Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Excess Resources in Training Neural Networks
Paper and Code



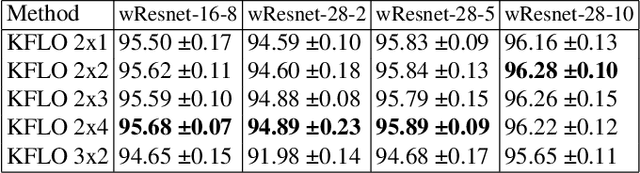
In this work, we suggest Kernel Filtering Linear Overparameterization (KFLO), where a linear cascade of filtering layers is used during training to improve network performance in test time. We implement this cascade in a kernel filtering fashion, which prevents the trained architecture from becoming unnecessarily deeper. This also allows using our approach with almost any network architecture and let combining the filtering layers into a single layer in test time. Thus, our approach does not add computational complexity during inference. We demonstrate the advantage of KFLO on various network models and datasets in supervised learning.
* Accepted to ICIP 2022. Code available at
https://github.com/AmitHenig/KFLO
View paper on