 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Contrastive Learning for Unpaired Image-to-Image Translation
Jul 30, 2020
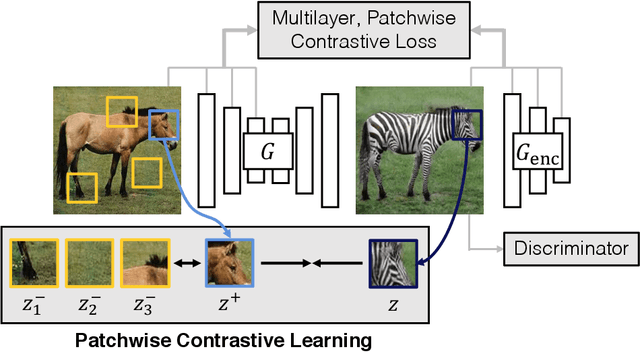
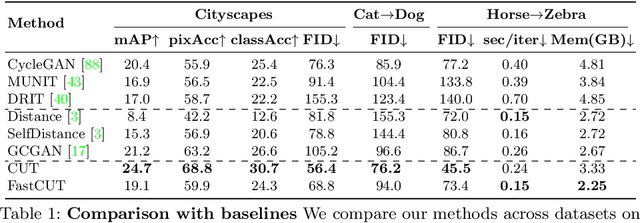
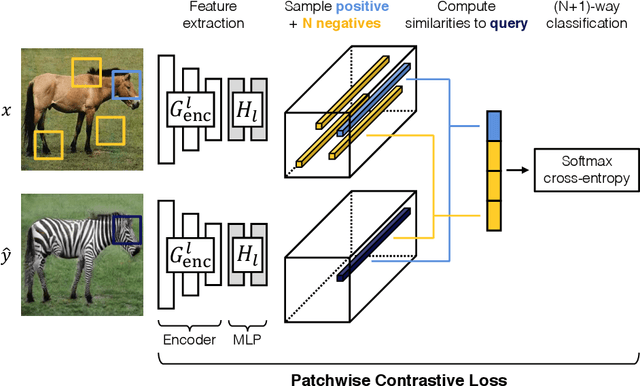
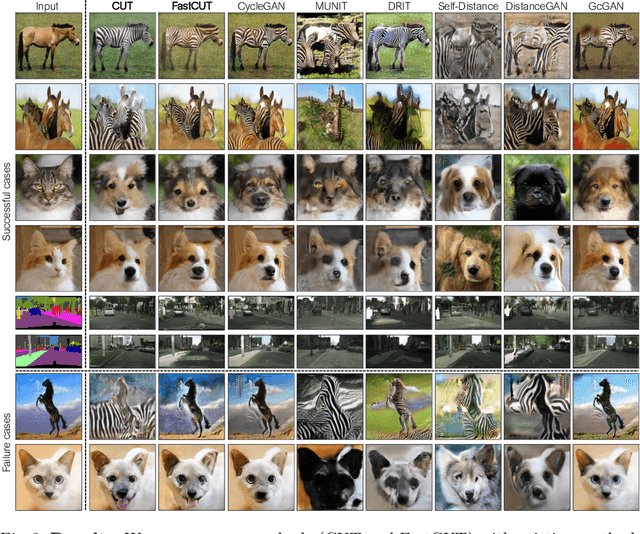
In image-to-image translation, each patch in the output should reflect the content of the corresponding patch in the input, independent of domain. We propose a straightforward method for doing so -- maximizing mutual information between the two, using a framework based on contrastive learning. The method encourages two elements (corresponding patches) to map to a similar point in a learned feature space, relative to other elements (other patches) in the dataset, referred to as negatives. We explore several critical design choices for making contrastive learning effective in the image synthesis setting. Notably, we use a multilayer, patch-based approach, rather than operate on entire images. Furthermore, we draw negatives from within the input image itself, rather than from the rest of the dataset. We demonstrate that our framework enables one-sided translation in the unpaired image-to-image translation setting, while improving quality and reducing training time. In addition, our method can even be extended to the training setting where each "domain" is only a single image.
A Semi-Paired Approach For Label-to-Image Translation
Jun 26, 2023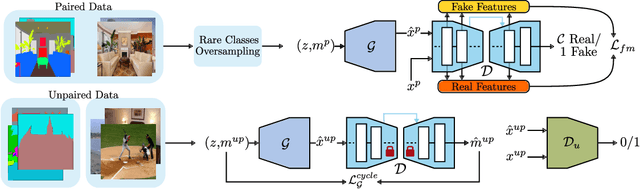
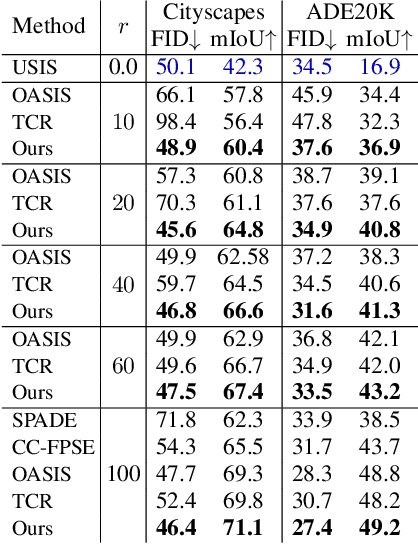

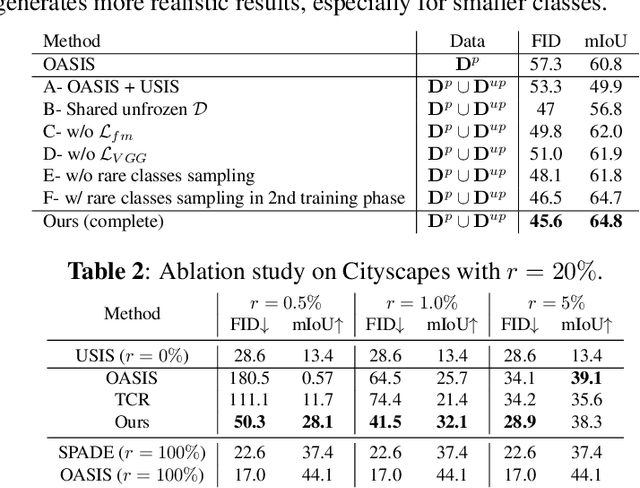
Data efficiency, or the ability to generalize from a few labeled data, remains a major challenge in deep learning. Semi-supervised learning has thrived in traditional recognition tasks alleviating the need for large amounts of labeled data, yet it remains understudied in image-to-image translation (I2I) tasks. In this work, we introduce the first semi-supervised (semi-paired) framework for label-to-image translation, a challenging subtask of I2I which generates photorealistic images from semantic label maps. In the semi-paired setting, the model has access to a small set of paired data and a larger set of unpaired images and labels. Instead of using geometrical transformations as a pretext task like previous works, we leverage an input reconstruction task by exploiting the conditional discriminator on the paired data as a reverse generator. We propose a training algorithm for this shared network, and we present a rare classes sampling algorithm to focus on under-represented classes. Experiments on 3 standard benchmarks show that the proposed model outperforms state-of-the-art unsupervised and semi-supervised approaches, as well as some fully supervised approaches while using a much smaller number of paired samples.
TRIP: Refining Image-to-Image Translation via Rival Preferences
Nov 26, 2021

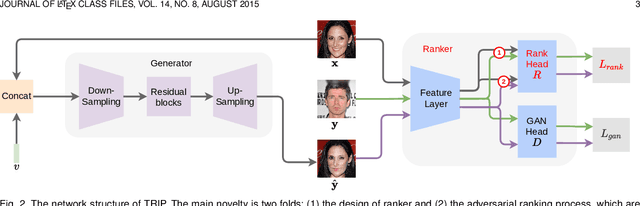
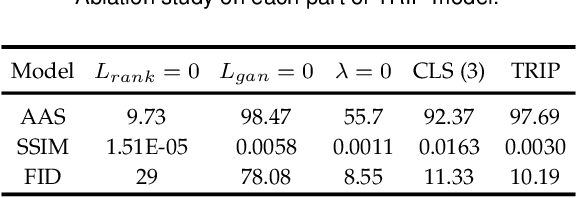
Relative attribute (RA), referring to the preference over two images on the strength of a specific attribute, can enable fine-grained image-to-image translation due to its rich semantic information. Existing work based on RAs however failed to reconcile the goal for fine-grained translation and the goal for high-quality generation. We propose a new model TRIP to coordinate these two goals for high-quality fine-grained translation. In particular, we simultaneously train two modules: a generator that translates an input image to the desired image with smooth subtle changes with respect to the interested attributes; and a ranker that ranks rival preferences consisting of the input image and the desired image. Rival preferences refer to the adversarial ranking process: (1) the ranker thinks no difference between the desired image and the input image in terms of the desired attributes; (2) the generator fools the ranker to believe that the desired image changes the attributes over the input image as desired. RAs over pairs of real images are introduced to guide the ranker to rank image pairs regarding the interested attributes only. With an effective ranker, the generator would "win" the adversarial game by producing high-quality images that present desired changes over the attributes compared to the input image. The experiments on two face image datasets and one shoe image dataset demonstrate that our TRIP achieves state-of-art results in generating high-fidelity images which exhibit smooth changes over the interested attributes.
Unsupervised Image-to-Image Translation with Self-Attention Networks
Jan 24, 2019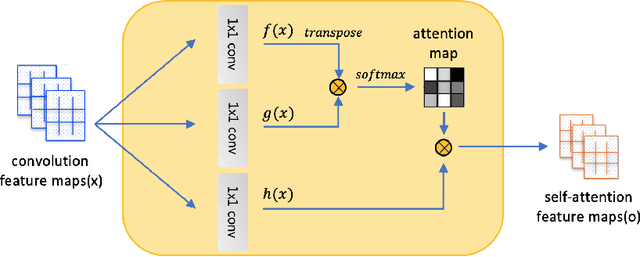
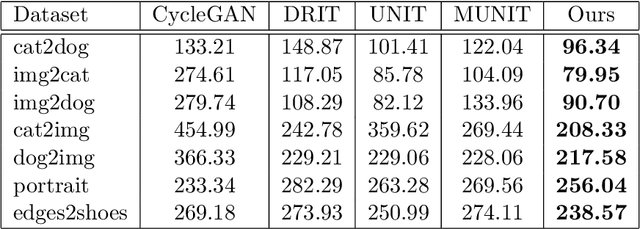
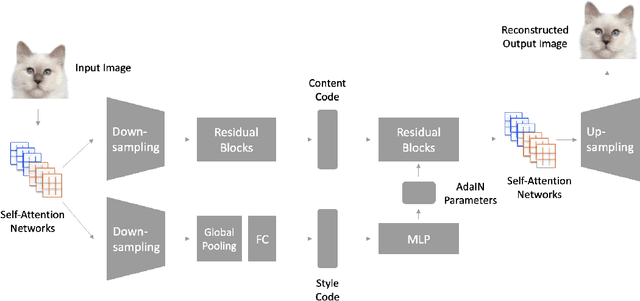

Unsupervised image translation aims to learn the transformation from a source domain to another target domain given unpaired training data. Several state-of-the-art works have yielded impressive results in the GANs-based unsupervised image-to-image translation. It fails to capture strong geometric or structural change between domains or is unsatisfactory for complex scenes, compared to texture change tasks such as style transfer. Recently, SAGAN (Han Zhang, 2018) showed that the self-attention network produces better results than the convolution-based GAN. However, the effectiveness of the self-attention network in unsupervised image-to-image translation tasks have not been verified. In this paper, we propose an unsupervised image-to-image translation with self-attention networks, in which long range dependency helps to not only capture strong geometric change but also generate details using cues from all feature locations. In experiments, we qualitatively and quantitatively show superiority of the proposed method compared to existing state-of-the-art unsupervised image-to-image translation task.
Unaligned Image-to-Image Translation by Learning to Reweight
Sep 24, 2021
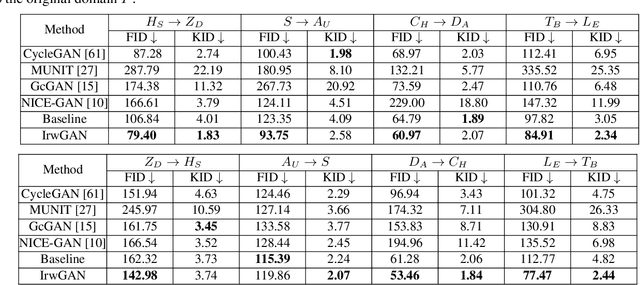
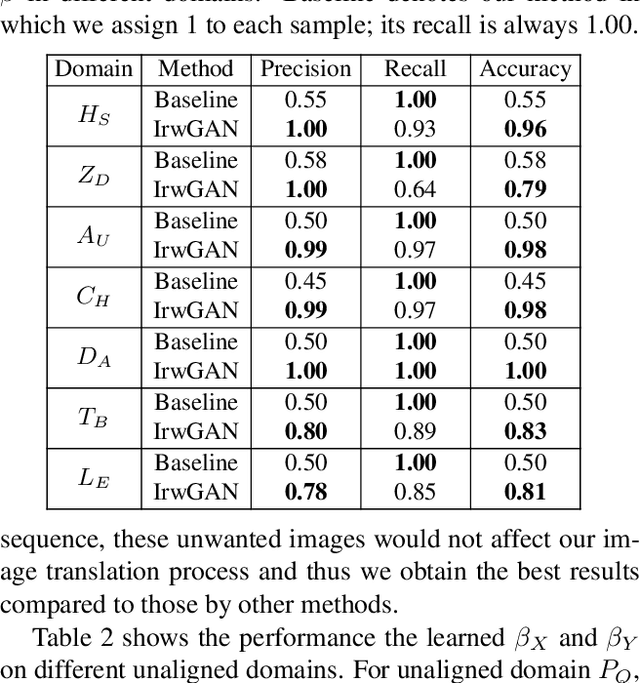
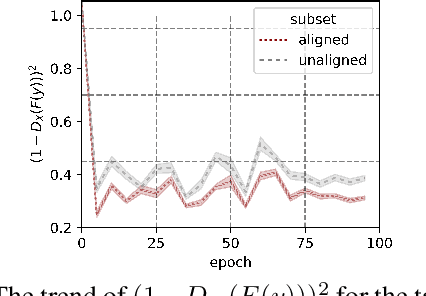
Unsupervised image-to-image translation aims at learning the mapping from the source to target domain without using paired images for training. An essential yet restrictive assumption for unsupervised image translation is that the two domains are aligned, e.g., for the selfie2anime task, the anime (selfie) domain must contain only anime (selfie) face images that can be translated to some images in the other domain. Collecting aligned domains can be laborious and needs lots of attention. In this paper, we consider the task of image translation between two unaligned domains, which may arise for various possible reasons. To solve this problem, we propose to select images based on importance reweighting and develop a method to learn the weights and perform translation simultaneously and automatically. We compare the proposed method with state-of-the-art image translation approaches and present qualitative and quantitative results on different tasks with unaligned domains. Extensive empirical evidence demonstrates the usefulness of the proposed problem formulation and the superiority of our method.
Generating Reliable Pixel-Level Labels for Source Free Domain Adaptation
Jul 03, 2023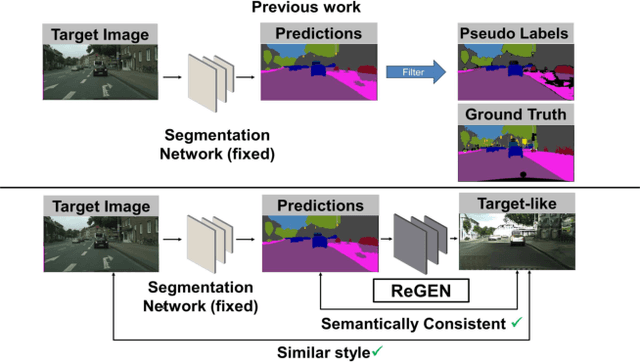

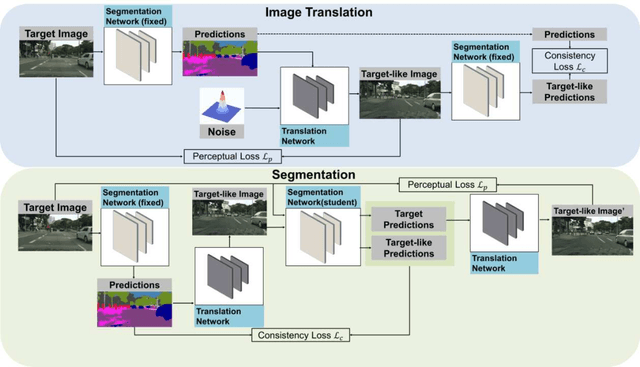
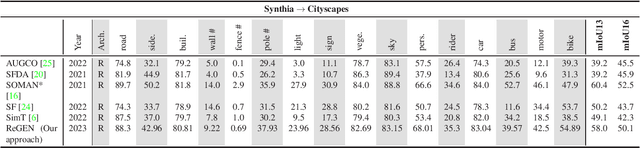
This work addresses the challenging domain adaptation setting in which knowledge from the labelled source domain dataset is available only from the pretrained black-box segmentation model. The pretrained model's predictions for the target domain images are noisy because of the distributional differences between the source domain data and the target domain data. Since the model's predictions serve as pseudo labels during self-training, the noise in the predictions impose an upper bound on model performance. Therefore, we propose a simple yet novel image translation workflow, ReGEN, to address this problem. ReGEN comprises an image-to-image translation network and a segmentation network. Our workflow generates target-like images using the noisy predictions from the original target domain images. These target-like images are semantically consistent with the noisy model predictions and therefore can be used to train the segmentation network. In addition to being semantically consistent with the predictions from the original target domain images, the generated target-like images are also stylistically similar to the target domain images. This allows us to leverage the stylistic differences between the target-like images and the target domain image as an additional source of supervision while training the segmentation model. We evaluate our model with two benchmark domain adaptation settings and demonstrate that our approach performs favourably relative to recent state-of-the-art work. The source code will be made available.
Attention Mechanism for Contrastive Learning in GAN-based Image-to-Image Translation
Feb 23, 2023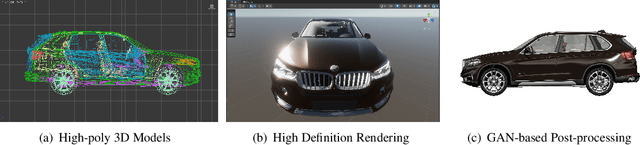

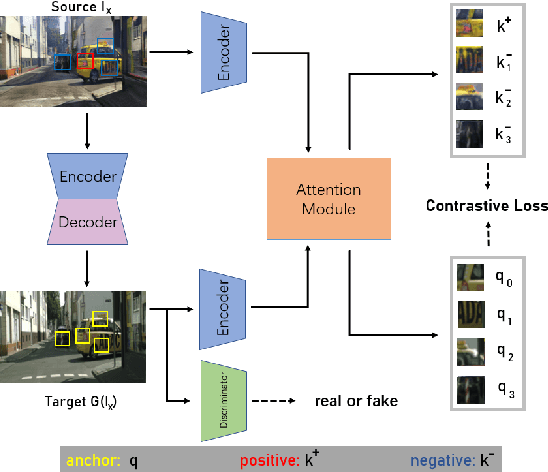
Using real road testing to optimize autonomous driving algorithms is time-consuming and capital-intensive. To solve this problem, we propose a GAN-based model that is capable of generating high-quality images across different domains. We further leverage Contrastive Learning to train the model in a self-supervised way using image data acquired in the real world using real sensors and simulated images from 3D games. In this paper, we also apply an Attention Mechanism module to emphasize features that contain more information about the source domain according to their measurement of significance. Finally, the generated images are used as datasets to train neural networks to perform a variety of downstream tasks to verify that the approach can fill in the gaps between the virtual and real worlds.
Semantic Map Injected GAN Training for Image-to-Image Translation
Dec 03, 2021
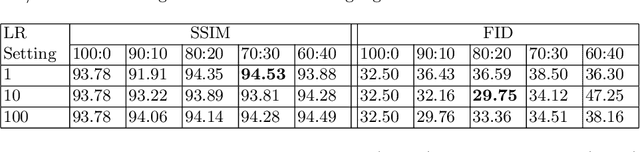

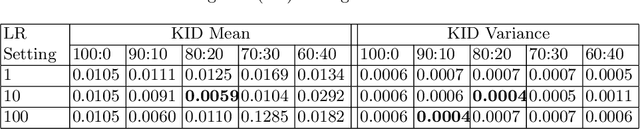
Image-to-image translation is the recent trend to transform images from one domain to another domain using generative adversarial network (GAN). The existing GAN models perform the training by only utilizing the input and output modalities of transformation. In this paper, we perform the semantic injected training of GAN models. Specifically, we train with original input and output modalities and inject a few epochs of training for translation from input to semantic map. Lets refer the original training as the training for the translation of input image into target domain. The injection of semantic training in the original training improves the generalization capability of the trained GAN model. Moreover, it also preserves the categorical information in a better way in the generated image. The semantic map is only utilized at the training time and is not required at the test time. The experiments are performed using state-of-the-art GAN models over CityScapes and RGB-NIR stereo datasets. We observe the improved performance in terms of the SSIM, FID and KID scores after injecting semantic training as compared to original training.
Filtered-Guided Diffusion: Fast Filter Guidance for Black-Box Diffusion Models
Jun 29, 2023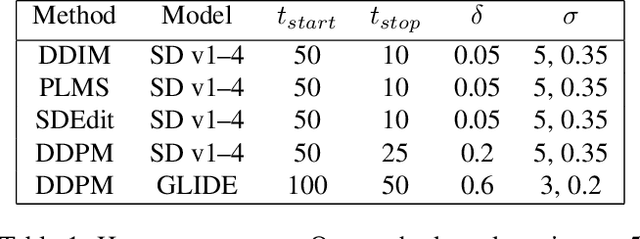


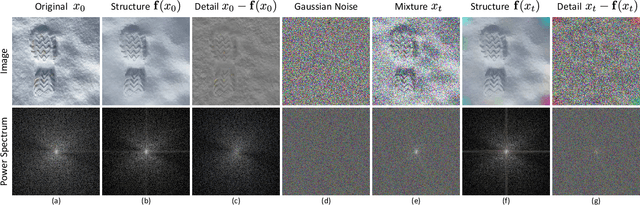
Recent advances in diffusion-based generative models have shown incredible promise for Image-to-Image translation and editing. Most recent work in this space relies on additional training or architecture-specific adjustments to the diffusion process. In this work, we show that much of this low-level control can be achieved without additional training or any access to features of the diffusion model. Our method simply applies a filter to the input of each diffusion step based on the output of the previous step in an adaptive manner. Notably, this approach does not depend on any specific architecture or sampler and can be done without access to internal features of the network, making it easy to combine with other techniques, samplers, and diffusion architectures. Furthermore, it has negligible cost to performance, and allows for more continuous adjustment of guidance strength than other approaches. We show FGD offers a fast and strong baseline that is competitive with recent architecture-dependent approaches. Furthermore, FGD can also be used as a simple add-on to enhance the structural guidance of other state-of-the-art I2I methods. Finally, our derivation of this method helps to understand the impact of self attention, a key component of other recent architecture-specific I2I approaches, in a more architecture-independent way. Project page: https://github.com/jaclyngu/FilteredGuidedDiffusion