 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame Of Hanabi
Papers and Code
Zero Shot Coordination for Sparse Reward Tasks with Diverse Reward Shapings
Apr 28, 2026Many Multi-Agent Reinforcement Learning (MARL) agents fail to adapt properly to cooperating with agents trained with the same objectives but different seeds, algorithms, or other training differences. This is the problem of Zero-Shot Coordination (ZSC), which focuses on training agents to cooperate well with unknown agents. ZSC has been studied for a variety of tabular cases and simple games such as Hanabi, achieving excellent results. However, existing solutions to ZSC only consider identical rewards for your trained agents and all future partners. This is not realistic for the trained agents, as they do not consider the problem of cooperating with agents that have identical sparse objectives but shape the rewards for those objectives in different manner. To address this issue, we show how to train an ensemble of methods using randomized reward shapings chosen using 4 selection algorithms. Experiments done on the Overcooked environment demonstrate consistent improvements of 62.2%-119.2% in sparse reward over baseline ZSC algorithms when playing with agents that have identical sparse rewards but different reward shapings.
Don't Make the LLM Read the Graph: Make the Graph Think
Apr 24, 2026We investigate whether explicit belief graphs improve LLM performance in cooperative multi-agent reasoning. Through 3,000+ controlled trials across four LLM families in the cooperative card game Hanabi, we establish four findings. First, integration architecture determines whether belief graphs provide value: as prompt context, graphs are decorative for strong models and beneficial only for weak models on 2nd-order Theory of Mind (80% vs 10%, p<0.0001, OR=36.0); when graphs gate action selection through ranked shortlists, they become structurally essential even for strong models (100% vs 20% on 2nd-order ToM, p<0.001). Second, we identify "Planner Defiance," a model-family-specific failure where LLMs override correct planner recommendations at partial competence (90% override, replicated N=20); Gemini models show near-zero defiance while Llama 70B shows 90%, and models distinguish factual context (deferred to) from advisory recommendations (overridden). Third, full-game evidence confirms inter-agent conventions (+128% over baseline, p=0.003) outperform all single-agent interventions, and individual belief-graph components must be combined to produce gains. Fourth, preliminary scaling analysis (N=10/cell, exploratory) suggests graph depth has diminishing returns: shallow graphs provide the best cost-benefit ratio, while deeper ToM graphs appear harmful at larger player counts (-1.5 pts at 5-player, p=0.029).
Sparks of Cooperative Reasoning: LLMs as Strategic Hanabi Agents
Jan 26, 2026Cooperative reasoning under incomplete information remains challenging for both humans and multi-agent systems. The card game Hanabi embodies this challenge, requiring theory-of-mind reasoning and strategic communication. We benchmark 17 state-of-the-art LLM agents in 2-5 player games and study the impact of context engineering across model scales (4B to 600B+) to understand persistent coordination failures and robustness to scaffolding: from a minimal prompt with only explicit card details (Watson setting), to scaffolding with programmatic, Bayesian-motivated deductions (Sherlock setting), to multi-turn state tracking via working memory (Mycroft setting). We show that (1) agents can maintain an internal working memory for state tracking and (2) cross-play performance between different LLMs smoothly interpolates with model strength. In the Sherlock setting, the strongest reasoning models exceed 15 points on average across player counts, yet still trail experienced humans and specialist Hanabi agents, both consistently scoring above 20. We release the first public Hanabi datasets with annotated trajectories and move utilities: (1) HanabiLogs, containing 1,520 full game logs for instruction tuning, and (2) HanabiRewards, containing 560 games with dense move-level value annotations for all candidate moves. Supervised and RL finetuning of a 4B open-weight model (Qwen3-Instruct) on our datasets improves cooperative Hanabi play by 21% and 156% respectively, bringing performance to within ~3 points of a strong proprietary reasoning model (o4-mini) and surpassing the best non-reasoning model (GPT-4.1) by 52%. The HanabiRewards RL-finetuned model further generalizes beyond Hanabi, improving performance on a cooperative group-guessing benchmark by 11%, temporal reasoning on EventQA by 6.4%, instruction-following on IFBench-800K by 1.7 Pass@10, and matching AIME 2025 mathematical reasoning Pass@10.
Efficient Reinforcement Learning for Zero-Shot Coordination in Evolving Games
Nov 18, 2025Zero-shot coordination(ZSC), a key challenge in multi-agent game theory, has become a hot topic in reinforcement learning (RL) research recently, especially in complex evolving games. It focuses on the generalization ability of agents, requiring them to coordinate well with collaborators from a diverse, potentially evolving, pool of partners that are not seen before without any fine-tuning. Population-based training, which approximates such an evolving partner pool, has been proven to provide good zero-shot coordination performance; nevertheless, existing methods are limited by computational resources, mainly focusing on optimizing diversity in small populations while neglecting the potential performance gains from scaling population size. To address this issue, this paper proposes the Scalable Population Training (ScaPT), an efficient RL training framework comprising two key components: a meta-agent that efficiently realizes a population by selectively sharing parameters across agents, and a mutual information regularizer that guarantees population diversity. To empirically validate the effectiveness of ScaPT, this paper evaluates it along with representational frameworks in Hanabi cooperative game and confirms its superiority.
Knowledge and Common Knowledge of Strategies
Oct 22, 2025Most existing work on strategic reasoning simply adopts either an informed or an uninformed semantics. We propose a model where knowledge of strategies can be specified on a fine-grained level. In particular, it is possible to distinguish first-order, higher-order, and common knowledge of strategies. We illustrate the effect of higher-order knowledge of strategies by studying the game Hanabi. Further, we show that common knowledge of strategies is necessary to solve the consensus problem. Finally, we study the decidability of the model checking problem.
LLM-Hanabi: Evaluating Multi-Agent Gameplays with Theory-of-Mind and Rationale Inference in Imperfect Information Collaboration Game
Oct 06, 2025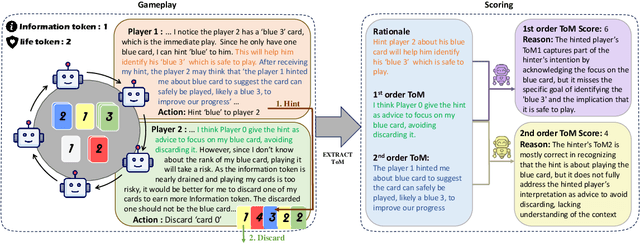
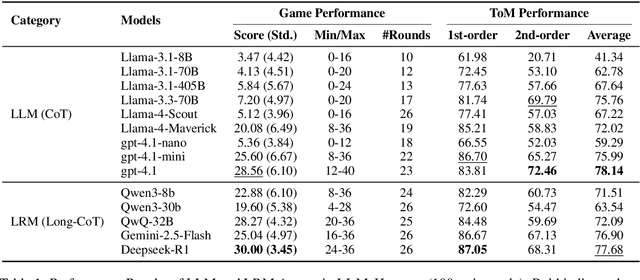
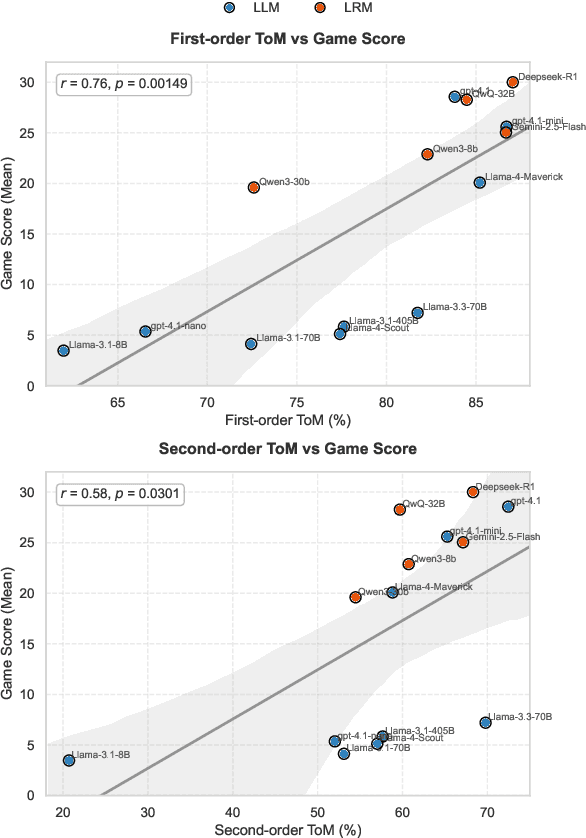
Effective multi-agent collaboration requires agents to infer the rationale behind others' actions, a capability rooted in Theory-of-Mind (ToM). While recent Large Language Models (LLMs) excel at logical inference, their ability to infer rationale in dynamic, collaborative settings remains under-explored. This study introduces LLM-Hanabi, a novel benchmark that uses the cooperative game Hanabi to evaluate the rationale inference and ToM of LLMs. Our framework features an automated evaluation system that measures both game performance and ToM proficiency. Across a range of models, we find a significant positive correlation between ToM and in-game success. Notably, first-order ToM (interpreting others' intent) correlates more strongly with performance than second-order ToM (predicting others' interpretations). These findings highlight that for effective AI collaboration, the ability to accurately interpret a partner's rationale is more critical than higher-order reasoning. We conclude that prioritizing first-order ToM is a promising direction for enhancing the collaborative capabilities of future models.
Ad-Hoc Human-AI Coordination Challenge
Jun 26, 2025



Achieving seamless coordination between AI agents and humans is crucial for real-world applications, yet it remains a significant open challenge. Hanabi is a cooperative card game featuring imperfect information, constrained communication, theory of mind requirements, and coordinated action -- making it an ideal testbed for human-AI coordination. However, its use for human-AI interaction has been limited by the challenges of human evaluation. In this work, we introduce the Ad-Hoc Human-AI Coordination Challenge (AH2AC2) to overcome the constraints of costly and difficult-to-reproduce human evaluations. We develop \textit{human proxy agents} on a large-scale human dataset that serve as robust, cheap, and reproducible human-like evaluation partners in AH2AC2. To encourage the development of data-efficient methods, we open-source a dataset of 3,079 games, deliberately limiting the amount of available human gameplay data. We present baseline results for both two- and three- player Hanabi scenarios. To ensure fair evaluation, we host the proxy agents through a controlled evaluation system rather than releasing them publicly. The code is available at \href{https://github.com/FLAIROx/ah2ac2}{https://github.com/FLAIROx/ah2ac2}.
A Generalist Hanabi Agent
Mar 17, 2025Traditional multi-agent reinforcement learning (MARL) systems can develop cooperative strategies through repeated interactions. However, these systems are unable to perform well on any other setting than the one they have been trained on, and struggle to successfully cooperate with unfamiliar collaborators. This is particularly visible in the Hanabi benchmark, a popular 2-to-5 player cooperative card-game which requires complex reasoning and precise assistance to other agents. Current MARL agents for Hanabi can only learn one specific game-setting (e.g., 2-player games), and play with the same algorithmic agents. This is in stark contrast to humans, who can quickly adjust their strategies to work with unfamiliar partners or situations. In this paper, we introduce Recurrent Replay Relevance Distributed DQN (R3D2), a generalist agent for Hanabi, designed to overcome these limitations. We reformulate the task using text, as language has been shown to improve transfer. We then propose a distributed MARL algorithm that copes with the resulting dynamic observation- and action-space. In doing so, our agent is the first that can play all game settings concurrently, and extend strategies learned from one setting to other ones. As a consequence, our agent also demonstrates the ability to collaborate with different algorithmic agents -- agents that are themselves unable to do so. The implementation code is available at: $\href{https://github.com/chandar-lab/R3D2-A-Generalist-Hanabi-Agent}{R3D2-A-Generalist-Hanabi-Agent}$
Augmenting the action space with conventions to improve multi-agent cooperation in Hanabi
Dec 09, 2024The card game Hanabi is considered a strong medium for the testing and development of multi-agent reinforcement learning (MARL) algorithms, due to its cooperative nature, hidden information, limited communication and remarkable complexity. Previous research efforts have explored the capabilities of MARL algorithms within Hanabi, focusing largely on advanced architecture design and algorithmic manipulations to achieve state-of-the-art performance for a various number of cooperators. However, this often leads to complex solution strategies with high computational cost and requiring large amounts of training data. For humans to solve the Hanabi game effectively, they require the use of conventions, which often allows for a means to implicitly convey ideas or knowledge based on a predefined, and mutually agreed upon, set of ``rules''. Multi-agent problems containing partial observability, especially when limited communication is present, can benefit greatly from the use of implicit knowledge sharing. In this paper, we propose a novel approach to augmenting the action space using conventions, which act as special cooperative actions that span over multiple time steps and multiple agents, requiring agents to actively opt in for it to reach fruition. These conventions are based on existing human conventions, and result in a significant improvement on the performance of existing techniques for self-play and cross-play across a various number of cooperators within Hanabi.
HOLA-Drone: Hypergraphic Open-ended Learning for Zero-Shot Multi-Drone Cooperative Pursuit
Sep 13, 2024Zero-shot coordination (ZSC) is a significant challenge in multi-agent collaboration, aiming to develop agents that can coordinate with unseen partners they have not encountered before. Recent cutting-edge ZSC methods have primarily focused on two-player video games such as OverCooked!2 and Hanabi. In this paper, we extend the scope of ZSC research to the multi-drone cooperative pursuit scenario, exploring how to construct a drone agent capable of coordinating with multiple unseen partners to capture multiple evaders. We propose a novel Hypergraphic Open-ended Learning Algorithm (HOLA-Drone) that continuously adapts the learning objective based on our hypergraphic-form game modeling, aiming to improve cooperative abilities with multiple unknown drone teammates. To empirically verify the effectiveness of HOLA-Drone, we build two different unseen drone teammate pools to evaluate their performance in coordination with various unseen partners. The experimental results demonstrate that HOLA-Drone outperforms the baseline methods in coordination with unseen drone teammates. Furthermore, real-world experiments validate the feasibility of HOLA-Drone in physical systems. Videos can be found on the project homepage~\url{https://sites.google.com/view/hola-drone}.