 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePython Programming Puzzles P3
Papers and Code
Language Models Can Teach Themselves to Program Better
Jul 29, 2022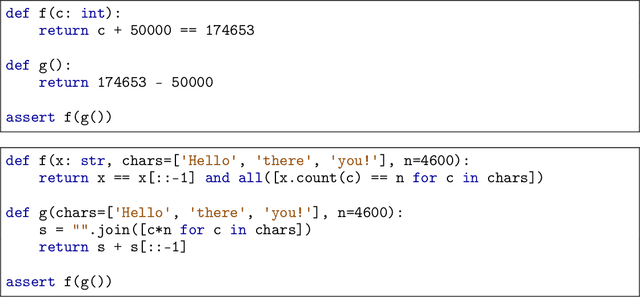

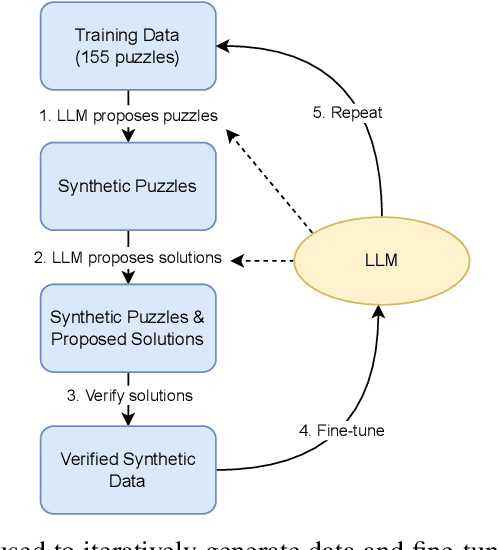
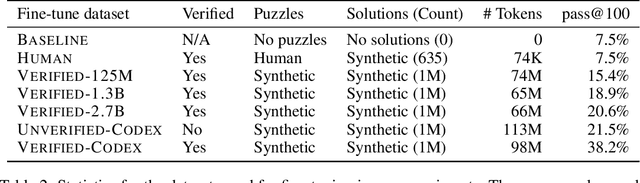
This work shows how one can use large-scale language models (LMs) to synthesize programming problems with verified solutions, in the form of programming puzzles, which can then in turn be used to fine-tune those same models, improving their performance. This work builds on two recent developments. First, LMs have achieved breakthroughs in non-trivial reasoning and algorithm implementation, generating code that can solve some intermediate-level competitive programming problems. However, training code LMs involves curated sets of natural-language problem descriptions and source-code tests and solutions, which are limited in size. Second, a new format of programming challenge called a programming puzzle was introduced, which does not require a natural language description and is directly specified by a source-code test. In this work we show how generating synthetic programming puzzles and solutions, verified for correctness by a Python interpreter, can be used to improve performance in solving test puzzles from P3, a public benchmark set of Python Programming Puzzles. Additionally, we release a dataset of 1 million puzzles and solutions generated by the Codex model, which we show can improve smaller models through fine-tuning.
Programming Puzzles
Jun 10, 2021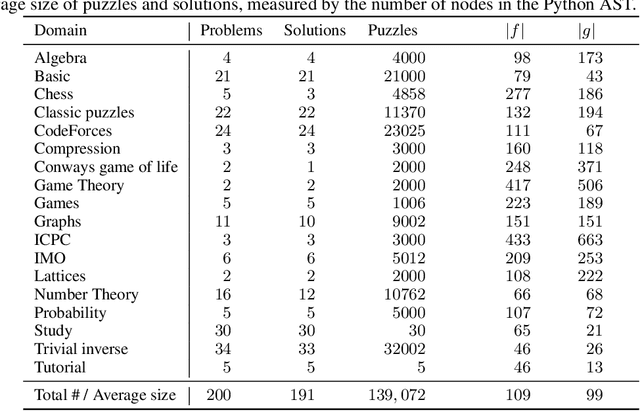
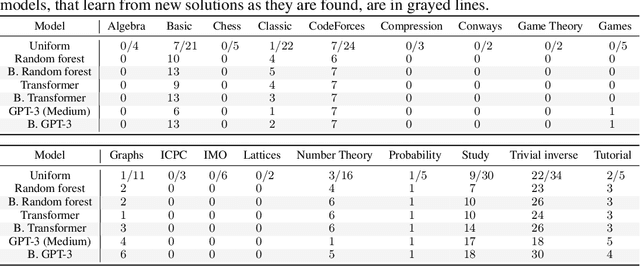
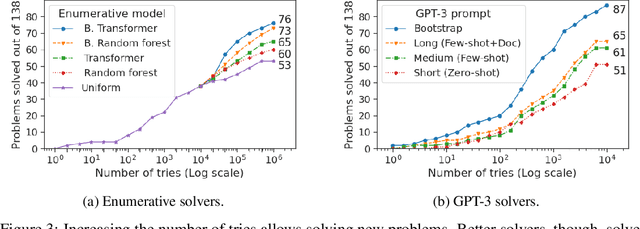
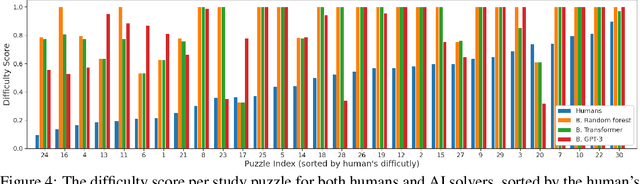
We introduce a new type of programming challenge called programming puzzles, as an objective and comprehensive evaluation of program synthesis, and release an open-source dataset of Python Programming Puzzles (P3). Each puzzle is defined by a short Python program $f$, and the goal is to find an input $x$ which makes $f$ output "True". The puzzles are objective in that each one is specified entirely by the source code of its verifier $f$, so evaluating $f(x)$ is all that is needed to test a candidate solution $x$. They do not require an answer key or input/output examples, nor do they depend on natural language understanding. The dataset is comprehensive in that it spans problems of a range of difficulties and domains, ranging from trivial string manipulation problems that are immediately obvious to human programmers (but not necessarily to AI), to classic programming puzzles (e.g., Towers of Hanoi), to interview/competitive-programming problems (e.g., dynamic programming), to longstanding open problems in algorithms and mathematics (e.g., factoring). The objective nature of P3 readily supports self-supervised bootstrapping. We develop baseline enumerative program synthesis and GPT-3 solvers that are capable of solving easy puzzles -- even without access to any reference solutions -- by learning from their own past solutions. Based on a small user study, we find puzzle difficulty to correlate between human programmers and the baseline AI solvers.