 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanglish
Papers and Code
BanglishRev: A Large-Scale Bangla-English and Code-mixed Dataset of Product Reviews in E-Commerce
Dec 17, 2024



This work presents the BanglishRev Dataset, the largest e-commerce product review dataset to date for reviews written in Bengali, English, a mixture of both and Banglish, Bengali words written with English alphabets. The dataset comprises of 1.74 million written reviews from 3.2 million ratings information collected from a total of 128k products being sold in online e-commerce platforms targeting the Bengali population. It includes an extensive array of related metadata for each of the reviews including the rating given by the reviewer, date the review was posted and date of purchase, number of likes, dislikes, response from the seller, images associated with the review etc. With sentiment analysis being the most prominent usage of review datasets, experimentation with a binary sentiment analysis model with the review rating serving as an indicator of positive or negative sentiment was conducted to evaluate the effectiveness of the large amount of data presented in BanglishRev for sentiment analysis tasks. A BanglishBERT model is trained on the data from BanglishRev with reviews being considered labeled positive if the rating is greater than 3 and negative if the rating is less than or equal to 3. The model is evaluated by being testing against a previously published manually annotated dataset for e-commerce reviews written in a mixture of Bangla, English and Banglish. The experimental model achieved an exceptional accuracy of 94\% and F1 score of 0.94, demonstrating the dataset's efficacy for sentiment analysis. Some of the intriguing patterns and observations seen within the dataset and future research directions where the dataset can be utilized is also discussed and explored. The dataset can be accessed through https://huggingface.co/datasets/BanglishRev/bangla-english-and-code-mixed-ecommerce-review-dataset.
Vashantor: A Large-scale Multilingual Benchmark Dataset for Automated Translation of Bangla Regional Dialects to Bangla Language
Nov 18, 2023



The Bangla linguistic variety is a fascinating mix of regional dialects that adds to the cultural diversity of the Bangla-speaking community. Despite extensive study into translating Bangla to English, English to Bangla, and Banglish to Bangla in the past, there has been a noticeable gap in translating Bangla regional dialects into standard Bangla. In this study, we set out to fill this gap by creating a collection of 32,500 sentences, encompassing Bangla, Banglish, and English, representing five regional Bangla dialects. Our aim is to translate these regional dialects into standard Bangla and detect regions accurately. To achieve this, we proposed models known as mT5 and BanglaT5 for translating regional dialects into standard Bangla. Additionally, we employed mBERT and Bangla-bert-base to determine the specific regions from where these dialects originated. Our experimental results showed the highest BLEU score of 69.06 for Mymensingh regional dialects and the lowest BLEU score of 36.75 for Chittagong regional dialects. We also observed the lowest average word error rate of 0.1548 for Mymensingh regional dialects and the highest of 0.3385 for Chittagong regional dialects. For region detection, we achieved an accuracy of 85.86% for Bangla-bert-base and 84.36% for mBERT. This is the first large-scale investigation of Bangla regional dialects to Bangla machine translation. We believe our findings will not only pave the way for future work on Bangla regional dialects to Bangla machine translation, but will also be useful in solving similar language-related challenges in low-resource language conditions.
Product Market Demand Analysis Using NLP in Banglish Text with Sentiment Analysis and Named Entity Recognition
Apr 04, 2022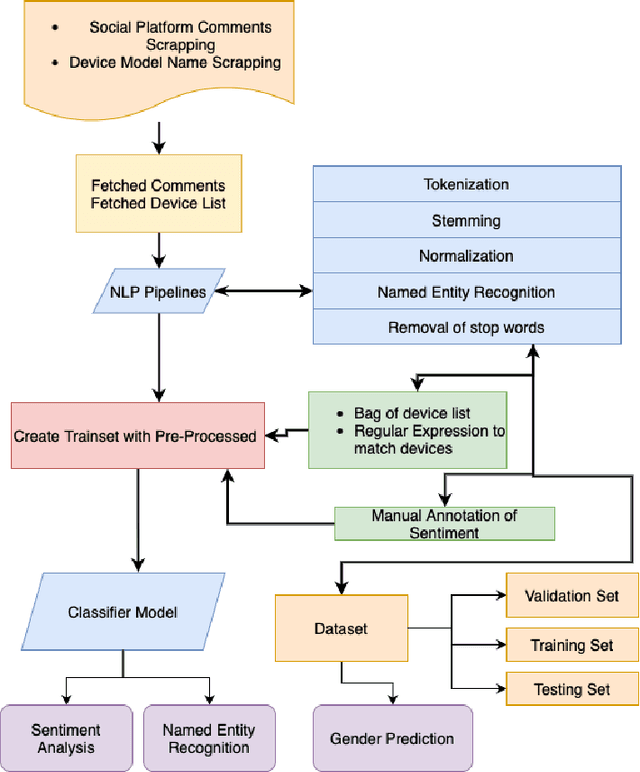

Product market demand analysis plays a significant role for originating business strategies due to its noticeable impact on the competitive business field. Furthermore, there are roughly 228 million native Bengali speakers, the majority of whom use Banglish text to interact with one another on social media. Consumers are buying and evaluating items on social media with Banglish text as social media emerges as an online marketplace for entrepreneurs. People use social media to find preferred smartphone brands and models by sharing their positive and bad experiences with them. For this reason, our goal is to gather Banglish text data and use sentiment analysis and named entity identification to assess Bangladeshi market demand for smartphones in order to determine the most popular smartphones by gender. We scraped product related data from social media with instant data scrapers and crawled data from Wikipedia and other sites for product information with python web scrapers. Using Python's Pandas and Seaborn libraries, the raw data is filtered using NLP methods. To train our datasets for named entity recognition, we utilized Spacey's custom NER model, Amazon Comprehend Custom NER. A tensorflow sequential model was deployed with parameter tweaking for sentiment analysis. Meanwhile, we used the Google Cloud Translation API to estimate the gender of the reviewers using the BanglaLinga library. In this article, we use natural language processing (NLP) approaches and several machine learning models to identify the most in-demand items and services in the Bangladeshi market. Our model has an accuracy of 87.99% in Spacy Custom Named Entity recognition, 95.51% in Amazon Comprehend Custom NER, and 87.02% in the Sequential model for demand analysis. After Spacy's study, we were able to manage 80% of mistakes related to misspelled words using a mix of Levenshtein distance and ratio algorithms.