 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTaPEs: Visuotactile Position Encodings for Cross-Modal Alignment in Multimodal Transformers
Paper and Code
May 26, 2025

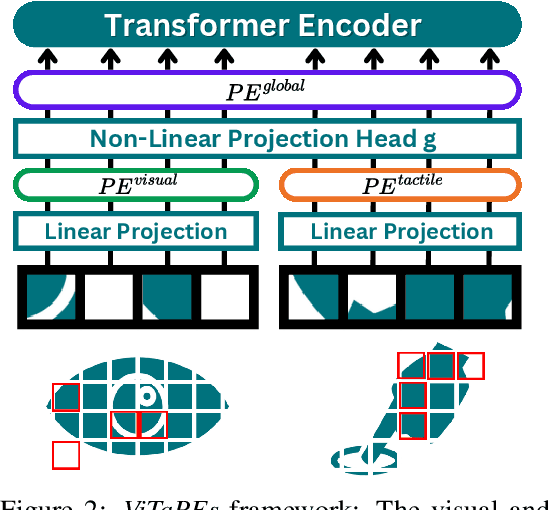

Tactile sensing provides local essential information that is complementary to visual perception, such as texture, compliance, and force. Despite recent advances in visuotactile representation learning, challenges remain in fusing these modalities and generalizing across tasks and environments without heavy reliance on pre-trained vision-language models. Moreover, existing methods do not study positional encodings, thereby overlooking the multi-scale spatial reasoning needed to capture fine-grained visuotactile correlations. We introduce ViTaPEs, a transformer-based framework that robustly integrates visual and tactile input data to learn task-agnostic representations for visuotactile perception. Our approach exploits a novel multi-scale positional encoding scheme to capture intra-modal structures, while simultaneously modeling cross-modal cues. Unlike prior work, we provide provable guarantees in visuotactile fusion, showing that our encodings are injective, rigid-motion-equivariant, and information-preserving, validating these properties empirically. Experiments on multiple large-scale real-world datasets show that ViTaPEs not only surpasses state-of-the-art baselines across various recognition tasks but also demonstrates zero-shot generalization to unseen, out-of-domain scenarios. We further demonstrate the transfer-learning strength of ViTaPEs in a robotic grasping task, where it outperforms state-of-the-art baselines in predicting grasp success. Project page: https://sites.google.com/view/vitapes