 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTroll Tweet Detection Using Contextualized Word Representations
Paper and Code
Jul 17, 2022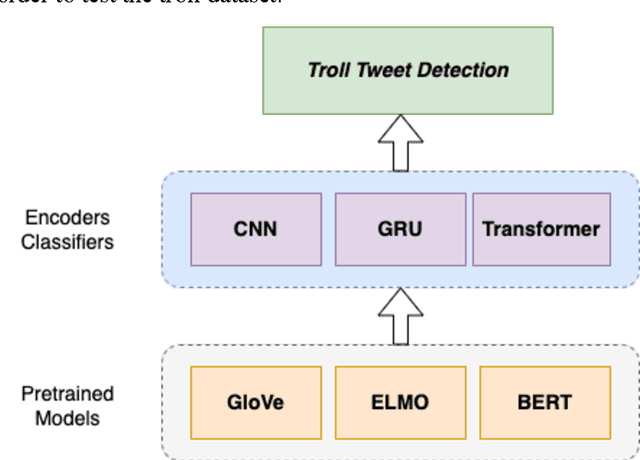
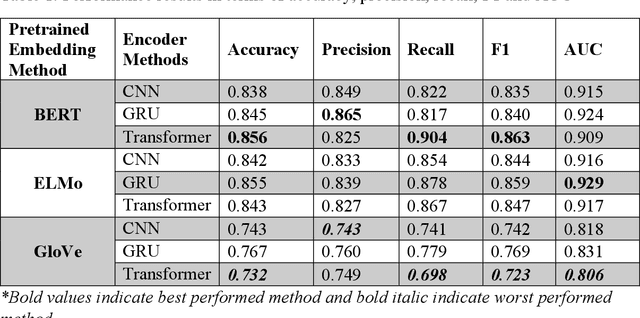

In recent years, many troll accounts have emerged to manipulate social media opinion. Detecting and eradicating trolling is a critical issue for social-networking platforms because businesses, abusers, and nation-state-sponsored troll farms use false and automated accounts. NLP techniques are used to extract data from social networking text, such as Twitter tweets. In many text processing applications, word embedding representation methods, such as BERT, have performed better than prior NLP techniques, offering novel breaks to precisely comprehend and categorize social-networking information for various tasks. This paper implements and compares nine deep learning-based troll tweet detection architectures, with three models for each BERT, ELMo, and GloVe word embedding model. Precision, recall, F1 score, AUC, and classification accuracy are used to evaluate each architecture. From the experimental results, most architectures using BERT models improved troll tweet detection. A customized ELMo-based architecture with a GRU classifier has the highest AUC for detecting troll messages. The proposed architectures can be used by various social-based systems to detect troll messages in the future.