 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Sea Treasure Pareto Front
Papers and Code
In Search for Architectures and Loss Functions in Multi-Objective Reinforcement Learning
Jul 23, 2024



Multi-objective reinforcement learning (MORL) is essential for addressing the intricacies of real-world RL problems, which often require trade-offs between multiple utility functions. However, MORL is challenging due to unstable learning dynamics with deep learning-based function approximators. The research path most taken has been to explore different value-based loss functions for MORL to overcome this issue. Our work empirically explores model-free policy learning loss functions and the impact of different architectural choices. We introduce two different approaches: Multi-objective Proximal Policy Optimization (MOPPO), which extends PPO to MORL, and Multi-objective Advantage Actor Critic (MOA2C), which acts as a simple baseline in our ablations. Our proposed approach is straightforward to implement, requiring only small modifications at the level of function approximator. We conduct comprehensive evaluations on the MORL Deep Sea Treasure, Minecart, and Reacher environments and show that MOPPO effectively captures the Pareto front. Our extensive ablation studies and empirical analyses reveal the impact of different architectural choices, underscoring the robustness and versatility of MOPPO compared to popular MORL approaches like Pareto Conditioned Networks (PCN) and Envelope Q-learning in terms of MORL metrics, including hypervolume and expected utility.
Deep W-Networks: Solving Multi-Objective Optimisation Problems With Deep Reinforcement Learning
Nov 09, 2022In this paper, we build on advances introduced by the Deep Q-Networks (DQN) approach to extend the multi-objective tabular Reinforcement Learning (RL) algorithm W-learning to large state spaces. W-learning algorithm can naturally solve the competition between multiple single policies in multi-objective environments. However, the tabular version does not scale well to environments with large state spaces. To address this issue, we replace underlying Q-tables with DQN, and propose an addition of W-Networks, as a replacement for tabular weights (W) representations. We evaluate the resulting Deep W-Networks (DWN) approach in two widely-accepted multi-objective RL benchmarks: deep sea treasure and multi-objective mountain car. We show that DWN solves the competition between multiple policies while outperforming the baseline in the form of a DQN solution. Additionally, we demonstrate that the proposed algorithm can find the Pareto front in both tested environments.
PD-MORL: Preference-Driven Multi-Objective Reinforcement Learning Algorithm
Aug 16, 2022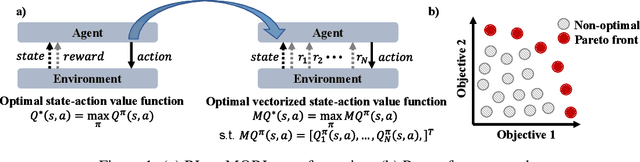

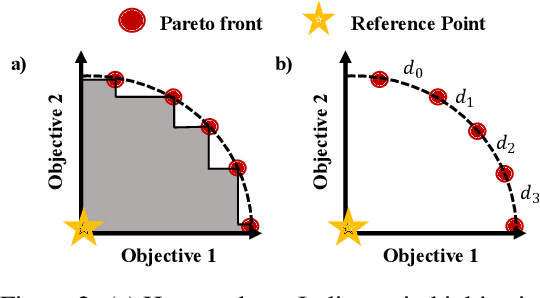
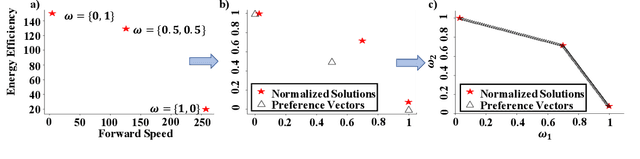
Many real-world problems involve multiple, possibly conflicting, objectives. Multi-objective reinforcement learning (MORL) approaches have emerged to tackle these problems by maximizing a joint objective function weighted by a preference vector. These approaches find fixed customized policies corresponding to preference vectors specified during training. However, the design constraints and objectives typically change dynamically in real-life scenarios. Furthermore, storing a policy for each potential preference is not scalable. Hence, obtaining a set of Pareto front solutions for the entire preference space in a given domain with a single training is critical. To this end, we propose a novel MORL algorithm that trains a single universal network to cover the entire preference space. The proposed approach, Preference-Driven MORL (PD-MORL), utilizes the preferences as guidance to update the network parameters. After demonstrating PD-MORL using classical Deep Sea Treasure and Fruit Tree Navigation benchmarks, we evaluate its performance on challenging multi-objective continuous control tasks.
A Review of the Deep Sea Treasure problem as a Multi-Objective Reinforcement Learning Benchmark
Oct 26, 2021
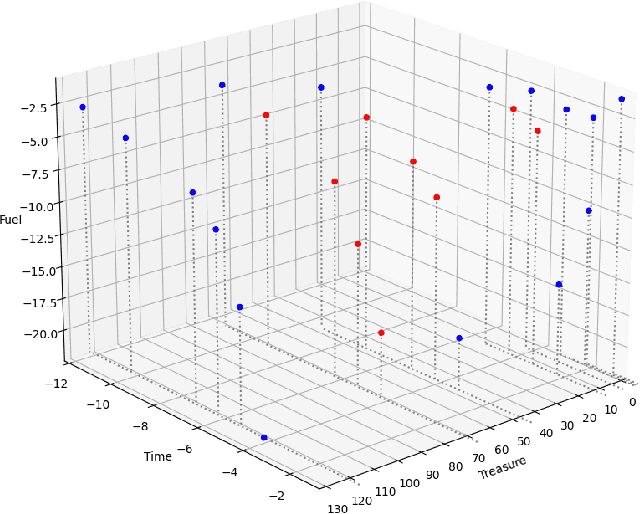
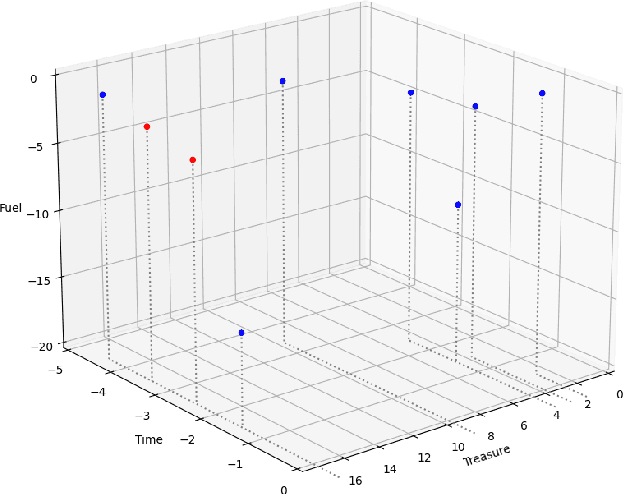
In this paper, the authors investigate the Deep Sea Treasure (DST) problem as proposed by Vamplew et al. Through a number of proofs, the authors show the original DST problem to be quite basic, and not always representative of practical Multi-Objective Optimization problems. In an attempt to bring theory closer to practice, the authors propose an alternative, improved version of the DST problem, and prove that some of the properties that simplify the original DST problem no longer hold. The authors also provide a reference implementation and perform a comparison between their implementation, and other existing open-source implementations of the problem. Finally, the authors also provide a complete Pareto-front for their new DST problem.