 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Multiple GAN Inversion for Exemplar-based Image-to-Image Translation
Mar 26, 2021
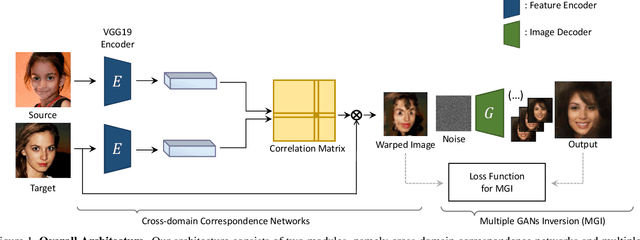
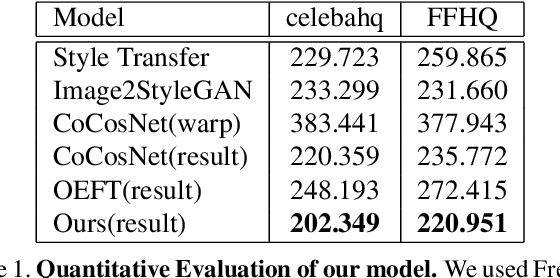
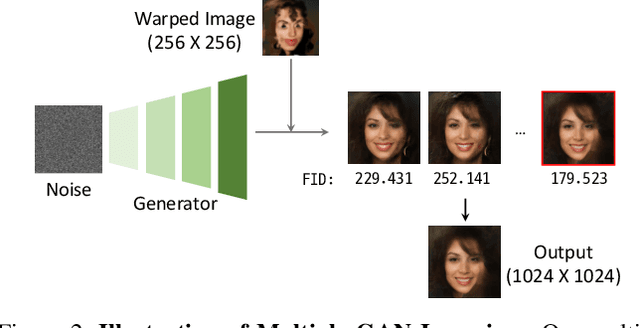
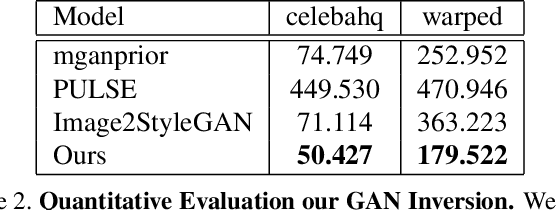
Existing state-of-the-art techniques in exemplar-based image-to-image translation have several critical problems. Existing method related to exemplar-based image-to-image translation is impossible to translate on an image tuple input(source, target) that is not aligned. Also, we can confirm that the existing method has limited generalization ability to unseen images. To overcome this limitation, we propose Multiple GAN Inversion for Exemplar-based Image-to-Image Translation. Our novel Multiple GAN Inversion avoids human intervention using a self-deciding algorithm in choosing the number of layers using Fr\'echet Inception Distance(FID), which selects more plausible image reconstruction result among multiple hypotheses without any training or supervision. Experimental results shows the advantage of the proposed method compared to existing state-of-the-art exemplar-based image-to-image translation methods.
Vision Matters When It Should: Sanity Checking Multimodal Machine Translation Models
Sep 08, 2021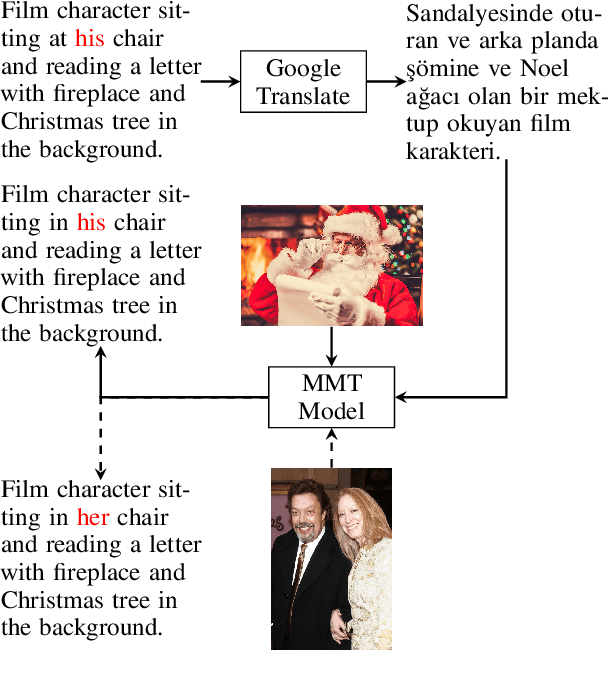
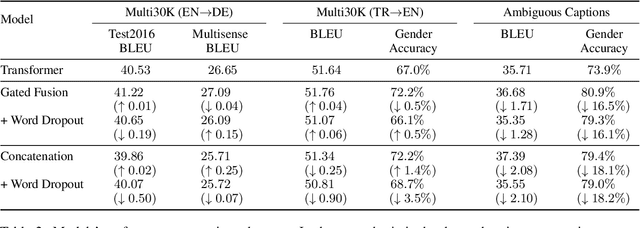
Multimodal machine translation (MMT) systems have been shown to outperform their text-only neural machine translation (NMT) counterparts when visual context is available. However, recent studies have also shown that the performance of MMT models is only marginally impacted when the associated image is replaced with an unrelated image or noise, which suggests that the visual context might not be exploited by the model at all. We hypothesize that this might be caused by the nature of the commonly used evaluation benchmark, also known as Multi30K, where the translations of image captions were prepared without actually showing the images to human translators. In this paper, we present a qualitative study that examines the role of datasets in stimulating the leverage of visual modality and we propose methods to highlight the importance of visual signals in the datasets which demonstrate improvements in reliance of models on the source images. Our findings suggest the research on effective MMT architectures is currently impaired by the lack of suitable datasets and careful consideration must be taken in creation of future MMT datasets, for which we also provide useful insights.
Scaling-up Disentanglement for Image Translation
Mar 25, 2021
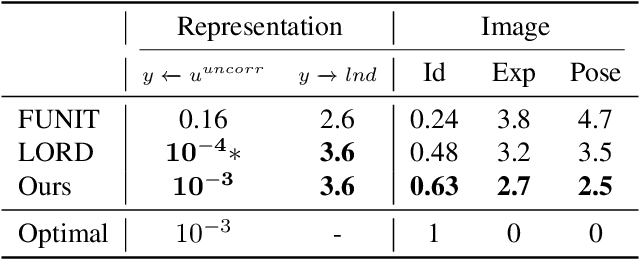

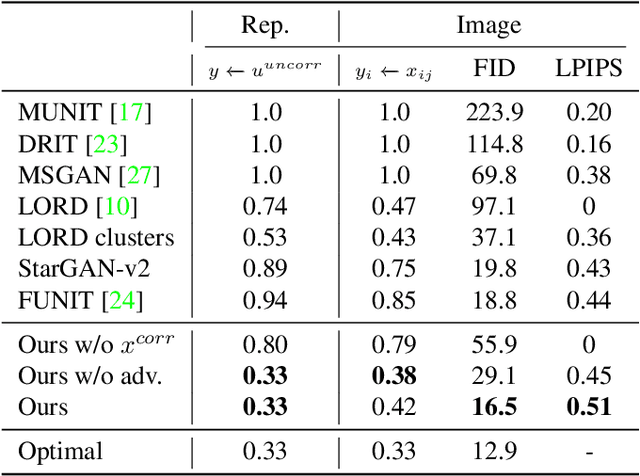
Image translation methods typically aim to manipulate a set of labeled attributes (given as supervision at training time e.g. domain label) while leaving the unlabeled attributes intact. Current methods achieve either: (i) disentanglement, which exhibits low visual fidelity and can only be satisfied where the attributes are perfectly uncorrelated. (ii) visually-plausible translations, which are clearly not disentangled. In this work, we propose OverLORD, a single framework for disentangling labeled and unlabeled attributes as well as synthesizing high-fidelity images, which is composed of two stages; (i) Disentanglement: Learning disentangled representations with latent optimization. Differently from previous approaches, we do not rely on adversarial training or any architectural biases. (ii) Synthesis: Training feed-forward encoders for inferring the learned attributes and tuning the generator in an adversarial manner to increase the perceptual quality. When the labeled and unlabeled attributes are correlated, we model an additional representation that accounts for the correlated attributes and improves disentanglement. We highlight that our flexible framework covers multiple image translation settings e.g. attribute manipulation, pose-appearance translation, segmentation-guided synthesis and shape-texture transfer. In an extensive evaluation, we present significantly better disentanglement with higher translation quality and greater output diversity than state-of-the-art methods.
Closing the Loop: Joint Rain Generation and Removal via Disentangled Image Translation
Mar 25, 2021
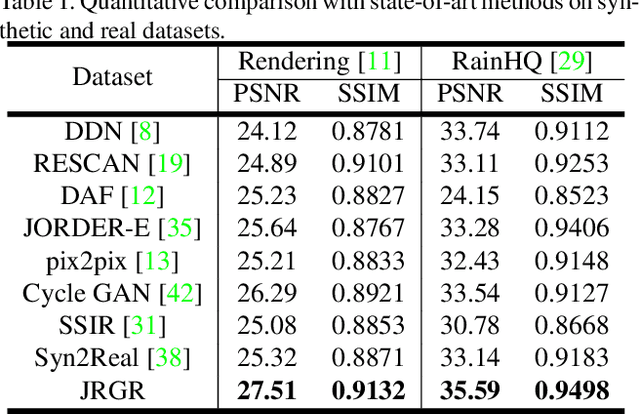
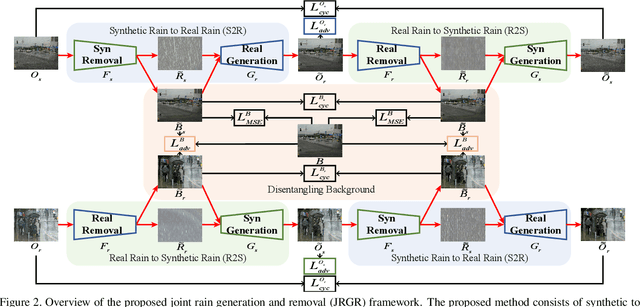
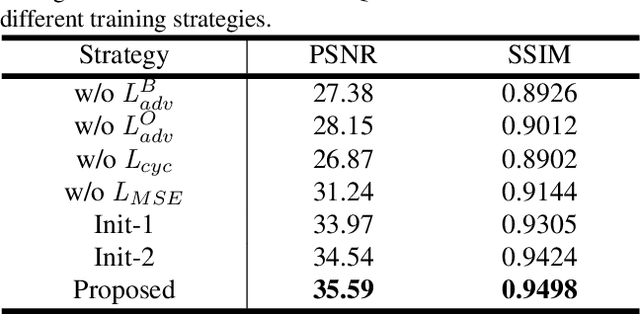
Existing deep learning-based image deraining methods have achieved promising performance for synthetic rainy images, typically rely on the pairs of sharp images and simulated rainy counterparts. However, these methods suffer from significant performance drop when facing the real rain, because of the huge gap between the simplified synthetic rain and the complex real rain. In this work, we argue that the rain generation and removal are the two sides of the same coin and should be tightly coupled. To close the loop, we propose to jointly learn real rain generation and removal procedure within a unified disentangled image translation framework. Specifically, we propose a bidirectional disentangled translation network, in which each unidirectional network contains two loops of joint rain generation and removal for both the real and synthetic rain image, respectively. Meanwhile, we enforce the disentanglement strategy by decomposing the rainy image into a clean background and rain layer (rain removal), in order to better preserve the identity background via both the cycle-consistency loss and adversarial loss, and ease the rain layer translating between the real and synthetic rainy image. A counterpart composition with the entanglement strategy is symmetrically applied for rain generation. Extensive experiments on synthetic and real-world rain datasets show the superiority of proposed method compared to state-of-the-arts.
Geometry-Aware Unsupervised Domain Adaptation for Stereo Matching
Mar 26, 2021
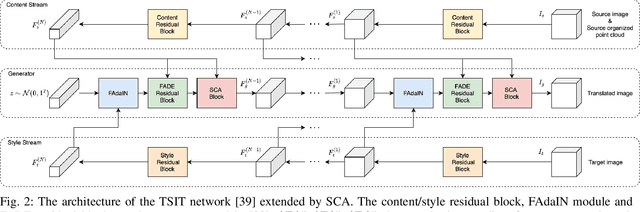
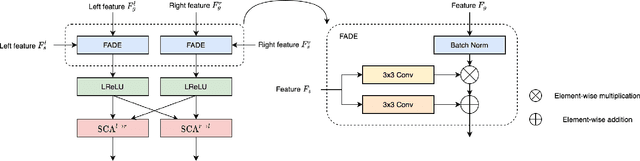
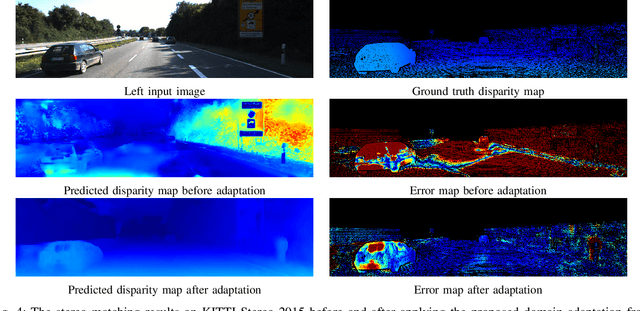
Recently proposed DNN-based stereo matching methods that learn priors directly from data are known to suffer a drastic drop in accuracy in new environments. Although supervised approaches with ground truth disparity maps often work well, collecting them in each deployment environment is cumbersome and costly. For this reason, many unsupervised domain adaptation methods based on image-to-image translation have been proposed, but these methods do not preserve the geometric structure of a stereo image pair because the image-to-image translation is applied to each view separately. To address this problem, in this paper, we propose an attention mechanism that aggregates features in the left and right views, called Stereoscopic Cross Attention (SCA). Incorporating SCA to an image-to-image translation network makes it possible to preserve the geometric structure of a stereo image pair in the process of the image-to-image translation. We empirically demonstrate the effectiveness of the proposed unsupervised domain adaptation based on the image-to-image translation with SCA.
FontNet: Closing the gap to font designer performance in font synthesis
May 13, 2022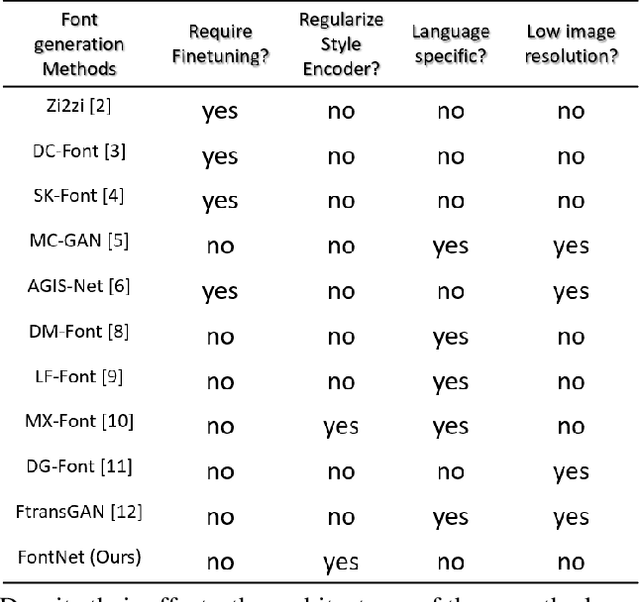
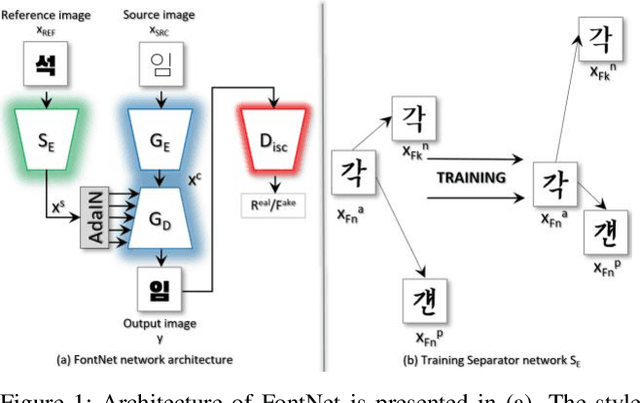
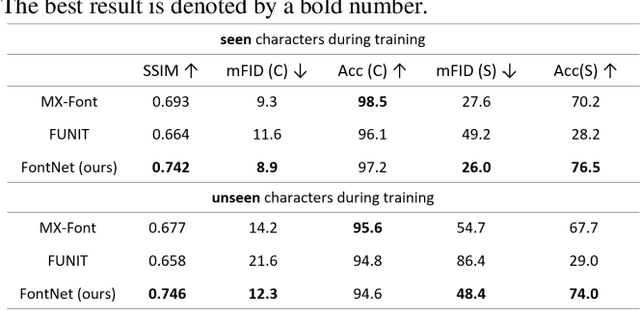

Font synthesis has been a very active topic in recent years because manual font design requires domain expertise and is a labor-intensive and time-consuming job. While remarkably successful, existing methods for font synthesis have major shortcomings; they require finetuning for unobserved font style with large reference images, the recent few-shot font synthesis methods are either designed for specific language systems or they operate on low-resolution images which limits their use. In this paper, we tackle this font synthesis problem by learning the font style in the embedding space. To this end, we propose a model, called FontNet, that simultaneously learns to separate font styles in the embedding space where distances directly correspond to a measure of font similarity, and translates input images into the given observed or unobserved font style. Additionally, we design the network architecture and training procedure that can be adopted for any language system and can produce high-resolution font images. Thanks to this approach, our proposed method outperforms the existing state-of-the-art font generation methods on both qualitative and quantitative experiments.
Guided Disentanglement in Generative Networks
Jul 29, 2021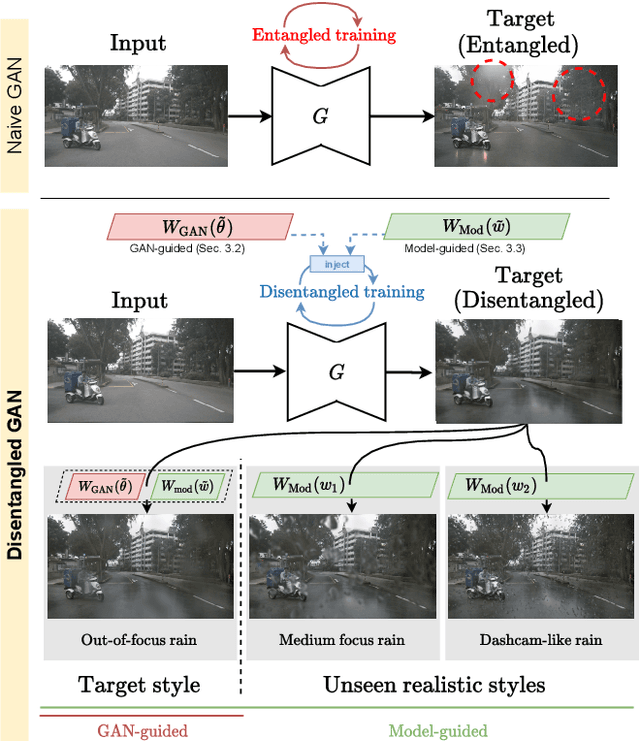
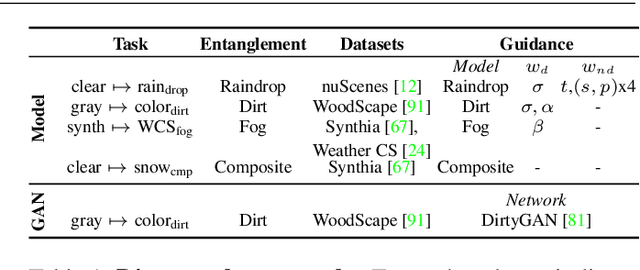
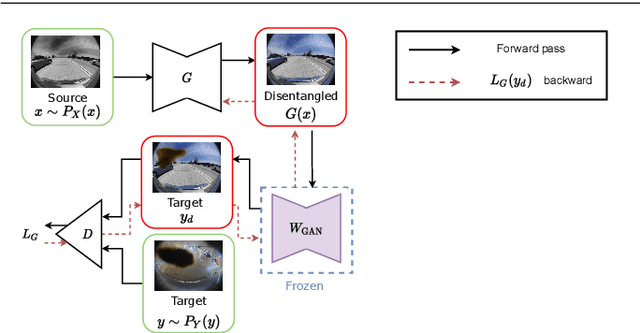
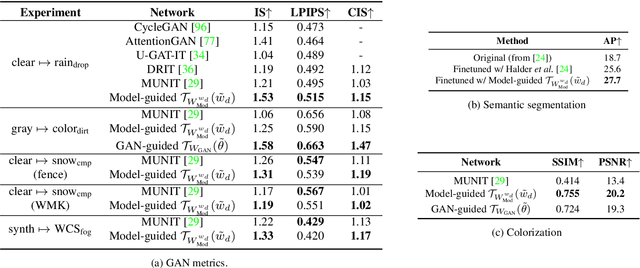
Image-to-image translation (i2i) networks suffer from entanglement effects in presence of physics-related phenomena in target domain (such as occlusions, fog, etc), thus lowering the translation quality and variability. In this paper, we present a comprehensive method for disentangling physics-based traits in the translation, guiding the learning process with neural or physical models. For the latter, we integrate adversarial estimation and genetic algorithms to correctly achieve disentanglement. The results show our approach dramatically increase performances in many challenging scenarios for image translation.
CAFLOW: Conditional Autoregressive Flows
Jun 04, 2021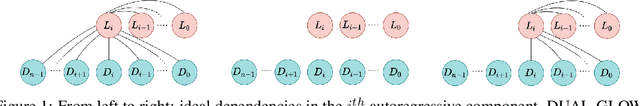


We introduce CAFLOW, a new diverse image-to-image translation model that simultaneously leverages the power of auto-regressive modeling and the modeling efficiency of conditional normalizing flows. We transform the conditioning image into a sequence of latent encodings using a multi-scale normalizing flow and repeat the process for the conditioned image. We model the conditional distribution of the latent encodings by modeling the auto-regressive distributions with an efficient multi-scale normalizing flow, where each conditioning factor affects image synthesis at its respective resolution scale. Our proposed framework performs well on a range of image-to-image translation tasks. It outperforms former designs of conditional flows because of its expressive auto-regressive structure.
Let There be Light: Improved Traffic Surveillance via Detail Preserving Night-to-Day Transfer
May 11, 2021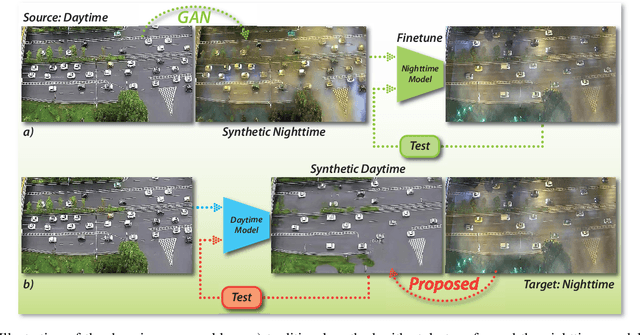

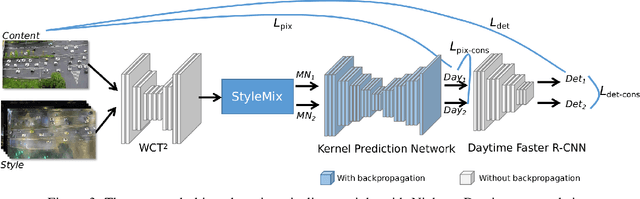
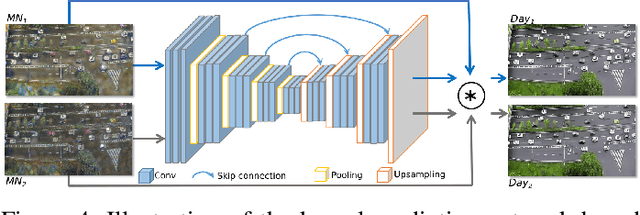
In recent years, image and video surveillance have made considerable progresses to the Intelligent Transportation Systems (ITS) with the help of deep Convolutional Neural Networks (CNNs). As one of the state-of-the-art perception approaches, detecting the interested objects in each frame of video surveillance is widely desired by ITS. Currently, object detection shows remarkable efficiency and reliability in standard scenarios such as daytime scenes with favorable illumination conditions. However, in face of adverse conditions such as the nighttime, object detection loses its accuracy significantly. One of the main causes of the problem is the lack of sufficient annotated detection datasets of nighttime scenes. In this paper, we propose a framework to alleviate the accuracy decline when object detection is taken to adverse conditions by using image translation method. We propose to utilize style translation based StyleMix method to acquire pairs of day time image and nighttime image as training data for following nighttime to daytime image translation. To alleviate the detail corruptions caused by Generative Adversarial Networks (GANs), we propose to utilize Kernel Prediction Network (KPN) based method to refine the nighttime to daytime image translation. The KPN network is trained with object detection task together to adapt the trained daytime model to nighttime vehicle detection directly. Experiments on vehicle detection verified the accuracy and effectiveness of the proposed approach.
CoPE: Conditional image generation using Polynomial Expansions
Apr 11, 2021
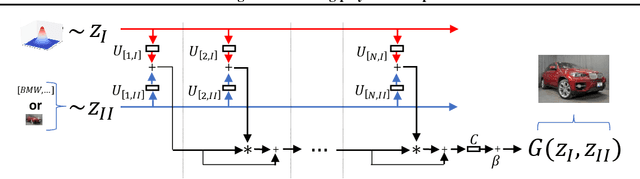


Generative modeling has evolved to a notable field of machine learning. Deep polynomial neural networks (PNNs) have demonstrated impressive results in unsupervised image generation, where the task is to map an input vector (i.e., noise) to a synthesized image. However, the success of PNNs has not been replicated in conditional generation tasks, such as super-resolution. Existing PNNs focus on single-variable polynomial expansions which do not fare well to two-variable inputs, i.e., the noise variable and the conditional variable. In this work, we introduce a general framework, called CoPE, that enables a polynomial expansion of two input variables and captures their auto- and cross-correlations. We exhibit how CoPE can be trivially augmented to accept an arbitrary number of input variables. CoPE is evaluated in five tasks (class-conditional generation, inverse problems, edges-to-image translation, image-to-image translation, attribute-guided generation) involving eight datasets. The thorough evaluation suggests that CoPE can be useful for tackling diverse conditional generation tasks.