 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTransPAD: Video Transformer using convolution and self-attention for Face Presentation Attack Detection
Paper and Code
Mar 14, 2022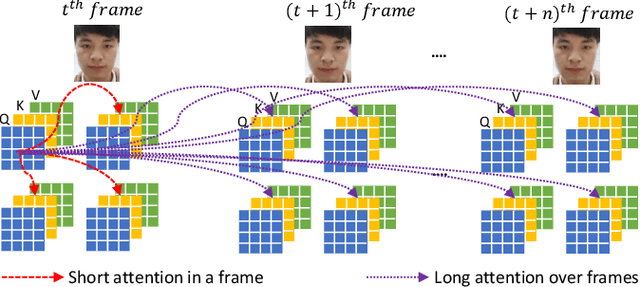
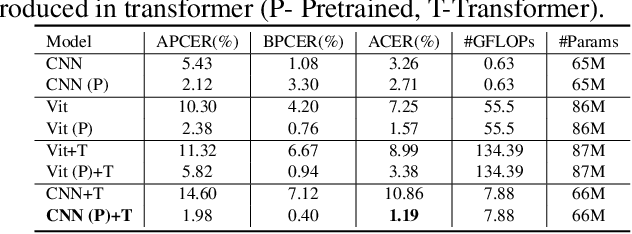
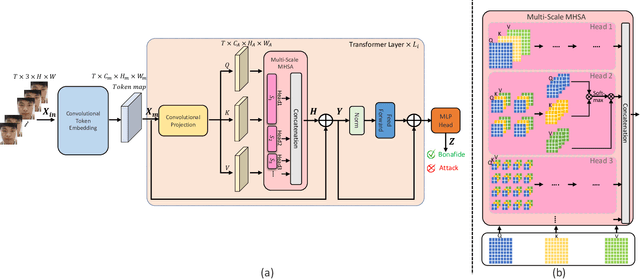
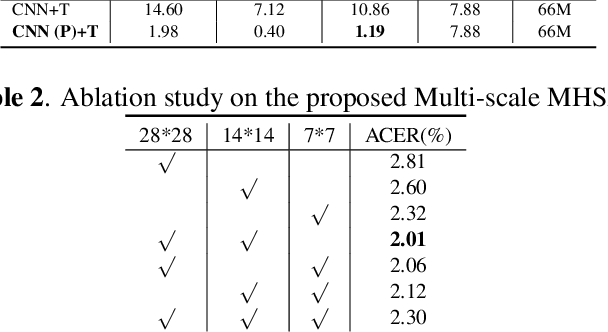
Face Presentation Attack Detection (PAD) is an important measure to prevent spoof attacks for face biometric systems. Many works based on Convolution Neural Networks (CNNs) for face PAD formulate the problem as an image-level binary classification task without considering the context. Alternatively, Vision Transformers (ViT) using self-attention to attend the context of an image become the mainstreams in face PAD. Inspired by ViT, we propose a Video-based Transformer for face PAD (ViTransPAD) with short/long-range spatio-temporal attention which can not only focus on local details with short attention within a frame but also capture long-range dependencies over frames. Instead of using coarse image patches with single-scale as in ViT, we propose the Multi-scale Multi-Head Self-Attention (MsMHSA) architecture to accommodate multi-scale patch partitions of Q, K, V feature maps to the heads of transformer in a coarse-to-fine manner, which enables to learn a fine-grained representation to perform pixel-level discrimination for face PAD. Due to lack inductive biases of convolutions in pure transformers, we also introduce convolutions to the proposed ViTransPAD to integrate the desirable properties of CNNs by using convolution patch embedding and convolution projection. The extensive experiments show the effectiveness of our proposed ViTransPAD with a preferable accuracy-computation balance, which can serve as a new backbone for face PAD.