate our approach on urban data, demonstrating superior quality in the challenging UI2I tasks of converting day images to night ones. In addition, we also demonstrate how reinforcing the target dataset with our augmented images improves the training of downstream tasks such as the classical detection one.
Unsupervised Domain Transfer for Science: Exploring Deep Learning Methods for Translation between LArTPC Detector Simulations with Differing Response Models
May 05, 2023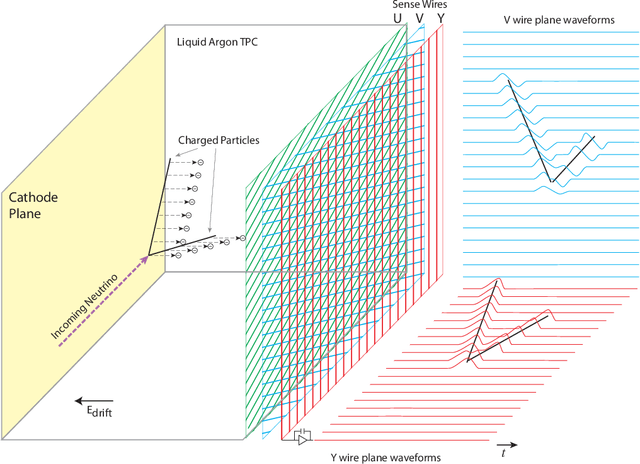
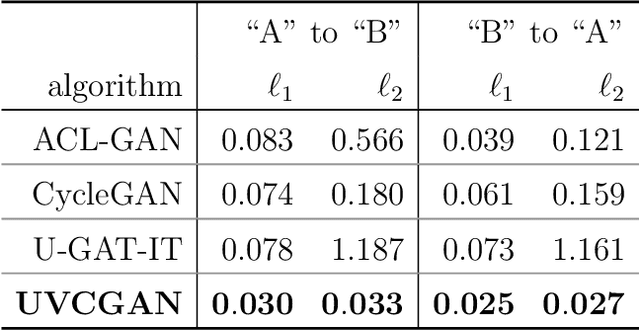
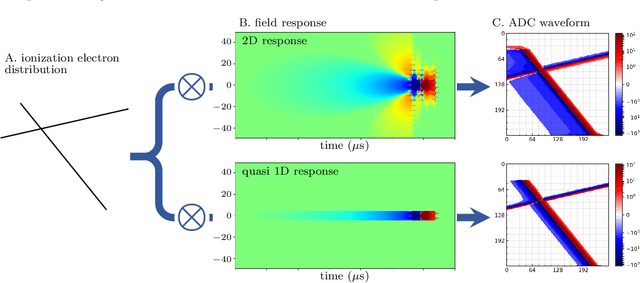
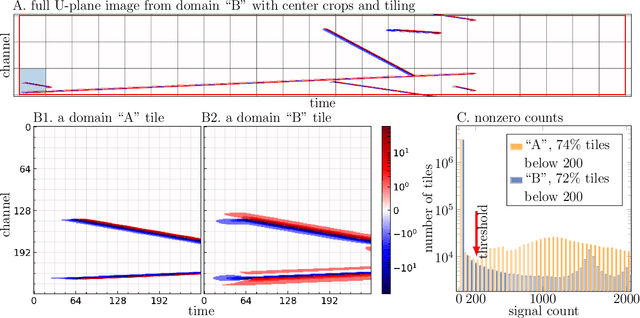
Deep learning (DL) techniques have broad applications in science, especially in seeking to streamline the pathway to potential solutions and discoveries. Frequently, however, DL models are trained on the results of simulation yet applied to real experimental data. As such, any systematic differences between the simulated and real data may degrade the model's performance -- an effect known as "domain shift." This work studies a toy model of the systematic differences between simulated and real data. It presents a fully unsupervised, task-agnostic method to reduce differences between two systematically different samples. The method is based on the recent advances in unpaired image-to-image translation techniques and is validated on two sets of samples of simulated Liquid Argon Time Projection Chamber (LArTPC) detector events, created to illustrate common systematic differences between the simulated and real data in a controlled way. LArTPC-based detectors represent the next-generation particle detectors, producing unique high-resolution particle track data. This work open-sources the generated LArTPC data set, called Simple Liquid-Argon Track Samples (or SLATS), allowing researchers from diverse domains to study the LArTPC-like data for the first time. The code and trained models are available at https://github.com/LS4GAN/uvcgan4slats.
Sem-GAN: Semantically-Consistent Image-to-Image Translation
Jul 12, 2018
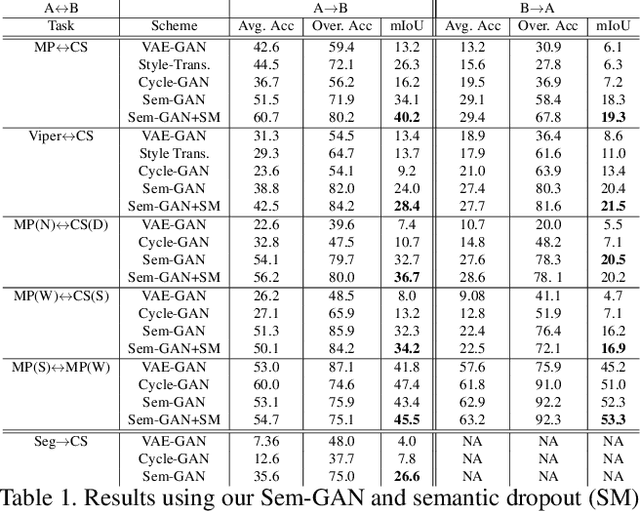
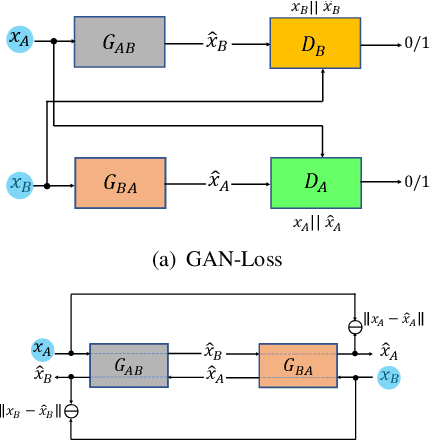
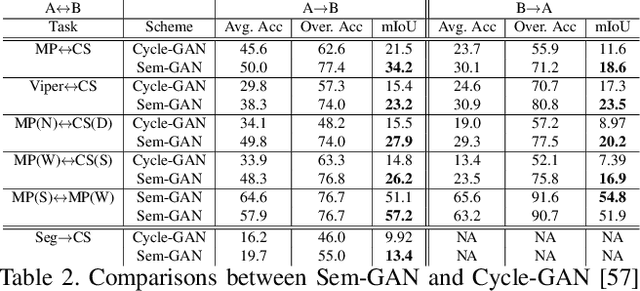
Unpaired image-to-image translation is the problem of mapping an image in the source domain to one in the target domain, without requiring corresponding image pairs. To ensure the translated images are realistically plausible, recent works, such as Cycle-GAN, demands this mapping to be invertible. While, this requirement demonstrates promising results when the domains are unimodal, its performance is unpredictable in a multi-modal scenario such as in an image segmentation task. This is because, invertibility does not necessarily enforce semantic correctness. To this end, we present a semantically-consistent GAN framework, dubbed Sem-GAN, in which the semantics are defined by the class identities of image segments in the source domain as produced by a semantic segmentation algorithm. Our proposed framework includes consistency constraints on the translation task that, together with the GAN loss and the cycle-constraints, enforces that the images when translated will inherit the appearances of the target domain, while (approximately) maintaining their identities from the source domain. We present experiments on several image-to-image translation tasks and demonstrate that Sem-GAN improves the quality of the translated images significantly, sometimes by more than 20% on the FCN score. Further, we show that semantic segmentation models, trained with synthetic images translated via Sem-GAN, leads to significantly better segmentation results than other variants.
EDIT: Exemplar-Domain Aware Image-to-Image Translation
Nov 24, 2019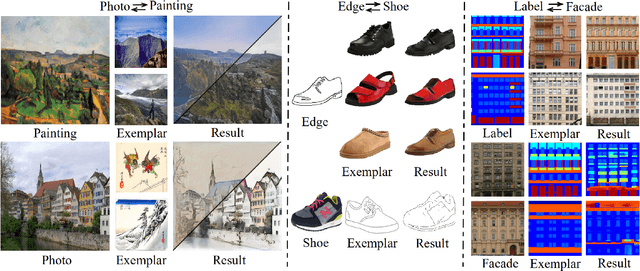
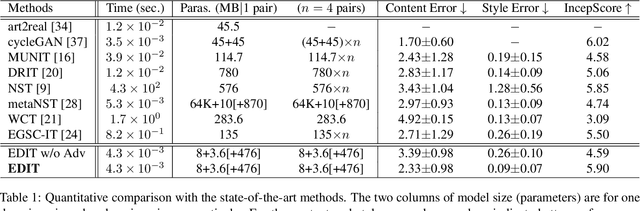
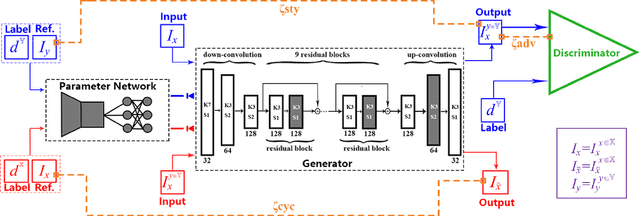
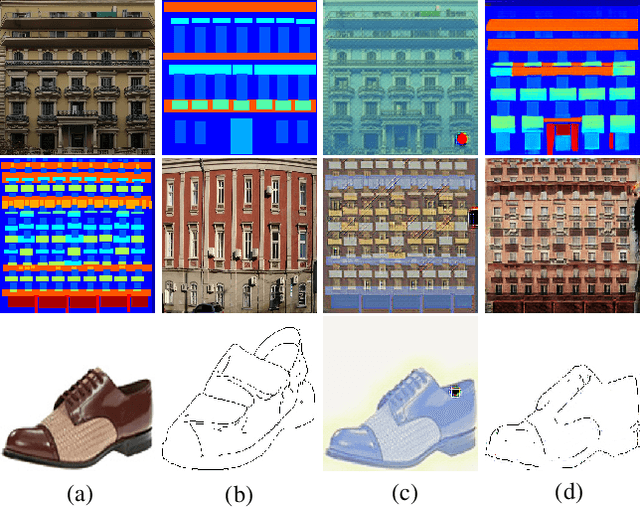
Image-to-image translation is to convert an image of the certain style to another of the target style with the content preserved. A desired translator should be capable to generate diverse results in a controllable (many-to-many) fashion. To this end, we design a novel generative adversarial network, namely exemplar-domain aware image-to-image translator (EDIT for short). The principle behind is that, for images from multiple domains, the content features can be obtained by a uniform extractor, while (re-)stylization is achieved by mapping the extracted features specifically to different purposes (domains and exemplars). The generator of our EDIT comprises of a part of blocks configured by shared parameters, and the rest by varied parameters exported by an exemplar-domain aware parameter network. In addition, a discriminator is equipped during the training phase to guarantee the output satisfying the distribution of the target domain. Our EDIT can flexibly and effectively work on multiple domains and arbitrary exemplars in a unified neat model. We conduct experiments to show the efficacy of our design, and reveal its advances over other state-of-the-art methods both quantitatively and qualitatively.
Transformer-based Generative Adversarial Networks in Computer Vision: A Comprehensive Survey
Feb 17, 2023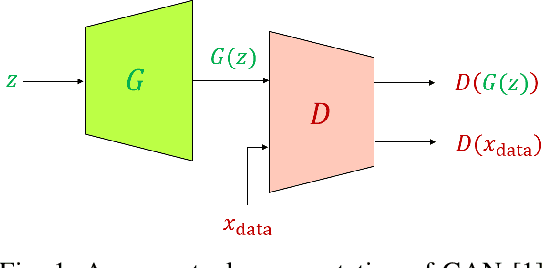
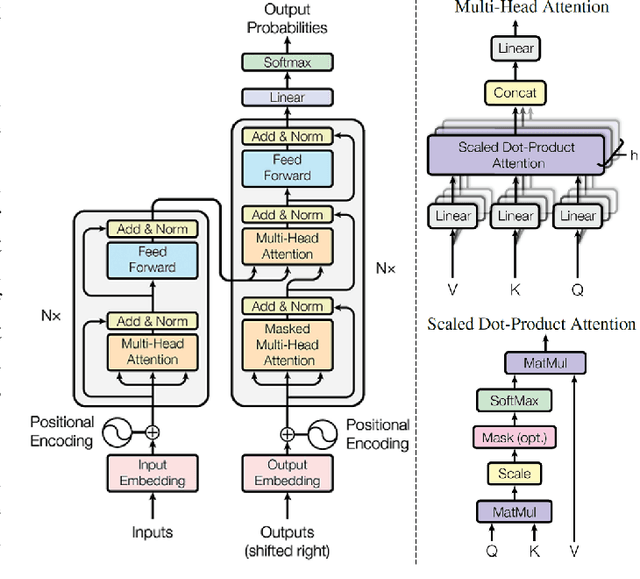
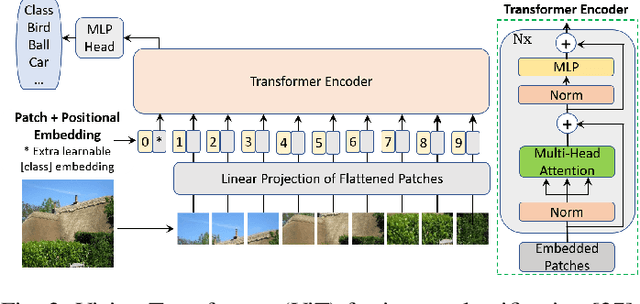
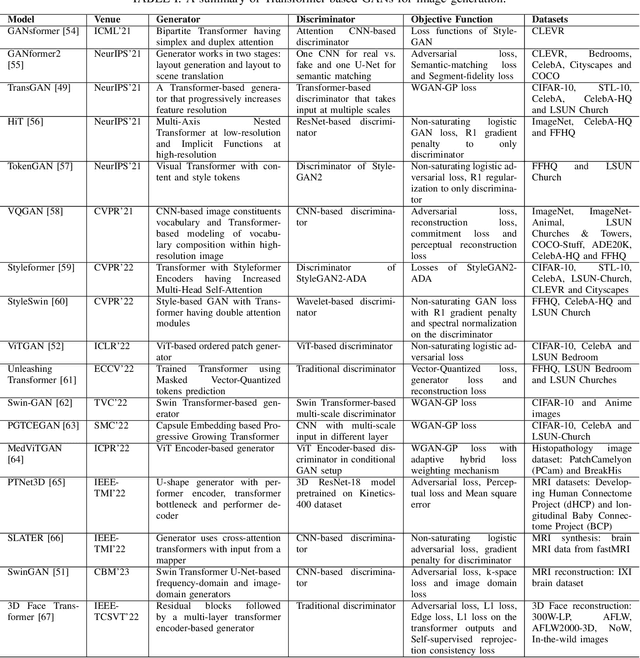
Generative Adversarial Networks (GANs) have been very successful for synthesizing the images in a given dataset. The artificially generated images by GANs are very realistic. The GANs have shown potential usability in several computer vision applications, including image generation, image-to-image translation, video synthesis, and others. Conventionally, the generator network is the backbone of GANs, which generates the samples and the discriminator network is used to facilitate the training of the generator network. The discriminator network is usually a Convolutional Neural Network (CNN). Whereas, the generator network is usually either an Up-CNN for image generation or an Encoder-Decoder network for image-to-image translation. The convolution-based networks exploit the local relationship in a layer, which requires the deep networks to extract the abstract features. Hence, CNNs suffer to exploit the global relationship in the feature space. However, recently developed Transformer networks are able to exploit the global relationship at every layer. The Transformer networks have shown tremendous performance improvement for several problems in computer vision. Motivated from the success of Transformer networks and GANs, recent works have tried to exploit the Transformers in GAN framework for the image/video synthesis. This paper presents a comprehensive survey on the developments and advancements in GANs utilizing the Transformer networks for computer vision applications. The performance comparison for several applications on benchmark datasets is also performed and analyzed. The conducted survey will be very useful to deep learning and computer vision community to understand the research trends \& gaps related with Transformer-based GANs and to develop the advanced GAN architectures by exploiting the global and local relationships for different applications.