 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Spotting In Handwritten Documents
Papers and Code
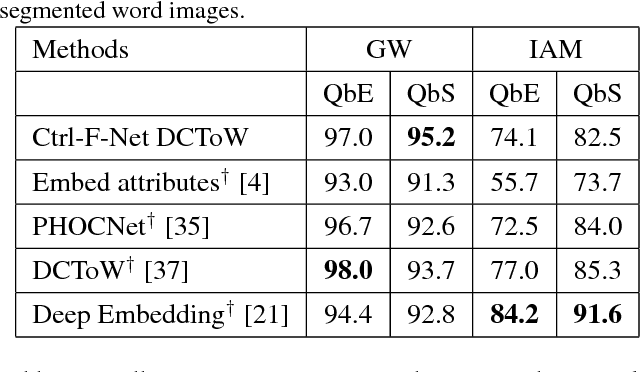
Bootstrapping Weakly Supervised Segmentation-free Word Spotting through HMM-based Alignment
Mar 24, 2020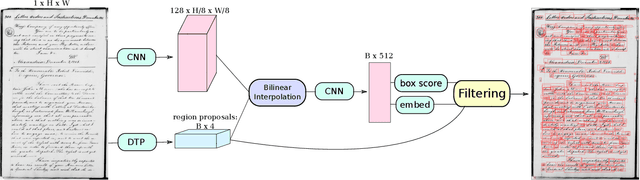
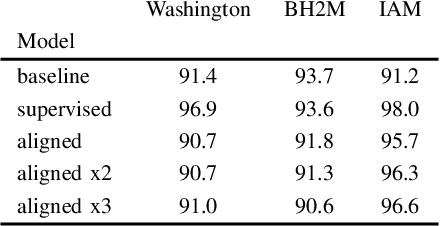
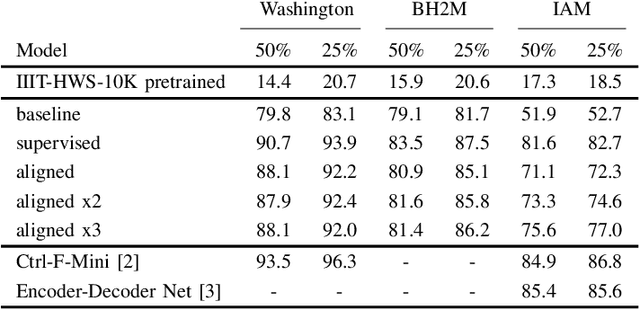
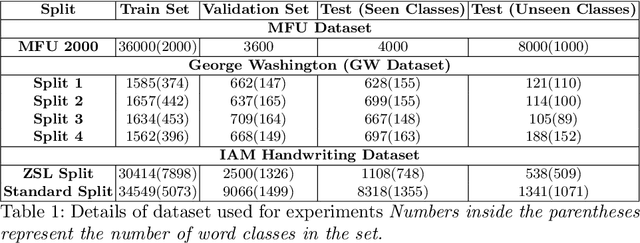
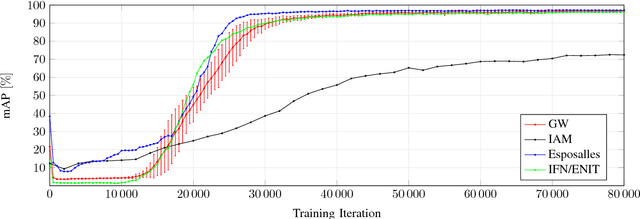
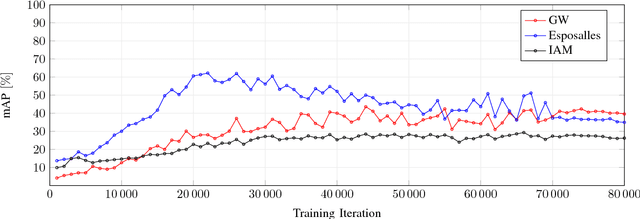
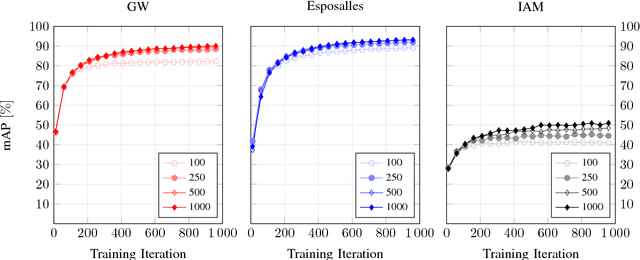
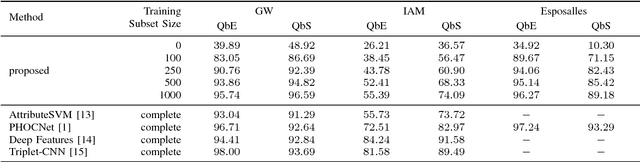
Recent work in word spotting in handwritten documents has yielded impressive results. This progress has largely been made by supervised learning systems, which are dependent on manually annotated data, making deployment to new collections a significant effort. In this paper, we propose an approach that utilises transcripts without bounding box annotations to train segmentation-free query-by-string word spotting models, given a partially trained model. This is done through a training-free alignment procedure based on hidden Markov models. This procedure creates a tentative mapping between word region proposals and the transcriptions to automatically create additional weakly annotated training data, without choosing any single alignment possibility as the correct one. When only using between 1% and 7% of the fully annotated training sets for partial convergence, we automatically annotate the remaining training data and successfully train using it. On all our datasets, our final trained model then comes within a few mAP% of the performance from a model trained with the full training set used as ground truth. We believe that this will be a significant advance towards a more general use of word spotting, since digital transcription data will already exist for parts of many collections of interest.
PhoNet: An Approach Towards Zero-shot Word Image Recognition in Historical Documents
May 31, 2021

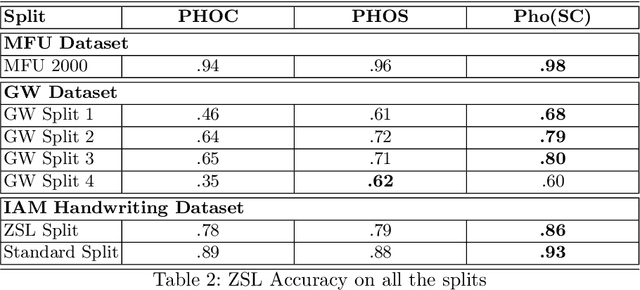
Annotating words in a historical document image archive for word image recognition purpose demands time and skilled human resource (like historians, paleographers). In a real-life scenario, obtaining sample images for all possible words is also not feasible. However, Zero-shot learning methods could aptly be used to recognize unseen/out-of-lexicon words in such historical document images. Based on previous state-of-the-art methods for word spotting and recognition, we propose a hybrid representation that considers the character's shape appearance to differentiate between two different words and has shown to be more effective in recognizing unseen words. This representation has been termed as Pyramidal Histogram of Shapes (PHOS), derived from PHOC, which embeds information about the occurrence and position of characters in the word. Later, the two representations are combined and experiments were conducted to examine the effectiveness of an embedding that has properties of both PHOS and PHOC. Encouraging results were obtained on two publicly available historical document datasets and one synthetic handwritten dataset, which justifies the efficacy of "Phos" and the combined "Pho(SC)" representation.
Annotation-free Learning of Deep Representations for Word Spotting using Synthetic Data and Self Labeling
Apr 09, 2020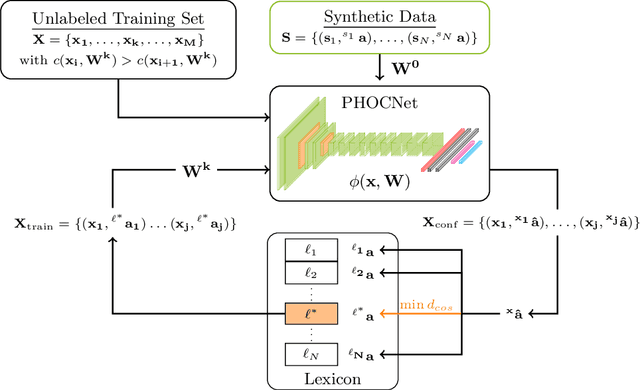
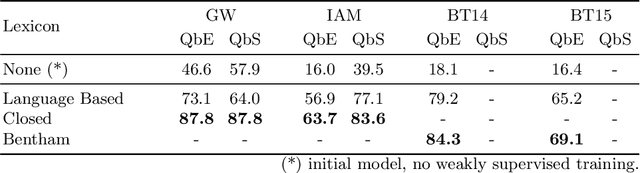
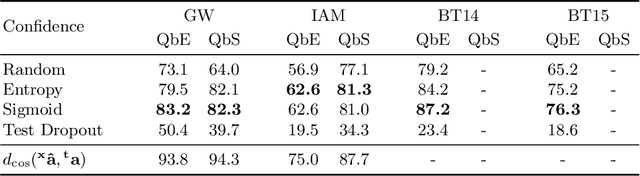
Word spotting is a popular tool for supporting the first exploration of historic, handwritten document collections. Today, the best performing methods rely on machine learning techniques, which require a high amount of annotated training material. As training data is usually not available in the application scenario, annotation-free methods aim at solving the retrieval task without representative training samples. In this work, we present an annotation-free method that still employs machine learning techniques and therefore outperforms other learning-free approaches. The weakly supervised training scheme relies on a lexicon, that does not need to precisely fit the dataset. In combination with a confidence based selection of pseudo-labeled training samples, we achieve state-of-the-art query-by-example performances. Furthermore, our method allows to perform query-by-string, which is usually not the case for other annotation-free methods.
A Probabilistic Framework for Lexicon-based Keyword Spotting in Handwritten Text Images
Apr 09, 2021


Query by String Keyword Spotting (KWS) is here considered as a key technology for indexing large collections of handwritten text images to allow fast textual access to the contents of these collections. Under this perspective, a probabilistic framework for lexicon-based KWS in text images is presented. The presentation aims at providing a tutorial view that helps to understand the relations between classical statements of KWS and the relative challenges entailed by these statements. More specifically, the development of the proposed framework makes it self-evident that word recognition or classification implicitly or explicitly underlies any formulation of KWS. Moreover, it clearly suggests that the same statistical models and training methods successfully used for handwriting text recognition can advantageously be used also for KWS, even though KWS does not generally require or rely on any kind of previously produced image transcripts. These ideas are developed into a specific, probabilistically sound approach for segmentation-free, lexicon-based, query-by-string KWS. Experiments carried out using this approach are presented, which support the consistency and general interest of the proposed framework. Several datasets, traditionally used for KWS benchmarking are considered, with results significantly better than those previously published for these datasets. In addition, results on two new, larger handwritten text image datasets are reported, showing the great potential of the methods proposed in this paper for indexing and textual search in large collections of handwritten documents.
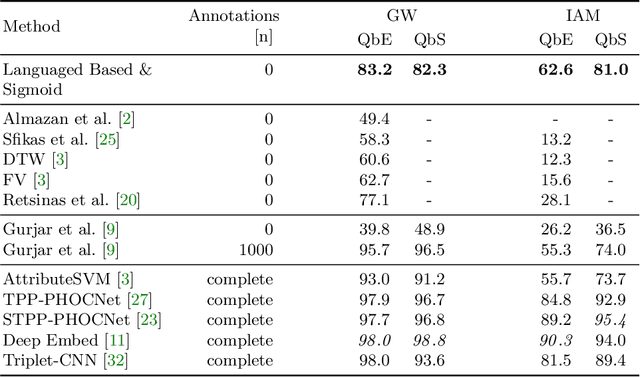
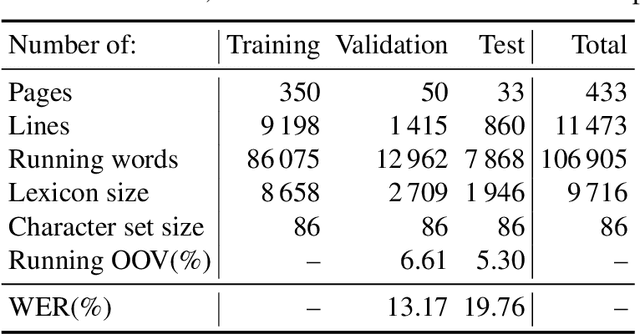
Attribute CNNs for Word Spotting in Handwritten Documents
Dec 20, 2017

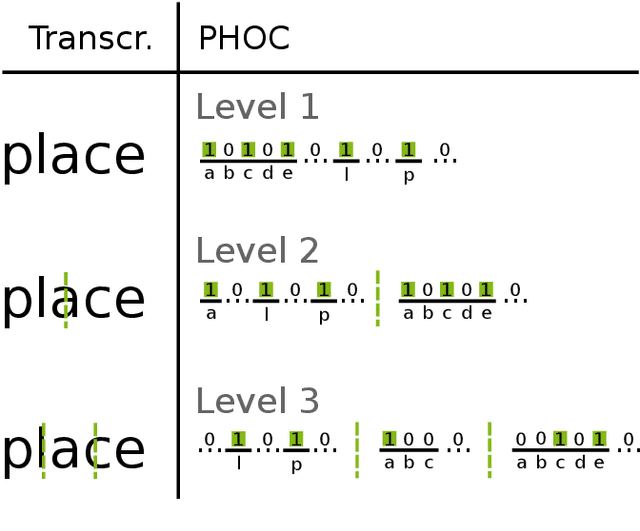
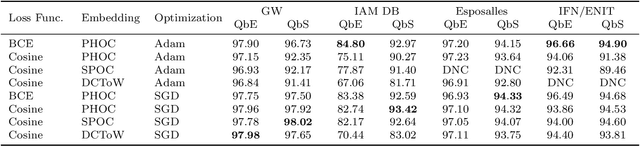
Word spotting has become a field of strong research interest in document image analysis over the last years. Recently, AttributeSVMs were proposed which predict a binary attribute representation. At their time, this influential method defined the state-of-the-art in segmentation-based word spotting. In this work, we present an approach for learning attribute representations with Convolutional Neural Networks (CNNs). By taking a probabilistic perspective on training CNNs, we derive two different loss functions for binary and real-valued word string embeddings. In addition, we propose two different CNN architectures, specifically designed for word spotting. These architectures are able to be trained in an end-to-end fashion. In a number of experiments, we investigate the influence of different word string embeddings and optimization strategies. We show our Attribute CNNs to achieve state-of-the-art results for segmentation-based word spotting on a large variety of data sets.
PHOCNet: A Deep Convolutional Neural Network for Word Spotting in Handwritten Documents
Dec 05, 2017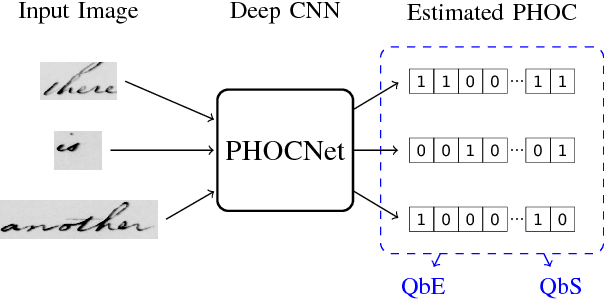
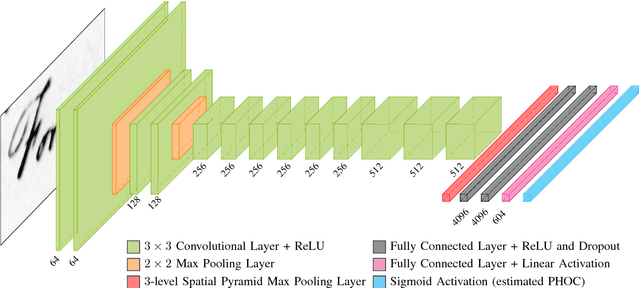
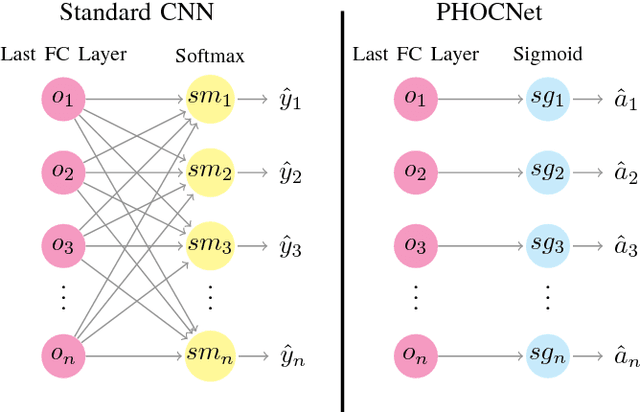
In recent years, deep convolutional neural networks have achieved state of the art performance in various computer vision task such as classification, detection or segmentation. Due to their outstanding performance, CNNs are more and more used in the field of document image analysis as well. In this work, we present a CNN architecture that is trained with the recently proposed PHOC representation. We show empirically that our CNN architecture is able to outperform state of the art results for various word spotting benchmarks while exhibiting short training and test times.
Learning Deep Representations for Word Spotting Under Weak Supervision
Jan 26, 2018
Convolutional Neural Networks have made their mark in various fields of computer vision in recent years. They have achieved state-of-the-art performance in the field of document analysis as well. However, CNNs require a large amount of annotated training data and, hence, great manual effort. In our approach, we introduce a method to drastically reduce the manual annotation effort while retaining the high performance of a CNN for word spotting in handwritten documents. The model is learned with weak supervision using a combination of synthetically generated training data and a small subset of the training partition of the handwritten data set. We show that the network achieves results highly competitive to the state-of-the-art in word spotting with shorter training times and a fraction of the annotation effort.
Radial Line Fourier Descriptor for Historical Handwritten Text Representation
Mar 20, 2018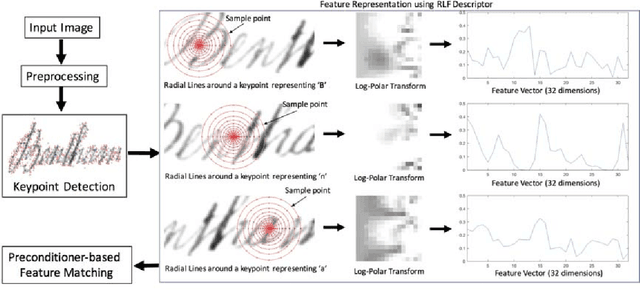
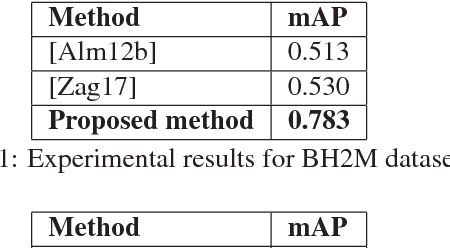

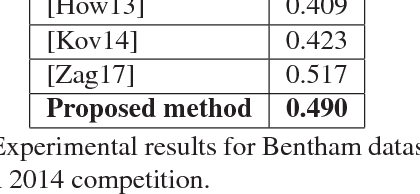
Automatic recognition of historical handwritten manuscripts is a daunting task due to paper degradation over time. Recognition-free retrieval or word spotting is popularly used for information retrieval and digitization of the historical handwritten documents. However, the performance of word spotting algorithms depends heavily on feature detection and representation methods. Although there exist popular feature descriptors such as Scale Invariant Feature Transform (SIFT) and Speeded Up Robust Features (SURF), the invariant properties of these descriptors amplify the noise in the degraded document images, rendering them more sensitive to noise and complex characteristics of historical manuscripts. Therefore, an efficient and relaxed feature descriptor is required as handwritten words across different documents are indeed similar, but not identical. This paper introduces a Radial Line Fourier (RLF) descriptor for handwritten word representation, with a short feature vector of 32 dimensions. A segmentation-free and training-free handwritten word spotting method is studied herein that relies on the proposed RLF descriptor, takes into account different keypoint representations and uses a simple preconditioner-based feature matching algorithm. The effectiveness of the RLF descriptor for segmentation-free handwritten word spotting is empirically evaluated on well-known historical handwritten datasets using standard evaluation measures.
Neural Ctrl-F: Segmentation-free Query-by-String Word Spotting in Handwritten Manuscript Collections
Aug 17, 2017
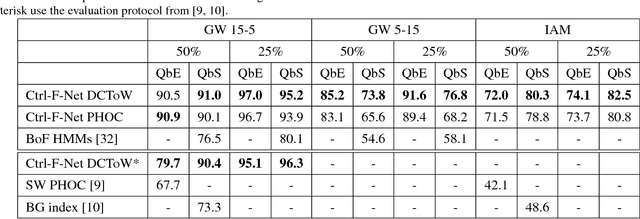
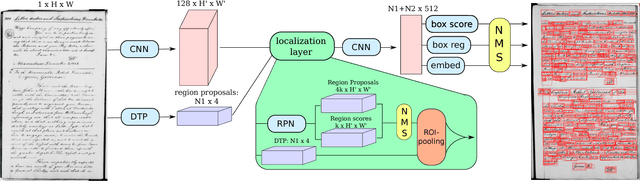
In this paper, we approach the problem of segmentation-free query-by-string word spotting for handwritten documents. In other words, we use methods inspired from computer vision and machine learning to search for words in large collections of digitized manuscripts. In particular, we are interested in historical handwritten texts, which are often far more challenging than modern printed documents. This task is important, as it provides people with a way to quickly find what they are looking for in large collections that are tedious and difficult to read manually. To this end, we introduce an end-to-end trainable model based on deep neural networks that we call Ctrl-F-Net. Given a full manuscript page, the model simultaneously generates region proposals, and embeds these into a distributed word embedding space, where searches are performed. We evaluate the model on common benchmarks for handwritten word spotting, outperforming the previous state-of-the-art segmentation-free approaches by a large margin, and in some cases even segmentation-based approaches. One interesting real-life application of our approach is to help historians to find and count specific words in court records that are related to women's sustenance activities and division of labor. We provide promising preliminary experiments that validate our method on this task.
Local Binary Pattern for Word Spotting in Handwritten Historical Document
Apr 21, 2016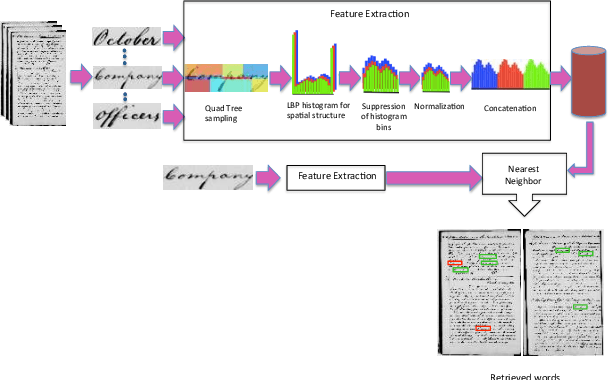


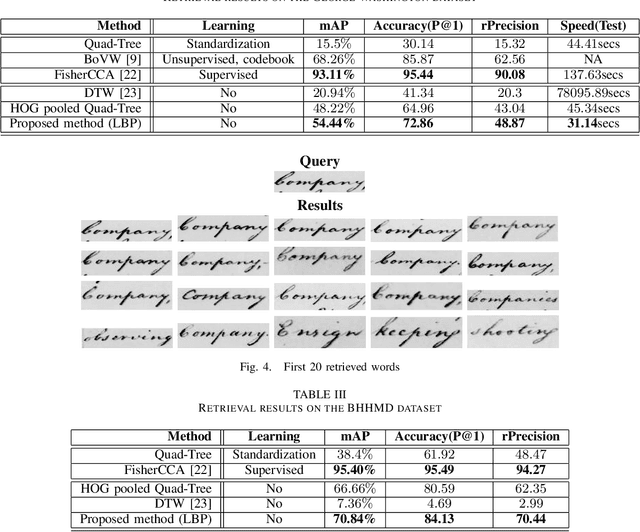
Digital libraries store images which can be highly degraded and to index this kind of images we resort to word spot- ting as our information retrieval system. Information retrieval for handwritten document images is more challenging due to the difficulties in complex layout analysis, large variations of writing styles, and degradation or low quality of historical manuscripts. This paper presents a simple innovative learning-free method for word spotting from large scale historical documents combining Local Binary Pattern (LBP) and spatial sampling. This method offers three advantages: firstly, it operates in completely learning free paradigm which is very different from unsupervised learning methods, secondly, the computational time is significantly low because of the LBP features which are very fast to compute, and thirdly, the method can be used in scenarios where annotations are not available. Finally we compare the results of our proposed retrieval method with the other methods in the literature.