 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU2 Net
Papers and Code
MATT-GS: Masked Attention-based 3DGS for Robot Perception and Object Detection
Mar 25, 2025This paper presents a novel masked attention-based 3D Gaussian Splatting (3DGS) approach to enhance robotic perception and object detection in industrial and smart factory environments. U2-Net is employed for background removal to isolate target objects from raw images, thereby minimizing clutter and ensuring that the model processes only relevant data. Additionally, a Sobel filter-based attention mechanism is integrated into the 3DGS framework to enhance fine details - capturing critical features such as screws, wires, and intricate textures essential for high-precision tasks. We validate our approach using quantitative metrics, including L1 loss, SSIM, PSNR, comparing the performance of the background-removed and attention-incorporated 3DGS model against the ground truth images and the original 3DGS training baseline. The results demonstrate significant improves in visual fidelity and detail preservation, highlighting the effectiveness of our method in enhancing robotic vision for object recognition and manipulation in complex industrial settings.
SKDCGN: Source-free Knowledge Distillation of Counterfactual Generative Networks using cGANs
Aug 10, 2022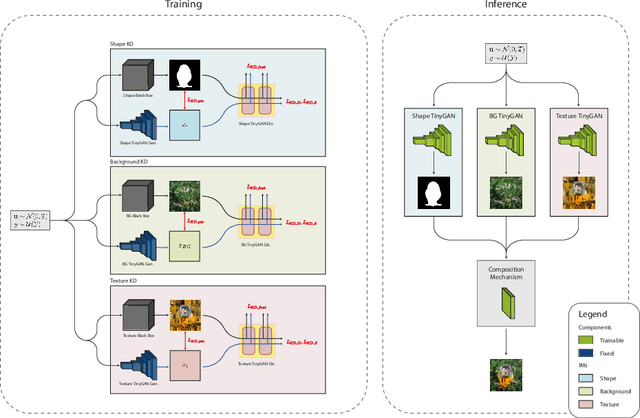


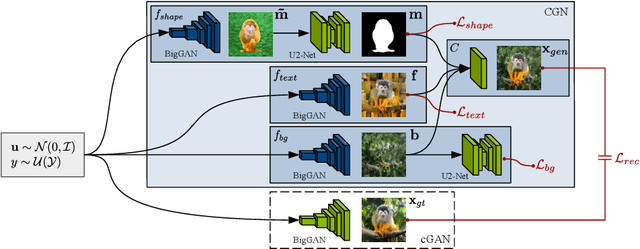
With the usage of appropriate inductive biases, Counterfactual Generative Networks (CGNs) can generate novel images from random combinations of shape, texture, and background manifolds. These images can be utilized to train an invariant classifier, avoiding the wide spread problem of deep architectures learning spurious correlations rather than meaningful ones. As a consequence, out-of-domain robustness is improved. However, the CGN architecture comprises multiple over parameterized networks, namely BigGAN and U2-Net. Training these networks requires appropriate background knowledge and extensive computation. Since one does not always have access to the precise training details, nor do they always possess the necessary knowledge of counterfactuals, our work addresses the following question: Can we use the knowledge embedded in pre-trained CGNs to train a lower-capacity model, assuming black-box access (i.e., only access to the pretrained CGN model) to the components of the architecture? In this direction, we propose a novel work named SKDCGN that attempts knowledge transfer using Knowledge Distillation (KD). In our proposed architecture, each independent mechanism (shape, texture, background) is represented by a student 'TinyGAN' that learns from the pretrained teacher 'BigGAN'. We demonstrate the efficacy of the proposed method using state-of-the-art datasets such as ImageNet, and MNIST by using KD and appropriate loss functions. Moreover, as an additional contribution, our paper conducts a thorough study on the composition mechanism of the CGNs, to gain a better understanding of how each mechanism influences the classification accuracy of an invariant classifier. Code available at: https://github.com/ambekarsameer96/SKDCGN
U2-Net: A Bayesian U-Net model with epistemic uncertainty feedback for photoreceptor layer segmentation in pathological OCT scans
Jan 23, 2019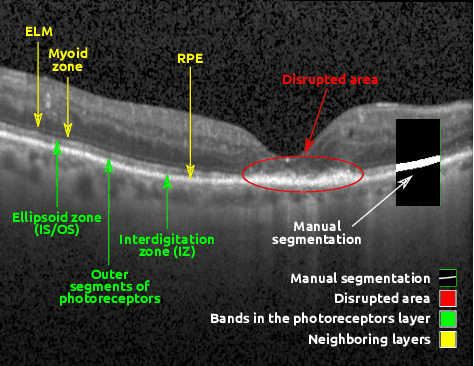
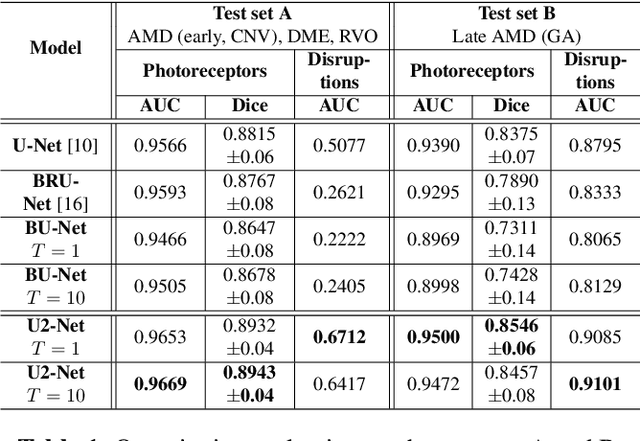
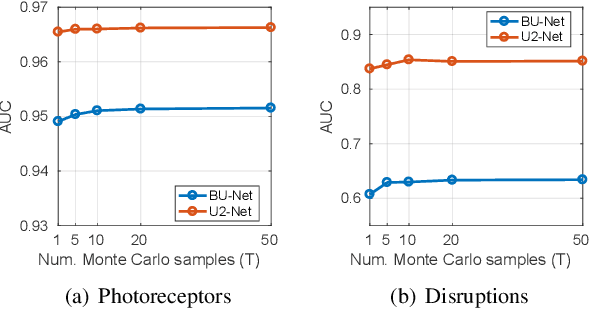
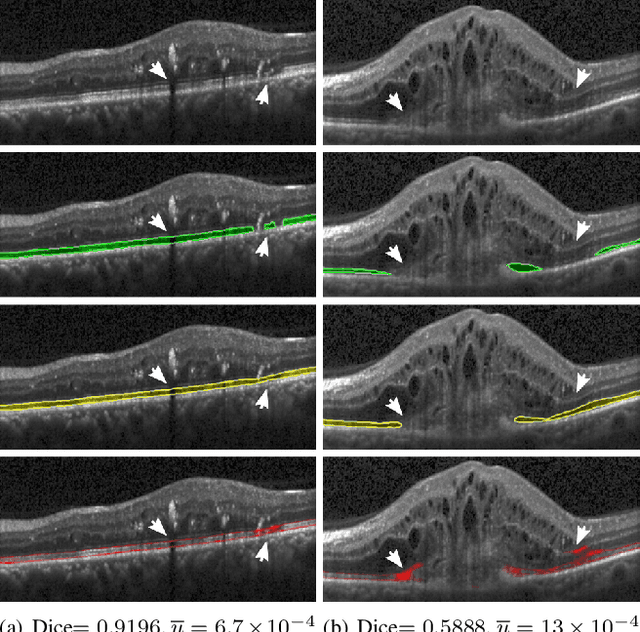
In this paper, we introduce a Bayesian deep learning based model for segmenting the photoreceptor layer in pathological OCT scans. Our architecture provides accurate segmentations of the photoreceptor layer and produces pixel-wise epistemic uncertainty maps that highlight potential areas of pathologies or segmentation errors. We empirically evaluated this approach in two sets of pathological OCT scans of patients with age-related macular degeneration, retinal vein oclussion and diabetic macular edema, improving the performance of the baseline U-Net both in terms of the Dice index and the area under the precision/recall curve. We also observed that the uncertainty estimates were inversely correlated with the model performance, underlying its utility for highlighting areas where manual inspection/correction might be needed.
* Accepted for publication at IEEE International Symposium on Biomedical Imaging (ISBI) 2019