 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
TPSeNCE: Towards Artifact-Free Realistic Rain Generation for Deraining and Object Detection in Rain
Nov 01, 2023
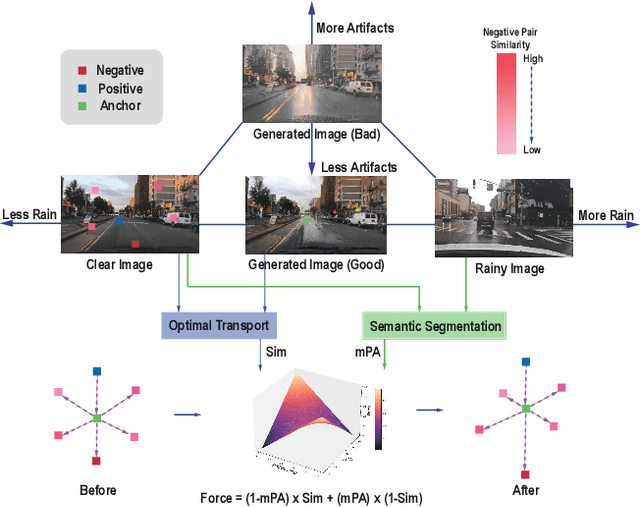

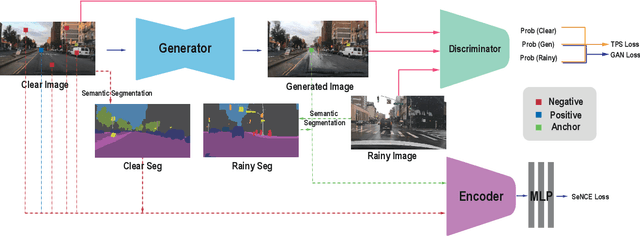
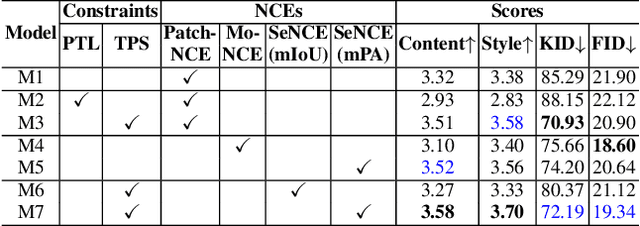
Rain generation algorithms have the potential to improve the generalization of deraining methods and scene understanding in rainy conditions. However, in practice, they produce artifacts and distortions and struggle to control the amount of rain generated due to a lack of proper constraints. In this paper, we propose an unpaired image-to-image translation framework for generating realistic rainy images. We first introduce a Triangular Probability Similarity (TPS) constraint to guide the generated images toward clear and rainy images in the discriminator manifold, thereby minimizing artifacts and distortions during rain generation. Unlike conventional contrastive learning approaches, which indiscriminately push negative samples away from the anchors, we propose a Semantic Noise Contrastive Estimation (SeNCE) strategy and reassess the pushing force of negative samples based on the semantic similarity between the clear and the rainy images and the feature similarity between the anchor and the negative samples. Experiments demonstrate realistic rain generation with minimal artifacts and distortions, which benefits image deraining and object detection in rain. Furthermore, the method can be used to generate realistic snowy and night images, underscoring its potential for broader applicability. Code is available at https://github.com/ShenZheng2000/TPSeNCE.
ACE: Zero-Shot Image to Image Translation via Pretrained Auto-Contrastive-Encoder
Feb 22, 2023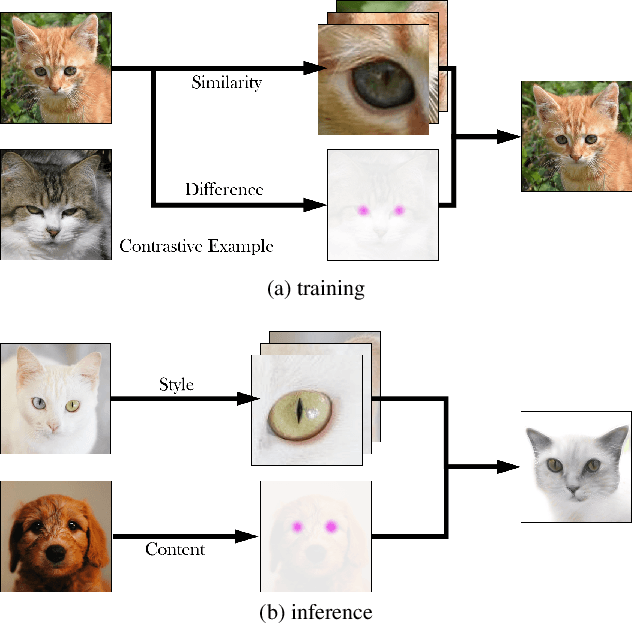
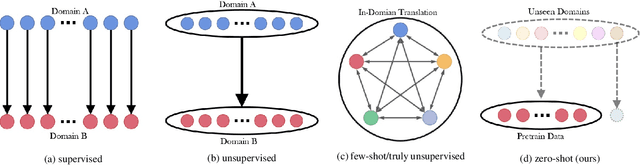
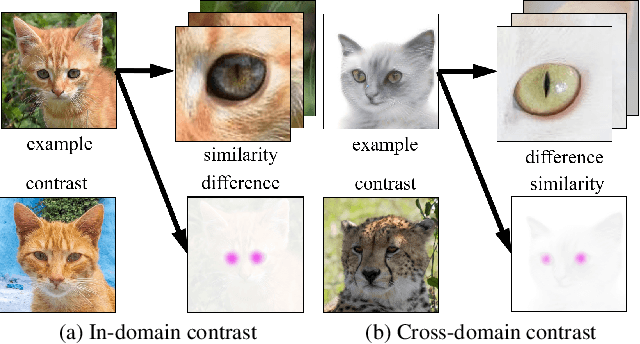
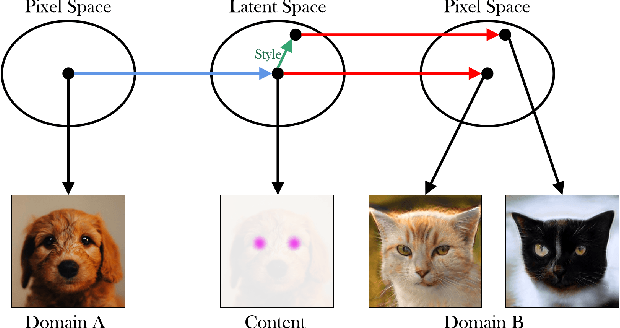
Image-to-image translation is a fundamental task in computer vision. It transforms images from one domain to images in another domain so that they have particular domain-specific characteristics. Most prior works train a generative model to learn the mapping from a source domain to a target domain. However, learning such mapping between domains is challenging because data from different domains can be highly unbalanced in terms of both quality and quantity. To address this problem, we propose a new approach to extract image features by learning the similarities and differences of samples within the same data distribution via a novel contrastive learning framework, which we call Auto-Contrastive-Encoder (ACE). ACE learns the content code as the similarity between samples with the same content information and different style perturbations. The design of ACE enables us to achieve zero-shot image-to-image translation with no training on image translation tasks for the first time. Moreover, our learning method can learn the style features of images on different domains effectively. Consequently, our model achieves competitive results on multimodal image translation tasks with zero-shot learning as well. Additionally, we demonstrate the potential of our method in transfer learning. With fine-tuning, the quality of translated images improves in unseen domains. Even though we use contrastive learning, all of our training can be performed on a single GPU with the batch size of 8.
The Blessing of Randomness: SDE Beats ODE in General Diffusion-based Image Editing
Nov 02, 2023
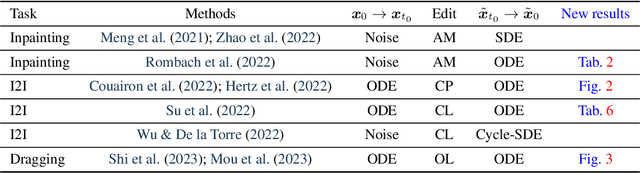

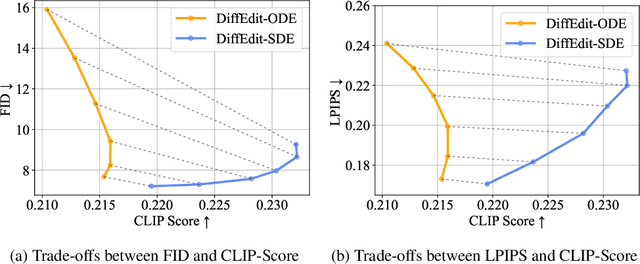
We present a unified probabilistic formulation for diffusion-based image editing, where a latent variable is edited in a task-specific manner and generally deviates from the corresponding marginal distribution induced by the original stochastic or ordinary differential equation (SDE or ODE). Instead, it defines a corresponding SDE or ODE for editing. In the formulation, we prove that the Kullback-Leibler divergence between the marginal distributions of the two SDEs gradually decreases while that for the ODEs remains as the time approaches zero, which shows the promise of SDE in image editing. Inspired by it, we provide the SDE counterparts for widely used ODE baselines in various tasks including inpainting and image-to-image translation, where SDE shows a consistent and substantial improvement. Moreover, we propose SDE-Drag -- a simple yet effective method built upon the SDE formulation for point-based content dragging. We build a challenging benchmark (termed DragBench) with open-set natural, art, and AI-generated images for evaluation. A user study on DragBench indicates that SDE-Drag significantly outperforms our ODE baseline, existing diffusion-based methods, and the renowned DragGAN. Our results demonstrate the superiority and versatility of SDE in image editing and push the boundary of diffusion-based editing methods.
Guided Image-to-Image Translation by Discriminator-Generator Communication
Mar 07, 2023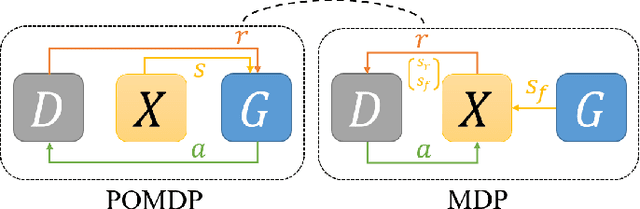
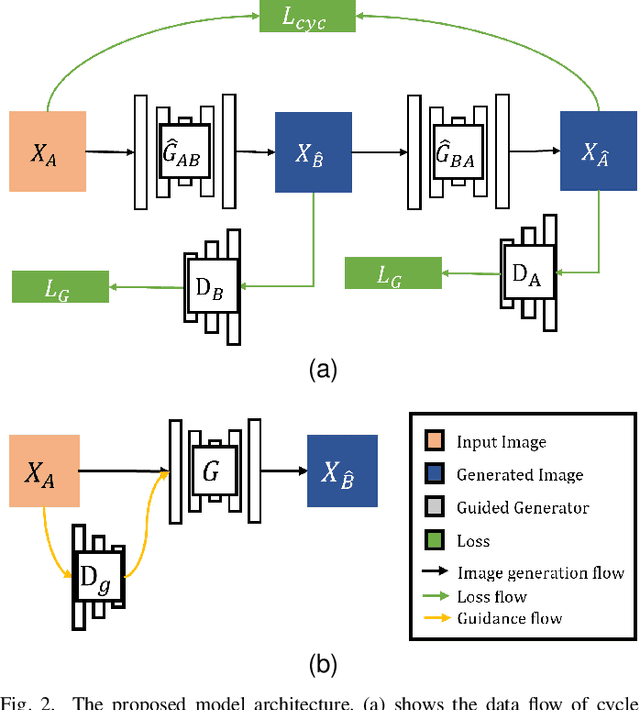


The goal of Image-to-image (I2I) translation is to transfer an image from a source domain to a target domain, which has recently drawn increasing attention. One major branch of this research is to formulate I2I translation based on Generative Adversarial Network (GAN). As a zero-sum game, GAN can be reformulated as a Partially-observed Markov Decision Process (POMDP) for generators, where generators cannot access full state information of their environments. This formulation illustrates the information insufficiency in the GAN training. To mitigate this problem, we propose to add a communication channel between discriminators and generators. We explore multiple architecture designs to integrate the communication mechanism into the I2I translation framework. To validate the performance of the proposed approach, we have conducted extensive experiments on various benchmark datasets. The experimental results confirm the superiority of our proposed method.
An Efficient Detection and Control System for Underwater Docking using Machine Learning and Realistic Simulation: A Comprehensive Approach
Nov 06, 2023
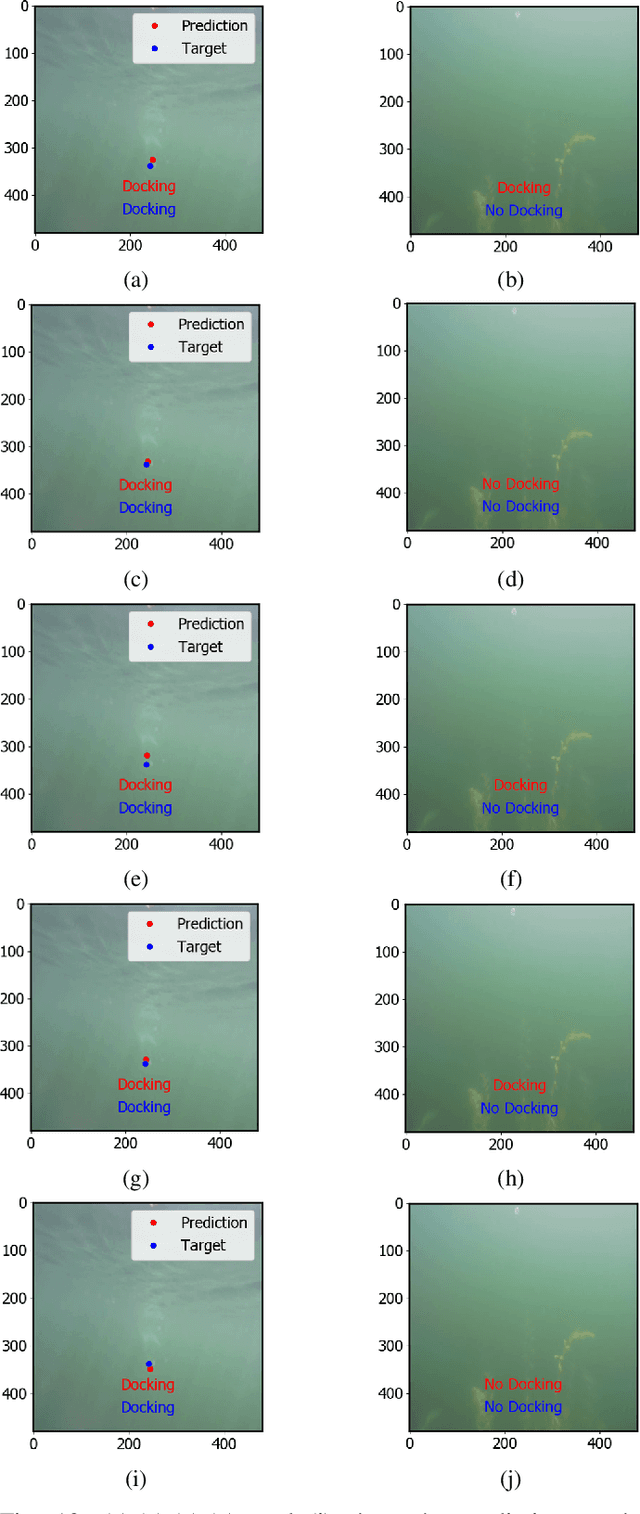


Underwater docking is critical to enable the persistent operation of Autonomous Underwater Vehicles (AUVs). For this, the AUV must be capable of detecting and localizing the docking station, which is complex due to the highly dynamic undersea environment. Image-based solutions offer a high acquisition rate and versatile alternative to adapt to this environment; however, the underwater environment presents challenges such as low visibility, high turbidity, and distortion. In addition to this, field experiments to validate underwater docking capabilities can be costly and dangerous due to the specialized equipment and safety considerations required to conduct the experiments. This work compares different deep-learning architectures to perform underwater docking detection and classification. The architecture with the best performance is then compressed using knowledge distillation under the teacher-student paradigm to reduce the network's memory footprint, allowing real-time implementation. To reduce the simulation-to-reality gap, a Generative Adversarial Network (GAN) is used to do image-to-image translation, converting the Gazebo simulation image into a realistic underwater-looking image. The obtained image is then processed using an underwater image formation model to simulate image attenuation over distance under different water types. The proposed method is finally evaluated according to the AUV docking success rate and compared with classical vision methods. The simulation results show an improvement of 20% in the high turbidity scenarios regardless of the underwater currents. Furthermore, we show the performance of the proposed approach by showing experimental results on the off-the-shelf AUV Iver3.
Frequency Domain Decomposition Translation for Enhanced Medical Image Translation Using GANs
Nov 06, 2023Medical Image-to-image translation is a key task in computer vision and generative artificial intelligence, and it is highly applicable to medical image analysis. GAN-based methods are the mainstream image translation methods, but they often ignore the variation and distribution of images in the frequency domain, or only take simple measures to align high-frequency information, which can lead to distortion and low quality of the generated images. To solve these problems, we propose a novel method called frequency domain decomposition translation (FDDT). This method decomposes the original image into a high-frequency component and a low-frequency component, with the high-frequency component containing the details and identity information, and the low-frequency component containing the style information. Next, the high-frequency and low-frequency components of the transformed image are aligned with the transformed results of the high-frequency and low-frequency components of the original image in the same frequency band in the spatial domain, thus preserving the identity information of the image while destroying as little stylistic information of the image as possible. We conduct extensive experiments on MRI images and natural images with FDDT and several mainstream baseline models, and we use four evaluation metrics to assess the quality of the generated images. Compared with the baseline models, optimally, FDDT can reduce Fr\'echet inception distance by up to 24.4%, structural similarity by up to 4.4%, peak signal-to-noise ratio by up to 5.8%, and mean squared error by up to 31%. Compared with the previous method, optimally, FDDT can reduce Fr\'echet inception distance by up to 23.7%, structural similarity by up to 1.8%, peak signal-to-noise ratio by up to 6.8%, and mean squared error by up to 31.6%.
A Comprehensive Review of Generative AI in Healthcare
Oct 01, 2023
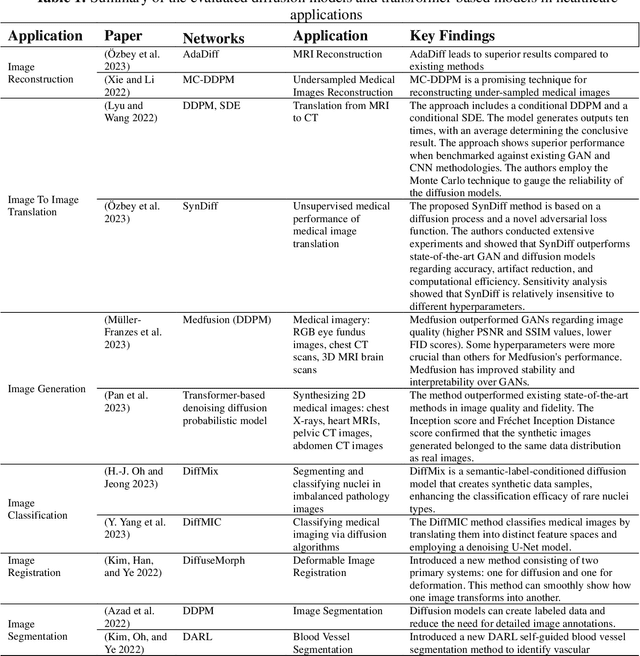
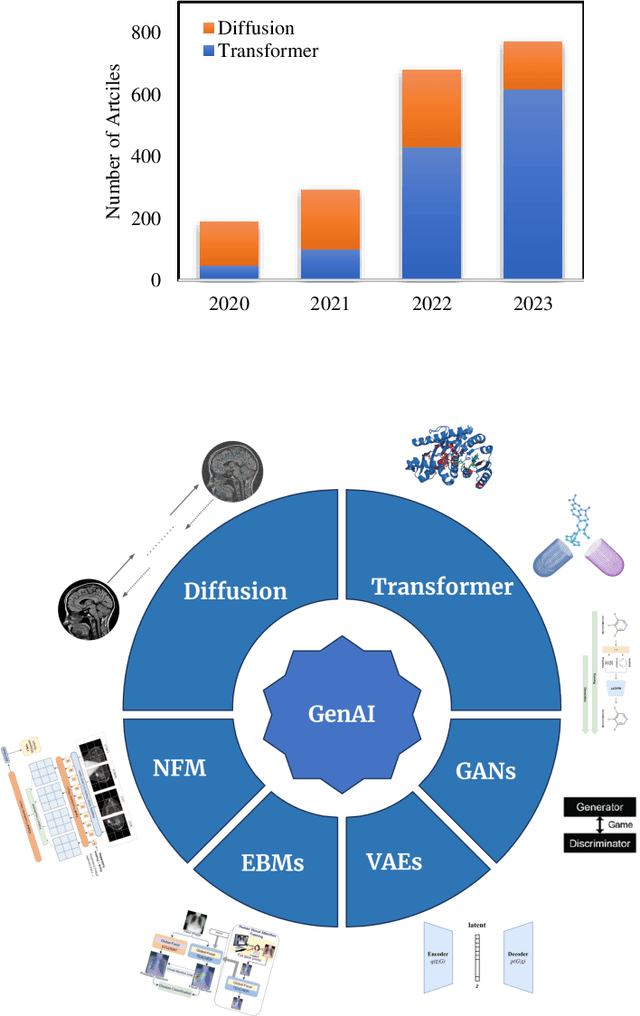
The advancement of Artificial Intelligence (AI) has catalyzed revolutionary changes across various sectors, notably in healthcare. Among the significant developments in this field are the applications of generative AI models, specifically transformers and diffusion models. These models have played a crucial role in analyzing diverse forms of data, including medical imaging (encompassing image reconstruction, image-to-image translation, image generation, and image classification), protein structure prediction, clinical documentation, diagnostic assistance, radiology interpretation, clinical decision support, medical coding, and billing, as well as drug design and molecular representation. Such applications have enhanced clinical diagnosis, data reconstruction, and drug synthesis. This review paper aims to offer a thorough overview of the generative AI applications in healthcare, focusing on transformers and diffusion models. Additionally, we propose potential directions for future research to tackle the existing limitations and meet the evolving demands of the healthcare sector. Intended to serve as a comprehensive guide for researchers and practitioners interested in the healthcare applications of generative AI, this review provides valuable insights into the current state of the art, challenges faced, and prospective future directions.
Deep Learning Enables Large Depth-of-Field Images for Sub-Diffraction-Limit Scanning Superlens Microscopy
Oct 27, 2023Scanning electron microscopy (SEM) is indispensable in diverse applications ranging from microelectronics to food processing because it provides large depth-of-field images with a resolution beyond the optical diffraction limit. However, the technology requires coating conductive films on insulator samples and a vacuum environment. We use deep learning to obtain the mapping relationship between optical super-resolution (OSR) images and SEM domain images, which enables the transformation of OSR images into SEM-like large depth-of-field images. Our custom-built scanning superlens microscopy (SSUM) system, which requires neither coating samples by conductive films nor a vacuum environment, is used to acquire the OSR images with features down to ~80 nm. The peak signal-to-noise ratio (PSNR) and structural similarity index measure values indicate that the deep learning method performs excellently in image-to-image translation, with a PSNR improvement of about 0.74 dB over the optical super-resolution images. The proposed method provides a high level of detail in the reconstructed results, indicating that it has broad applicability to chip-level defect detection, biological sample analysis, forensics, and various other fields.
OTRE: Where Optimal Transport Guided Unpaired Image-to-Image Translation Meets Regularization by Enhancing
Feb 09, 2023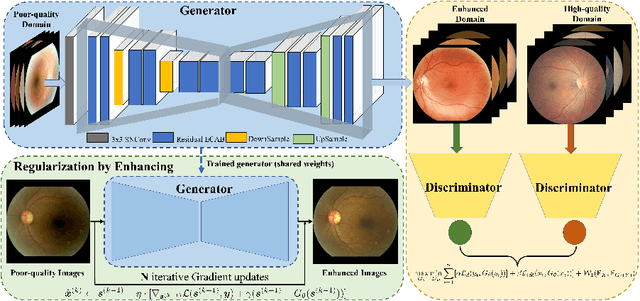
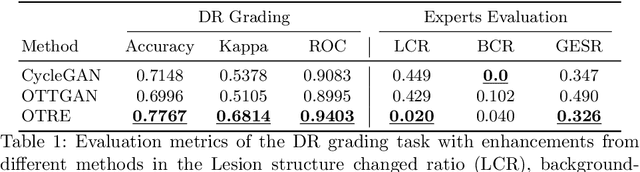
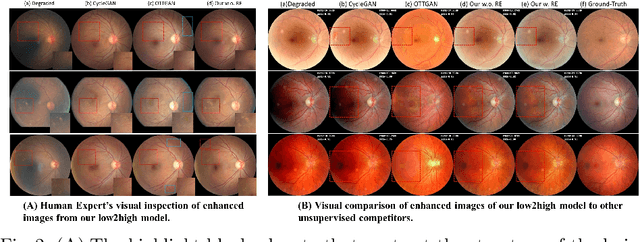
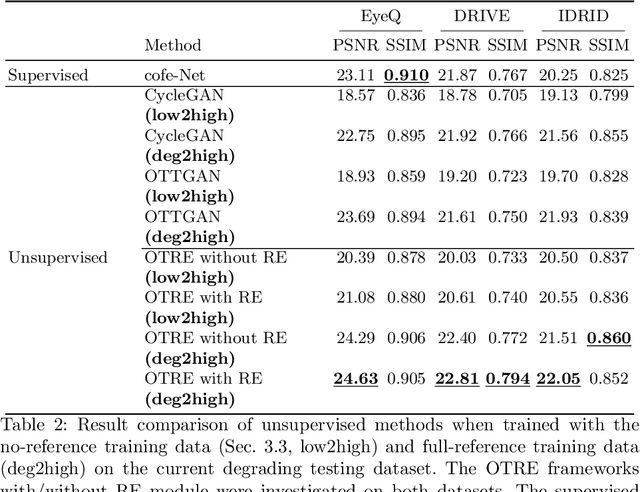
Non-mydriatic retinal color fundus photography (CFP) is widely available due to the advantage of not requiring pupillary dilation, however, is prone to poor quality due to operators, systemic imperfections, or patient-related causes. Optimal retinal image quality is mandated for accurate medical diagnoses and automated analyses. Herein, we leveraged the Optimal Transport (OT) theory to propose an unpaired image-to-image translation scheme for mapping low-quality retinal CFPs to high-quality counterparts. Furthermore, to improve the flexibility, robustness, and applicability of our image enhancement pipeline in the clinical practice, we generalized a state-of-the-art model-based image reconstruction method, regularization by denoising, by plugging in priors learned by our OT-guided image-to-image translation network. We named it as regularization by enhancing (RE). We validated the integrated framework, OTRE, on three publicly available retinal image datasets by assessing the quality after enhancement and their performance on various downstream tasks, including diabetic retinopathy grading, vessel segmentation, and diabetic lesion segmentation. The experimental results demonstrated the superiority of our proposed framework over some state-of-the-art unsupervised competitors and a state-of-the-art supervised method.
Optimal Transport-Guided Conditional Score-Based Diffusion Models
Nov 02, 2023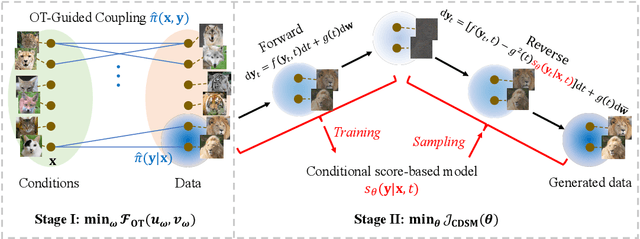
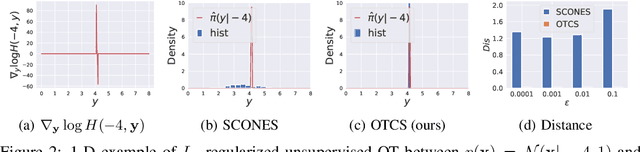


Conditional score-based diffusion model (SBDM) is for conditional generation of target data with paired data as condition, and has achieved great success in image translation. However, it requires the paired data as condition, and there would be insufficient paired data provided in real-world applications. To tackle the applications with partially paired or even unpaired dataset, we propose a novel Optimal Transport-guided Conditional Score-based diffusion model (OTCS) in this paper. We build the coupling relationship for the unpaired or partially paired dataset based on $L_2$-regularized unsupervised or semi-supervised optimal transport, respectively. Based on the coupling relationship, we develop the objective for training the conditional score-based model for unpaired or partially paired settings, which is based on a reformulation and generalization of the conditional SBDM for paired setting. With the estimated coupling relationship, we effectively train the conditional score-based model by designing a ``resampling-by-compatibility'' strategy to choose the sampled data with high compatibility as guidance. Extensive experiments on unpaired super-resolution and semi-paired image-to-image translation demonstrated the effectiveness of the proposed OTCS model. From the viewpoint of optimal transport, OTCS provides an approach to transport data across distributions, which is a challenge for OT on large-scale datasets. We theoretically prove that OTCS realizes the data transport in OT with a theoretical bound. Code is available at \url{https://github.com/XJTU-XGU/OTCS}.