 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Few-Shot Unsupervised Image-to-Image Translation on complex scenes
Jun 07, 2021
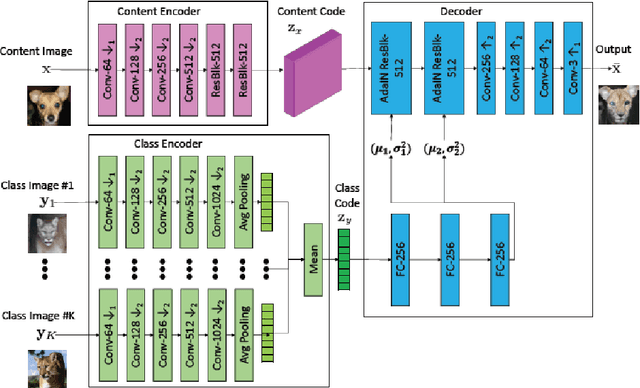
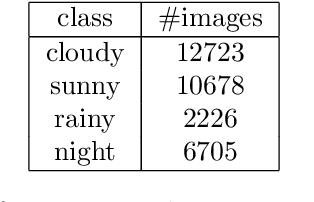

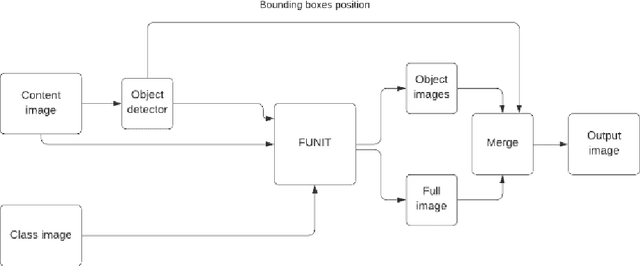
Unsupervised image-to-image translation methods have received a lot of attention in the last few years. Multiple techniques emerged tackling the initial challenge from different perspectives. Some focus on learning as much as possible from several target style images for translations while other make use of object detection in order to produce more realistic results on content-rich scenes. In this work, we assess how a method that has initially been developed for single object translation performs on more diverse and content-rich images. Our work is based on the FUNIT[1] framework and we train it with a more diverse dataset. This helps understanding how such method behaves beyond their initial frame of application. We present a way to extend a dataset based on object detection. Moreover, we propose a way to adapt the FUNIT framework in order to leverage the power of object detection that one can see in other methods.
Semantics-Aware Image to Image Translation and Domain Transfer
Apr 03, 2019
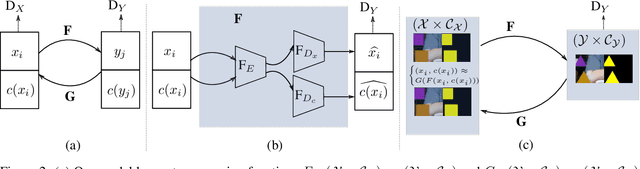
Image to image translation is the problem of transferring an image from a source domain to a target domain. We present a new method to transfer the underlying semantics of an image even when there are geometric changes across the two domains. Specifically, we present a Generative Adversarial Network (GAN) that can transfer semantic information presented as segmentation masks. Our main technical contribution is an encoder-decoder based generator architecture that jointly encodes the image and its underlying semantics and translates both simultaneously to the target domain. Additionally, we propose object transfiguration and cross-domain semantic consistency losses that preserve the underlying semantic labels maps. We demonstrate the effectiveness of our approach in multiple object transfiguration and domain transfer tasks through qualitative and quantitative experiments. The results show that our method is better at transferring image semantics than state of the art image to image translation methods.
Controlling biases and diversity in diverse image-to-image translation
Jul 23, 2019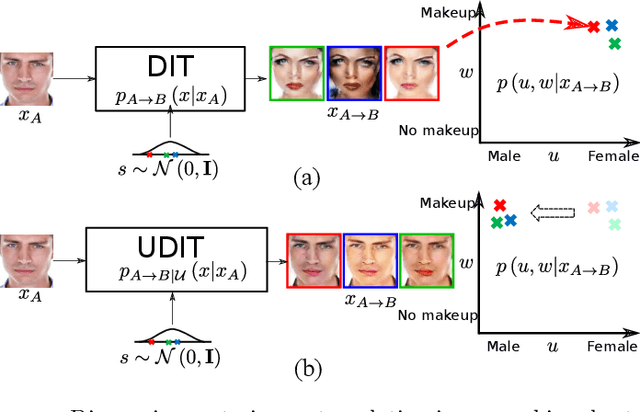



The task of unpaired image-to-image translation is highly challenging due to the lack of explicit cross-domain pairs of instances. We consider here diverse image translation (DIT), an even more challenging setting in which an image can have multiple plausible translations. This is normally achieved by explicitly disentangling content and style in the latent representation and sampling different styles codes while maintaining the image content. Despite the success of current DIT models, they are prone to suffer from bias. In this paper, we study the problem of bias in image-to-image translation. Biased datasets may add undesired changes (e.g. change gender or race in face images) to the output translations as a consequence of the particular underlying visual distribution in the target domain. In order to alleviate the effects of this problem we propose the use of semantic constraints that enforce the preservation of desired image properties. Our proposed model is a step towards unbiased diverse image-to-image translation (UDIT), and results in less unwanted changes in the translated images while still performing the wanted transformation. Experiments on several heavily biased datasets show the effectiveness of the proposed techniques in different domains such as faces, objects, and scenes.
A Novel Application of Image-to-Image Translation: Chromosome Straightening Framework by Learning from a Single Image
Mar 04, 2021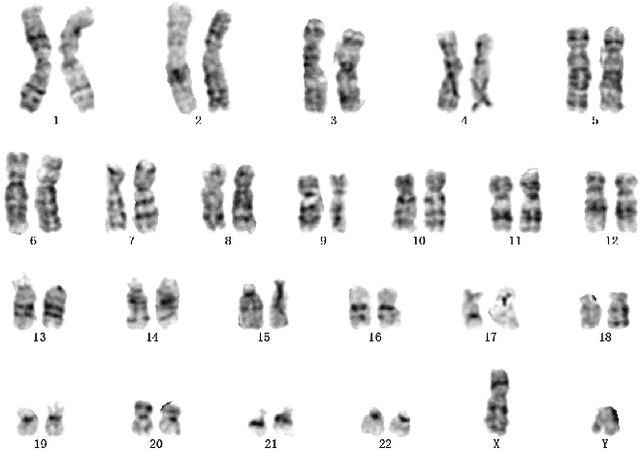

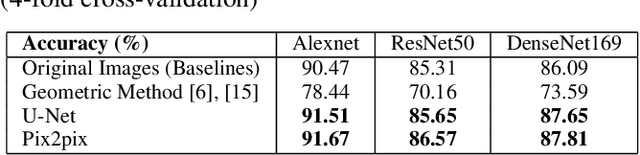
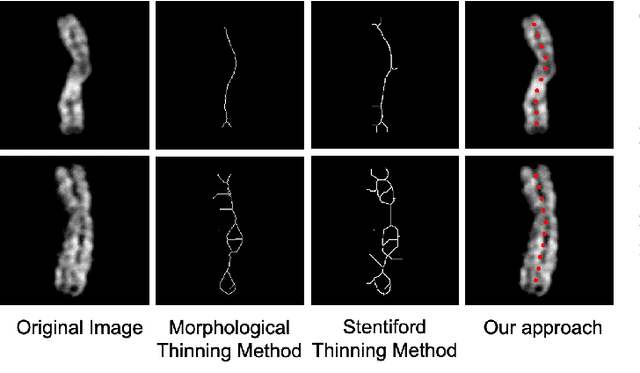
In medical imaging, chromosome straightening plays a significant role in the pathological study of chromosomes and in the development of cytogenetic maps. Whereas different approaches exist for the straightening task, they are mostly geometric algorithms whose outputs are characterized by jagged edges or fragments with discontinued banding patterns. To address the flaws in the geometric algorithms, we propose a novel framework based on image-to-image translation to learn a pertinent mapping dependence for synthesizing straightened chromosomes with uninterrupted banding patterns and preserved details. In addition, to avoid the pitfall of deficient input chromosomes, we construct an augmented dataset using only one single curved chromosome image for training models. Based on this framework, we apply two popular image-to-image translation architectures, U-shape networks and conditional generative adversarial networks, to assess its efficacy. Experiments on a dataset comprising of 642 real-world chromosomes demonstrate the superiority of our framework as compared to the geometric method in straightening performance by rendering realistic and continued chromosome details. Furthermore, our straightened results improve the chromosome classification, achieving 0.98%-1.39% in mean accuracy.
Towards Instance-level Image-to-Image Translation
May 05, 2019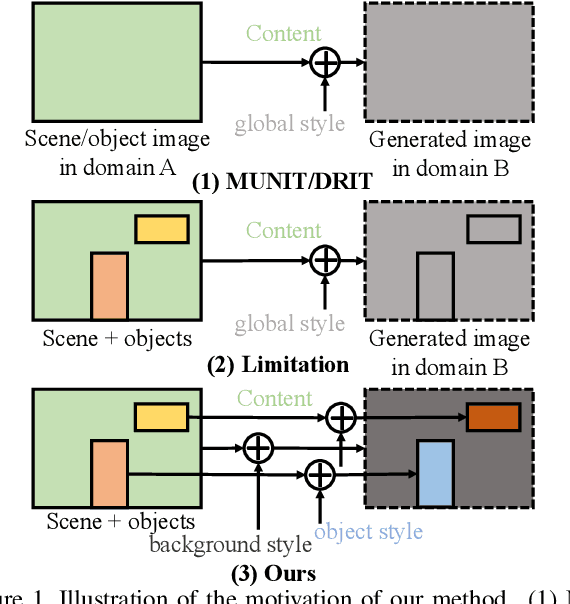
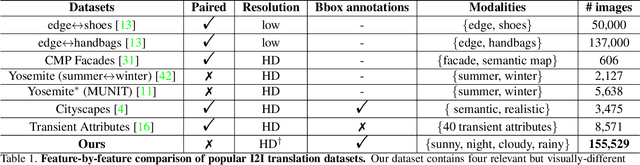
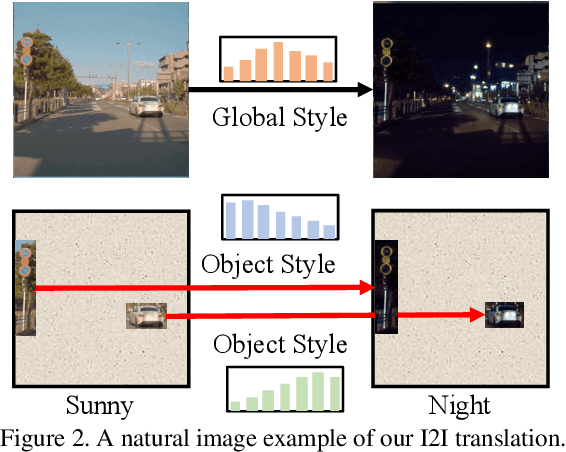
Unpaired Image-to-image Translation is a new rising and challenging vision problem that aims to learn a mapping between unaligned image pairs in diverse domains. Recent advances in this field like MUNIT and DRIT mainly focus on disentangling content and style/attribute from a given image first, then directly adopting the global style to guide the model to synthesize new domain images. However, this kind of approaches severely incurs contradiction if the target domain images are content-rich with multiple discrepant objects. In this paper, we present a simple yet effective instance-aware image-to-image translation approach (INIT), which employs the fine-grained local (instance) and global styles to the target image spatially. The proposed INIT exhibits three import advantages: (1) the instance-level objective loss can help learn a more accurate reconstruction and incorporate diverse attributes of objects; (2) the styles used for target domain of local/global areas are from corresponding spatial regions in source domain, which intuitively is a more reasonable mapping; (3) the joint training process can benefit both fine and coarse granularity and incorporates instance information to improve the quality of global translation. We also collect a large-scale benchmark for the new instance-level translation task. We observe that our synthetic images can even benefit real-world vision tasks like generic object detection.
SPatchGAN: A Statistical Feature Based Discriminator for Unsupervised Image-to-Image Translation
Mar 30, 2021
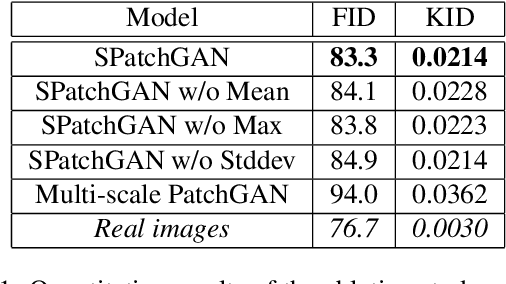
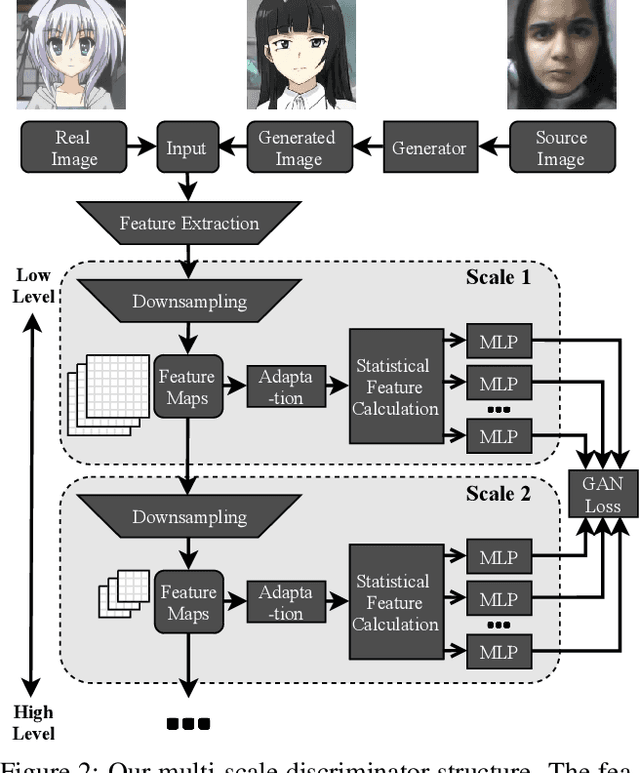
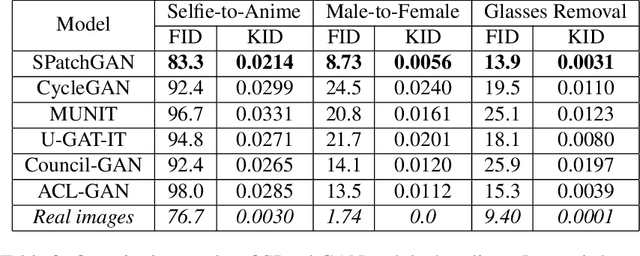
For unsupervised image-to-image translation, we propose a discriminator architecture which focuses on the statistical features instead of individual patches. The network is stabilized by distribution matching of key statistical features at multiple scales. Unlike the existing methods which impose more and more constraints on the generator, our method facilitates the shape deformation and enhances the fine details with a greatly simplified framework. We show that the proposed method outperforms the existing state-of-the-art models in various challenging applications including selfie-to-anime, male-to-female and glasses removal. The code will be made publicly available.
Single Image LDR to HDR Conversion using Conditional Diffusion
Jul 06, 2023
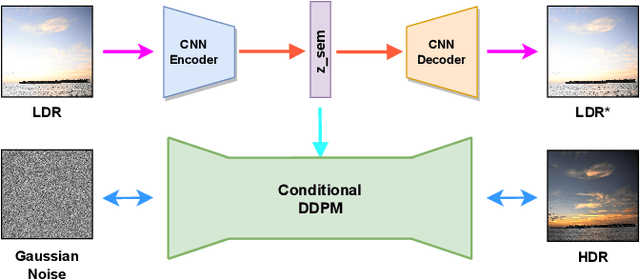
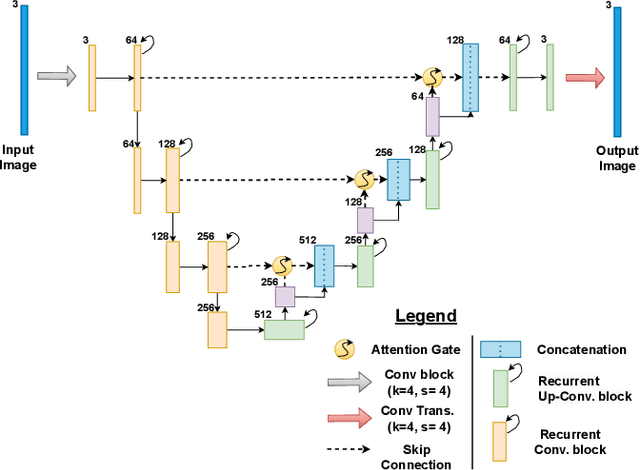

Digital imaging aims to replicate realistic scenes, but Low Dynamic Range (LDR) cameras cannot represent the wide dynamic range of real scenes, resulting in under-/overexposed images. This paper presents a deep learning-based approach for recovering intricate details from shadows and highlights while reconstructing High Dynamic Range (HDR) images. We formulate the problem as an image-to-image (I2I) translation task and propose a conditional Denoising Diffusion Probabilistic Model (DDPM) based framework using classifier-free guidance. We incorporate a deep CNN-based autoencoder in our proposed framework to enhance the quality of the latent representation of the input LDR image used for conditioning. Moreover, we introduce a new loss function for LDR-HDR translation tasks, termed Exposure Loss. This loss helps direct gradients in the opposite direction of the saturation, further improving the results' quality. By conducting comprehensive quantitative and qualitative experiments, we have effectively demonstrated the proficiency of our proposed method. The results indicate that a simple conditional diffusion-based method can replace the complex camera pipeline-based architectures.
Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
Aug 03, 2020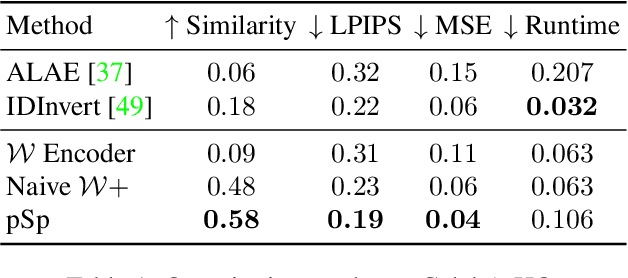
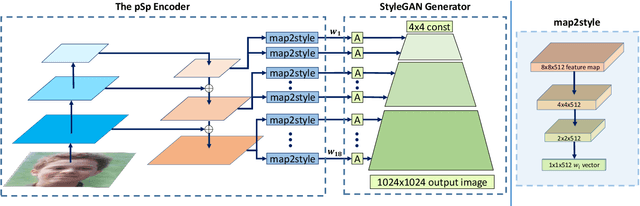
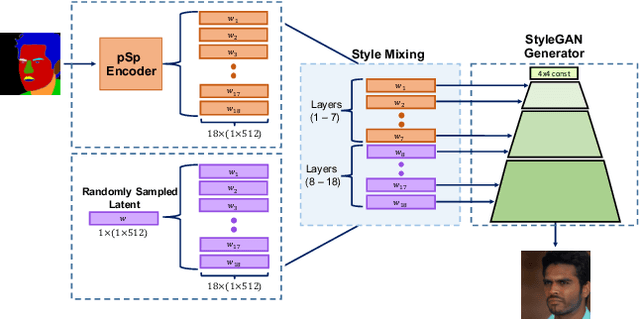

We present a generic image-to-image translation framework, Pixel2Style2Pixel (pSp). Our pSp framework is based on a novel encoder network that directly generates a series of style vectors which are fed into a pretrained StyleGAN generator, forming the extended W+ latent space. We first show that our encoder can directly embed real images into W+, with no additional optimization. We further introduce a dedicated identity loss which is shown to achieve improved performance in the reconstruction of an input image. We demonstrate pSp to be a simple architecture that, by leveraging a well-trained, fixed generator network, can be easily applied on a wide-range of image-to-image translation tasks. Solving these tasks through the style representation results in a global approach that does not rely on a local pixel-to-pixel correspondence and further supports multi-modal synthesis via the resampling of styles. Notably, we demonstrate that pSp can be trained to align a face image to a frontal pose without any labeled data, generate multi-modal results for ambiguous tasks such as conditional face generation from segmentation maps, and construct high-resolution images from corresponding low-resolution images.
Unsupervised Image to Image Translation for Multiple Retinal Pathology Synthesis in Optical Coherence Tomography Scans
Dec 11, 2021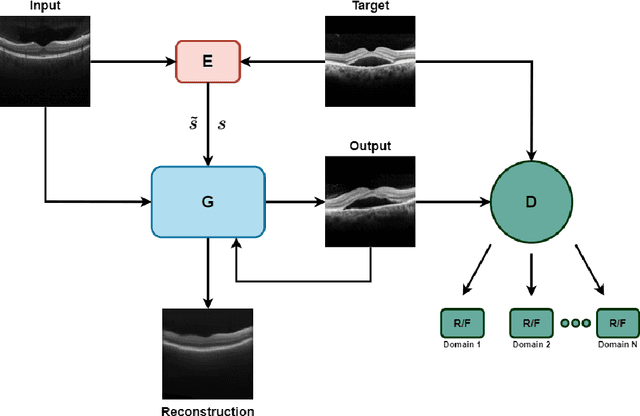
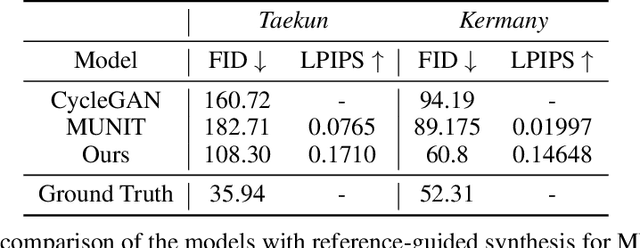
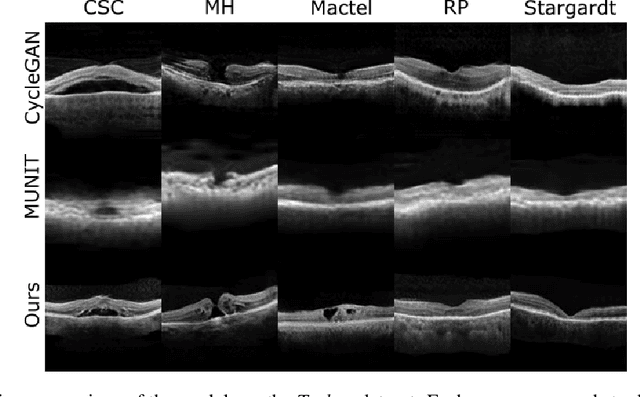
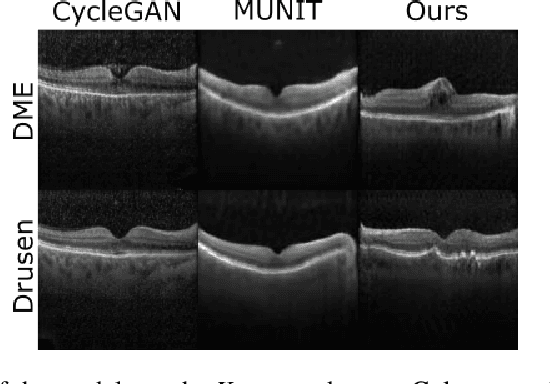
Image to Image Translation (I2I) is a challenging computer vision problem used in numerous domains for multiple tasks. Recently, ophthalmology became one of the major fields where the application of I2I is increasing rapidly. One such application is the generation of synthetic retinal optical coherence tomographic (OCT) scans. Existing I2I methods require training of multiple models to translate images from normal scans to a specific pathology: limiting the use of these models due to their complexity. To address this issue, we propose an unsupervised multi-domain I2I network with pre-trained style encoder that translates retinal OCT images in one domain to multiple domains. We assume that the image splits into domain-invariant content and domain-specific style codes, and pre-train these style codes. The performed experiments show that the proposed model outperforms state-of-the-art models like MUNIT and CycleGAN synthesizing diverse pathological scans.
RelGAN: Multi-Domain Image-to-Image Translation via Relative Attributes
Aug 20, 2019
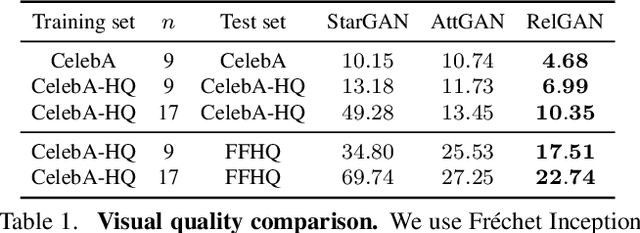
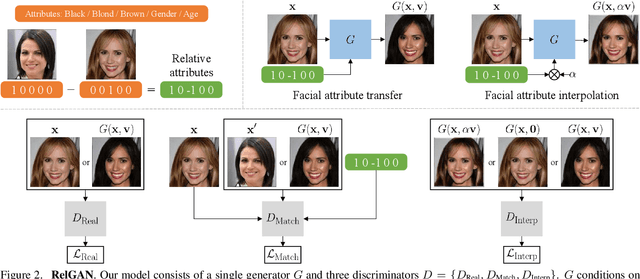
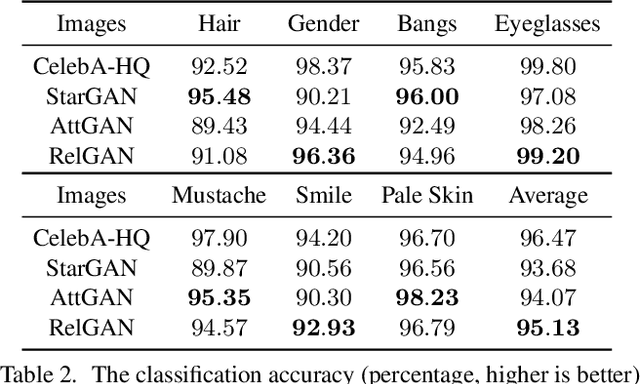
Multi-domain image-to-image translation has gained increasing attention recently. Previous methods take an image and some target attributes as inputs and generate an output image with the desired attributes. However, such methods have two limitations. First, these methods assume binary-valued attributes and thus cannot yield satisfactory results for fine-grained control. Second, these methods require specifying the entire set of target attributes, even if most of the attributes would not be changed. To address these limitations, we propose RelGAN, a new method for multi-domain image-to-image translation. The key idea is to use relative attributes, which describes the desired change on selected attributes. Our method is capable of modifying images by changing particular attributes of interest in a continuous manner while preserving the other attributes. Experimental results demonstrate both the quantitative and qualitative effectiveness of our method on the tasks of facial attribute transfer and interpolation.